

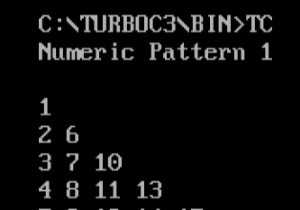
백분율 범위에서 요소 빈도를 찾아야 할 때 간단한 반복 기법과 함께 카운터를 사용합니다. 예 아래는 동일한 데모입니다. from collections import Counter my_list = [56, 34, 78, 90, 11, 23, 6, 56, 79, 90] print("The list is :") print(my_list) start, end = 13, 60 my_freq = dict(Counter(my_list)) my_result = [] for element in set(my_list):
Pandas DataFrame에 0 열을 추가하려면 대괄호를 사용하여 0으로 설정합니다. 먼저 필요한 라이브러리를 가져옵니다 - import pandas as pd 3개의 열이 있는 DataFrame 만들기 - dataFrame = pd.DataFrame( { "Student": ['Jack', 'Robin', 'Ted', 'Marc', 'Scarlett', 'Kat'
리스트에 존재하는 문자열의 연속적인 요소를 그룹화해야 할 때 groupby와 yield를 사용하는 메소드를 정의합니다. 예시 아래는 동일한 데모입니다. itertools에서 import groupbydef string_check(elem):return isinstance(elem, str)def group_string(my_list):key, groupby의 grp(my_list, key=string_check):if key:yield list(grp) else:yield from grpmy_list =[52, 11, py, t
주어진 문자의 문자반복을 얻어야 할 때 인덱스 값을 사용하여 반복을 출력하는 메소드를 정의한다. 예시 아래는 동일한 데모입니다. def to_string(my_list): return ''.join(my_list) def lex_recurrence(my_string, my_data, last_val, index_val): length = len(my_string) for i in range(length): my_data[index_val] = my_string[i] if
열의 데이터 유형을 얻으려면 info() 메소드를 사용하십시오. 먼저 필요한 라이브러리를 가져오도록 합시다 - import pandas as pd 데이터 유형이 다른 2개의 열이 있는 DataFrame 만들기 - dataFrame = pd.DataFrame( { "Student": ['Jack', 'Robin', 'Ted', 'Marc', 'Scarlett', 'Kat'
특정 데이터 유형이 있는 열을 선택하려면 select_dtypes()를 사용하세요. 메소드 및 include 매개변수. 먼저 2개의 열이 있는 DataFrame을 만듭니다. - dataFrame = pd.DataFrame( { "Student": ['Jack', 'Robin', 'Ted', 'Marc', 'Scarlett', 'Kat', 'John'],&q
여러 열 헤더의 이름을 바꾸려면 rename()을 사용하세요. 메소드 및 열에 사전 설정 매개변수. 먼저 DataFrame을 생성하겠습니다 - dataFrame =pd.DataFrame({자동차:[BMW, 머스탱, 테슬라, 머스탱, 메르세데스, 테슬라, 아우디],입방 용량:[ 2000, 1800, 1500, 2500, 2200, 3000, 2000],정가:[7000, 1500, 5000, 8000, 5000, 6000, 1500],판매 단위 210, 250, 220]}) 열 이름을 바꾸는 사전 만들기. 이전 이름과 새 이름으로 키
행렬 행 길이의 빈도를 계산해야 할 때 반복되고 빈도가 빈 사전에 추가되거나 다시 발견되면 증가합니다. 예 아래는 동일한 데모입니다. my_list = [[42, 24, 11], [67, 18], [20], [54, 10, 25], [45, 99]] print("The list is :") print(my_list) my_result = dict() for element in my_list: if len(element) not in my_result: my_result[len(element)]
iat를 사용합니다. 속성은 정수 위치로 행/열 쌍의 단일 값에 액세스하는 데 사용되기 때문에 마지막 요소에 액세스합니다. 먼저 필요한 Pandas 라이브러리를 가져오겠습니다 - import pandas as pd 숫자로 판다 시리즈 만들기 - data = pd.Series([10, 20, 5, 65, 75, 85, 30, 100]) 이제 iat() −를 사용하여 마지막 요소를 가져옵니다. data.iat[-1] 예 다음은 코드입니다 - import pandas as pd # pandas series data = pd.Se
목록 요소의 개수로 값을 포함하는 중첩 목록을 생성해야 하는 경우 단순 반복이 사용됩니다. 예시 아래는 동일한 데모입니다. my_list = [11, 25, 36, 24] print("The list is :") print(my_list) for element in range(len(my_list)): my_list[element] = [element+1 for j in range(element+1)] print("The resultant list is :") print(my_list)
중첩된 목록을 튜플 목록으로 병합해야 하는 경우 목록을 매개 변수로 사용하고 isinstance 메서드를 사용하여 요소가 특정 유형에 속하는지 확인하는 메서드가 정의됩니다. 이에 따라 출력이 표시됩니다. 예 아래는 동일한 데모입니다. def convert_nested_tuple(my_list): for elem in my_list: if isinstance(elem, list): convert_nested_tuple(elem) else: my_result.append(el
단일 레벨 열을 스택하려면 datafrem.stack()을 사용하십시오. 먼저 필요한 라이브러리를 가져오도록 합시다 - import pandas as pd 단일 수준 열이 있는 DataFrame 만들기 - dataFrame = pd.DataFrame([[10, 15], [20, 25], [30, 35], [40, 45]],index=['w', 'x', 'y', 'z'],columns=['a', 'b']) stack() 메서드를 사용하여 Data
N보다 큰 K의 연속된 범위를 가져와야 하는 경우 열거 속성과 단순 반복을 사용합니다. 예시 아래는 동일한 데모입니다. my_list = [3, 65, 33, 23, 65, 65, 65, 65, 65, 65, 65, 3, 65] print("The list is :") print(my_list) K = 65 N = 3 print("The value of K is ") print(K) print("The value of N is ") print(N) my_result = [] b
append()를 사용하여 DataFrame에 목록을 추가하려면 먼저 DataFrame을 만듭니다. 데이터는 이 예의 팀 순위 목록 형식입니다. # data in the form of list of team rankings Team = [['India', 1, 100],['Australia', 2, 85],['England', 3, 75],['New Zealand', 4 , 65],['South Africa', 5, 50]] # Creating a Data
증가하지 않는 요소를 제거해야 하는 경우 요소 비교와 함께 단순 반복이 사용됩니다. 예 아래는 동일한 데모입니다. my_list = [5,23, 45, 11, 45, 67, 89, 99, 10, 26, 7, 11] print("The list is :") print(my_list) my_result = [my_list[0]] for elem in my_list: if elem >= my_result[-1]: my_result.append(elem) print("The resu
데이터 구조에서 요소의 인덱스 순위를 결정해야 하는 경우 목록을 매개변수로 사용하는 메서드가 정의됩니다. 목록의 요소를 반복하고 두 변수의 값을 변경하기 전에 특정 비교를 수행합니다. 예시 아래는 동일한 데모입니다. def find_rank_elem(my_list): my_result = [0 for x in range(len(my_list))] for elem in range(len(my_list)): (r, s) = (1, 1) for j in range(len(my_list)):
Intersection에 의해 두 DataFrame 사이의 열을 가져오려면 Intersection() 메서드를 사용합니다. 두 개의 DataFrame을 생성해 보겠습니다 - # creating dataframe1 dataFrame1 = pd.DataFrame({"Car": ['Bentley', 'Lexus', 'Tesla', 'Mustang', 'Mercedes', 'Jaguar'],"Cubic_Capacity"
성질이 유사한 결합된 연속 문자를 분리해야 하는 경우 groupby 방법과 join 방법을 사용합니다. 예시 아래는 동일한 데모입니다. from itertools import groupby my_string = 'pppyyytthhhhhhhoooooonnn' print("The string is :") print(my_string) my_result = ["".join(grp) for elem, grp in groupby(my_string)] print("The re
주어진 합계로 K 길이 그룹을 가져와야 할 때 빈 목록, product 방법, sum 방법 및 append 방법을 사용할 수 있습니다. 예 아래는 동일한 데모입니다. from itertools import product my_list = [45, 32, 67, 11, 88, 90, 87, 33, 45, 32] print("The list is : ") print(my_list) N = 77 print("The value of N is ") print(N) K = 2 print("Th
두 개의 숫자에 존재하는 모든 고유한 비공통 숫자를 인쇄해야 하는 경우 두 개의 정수를 매개변수로 사용하는 방법이 정의됩니다. symmetric_difference 메서드는 흔하지 않은 숫자를 얻는 데 사용됩니다. 예 아래는 동일한 데모입니다. def distinct_uncommon_nums(val_1, val_2): val_1 = str(val_1) val_2 = str(val_2) list_1 = list(map(int, val_1)) list_2 = list(map(int, val_2)) list