

pdpipe 라이브러리의 colDrop() 메서드를 사용하여 Pandas DataFrame에서 열을 제거합니다. 먼저 필요한 pdpipe 및 pandas 라이브러리를 해당 별칭과 함께 가져옵니다. - import pdpipe as pdp import pandas as pd DataFrame을 생성해 보겠습니다. 여기에 두 개의 열이 있습니다 - dataFrame = pd.DataFrame( { "Car": ['BMW', 'Lexus
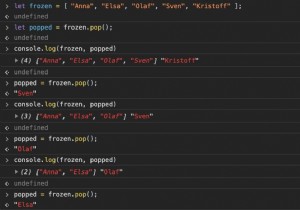
단일 열에서 고유한 값을 찾으려면 unique() 메서드를 사용합니다. Pandas DataFrame에 직원 레코드가 있다고 가정해 보겠습니다. 두 직원의 이름이 비슷할 수 있으므로 이름이 반복될 수 있습니다. 이 경우 고유한 Employee 이름을 원하면 DataFrame에 unique()를 사용하십시오. 먼저 필요한 라이브러리를 가져옵니다. 여기에서 pd를 별칭으로 설정했습니다 - import pandas as pd 먼저 DataFrame을 만듭니다. 여기에 두 개의 열이 있습니다 - dataFrame = pd.DataFra
기존 Pandas DataFrame에 사전 목록을 추가하고 append() 메서드를 사용합니다. 먼저 DataFrame을 생성하십시오 - dataFrame = pd.DataFrame( { "Car": ['BMW', 'Audi', 'XUV', 'Lexus', 'Volkswagen'],"Place": ['Delhi','Bangalore',&#
Seaborn의 막대 그림은 점 추정치와 신뢰 구간을 직사각형 막대로 표시하는 데 사용됩니다. seaborn.barplot() 이를 위해 사용됩니다. x, y 또는 색조를 사용하여 범주형 변수를 전달하여 범주형 변수로 그룹화된 수직 막대 플롯 그리기 매개변수. 다음이 CSV 파일 형식의 데이터세트라고 가정해 보겠습니다. Cricketers2.csv 먼저 필요한 라이브러리를 가져옵니다 - import seaborn as sb import pandas as pd import matplotlib.pyplot as plt CSV 파일
Seaborn의 막대 그림은 점 추정치와 신뢰 구간을 직사각형 막대로 표시하는 데 사용됩니다. seaborn.barplot()은 가로 막대 플롯을 만드는 데 사용됩니다. 다음이 CSV 파일 형식의 데이터세트라고 가정해 보겠습니다. Cricketers2.csv 먼저 필요한 라이브러리를 가져옵니다 - import seaborn as sb import pandas as pd import matplotlib.pyplot as plt CSV 파일에서 Pandas DataFrame으로 데이터 로드 - dataFrame = pd.read_
Seaborn의 막대 그림은 점 추정치와 신뢰 구간을 직사각형 막대로 표시하는 데 사용됩니다. seaborn.barplot()이 이를 위해 사용됩니다. 데이터세트 열을 x 및 y 값으로 사용하여 수평 막대 플롯을 플로팅합니다. 에스티메이터 사용 중앙값을 설정하는 매개변수 중심 경향의 추정치로. 다음이 CSV 파일 형식의 데이터세트라고 가정해 보겠습니다. Cricketers2.csv 먼저 필요한 라이브러리를 가져옵니다 - import seaborn as sb import pandas as pd import matplotlib.py
여러 열을 그리기 위해 막대 그래프를 그릴 것입니다. plot() 사용 메소드 및 종류 설정 막대에 대한 매개변수 막대 그래프의 경우. 먼저 필요한 라이브러리를 가져오도록 합시다 - import pandas as pd import matplotlib.pyplot as mp 다음은 팀 기록을 사용한 데이터입니다 − data = [["Australia", 2500, 2021],["Bangladesh", 1000, 2021],["England", 2000, 2021],["I
다음이 CSV 파일의 내용이라고 가정해 보겠습니다. - Car Reg_Price 0 BMW 2000 1 Lexus 1500 2 Audi 1500 3 Jaguar 2000 4 Mustang 1500 필요한 라이브러리 가져오기 - import pandas as pd import matplotlib.pyplot as
선 그래프에서 DataFrame을 플롯하려면 plot() 메소드 및 종류 설정 라인에 대한 매개변수. 먼저 필요한 라이브러리를 가져오도록 합시다 - import pandas as pd import matplotlib.pyplot as mp 다음은 팀 기록을 사용한 데이터입니다 − data = [["Australia", 2500, 2021],["Bangladesh", 1000, 2021],["England", 2000, 2021],["India", 3000, 2
다음이 Microsoft Excel에서 열린 CSV 파일의 내용이라고 가정해 보겠습니다. - 먼저 CSV 파일에서 Pandas DataFrame으로 데이터를 로드합니다. - dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\SalesData.csv") 하위 집합을 선택하려면 대괄호를 사용합니다. 대괄호 안의 열을 언급하고 전체 데이터 세트에서 단일 열을 가져옵니다 - dataFrame['Car'] 예 다음은 코드입니다 - import pandas
행의 하위 집합을 선택하려면 조건을 사용하고 데이터를 가져옵니다. 다음이 Microsoft Excel에서 열린 CSV 파일의 내용이라고 가정해 보겠습니다. - 먼저 CSV 파일에서 Pandas DataFrame으로 데이터를 로드합니다. - dataFrame =pd.read_csv(C:\\Users\\amit_\\Desktop\\SalesData.csv) 단위가 100개 이상인 자동차 레코드, 즉 행의 하위 집합을 원한다고 가정해 보겠습니다. 이를 위해 -를 사용하십시오. 100] 이제 Reg_Price가 100 미만인
다음이 Microsoft Excel에서 열린 CSV 파일의 내용이라고 가정해 보겠습니다. - 먼저 CSV 파일에서 Pandas DataFrame으로 데이터를 로드합니다. - dataFrame =pd.read_csv(C:\\Users\\amit_\\Desktop\\SalesData.csv) 여러 열 레코드를 선택하려면 대괄호를 사용하십시오. 대괄호 안에 있는 열을 언급하고 전체 데이터 세트에서 여러 열을 가져옵니다. - dataFrame[[Reg_Price,단위]] 예시 다음은 코드입니다 - pandas를 pd로 가져오기#
Pandas DataFrame을 병합하려면 merge()를 사용하세요. 기능. 다대일 관계 validate 아래에서 설정하여 두 DataFrame에서 모두 구현됩니다. merge() 함수의 매개변수, 즉 - validate = “many-to-one” or validate = “m:1” 다대일 관계는 병합 키가 올바른 데이터 세트에서 고유한지 확인합니다. 먼저 첫 번째st를 만들어 보겠습니다. 데이터프레임 - dataFrame1 = pd.DataFrame( { &
특정 텍스트가 포함된 행을 선택하려면 contains() 메서드를 사용합니다. 다음이 CSV 파일 경로라고 가정해 보겠습니다. - C:\\Users\\amit_\\Desktop\\SalesRecords.csv 먼저 CSV 파일을 읽고 Pandas DataFrame을 생성해 보겠습니다 - dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\CarRecords.csv") 이제 특정 텍스트 BMW가 포함된 행을 선택하겠습니다. - dataFrame = dataFrame[dat
columns.values()를 사용하면 CSV 파일의 인덱스 번호로 열 이름을 쉽게 바꿀 수 있습니다. 다음이 Microsoft Excel에서 열린 CSV 파일의 내용이라고 가정해 보겠습니다. - 열 이름을 바꿀 것입니다. 먼저 CSV 파일에서 Pandas DataFrame으로 데이터를 로드합니다. - dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\SalesData.csv") CSV의 모든 열 이름 표시 - dataFrame.columns 이제 열 이름을
산점도는 데이터 시각화 기술입니다. plot.scatter()를 사용하여 산점도를 플로팅합니다. 먼저 필요한 라이브러리를 가져오도록 합시다 - 팀 기록에 데이터가 있습니다. Pandas DataFrame에서 설정 - data = [["Australia", 2500],["Bangladesh", 1000],["England", 2000],["India", 3000],["Srilanka", 1500]] dataFrame = pd.DataFrame
헤더가 없는 CSV 파일을 읽으려면 헤더 매개변수를 사용하고 없음으로 설정합니다. 에서 read_csv() 방법. 다음이 Microsoft Excel에서 열린 CSV 파일의 내용이라고 가정해 보겠습니다. - 먼저 필요한 라이브러리를 가져옵니다 - import pandas as pd CSV 파일에서 Pandas DataFrame으로 데이터를 로드합니다. 이렇게 하면 헤더도 표시됩니다 - dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\SalesData.csv")
Seaborn의 Swarm Plot은 겹치지 않는 포인트가 있는 범주형 산점도를 그리는 데 사용됩니다. seaborn.swarmplot()이 이를 위해 사용됩니다. 바이올린 플롯()을 사용하여 바이올린 플롯 위에 관찰의 무리를 그립니다. 다음이 CSV 파일 형식의 데이터세트라고 가정해 보겠습니다. Cricketers2.csv 먼저 필요한 라이브러리를 가져옵니다 - import seaborn as sb import pandas as pd import matplotlib.pyplot as plt CSV 파일에서 Pandas Dat
Seaborn의 막대 그림은 점 추정치와 신뢰 구간을 직사각형 막대로 표시하는 데 사용됩니다. seaborn.barplot()이 이를 위해 사용됩니다. barplot() 메서드에서 변수를 x 또는 y 좌표로 전달하여 범주형 변수로 그룹화된 수직 막대 플롯을 플로팅합니다. 다음이 CSV 파일 형식의 데이터세트라고 가정해 보겠습니다. Cricketers2.csv 먼저 필요한 라이브러리를 가져옵니다 - import seaborn as sb import pandas as pd import matplotlib.pyplot as plt
NaN 값을 바꾸려면 fillna() 메서드를 사용하십시오. 다음이 일부 NaN 값을 사용하여 Microsoft Excel에서 열린 CSV 파일이라고 가정해 보겠습니다. - 먼저 필요한 라이브러리를 가져옵니다 - import pandas as pd CSV 파일에서 Pandas DataFrame으로 데이터 로드 - dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\SalesData.csv") fillna() 메서드를 사용하여 NaN 값을 0으로 교체 - dataFr