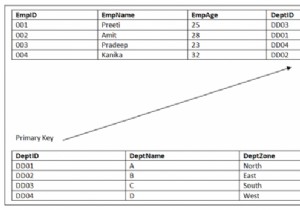


가격이라고 하는 숫자 목록이 있고 시간순으로 회사의 주가를 나타내는 목록이 있다고 가정하면 해당 주식을 최대 2번 사고팔 때 얻을 수 있는 최대 이익을 찾아야 합니다. 먼저 사서 팔아야 합니다. 따라서 입력이 가격 =[2, 6, 3, 4, 2, 9]와 같으면 출력은 11이 됩니다. 가격 2에서 구매한 다음 6에서 판매하고 다시 2에서 구매하고 판매할 수 있기 때문입니다. 9시에. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − first_buy :=-inf, first_sell :=-inf second_buy :=-inf,
숫자 num과 다른 값 k의 목록이 있다고 가정합니다. 여기서 nums[i]의 항목은 지수 i에 도달하는 비용을 나타냅니다. 인덱스 0에서 시작하여 nums의 마지막 인덱스에서 끝나는 경우. 각 단계에서 우리는 위치 X에서 최대 k 단계 떨어진 위치로 이동할 수 있습니다. 마지막 인덱스에 도달하려면 비용 합계를 최소화해야 하므로 최소 합계는 얼마가 될까요? 따라서 입력이 nums =[2, 3, 4, 5, 6] k =2와 같으면 출력은 12가 됩니다. 2 + 4 + 6을 선택하여 최소 비용 12를 얻을 수 있기 때문입니다. 이 문
회사의 주가를 시간순으로 나타내는 nums라는 숫자 목록이 있고 또 다른 값 k가 있다고 가정하면 최대 k개의 매매로 얻을 수 있는 최대 이익을 찾아야 합니다. 매도 전, 매수 전 매도). 따라서 입력이 가격 =[7, 3, 5, 2, 3] k =2와 같으면 출력은 3이 됩니다. 3에서 구매한 다음 5에서 판매하고 2에서 다시 구매하고 판매할 수 있기 때문입니다. 3시에. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − dp() 함수를 정의합니다. 이것은 i, k, 샀습니다 i가 가격의 크기와 같거나 k가 0과 같으면 0을
(+, -, *, /)를 사용하여 수학 표현식을 나타내는 문자열이 있다고 가정합니다. 여기서 /는 정수 나누기를 나타내며 내장 함수를 사용하지 않고 결과를 평가하고 반환해야 합니다. 따라서 입력이 s =2+3*5/7과 같으면 출력은 2 + ((3 * 5) / 7) =4와 같이 4가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − :=주어진 문자열을 뒤집습니다. get_value() 함수를 정의합니다. 기호 :=1 s가 비어 있지 않고 s의 마지막 요소가 -와 같으면 s에서 마지막 요소 삭제 기호 :=-1 값:
각 행에 세 개의 필드[src, dest, id]가 포함된 n x 3 행렬이 있다고 가정합니다. 이는 버스에 src에서 dest까지의 경로가 있음을 의미합니다. 새 버스를 타려면 한 단위의 돈이 필요하지만 같은 버스에 계속 있으면 한 단위만 지불하면 됩니다. 0번 위치에서 종점(가장 큰 위치)까지 버스를 타는 데 필요한 최소 비용을 찾아야 합니다. 솔루션이 없으면 -1을 반환합니다. 따라서 입력이 다음과 같으면 0 1 0 1 2 0 2 3 0 3 5 1 5 0 2
0이 빈 셀이고 1이 차단된 셀인 N x N 이진 행렬이 있다고 가정하면 모든 행과 모든 열에 최소한 하나의 선택된 셀이 있도록 N개의 빈 셀을 선택하는 방법의 수를 찾아야 합니다. 대답이 매우 크면 결과 모드 10^9 + 7을 반환합니다. 따라서 입력이 다음과 같으면 0 0 0 0 0 0 0 1 0 다음 구성이 있으므로 출력은 4가 됩니다(여기서 x는 선택된 셀) - 이 문제를 해결하기 위해 다음 단계를 따릅니다. − n :=행렬의 크기 f() 함수를 정의합니다. I, bs =n
nums라는 숫자 목록이 있다고 가정하고 가장 길게 증가하는 부분 수열의 길이를 찾아야 하고 부분 수열이 목록의 시작 부분으로 줄바꿈할 수 있다고 가정합니다. 따라서 입력이 nums =[6, 5, 8, 2, 3, 4]와 같으면 가장 긴 증가 부분 시퀀스가 [2, 3, 4, 6, 8]이므로 출력은 5가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − a :=숫자의 두 배 크기 목록을 만들고 숫자를 두 번 채우기 ans :=0 0~숫자 크기 범위의 i에 대해 dp :=새 목록 i 범위에서 nums + i - 1의
폴리곤을 나타내는 데카르트 포인트 목록 [(x1, y1), (x2, y2), ..., (xn, yn)]이 있고 두 개의 값 x와 y가 있다고 가정하면 다음을 수행해야 합니다. (x, y)가 이 다각형 내부에 있는지 또는 경계에 있는지 확인하십시오. 따라서 입력이 점 =[(0, 0), (1, 3), (4, 4), (6, 2), (4, 0)] pt =(3, 1) 그러면 출력은 True가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − ans :=거짓 범위 0에서 다각형 크기 - 1에 있는 i에 대해 (x0, y
nums라고 하는 숫자 목록과 다른 값 k가 있다고 가정하면 목록에서 k가 되는 부분 집합의 수를 찾아야 합니다. 답이 매우 크면 이것을 10^9 + 7로 수정하십시오. 따라서 입력이 nums =[2, 3, 4, 5, 7] k =7과 같으면 하위 집합 [2,5],[3,4] 및 [ 7]. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − dp :=크기 목록(k + 1) 및 0으로 채우기 dp[0] :=1 m :=10^9 + 7 0부터 숫자 - 1까지의 범위에 있는 i에 대해 k 범위에서 0까지의 j에 대해 1만큼 감소, do
N개의 노드와 N-1개의 가장자리가 있는 트리로 표현되는 국가를 고려하십시오. 이제 각 노드는 마을을 나타내고 각 가장자리는 도로를 나타냅니다. N-1 크기의 소스와 목적지의 두 가지 숫자 목록이 있습니다. 그들에 따르면 i 번째 도로는 소스[i]와 목적지[i]를 연결합니다. 그리고 도로는 양방향입니다. 또한 크기 N의 인구라고 하는 또 다른 숫자 목록이 있습니다. 여기서 인구[i]는 i번째 마을의 인구를 나타냅니다. 우리는 몇몇 마을을 도시로 업그레이드하려고 합니다. 그러나 두 도시는 서로 인접해서는 안 되며 마을에 인접한 모든
문자열 s가 있다고 가정하고 최대 k개의 문자를 삭제한 후 이 문자열을 회문으로 만들 수 있는지 여부를 확인해야 합니다. 따라서 입력이 s =lieuvrel, k =4와 같으면 출력은 True가 되고 3개의 문자를 삭제하여 회문 레벨을 얻을 수 있습니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − lcs() 함수를 정의합니다. , b m :=크기, n :=b 크기 table :=크기(m + 1) x (n + 1)의 행렬이고 0으로 채움 1~m 범위의 i에 대해 다음을 수행합니다. 1~n 범위의 j에 대해 다음을 수행합
이진 행렬과 다른 값 k가 있다고 가정합니다. 각 조각에 적어도 하나의 1이 포함되도록 행렬을 k 조각으로 분할하려고 합니다. 그러나 자르기에는 몇 가지 규칙이 있으므로 순서대로 따라야 합니다. 1. 방향 선택:수직 또는 수평 2. 행렬에서 인덱스를 선택하여 두 섹션으로 자르십시오. 3. 세로로 자르면 더 이상 왼쪽 부분을 자를 수 없고 오른쪽 부분만 계속 자를 수 있습니다. 4. 수평으로 자르면 더 이상 상단 부분을자를 수없고 하단 부분만 계속자를 수 있습니다. 따라서 행렬을 나누는 다양한 방법을 찾아야 합니다. 답변이 매우 크면
2차원 행렬이 있다고 가정합니다. 어떤 셀에서 시작하여 같은 값의 인접한 셀(위, 아래, 왼쪽, 오른쪽)을 이동하고 같은 시작점으로 돌아올 수 있는지 확인해야 합니다. 마지막으로 방문한 셀은 다시 방문할 수 없습니다. 따라서 입력이 다음과 같으면 2 2 2 1 2 1 2 1 2 2 2 1 그러면 2초를 따라 주기를 형성할 수 있으므로 출력은 True가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − R :=행렬의 행 수 C :=행렬의 열 개수 vis :=R x
각 목록에 [uid, time_sec]와 같은 요소가 포함된 요청 목록이 있다고 가정합니다(uid는 사용자 ID이고 time_sec는 타임스탬프입니다). 이것은 id가 uid인 사용자가 timestamp time_sec에 웹사이트에 요청했음을 나타냅니다. 우리는 또한 두 개의 값 u와 g가 있습니다. 여기서 u는 주어진 uid에 대해 60초 미만 프레임에서 허용되는 최대 요청 수를 나타내고 g는 전역적으로 60초 미만 프레임에서 허용되는 최대 요청 수를 나타냅니다. 이제 각 요청을 하나씩 처리하고 속도를 제한하려는 경우입니다. 그리
Numpy 배열을 사용하여 시리즈 데이터 구조를 만들고 색인에 대한 값을 명시적으로 제공하는 방법을 살펴보겠습니다. 인덱스에 값을 지정하지 않으면 계열의 값에 0부터 시작하는 기본값이 할당됩니다. 다음은 예입니다 - 예시 import pandas as pd import numpy as np my_data = np.array(['ab','bc','cd','de', 'ef', 'fg','gh', 'hi']) my_ind
데이터 시각화는 실제로 숫자를 보고 복잡한 계산을 수행하지 않고도 데이터에서 무슨 일이 일어나고 있는지 이해하는 데 도움이 되기 때문에 중요한 단계입니다. Seaborn은 데이터 시각화에 도움이 되는 라이브러리입니다. 산점도는 데이터의 분포를 그래프에 분산/산포된 데이터 포인트로 표시합니다. 점을 사용하여 본질적으로 숫자인 데이터 세트의 값을 나타냅니다. 가로 및 세로 축에서 모든 점의 위치는 단일 데이터 포인트에 대한 값을 나타냅니다. 두 변수 간의 관계를 이해하는 데 도움이 됩니다. Python에서 Seaborn 라이브러리를
스칼라 또는 상수 값은 한 번 정의되며 계열 데이터 구조의 모든 행/항목에서 반복됩니다. 다음은 예입니다 - 예시 import pandas as pd my_index = ['ab', 'mn' ,'gh','kl'] my_series = pd.Series(7, index = my_index) print("This is series data structure created using scalar values and specifying index values") p
Series에서 기본값이 인덱스 값으로 사용되는 경우 인덱싱을 사용하여 액세스할 수 있습니다. 인덱스 값을 사용자 정의하면 인덱스 값으로 전달되어 콘솔에 표시됩니다. 예시를 통해 이해해 봅시다. 예 import pandas as pd my_data = [34, 56, 78, 90, 123, 45] my_index = ['ab', 'mn' ,'gh','kl', 'wq', 'az'] my_series = pd.Series(my_data, index
인덱스 값을 사용자 정의할 때 series_name[index_value]을 사용하여 액세스합니다. . index_value 시리즈로 전달된 것은 원래 시리즈와 일치시키려고 시도합니다. 발견되면 해당 데이터도 콘솔에 표시됩니다. 여러 요소를 표시하는 방법을 살펴보겠습니다. 예시 import pandas as pd my_data = [34, 56, 78, 90, 123, 45] my_index = ['ab', 'mn' ,'gh','kl', 'wq', '
인덱스 값을 사용자 정의할 때 series_name[index_value]을 사용하여 액세스합니다. . index_value 시리즈로 전달된 것은 원래 시리즈와 일치시키려고 시도합니다. 발견되면 해당 데이터도 콘솔에 표시됩니다. 액세스하려는 인덱스가 시리즈에 없으면 오류가 발생합니다. 아래에 표시되었습니다. 예시 import pandas as pd my_data = [34, 56, 78, 90, 123, 45] my_index = ['ab', 'mn' ,'gh','kl',