
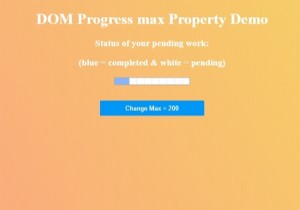
사전 목록에서 모든 고유 키를 가져와야 하는 경우 사전 값이 반복되어 집합으로 변환됩니다. 이것은 목록으로 변환되어 콘솔에 표시됩니다. 예 아래는 동일한 데모입니다. my_list = [{'hi' : 11, 'there' : 28}, {'how' : 11, 'are' : 31}, {'you' : 28, 'Will':31}] print("The list is:") print(my_list) my_result = list(set(
예, &연산자를 사용하여 두 DataFrame 간의 공통 열을 찾을 수 있습니다. 먼저 두 개의 DataFrame을 생성해 보겠습니다. # creating dataframe1 dataFrame1 = pd.DataFrame({"Car": ['BMW', 'Lexus', 'Tesla', 'Mustang', 'Mercedes', 'Jaguar'],"Cubic_Capacity": [2000, 1800, 1500, 250
배열의 요소를 병합하여 형성된 정렬된 숫자를 인쇄해야 하는 경우 먼저 숫자를 정렬하고 숫자를 정수로 변환하는 방법을 정의할 수 있습니다. 다른 방법은 이 목록을 문자열에 매핑하고 다시 정렬합니다. 예시 아래는 동일한 데모입니다. def get_sorted_nums(my_num): my_num = ''.join(sorted(my_num)) my_num = int(my_num) print(my_num) def merged_list(my_list): my_list = list(map(str, m
주어진 문자열 목록의 부분 문자열인 모든 문자열을 찾아야 할 때 set 및 list 속성이 사용됩니다. 예시 아래는 동일한 데모입니다. my_list_1 = ["Hi", "there", "how", "are", "you"] my_list_2 = ["Hi", "there", "how", "have", "you", 'been'] print(&q
열 값을 기반으로 행을 필터링하려면 query() 함수를 사용할 수 있습니다. 함수에서 레코드를 필터링할 조건을 설정합니다. 먼저 필요한 라이브러리를 가져옵니다 - import pandas as pd 다음은 팀 기록을 사용한 데이터입니다 − Team = [['India', 1, 100],['Australia', 2, 85],['England', 3, 75],['New Zealand', 4 , 65],['South Africa', 5, 50],['Bang
특정 합이 인 부분집합을 모두 구해야 할 때 목록을 순회하여 목록의 모든 조합을 구하고 합과 일치하면 콘솔에 출력하는 메소드가 정의됩니다. 예 아래는 동일한 데모입니다. from itertools import combinations def sub_set_sum(size, my_array, sub_set_sum): for i in range(size+1): for my_sub_set in combinations(my_array, i): &nb
목록의 목록을 집합의 목록으로 변환해야 하는 경우 map, set, list 메서드를 사용합니다. 예 아래는 동일한 데모입니다. my_list = [[2, 2, 2, 2], [1, 2, 1], [1, 2, 3], [1,1], [0]] print("The list of lists is: ") print(my_list) my_result = list(map(set, my_list)) print("The resultant list is: ") print(my_result) 출력 The list
피벗 테이블을 만들려면 pandas.pivot_table()을 사용하세요. 스프레드시트 스타일의 피벗 테이블을 DataFrame으로 생성합니다. 먼저 필요한 라이브러리를 가져옵니다 - import pandas as pd 팀 기록으로 DataFrame 만들기 - dataFrame = pd.DataFrame({'Team ID': {0: 5, 1: 9, 2: 6, 3: 11, 4: 2, 5: 7 },'Team Name': {0: 'India', 1: 'Australia', 2:
Seaborn pairplots에 주석을 달기 위해 fig.text()를 사용할 수 있습니다. 방법. 단계 Seaborn, Pandas, Numpy 및 Pyplot 패키지를 가져옵니다. 그림 크기를 설정하고 서브플롯 사이 및 주변 여백을 조정합니다. 크기가 변경 가능한 2차원 테이블 형식 데이터의 Pandas 데이터 프레임을 생성합니다. sns.pairplot()을 사용하여 데이터 세트에서 쌍별 관계를 플로팅합니다. fig.text()를 사용하여 주석 텍스트 추가 방법. 그림을 표시하려면 show()를 사용하세요. 방법. 예시
matplotlib를 사용하여 Y축을 기하급수적으로 확장하려면 다음 단계를 수행할 수 있습니다. - 그림 크기를 설정하고 서브플롯 사이 및 주변 여백을 조정합니다. 단계에 대한 변수 dt를 초기화합니다. numpy를 사용하여 x 및 y 데이터 포인트를 생성합니다. numpy를 사용하여 x 및 y 데이터 포인트를 플로팅합니다. plt.yscale(symlog)을 사용하여 Y축의 지수 스케일을 설정합니다. . 그림을 표시하려면 show()를 사용하세요. 방법. 예시 import numpy as np import matplotlib.
matplotlib에 세로선이 있는 범례를 추가하려면 다음 단계를 수행할 수 있습니다. - 그림 크기를 설정하고 서브플롯 사이 및 주변 여백을 조정합니다. 그림과 서브플롯 세트를 생성합니다. 빨간색으로 세로선을 그립니다. 선은 모든 정점을 연결하는 실선 스타일과 각 정점에 마커를 둘 다 가질 수 있습니다. 수직선으로 플롯에 범례를 배치합니다. 그림을 표시하려면 show()를 사용하세요. 방법. 예시 import matplotlib.pyplot as plt from matplotlib import lines plt.rcParam
FEM(Finite Element Method)은 다양한 재료 유형 모델링, 복잡한 형상 테스트, 설계의 작은 영역에 작용하는 국소 효과 시각화와 같은 다양한 작업에 사용됩니다. 기본적으로 큰 공간 영역을 유한 요소라고 하는 간단한 부분으로 나눕니다. 이러한 유한 요소를 모델링하는 간단한 방정식은 전체 영역을 모델링하기 위해 더 큰 방정식 시스템으로 수집됩니다. matplotlib를 사용하여 2D FEM 결과를 플롯하려면 다음 단계를 수행할 수 있습니다. - 그림 크기를 설정하고 서브플롯 사이 및 주변 여백을 조정합니다. num
pandas.DataFrame.corr을 사용할 수 있습니다. NULL 값을 제외한 열의 쌍별 상관 관계를 계산합니다. 상관 계수는 두 변수 간의 선형 연관성의 강도를 나타냅니다. 계수 범위는 -1과 1 사이입니다. Pandas 데이터 프레임에서 두 숫자 열 간의 상관 관계를 얻으려면 다음 단계를 수행할 수 있습니다. 그림 크기를 설정하고 서브플롯 사이 및 주변 여백을 조정합니다. 크기가 변경 가능한 2차원 테이블 형식 데이터의 Pandas 데이터 프레임을 생성합니다. 두 열의 값을 비교하고 col1.corr(col2)을 사용
Python에서 히스토그램 플롯을 저장하려면 다음 단계를 수행할 수 있습니다. - 그림 크기를 설정하고 서브플롯 사이 및 주변 여백을 조정합니다. 데이터 포인트 생성 k 히스토그램용. hist()를 사용하여 히스토그램을 플로팅합니다. 방법. 히스토그램을 저장하려면 plt.savefig(image_name)를 사용하세요. . 그림을 표시하려면 show()를 사용하세요. 방법. 예 import matplotlib.pyplot as plt # Set the figure size plt.rcParams["figure.fig
matplotlib를 사용하여 .txt 파일에서 데이터를 플롯하려면 다음 단계를 수행할 수 있습니다. - 그림 크기를 설정하고 서브플롯 사이 및 주변 여백을 조정합니다. bar_names 및 bar_heights에 대한 빈 목록을 초기화합니다. 읽기 r 모드에서 샘플 .txt 파일을 열고 막대 이름 및 높이 목록에 추가합니다. 막대 플롯을 만듭니다. 그림을 표시하려면 show()를 사용하세요. 방법. 예시 from matplotlib import pyplot as plt plt.rcParams["figure.figsi
matplotlib에서 직선 대신 두 점을 연결하는 곡선을 그리려면 다음 단계를 수행할 수 있습니다. - 그림 크기를 설정하고 서브플롯 사이 및 주변 여백을 조정합니다. draw_curve() 정의 수학적 표현으로 곡선을 만드는 방법입니다. point1 및 point2 데이터 포인트를 플로팅합니다. draw_curve()에서 반환된 x 및 y 데이터 포인트 플롯 방법. 그림을 표시하려면 show()를 사용하세요. 방법. 예 import matplotlib.pyplot as plt import numpy as np plt.rcP
열 값의 최소값을 얻으려면 min() 함수를 사용하십시오. 먼저 필요한 Pandas 라이브러리를 가져옵니다. - pandas를 pd로 가져오기 이제 두 개의 열이 있는 DataFrame을 만듭니다. - dataFrame1 =pd.DataFrame( { 자동차:[BMW, 렉서스, 아우디, 테슬라, 벤틀리, 재규어],단위:[100, 150, 110 , 80, 110, 90] }) min()을 사용하여 단일 열 단위의 최소값 찾기 - printDataFrame1의 최소 단위 =,dataFrame1[Units].min() 같은 방법으
여러 열이 있는 피벗 테이블을 만들 수 있습니다. 피벗 테이블을 만들려면 pandas.pivot_table을 사용하세요. 스프레드시트 스타일의 피벗 테이블을 DataFrame으로 생성합니다. 먼저 필요한 라이브러리를 가져옵니다 - import pandas as pd 팀 기록으로 DataFrame 만들기 - dataFrame = pd.DataFrame({'Team ID': {0: 5, 1: 9, 2: 6, 3: 11, 4: 2, 5: 7 },'Team Name': {0: 'India',
확인하려면 isinf() 메서드를 사용하십시오. 무한 값의 개수를 찾으려면 sum()을 사용하십시오. 먼저 필요한 라이브러리를 해당 별칭과 함께 가져오도록 하겠습니다. − import pandas as pd import numpy as np 목록의 사전을 만듭니다. Numpy np.inf를 사용하여 무한대 값을 설정했습니다. - d = { "Reg_Price": [7000.5057, np.inf, 5000, np.inf, 9000.75768, 6000] } 위의 목록 사전에서 데이터 프레임 생성 dataFra
상수 값이 있는 새 열을 추가하려면 대괄호(예:인덱스 연산자)를 사용하고 해당 값을 설정하십시오. 먼저 필요한 라이브러리를 가져옵니다 - pandas를 pd로 가져오기 4개의 열로 DataFrame 만들기 - dataFrame =pd.DataFrame({자동차:[벤틀리, 렉서스, BBW, 머스탱, 메르세데스, 재규어],Cubic_Capacity:[2000, 1800, 1500 , 2500, 2200, 3000],등록 가격:[7000, 1500, 5000, 8000, 9000, 6000],판매 단위:[ 100, 110, 150,