
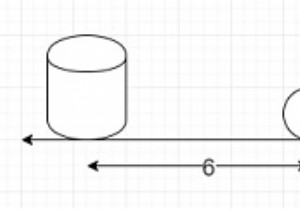

N개의 숫자 목록이 있다고 가정합니다. 나머지 숫자의 GCD가 N개 숫자의 초기 GCD보다 크도록 필요한 숫자 제거의 최소 수를 찾아야 합니다. 3으로 얻을 수 있습니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − INF :=100001 spf :=요소가 0에서 INF인 목록 sieve() 함수 정의 4~INF 범위의 i에 대해 2만큼 증가, do spf[i] :=2 범위 3에서 INF까지의 i에 대해 INF - 중단 spf[i]가 i와 같으면 범위 2 * i에서 INF까지의 j에 대해 i, do로 각 단계
n개의 정수를 가진 배열 arr이 있다고 가정하고 배열에서 arr[i]Carr[j]가 최대한 크도록 arr[i]와 arr[j]를 찾아야 합니다. 한 쌍 이상이면 그 중 하나를 반환하십시오. 따라서 입력이 [4, 1, 2]와 같으면 출력은 4C1 =4, 4C2 =6 및 2C1 =2이므로 4 2가 되므로 (4,2)는 우리가 원하는 대로만 쌍입니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 목록 정렬 N :=v[n - 1] N mod 2가 1과 같으면 첫 번째 :=N / 2(정수 나누기) 두 번째 :=첫 번째 + 1 왼
이진 트리가 있다고 가정합니다. 이 이진 트리에서 최대 전체 하위 트리의 크기를 찾아야 합니다. 우리가 알고 있듯이 모든 레벨이 최종 레벨 없이 완전히 채워지고 최종 레벨에 가능한 모든 키가 남아 있는 경우 완전한 이진 트리는 이진 트리입니다. 따라서 입력이 다음과 같으면 그러면 출력은 크기가 4가 되고 중위 순회는 10, 45, 60, 70,가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − isComplete, isPerfect와 같은 매개변수가 거의 없는 반환 유형을 정의합니다. 초기에는 false이고,
숫자 N이 있다고 가정하고 숫자에서 최소 자릿수(0 가능)를 제거하여 생성할 수 있는 가장 큰 완전 큐브를 결정해야 합니다. 목표에 도달하기 위해 주어진 숫자에서 숫자를 삭제할 수 있습니다. 우리가 알고 있듯이 어떤 정수 M에 대해 N =M^3인 경우 숫자 N을 완전 입방체라고 합니다. 따라서 입력이 806과 같으면 출력은 8이 됩니다. 숫자에서 0과 6을 삭제할 수 있으므로 8을 얻을 수 있습니다. 이것은 2의 완벽한 세제곱입니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − preProcess() 함수를 정의합니다.
이러한 대괄호 (, ), {, }, [ 및 ]를 포함하는 문자열 str이 있다고 가정하고 대괄호가 균형을 이루는지 여부를 확인해야 합니다. 여는 대괄호 유형과 닫는 대괄호 유형이 같은 유형일 때 대괄호가 균형을 이룬다고 말할 수 있습니다. 대괄호는 올바른 순서로 닫힙니다. 따라서 입력이 {([])}와 같으면 출력은 True가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − cnt :=0 i :=0 j :=-1 solve() 함수를 정의합니다. 시간이 걸립니다. cnt :=cnt - 1 s :=s의 새 목록 -1이
Red-Black Tree가 있다고 가정합니다. 여기에서 노드의 가장 큰 높이는 최소 높이의 기껏해야 두 배입니다. 이진 탐색 트리가 있는 경우 다음 속성을 확인해야 합니다. 모든 노드와 관련하여 가장 긴 리프에서 노드까지의 경로 길이는 노드에서 리프까지의 최단 경로에서 노드의 두 배 이하입니다. 따라서 입력이 다음과 같으면 균형이 잡혀 있으므로 출력은 True가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − solve() 함수를 정의합니다. 이것은 root, max_height, min_height를 취합
이진 트리가 있다고 가정합니다. 힙인지 아닌지 확인해야 합니다. 힙에는 다음과 같은 속성이 있습니다. 힙은 이진 트리가 됩니다. 해당 트리는 완전한 트리여야 합니다(그래서 마지막을 제외한 모든 수준은 가득 차 있어야 함). 해당 트리의 모든 노드 값은 자식 노드(최대 힙)보다 크거나 같아야 합니다. 따라서 입력이 다음과 같으면 그러면 출력이 true가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − number_of_nodes() 함수를 정의합니다. 이것은 뿌리를 내릴 것입니다 루트가 null이면 0을 반환
숫자와 소수점을 포함하는 문자열이 있다고 가정하고 해당 문자열이 숫자를 나타내는지 여부를 확인해야 합니다. 입력이 2.5와 같으면 출력이 true이고 입력이 xyz와 같으면 출력이 false가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 이 문제를 해결하기 위해 프로그래밍 언어의 문자열 구문 분석 기술을 사용합니다. 문자열을 숫자로 변환하려고 시도합니다. 예외가 없으면 숫자가 되고 그렇지 않으면 숫자가 아닙니다. 예 이해를 돕기 위해 다음 구현을 살펴보겠습니다. − def isNumeric(s):
N개의 요소가 있는 배열 A가 있고 또 다른 값 p와 세그먼트 크기 k가 있다고 가정합니다. 키 p가 A의 크기 k인 모든 세그먼트에 있는지 확인해야 합니다. 따라서 입력이 A =[4, 6, 3, 5, 10, 4, 2, 8, 4, 12, 13, 4], p =4 및 k =3과 같으면 출력은 True 이 문제를 해결하기 위해 다음 단계를 따릅니다. − i :=0 i
체스와 같은 규칙을 가진 무한체스판이 하나 있고 무한체스판에 N개의 기사좌표와 왕좌표가 있다면 왕이 체크메이트인지 아닌지를 확인해야 한다. 무한판의 좌표는 (-10^9 <=x, y <=10^9)와 같이 큰 값으로 경계가 지정됩니다. 따라서 입력이 기사 위치 =[[2,1],[1,3],[3,6],[5,5],[6,1],[7,3]] 및 왕 위치와 같으면 :[4,3], 킹은 이동이 없으므로 출력은 True가 됩니다. 따라서 체크 메이트입니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − my_dict :=새 지도 0에서 n
숫자 n이 있다고 가정하면 n이 트로이 목마 번호인지 여부를 확인해야 합니다. 알다시피 트로이 목마는 완전수가 없는 강한 숫자입니다. 모든 소수 또는 n의 인수 p에 대해 p^2도 제수일 때 숫자 n은 강한 숫자입니다. 즉, 모든 소인수는 적어도 두 번 나타납니다. 트로이 목마는 강력합니다. 그러나 그 반대는 사실이 아닙니다. 따라서 모든 강력한 숫자가 트로이 숫자가 아니라 ^b로 표시될 수 없는 숫자만 의미합니다. 따라서 입력이 72와 같으면 72가 (6*6*2) =(6^2 * 2)로 표시될 수 있으므로 출력은 True가 됩니다
숫자 n이 있다고 가정합니다. n이 아킬레스 수인지 아닌지 확인해야 합니다. 우리가 알고 있듯이 숫자는 강력한 숫자일 때 아킬레스 수입니다(수 N은 모든 소인수 p에 대해 p^2도 나눌 때 강력한 숫자라고 함). 그러나 완전한 거듭제곱은 아닙니다. 아킬레스 수의 몇 가지 예는 다음과 같습니다:72, 108, 200, 288, 392, 432, 500, 648, 675, 800, 864, 968, 972, 1125. 따라서 입력이 108과 같으면 6과 36이 모두 나누기 때문에 완전제곱수가 아니기 때문에 출력은 True가 됩니다.
숫자 n이 있다고 가정하면 n이 원시 소수인지 여부를 확인해야 합니다. 숫자는 pN# + 1 또는 pN# – 1 형식의 소수일 때 원시 소수라고 합니다. 여기서 pN#은 처음 N 소수의 곱이 되는 pN의 원시를 나타냅니다. 따라서 입력이 29와 같으면 29가 N=3인 경우 pN - 1 형식의 원시 소수이고 원시가 2*3*5 =30이고 30-1 =29이므로 출력은 True가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 최대 :=100000 prime :=크기가 MAX이고 True로 채워진 목록 arr :=새 목록
이 섹션에서는 C++ STL에 있는 힙 데이터 구조를 볼 것입니다. 이것은 힙에 더 빠른 입력을 허용하고 숫자를 검색하면 항상 가장 큰 숫자가 나옵니다. 즉, 매번 나머지 숫자 중 가장 큰 숫자가 튀어 나옵니다. 힙의 다른 요소는 구현에 따라 정렬됩니다. 힙 작업은 다음과 같습니다 - make_heap() − 이것은 컨테이너의 범위를 힙으로 변환합니다. 앞() − 힙의 가장 큰 숫자인 첫 번째 요소를 반환합니다. 예 이해를 돕기 위해 다음 구현을 살펴보겠습니다. − #include<bits/stdc++.h>
이진 검색 트리의 후위 순회 시퀀스가 있다고 가정합니다. 이 시퀀스에서 트리를 생성해야 합니다. 따라서 후위 순서가 [9,15,7,20,3]이면 트리는 -가 됩니다. 트리를 형성하려면 중위 순회도 필요하지만 이진 탐색 트리의 경우 중위 순회는 정렬된 형식이 됩니다. 단계를 살펴보겠습니다 - Inorder =postorder 순회 정렬된 목록입니다. build_tree() 메서드를 정의하면 순서가 뒤바뀔 것입니다. - 중위 목록이 비어 있지 않은 경우 - root :=postorder의 마지막 값으로
이진 트리의 중위 및 후위 순회 시퀀스가 있다고 가정합니다. 이 시퀀스에서 트리를 생성해야 합니다. 따라서 후위 및 중위 시퀀스가 [9,15,7,20,3] 및 [9,3,15,20,7]이면 트리는 - 단계를 살펴보겠습니다 - build_tree() 메서드를 정의하면 순서가 뒤바뀔 것입니다. - 중위 목록이 비어 있지 않은 경우 - root :=postorder의 마지막 값으로 트리 노드를 만든 다음 해당 요소를 삭제합니다. ind :=inorder 목록의 루트 데이터 인덱스 root의 오른쪽 :
이진 검색 트리에 대한 하나의 후위 순회가 있다고 가정합니다. 여기서 바이너리 검색 트리를 찾아야 합니다. 따라서 입력이 [6, 12, 10, 55, 45, 15]와 같으면 출력은 이 문제를 해결하기 위해 다음 단계를 따릅니다. − solve() 함수를 정의합니다. 우편 주문이 필요합니다 n :=포스트오더의 크기 root :=postorder의 마지막 요소로 새 트리 노드 만들기 stk :=스택 stk에 루트 삽입 나는 :=n - 2 =0인 동안 수행 x :=값이 postorder[i
여기서 문자열 유형 데이터를 사용하여 pandas 데이터 프레임을 구성하는 방법을 살펴보겠습니다. Pandas는 csv 파일을 지원하지만 string을 사용하여 동일한 작업을 수행할 수도 있습니다. 문자열 유형 데이터의 경우 데이터를 csv 리더로 사용할 때 시뮬레이션하는 데 도움이 되는 하나의 래퍼를 사용해야 합니다. 여기에서는 데이터를 가져오고 세미콜론으로 구분된 문자열을 사용하고 있습니다. 예 더 나은 이해를 위해 다음 구현을 살펴보겠습니다. − import pandas as pd from io import StringIO
하나의 크기 변수 N이 있다고 가정하고, 하나의 변수 SUM도 있다고 가정합니다. 이것은 배열에서 사용 가능한 모든 요소의 총합이고 배열에 요소가 없는 다른 변수 K는 다음과 같습니다. K보다 크면 배열의 모든 요소가 구별되는 하나의 직교 배열을 찾아야 합니다. 솔루션이 없으면 -1을 반환합니다. 따라서 입력이 N =4, SUM =16 K =9와 같으면 출력은 [1,2,4,9]가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − minimum_sum :=(N *(N + 1)) / 2 maximum_sum :
두 개의 정렬된 연결 목록이 있다고 가정하면 시작 노드에서 끝 노드까지의 최대 합 경로로 구성된 연결 목록을 만들어야 합니다. 최종 목록은 두 입력 목록의 노드로 구성될 수 있습니다. 결과 목록을 생성할 때 교차점(목록에서 동일한 값을 갖는 두 노드)에 대해서만 다른 입력 목록으로 전환할 수 있습니다. 일정한 양의 추가 공간을 사용하여 해결해야 합니다. 따라서 입력이 [6,8,35,95,115,125], [5,8,17,37,95,105,125,135]와 같으면 출력은 [6,8,17,37,95,115,125,135]가 됩니다.