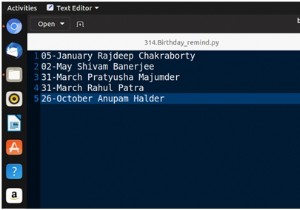


DataFrame의 통계 요약을 찾으려면 describe() 메서드를 사용하세요. 처음에는 별칭이 있는 다음 pandas 라이브러리를 가져왔습니다. import pandas as pd 다음은 CSV 파일이며 Pandas DataFrame을 만들고 있습니다 - dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\CarRecords.csv") 이제 Pandas DataFrame의 통계 요약을 얻으십시오 - dataFrame.describe() 예시 다음은 전체 코드입니다.
누락된 값, 즉 NaN 값을 제거하려면 dropna()를 사용하세요. 방법. 먼저 필요한 라이브러리를 가져오도록 합시다 - pandas를 pd로 가져오기 CSV를 읽고 DataFrame 생성 - dataFrame =pd.read_csv(C:\\Users\\amit_\\Desktop\\CarRecords.csv) dropna()를 사용하여 누락된 값을 제거합니다. dropna()가 사용된 후 누락된 값에 대해 NaN이 표시됩니다. - dataFrame.dropna() 예시 다음은 전체 코드입니다. pandas를 pd로 가져오기#
DataFrame의 열 이름을 바꾸려면 rename()을 사용하세요. 방법. rename() 메서드의 columns 매개변수에서 이름을 바꾸고자 하는 열 이름을 설정합니다. 예를 들어 자동차 열을 자동차 이름으로 - dataFrame.rename(columns={'Car': 'Car Name'}, inplace=False) 먼저 CSV를 읽고 DataFrame을 만듭니다. - dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\SalesRecords
새 열을 생성하기 위해 이미 생성된 열을 사용할 것입니다. 먼저 DataFrame을 만들고 CSV를 읽겠습니다. dataFrame =pd.read_csv(C:\\Users\\amit_\\Desktop\\SalesRecords.csv) 이제 이미 생성된 Reg_Price 열에서 새 열 New_Reg_Price를 만들고 각 값에 100을 추가하여 새 열을 형성합니다 - dataFrame[New_Reg_Price] =(dataFrame[Reg_Price] + 100) 예 다음은 코드입니다 - 판다를 pd로 가져오기# 읽기 csv f
조건을 설정하고 DataFrame 행을 가져올 수 있습니다. 이러한 조건은 논리 연산자와 관계 연산자를 사용하여 설정할 수 있습니다. 먼저 필요한 pandas 라이브러리를 가져옵니다. - import pandas as pd DataFrame을 만들고 CSV 파일을 읽겠습니다. − dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\SalesRecords.csv") 등록 가격이 1000 미만인 데이터 프레임 행을 가져옵니다. 이를 위해 관계 연산자를 사용하고 있습니다
Seaborn의 막대 그림은 점 추정치와 신뢰 구간을 직사각형 막대로 표시하는 데 사용됩니다. seaborn.barplot()이 사용됩니다. 페이스 컬러를 사용하여 막대 스타일 지정 , 선폭 및 가장자리 색상 매개변수. 다음이 CSV 파일 −Cricketers2.csv 형식의 데이터세트라고 가정해 보겠습니다. 먼저 필요한 라이브러리를 가져옵니다 - import seaborn as sb import pandas as pd import matplotlib.pyplot as plt CSV 파일에서 Pandas DataFrame으로
Seaborn의 Lineplot은 여러 의미 그룹화 가능성이 있는 선 플롯을 그리는 데 사용됩니다. seaborn.lineplot()이 이를 위해 사용됩니다. 전체 데이터 세트로 선 그림을 그리려면 x 및 y 값을 언급하지 않고 lineplot()을 사용하고 전체 데이터 세트를 설정하기만 하면 됩니다. 다음이 CSV 파일 형식의 데이터세트라고 가정해 보겠습니다. Cricketers2.csv 먼저 필요한 라이브러리를 가져옵니다 - import seaborn as sb import pandas as pd import matplotl
모든 열이 있는 그룹화된 가로 막대 차트의 경우 barh()를 사용하여 막대 차트를 만들고 a 및 y 값을 설정하지 마십시오. 먼저 필요한 라이브러리를 가져옵니다 - import pandas as pd import matplotlib.pyplot as plt 3개의 열이 있는 DataFrame 만들기 - dataFrame = pd.DataFrame({"Car": ['Bentley', 'Lexus', 'BMW', 'Mustang', 'Mercedes
메서드 사용 fillna의 ” 매개변수 () 방법. 뒤로 채우기의 경우 bfill 값을 사용합니다. 아래와 같이 - fillna(method='bfill') 다음이 일부 NaN 값을 사용하여 Microsoft Excel에서 열린 CSV 파일이라고 가정해 보겠습니다. - 먼저 필요한 라이브러리를 가져옵니다 - import pandas as pd CSV 파일에서 Pandas DataFrame으로 데이터 로드 - dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\
Interpolate() 메서드를 사용하여 NaN 값을 채웁니다. 다음이 일부 NaN 값을 사용하여 Microsoft Excel에서 열린 CSV 파일이라고 가정해 보겠습니다. - CSV 파일에서 Pandas DataFrame으로 데이터 로드 - dataFrame =pd.read_csv(C:\\Users\\amit_\\Desktop\\SalesData.csv) 보간()으로 NaN 값 채우기 - dataFrame.interpolate() 예 다음은 코드입니다 - pandas를 pd로 가져오기# CSV 파일에서 Pandas로 데
상자 플롯 위에 군집 플롯을 플롯하려면 먼저 boxplot()을 설정한 다음 동일한 x 및 y 값으로 swarmplot()을 설정합니다. Seaborn의 상자 그림은 범주에 대한 분포를 표시하기 위해 상자 그림을 그리는 데 사용됩니다. 이를 위해 seaborn.boxplot()가 사용됩니다. Seaborn의 Swarm Plot은 겹치지 않는 포인트가 있는 범주형 산점도를 그리는 데 사용됩니다. 이를 위해 seaborn.swarmplot()가 사용됩니다. 다음이 CSV 파일 형식의 데이터세트라고 가정해 보겠습니다. Crickete
Pandas DataFrame에서 초기 공간을 건너뛰려면 skipinitialspace를 사용하세요. read_csv 매개변수 () 방법. 매개변수를 True로 설정 추가 공간을 제거합니다. 다음이 csv 파일이라고 가정해 보겠습니다. - 초기 공백을 건너뛰고 CSV에서 DataFrame을 표시하는 것과 같은 출력을 얻어야 합니다 - 예 다음은 전체 코드입니다 - import pandas as pd # reading csv file dataFrame = pd.read_csv("C:\\Users\\amit_\\
Pandas DataFrame에서 null 행을 삭제하려면 dropna() 메서드를 사용합니다. 다음이 NaN, 즉 null 값이 포함된 CSV 파일이라고 가정해 보겠습니다. - read_csv()를 사용하여 CSV 파일을 읽어봅시다. 우리의 CSV는 바탕 화면에 있습니다 − dataFrame =pd.read_csv(C:\\Users\\amit_\\Desktop\\CarRecords.csv) dropna() −를 사용하여 null 값을 제거합니다. dataFrame =dataFrame.dropna() 예시 다음은 전체 코드
notnull() 메서드는 부울 값을 반환합니다. 즉, DataFrame에 null 값이 있으면 False가 반환되고 그렇지 않으면 True가 반환됩니다. 다음이 일부 NaN, 즉 null 값이 포함된 CSV 파일이라고 가정해 보겠습니다. - 먼저 CSV 파일을 읽겠습니다 - dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\CarRecords.csv") null 값이 아닌지 확인 - res = dataFrame.notnull() 이제 DataFrame을 표시할
DataFrame에서 Multiindex를 생성하려면 MultiIndex를 사용하십시오. from_frame() 메서드. 먼저 목록 사전을 만들어 보겠습니다. − d = {'Car': ['BMW', 'Lexus', 'Audi', 'Mercedes', 'Jaguar', 'Bentley'],'Date_of_purchase': ['2020-10-10', '2020-10-12', '2020-
두 개의 Pandas DataFrame을 공통 열과 병합하려면 merge()를 사용하세요. 기능을 설정하고 켜기 매개변수를 열 이름으로 사용합니다. 일치하지 않는 값에 대해 NaN을 설정하려면 how 매개변수를 지정하고 왼쪽으로 설정합니다. 또는 맞음 . 즉, 왼쪽 또는 오른쪽을 병합합니다. 먼저 별칭을 사용하여 pandas 라이브러리를 가져오겠습니다. import pandas as pd DataFrame1을 만들어 봅시다 - dataFrame1 = pd.DataFrame( {
Pandas DataFrame을 병합하려면 merge()를 사용하세요. 기능. 데카르트 곱은 how merge() 함수의 매개변수, 즉 - 방법 =교차 먼저 별칭을 사용하여 pandas 라이브러리를 가져오겠습니다. pandas를 pd로 가져오기 DataFrame1 생성 - dataFrame1 =pd.DataFrame( { 자동차:[BMW, 머스탱, 벤틀리, 재규어],단위:[100, 150, 110, 120] }) DataFrame2 생성 dataFrame2 =pd.DataFrame( { 자동차:[BMW, 테슬라, 재규어],R
Pandas DataFrame을 병합하려면 merge()를 사용하세요. 기능. 일대다 관계 validate 아래에서 설정하여 두 DataFrame에서 모두 구현됩니다. merge() 함수의 매개변수, 즉 - validate = “one-to-many” or validate = “1:m” 일대다 관계는 병합 키가 왼쪽 데이터 세트에서 고유한지 확인합니다. 먼저 첫 번째st를 만들어 보겠습니다. 데이터프레임 - dataFrame1 = pd.DataFrame( { &n
값 이름과 개수를 추출하기 위해 먼저 4개의 열이 있는 DataFrame을 생성하겠습니다. − dataFrame =pd.DataFrame({자동차:[BMW, 머스탱, 테슬라, 머스탱, 메르세데스, 테슬라, 아우디],입방 용량:[ 2000, 1800, 1500, 2500, 2200, 3000, 2000],정가:[7000, 1500, 5000, 8000, 9000, 6000, 1500],판매 단위 210, 250, 220]}) 특정 열에 대한 값 이름 및 개수를 가져옵니다. Car − res =dataFrame[자동차].value_c
그룹 값 중 첫 번째 값을 계산하려면 groupby.first() 메서드를 사용합니다. 처음에는 별칭을 사용하여 필요한 라이브러리를 가져옵니다. - pandas를 pd로 가져오기; 3개의 열이 있는 DataFrame 만들기 - dataFrame =pd.DataFrame( { 자동차:[BMW, 렉서스, BMW, 테슬라, 렉서스, 테슬라],장소:[델리, 방갈로르,푸네,펀자브,찬디가르,뭄바이],단위:[100, 150, 50, 80, 110, 90] }) 이제 열별로 DataFrame 그룹화 - groupDF =dataFrame.gro