

이 섹션에서는 다차원 배열의 또 다른 표현을 볼 것입니다. 여기서 우리는 Array of Arrays 표현을 볼 것입니다. 이 형식에는 여러 배열의 시작 주소를 보유하는 배열이 있습니다. 표현은 다음과 같습니다. 이것은 [7 x 8] 크기의 2차원 배열 x입니다. 각 행은 단일 1차원 배열로 표시됩니다. 초기 어레이는 이러한 단일 어레이의 주소를 보유하고 있습니다. 그것들은 주소 배열이므로 포인터 배열이라고 말할 수 있습니다. 각 포인터는 다른 배열의 주소를 보유하고 있습니다. 이런 종류의 배열을 만들면 아래와 같이 new
여기서 우리는 불규칙한 배열을 볼 것입니다. 불규칙 배열에 대해 논의하기 전에 정규 배열이 무엇인지 알아야 합니다. 일반 배열은 각 행의 열 수가 동일한 종류의 배열입니다. 즉, 각 행이 동일한 수의 요소를 보유하는 경우 이는 일반 배열입니다. 다음 표현은 일반 배열입니다. 정규 배열의 정의에서 불규칙 배열이 무엇인지 이해할 수 있습니다. 따라서 불규칙한 배열에서 각 행은 동일한 수의 요소를 포함하거나 포함하지 않을 수 있습니다. 이러한 종류의 불규칙한 배열은 배열의 배열 표현으로도 나타낼 수 있습니다. 이것은 아래와 같을 것
이 섹션에서는 희소 행렬이 무엇이고 메모리에서 어떻게 표현할 수 있는지 알아보겠습니다. 따라서 행렬의 요소 대부분이 0인 경우 행렬은 희소 행렬이 됩니다. 또 다른 정의는 최대 1/3의 0이 아닌 요소(m x n의 약 30%)가 있는 행렬을 희소 행렬이라고 합니다. 우리는 효율적인 방법으로 몇 가지 작업을 수행하기 위해 컴퓨터 메모리의 행렬을 사용합니다. 그러나 행렬이 본질적으로 희소하면 연산을 효율적으로 수행하는 데 도움이 될 수 있지만 메모리에서 더 많은 공간을 차지합니다. 그 공간은 목적이 없습니다. 그래서 우리는 희소 행렬
이 섹션에서는 일반화된 목록을 볼 수 있습니다. 일반화된 목록은 다음과 같이 정의할 수 있습니다. - 일반화된 목록 L은 n개 요소(n ≥ 0)의 유한 시퀀스입니다. 요소 ei는 원자(단일 요소)이거나 다른 일반화된 목록입니다. 원자가 아닌 요소 ei는 L의 하위 목록이 됩니다. L이 ((A, B, C), ((D, E), F), G)라고 가정합니다. 여기서 L에는 세 개의 요소 하위 목록(A, B, C), 하위 목록((D, E), F) 및 원자 G가 있습니다. 다시 하위 목록((D, E), F)에는 두 개의 요소가 있습니다. 하위
여기에 스레드 이진 트리 데이터 구조가 표시됩니다. 우리는 바이너리 트리 노드가 최대 두 개의 자식을 가질 수 있다는 것을 알고 있습니다. 그러나 자식이 하나만 있거나 자식이 없는 경우 연결 목록 표현의 링크 부분은 null로 유지됩니다. 스레드 이진 트리 표현을 사용하여 스레드를 만들어 빈 링크를 재사용할 수 있습니다. 한 노드에 왼쪽 또는 오른쪽 자식 영역이 비어 있으면 스레드로 사용됩니다. 스레드 이진 트리에는 두 가지 유형이 있습니다. 단일 스레드 트리 또는 전체 스레드 이진 트리. 단일 스레드 모드에는 또 다른 두 가지
힙 또는 이진 힙은 균형 이진 트리 데이터 구조의 특별한 경우입니다. 이것은 완전한 이진 트리 구조입니다. 따라서 l-1 레벨까지는 가득 차고 l 레벨에서는 모든 노드가 왼쪽에서 옵니다. 여기서 루트 노드 키는 자식과 비교되고 그에 따라 정렬됩니다. a에 자식 노드 b가 있는 경우 - key(a) ≥ key(b) 부모의 값이 자식의 값보다 크므로 이 속성은 Max Heap을 생성합니다. 이 기준에 따라 힙은 최대 힙(Max Heap)과 최소 힙(Min Heap)의 두 가지 유형이 될 수 있습니다. 다음은 각각 최대 및 최소
여기서는 바이너리 힙 데이터 구조에서 요소를 삽입하고 삭제하는 방법을 볼 것입니다. 초기 트리가 아래와 같다고 가정 - 삽입 알고리즘 insert(heap, n, item): Begin if heap is full, then exit else n := n + 1 for i := n, i > 1, set i := i / 2 in each iteration, do &nb
그래프가 다양한 변형으로 분류될 수 있다는 것을 알고 있습니다. 그것들은 지시되거나 지시되지 않을 수 있으며 가중치가 있거나 가중치가 없을 수 있습니다. 여기서는 가중 그래프를 메모리에 표시하는 방법을 살펴보겠습니다. 다음 그래프를 고려하십시오 - 인접 행렬 표현 인접행렬 형식을 사용하여 가중치 그래프를 저장하기 위해 행렬을 비용행렬이라고 합니다. 여기서 M[i, j] 위치의 각 셀은 가장자리 i에서 j까지 가중치를 유지합니다. 가장자리가 없으면 무한대가 됩니다. 동일한 노드의 경우 0이 됩니다. 0 ∞ 6 3 ∞ 3 0 ∞
데이터 과학자, 데이터 엔지니어 및 데이터 분석가는 정보 기술 회사의 다양한 직업 프로필입니다. 데이터 과학자 데이터 과학자는 전반적인 기능을 감독하고 감독을 제공하며 정보, 데이터의 미래 지향적인 표시에 중점을 두는 매우 특권적인 직업입니다. 데이터 엔지니어 데이터 엔지니어는 기술 최적화, 필요한 형식으로 데이터 구축 등에 중점을 둡니다. 데이터 분석가 데이터 분석가는 데이터 정리, 원시 데이터 구성, 데이터 시각화 및 데이터의 기술적 분석 제공에 중점을 둡니다. 다음은 데이터 과학자, 데이터 엔지니어 및 데이터 분석가 간의
Inverted Index 및 Forward Index는 문서 또는 문서 세트에서 텍스트를 검색하는 데 사용되는 데이터 구조입니다. 역 인덱스 Inverted Index는 단어를 색인으로 저장하고 문서 이름을 매핑된 참조로 저장합니다. 포워드 인덱스 Forward Index는 문서 이름을 인덱스로, 단어를 매핑된 참조로 저장합니다. 다음은 역지수와 순지수의 중요한 차이점입니다. Sr. 아니요. 키 역 인덱스 앞으로 색인 1 매핑 패턴 역 색인은 단어를 색인으로 저장하고 문서 이름을 매핑된 참조로 저장합니다. 앞으로 색인은 문
EPC(전자 제품 코드)는 가능한 모든 물리적 개체에 고유한 ID를 부여하는 것을 목표로 하는 범용 식별자입니다. EPC는 대부분 인벤토리, 자산, 사람과 같은 개체의 신원을 확인하고 추적하는 데 사용되는 RFID(Radio Frequency Identification) 태그에 인코딩됩니다. EPC는 다른 태그 중에서 특정 태그를 식별하기 위한 RFID 태그와 관련된 96비트 번호입니다. 두 개의 동일한 제품을 구별하고 제품의 제조일자, 원산지 또는 배치 번호도 제공합니다. EPC 구조는 EPCglobal Inc.에서 자유롭게
EPC 또는 전자 제품 코드는 RFID(Radio Frequency Identification) 태그에 인코딩되어 재고, 자산, 사람과 같은 개체의 신원을 확인하고 추적하는 범용 식별자입니다. EPCglobal Tag Data Standard에서 규정한 이 기술의 2세대를 EPC Gen 2라고 합니다. EPC Gen 2의 아키텍처, RFID 네트워크에는 두 가지 주요 구성 요소가 있습니다. 태그 또는 라벨 − 식별하거나 추적할 수 있도록 물체에 부착됩니다. 독자 또는 질문자 − 태그를 추적하는 시스템의 지능적인 부분입니다.
우리가 알고 있듯이 암호화는 송신측과 수신측에서 각각 수행되는 암호화 및 해독이라는 두 가지 프로세스로 구성됩니다. 기본적으로 암호화는 공개 환경에서 발신자와 수신자 간의 안전한 통신을 위해 실행되거나 구현되어 이 두 당사자 외에는 전달되는 메시지를 누구도 얻거나 이해할 수 없습니다. 메시지의 암호화 및 암호 해독 유형에 따라 다음과 같이 고전 및 양자 암호화를 구별할 수 있습니다. - Sr. 아니요. 키 고전적인 암호화 양자 암호화 1 기준 고전 암호학에서는 수학적 계산을 기반으로 암호화 및 암호 해독이 수행됩니다. 반면에
백오프 알고리즘 충돌 해결에 사용되는 알고리즘입니다. 다음과 같이 작동합니다. 이 충돌이 발생하면 두 장치 모두 신호를 다시 재전송하기 전에 임의의 시간 동안 대기하고 데이터가 성공적으로 전송될 때까지 계속 시도합니다. 노드가 다시 액세스를 시도하기 전에 일정 시간 동안 백오프하기 때문에 이를 백오프라고 합니다. 이 임의의 시간은 신호 전송을 시도한 횟수에 정비례합니다. 알고리즘 다음은 백오프 알고리즘을 간략하게 설명하는 간단한 순서도입니다. 알 수 있듯이 N의 각 반복 값이 증가하고 범위 [0,2^n-1]도 증가하므로
일부 알고리즘의 비용을 추정하는 다양한 방법이 있습니다. 작업 수를 사용하여 그 중 하나입니다. 다른 연산 중 하나를 선택하여 알고리즘의 시간 복잡도를 추정할 수 있습니다. 이것들은 더하기, 빼기 등과 같습니다. 이러한 연산이 얼마나 수행되었는지 확인해야 합니다. 이 방법의 성공 여부는 시간 복잡성의 대부분을 차지하는 작업을 식별하는 능력에 달려 있습니다. 크기가 n [0에서 n - 1]인 배열이 있다고 가정합니다. 우리의 알고리즘은 가장 큰 요소의 인덱스를 찾습니다. 배열의 각 요소 쌍 간에 수행되는 비교 작업의 수를 계산하여
알고리즘 분석에서 우리는 작업과 단계를 계산합니다. 이것은 기본적으로 컴퓨터가 해당 작업에 필요한 데이터를 가져오는 데 걸리는 시간보다 작업을 수행하는 데 더 많은 시간이 소요될 때 정당화됩니다. 오늘날 작업 수행 비용은 메모리에서 데이터를 가져오는 비용보다 훨씬 낮습니다. 많은 알고리즘의 실행 시간은 작업 수보다는 메모리 참조 수(캐시 누락 수)에 의해 좌우됩니다. 따라서 일부 알고리즘을 설계하려고 할 때 작업 수뿐만 아니라 메모리 액세스 수를 줄이는 데 집중해야 합니다. 또한 메모리 지연을 숨기는 알고리즘을 설계하는 데 집중해야
알고리즘을 분석하는 동안 몇 가지 반복 관계를 찾습니다. 이러한 반복 관계는 기본적으로 표현식에서 동일한 기능을 사용합니다. 재귀 알고리즘 분석과 분할 정복 알고리즘의 경우 대부분의 경우 재귀 관계를 얻습니다. 여기에서 몇 가지 예의 도움으로 반복 방정식의 한 예를 볼 것입니다. 이진 검색 기술을 사용한다고 가정합니다. 이 기술에서는 요소가 끝에 있는지 여부를 확인합니다. 그것이 중간에 있으면 알고리즘이 종료되고, 그렇지 않으면 실제 배열에서 왼쪽 및 오른쪽 하위 배열을 계속해서 가져옵니다. 따라서 각 단계에서 배열의 크기는 n
여기서 대체 방법을 사용하여 반복 관계를 해결하는 방법을 살펴보겠습니다. 더 나은 방법으로 이해하기 위해 두 가지 예를 들어보겠습니다. 이진 검색 기술을 사용한다고 가정합니다. 이 기술에서는 요소가 끝에 있는지 여부를 확인합니다. 그것이 중간에 있으면 알고리즘이 종료되고, 그렇지 않으면 실제 배열에서 왼쪽 및 오른쪽 하위 배열을 계속해서 가져옵니다. 따라서 각 단계에서 배열의 크기는 n / 2만큼 감소합니다. 이진 검색 알고리즘을 실행하는 데 T(n) 시간이 걸린다고 가정합니다. 기본 조건은 O(1) 시간이 걸립니다. 따라서 재귀
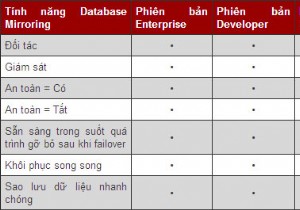
미러링 미러링은 마스터 데이터베이스 서버에 대한 백업 데이터베이스 서버를 유지하는 것을 말합니다. 어떤 이유로 마스터 데이터베이스가 다운된 경우 미러 데이터베이스를 마스터 데이터베이스의 대안으로 사용할 수 있습니다. 원칙적으로 한 번에 하나의 데이터베이스 서버만 활성화되며 데이터베이스에 대한 요청은 활성 상태인 하나의 서버에서만 제공됩니다. 복제 복제는 여러 지리적 위치에 분산된 데이터베이스의 여러 복사본을 유지하는 것을 말합니다. 복제의 전형적인 예는 사용자가 네트워크 지연 및 느린 응답을 피하기 위해 가장 가까운 위치에서 파
선형 데이터 구조 선형 데이터 구조는 데이터 요소가 순차적으로 배열되며 각 요소 요소는 이전 및 다음 요소에 연결됩니다. 이 연결은 단일 수준 및 단일 실행에서 선형 데이터 구조를 탐색하는 데 도움이 됩니다. 이러한 데이터 구조는 컴퓨터 메모리도 순차적이므로 구현하기 쉽습니다. 선형 데이터 구조의 예는 목록, 대기열, 스택, 배열 등입니다. 비선형 데이터 구조 비선형 데이터 구조에는 모든 요소를 연결하는 일련의 설정이 없으며 각 요소는 다른 요소에 연결하기 위해 여러 경로를 가질 수 있습니다. 이러한 데이터 구조는 다중 레벨