
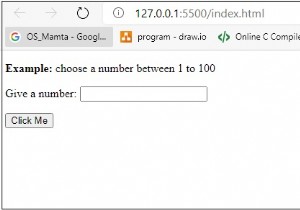

Dataframe은 데이터가 행과 열의 형태로 표 형식으로 저장되는 2차원 데이터 구조입니다. SQL 데이터 테이블이나 엑셀 시트 표현으로 시각화할 수 있습니다. 다음 생성자를 사용하여 생성할 수 있습니다. - pd.Dataframe(데이터, 인덱스, 열, dtype, 복사) data, index, columns, dtype 및 copy는 필수 값이 아닙니다. 사전 목록을 데이터 프레임에 대한 입력으로 전달할 수 있습니다. 사전의 키는 기본적으로 열 이름으로 사용됩니다. 예를 들어 보겠습니다 - 예시 판다를 pdmy_data
Dataframe은 데이터가 행과 열의 형태로 표 형식으로 저장되는 2차원 데이터 구조입니다. SQL 데이터 테이블 또는 Excel 시트 표현으로 시각화할 수 있습니다. 다음 생성자를 사용하여 생성할 수 있습니다. - pd.Dataframe(data, index, columns, dtype, copy) 다른 방법으로 데이터 프레임에 새 열을 추가할 수 있습니다. 먼저 계열 데이터 구조를 만들고 이를 기존 데이터 프레임에 추가 열로 전달하여 새 열을 만드는 방법 중 하나를 살펴보겠습니다. 코드가 실행되는 것을 봅시다 - 예시
Dataframe은 데이터가 행과 열의 형태로 표 형식으로 저장되는 2차원 데이터 구조입니다. SQL 데이터 테이블 또는 Excel 시트 표현으로 시각화할 수 있습니다. 다음 생성자를 사용하여 생성할 수 있습니다. - pd.Dataframe(data, index, columns, dtype, copy) Series 사전을 사용하여 데이터 프레임을 생성하는 방법을 이해합시다. Series는 Pandas 라이브러리에 있는 1차원 데이터 구조입니다. 축 레이블을 총칭하여 인덱스라고 합니다. 시리즈 구조는 정수, 부동
Dataframe은 데이터가 행과 열의 형태로 표 형식으로 저장되는 2차원 데이터 구조입니다. SQL 데이터 테이블 또는 Excel 시트 표현으로 시각화할 수 있습니다. 데이터 프레임의 열은 다른 방법을 사용하여 삭제할 수 있습니다. 삭제해야 하는 열의 이름을 매개변수로 받아 삭제하는 del 연산자를 볼 수 있습니다. − 예시 판다를 pdmy_data ={ab로 가져오기 :pd.Series([1, 8, 7], index=[a, b, c]),cd :pd.Series( [1, 2, 0, 9], 인덱스=[a, b, c, d]),ef
데이터 시각화는 실제로 숫자를 보고 복잡한 계산을 수행하지 않고도 데이터에서 무슨 일이 일어나고 있는지 이해하는 데 도움이 되기 때문에 중요한 단계입니다. 청중에게 정량적 통찰력을 효과적으로 전달하는 데 도움이 됩니다. Seaborn은 데이터 시각화에 도움이 되는 라이브러리입니다. 맞춤형 테마와 고급 인터페이스가 함께 제공됩니다. Python에서 히스토그램을 표시하는 예를 살펴보겠습니다. 예시 import pandas as pd import seaborn as sb from matplotlib import pyplot as p
Dataframe은 데이터가 행과 열의 형태로 표 형식으로 저장되는 2차원 데이터 구조입니다. SQL 데이터 테이블 또는 Excel 시트 표현으로 시각화할 수 있습니다. 데이터 프레임의 열은 다른 방법을 사용하여 삭제할 수 있습니다. 삭제해야 할 컬럼의 이름을 매개변수로 받아 삭제하는 pop 함수를 볼 수 있습니다. 예 판다를 pdmy_data ={ab로 가져오기 :pd.Series([1, 8, 7], index=[a, b, c]),cd :pd.Series( [1, 2, 0, 9], 인덱스=[a, b, c, d]),ef :pd.
경우에 따라 특정 열의 합계를 가져와야 할 수도 있습니다. 여기서 sum 함수를 사용할 수 있습니다. 합계를 계산해야 하는 열은 합계 함수에 값으로 전달할 수 있습니다. 열의 인덱스를 전달하여 합계를 찾을 수도 있습니다. 동일한 시연을 봅시다 - 예시 판다를 pdmy_data로 가져오기 ={이름:pd.Series([Tom,Jane,Vin,Eve,Will]),Age:pd.Series([45 , 67, 89, 12, 23]),값:pd.Series([8.79,23.24,31.98,78.56,90.20])}print(데이터 프레임은 다
Dataframe은 데이터가 행과 열의 형태로 표 형식으로 저장되는 2차원 데이터 구조입니다. SQL 데이터 테이블이나 엑셀 시트 표현으로 시각화할 수 있습니다. 다음 생성자를 사용하여 생성할 수 있습니다. - pd.Dataframe(data, index, columns, dtype, copy) 이전에 Series 데이터 구조로 새 열을 생성하는 방법을 보았습니다. 이것은 원래 데이터 프레임에 인덱싱되어 데이터 프레임에 추가되었습니다. 데이터 프레임의 이미 존재하는 열을 사용하여 열을 만드는 방법을 사용하겠습니다. 이것은 이미
경우에 따라 특정 열의 평균 값이나 숫자 값이 포함된 모든 열의 평균 값을 가져와야 할 수도 있습니다. 여기에서 mean() 함수를 사용할 수 있습니다. 평균이라는 용어는 모든 값의 합을 구하여 데이터 세트의 총 값 수로 나누는 것을 의미합니다. 동일한 시연을 봅시다 - 예 import pandas as pd my_data = {'Name':pd.Series(['Tom','Jane','Vin','Eve','Will']), 'Age'
데이터 전처리는 기본적으로 모든 데이터(다양한 리소스 또는 단일 리소스에서 수집됨)를 공통 형식 또는 단일 데이터 세트(데이터 유형에 따라 다름)로 수집하는 작업을 의미합니다. 실제 데이터는 결코 이상적이지 않으므로 데이터에 누락된 셀, 오류, 이상값, 열 불일치 등이 있을 가능성이 있습니다. 경우에 따라 이미지가 올바르게 정렬되지 않거나 선명하지 않거나 크기가 매우 클 수 있습니다. 전처리의 목표는 이러한 불일치와 오류를 제거하는 것입니다. 이미지의 해상도를 얻기 위해 shape라는 내장 함수가 사용됩니다. 이미지를 읽은 후 픽
데이터 전처리는 기본적으로 모든 데이터(다양한 리소스 또는 단일 리소스에서 수집됨)를 공통 형식 또는 단일 데이터 세트(데이터 유형에 따라 다름)로 수집하는 작업을 말합니다. 실제 데이터는 결코 이상적이지 않으므로 데이터에 누락된 셀, 오류, 이상값, 열 불일치 등이 있을 가능성이 있습니다. 경우에 따라 이미지가 올바르게 정렬되지 않거나 선명하지 않거나 크기가 매우 클 수 있습니다. 전처리의 목표는 이러한 불일치와 오류를 제거하는 것입니다. 이미지의 픽셀을 가져오기 위해 flatten이라는 내장 함수가 사용됩니다. 이미지를 읽
일반적으로 sklearn으로 알려진 Scikit-learn은 기계 학습 알고리즘을 구현하기 위해 사용되는 Python 라이브러리입니다. 오픈 소스 라이브러리이므로 무료로 사용할 수 있습니다. 이 라이브러리는 Numpy, SciPy 및 Matplotlib 라이브러리를 기반으로 합니다. 행진 사각형 방법은 이미지에서 윤곽선을 찾는 데 사용됩니다. skimage 라이브러리의 measure 클래스에 있는 find_contours 함수를 사용합니다. 여기서 배열에 있는 값은 선형 방식으로 보간됩니다. 이렇게 하면 출력 이미지의 윤곽 정밀
NumPy는 숫자 파이썬을 나타냅니다. 다차원 배열 개체와 배열 처리에 도움이 되는 여러 메서드가 포함된 라이브러리입니다. NumPy는 배열에서 다양한 작업을 수행하는 데 사용할 수 있습니다. SciPy, Matplotlib 등과 같은 패키지와 함께 사용됩니다. NumPy+Matplotlib는 MatLab의 대안으로 이해할 수 있습니다. 누구나 사용할 수 있는 오픈 소스 패키지입니다. NumPy 패키지에 존재하는 가장 중요한 객체는 ndarray로 알려진 n차원 배열입니다. 동일한 유형의 항목 모음을 정의합니다. ndarray 내
의사 결정 트리는 랜덤 포레스트 알고리즘의 기본 빌딩 블록입니다. 기계 학습에서 가장 널리 사용되는 알고리즘 중 하나로 간주되며 분류 목적으로 사용됩니다. 그들은 이해하기 쉽기 때문에 매우 인기가 있습니다. 의사 결정 트리에서 내린 결정은 특정 예측이 이루어진 이유를 설명하는 데 사용할 수 있습니다. 이것은 프로세스의 안팎이 사용자에게 명확하다는 것을 의미합니다. 또한 배깅, 랜덤 포레스트 및 그래디언트 부스팅과 같은 앙상블 방법의 기초입니다. 분류 및 회귀 트리, 즉 CART라고도 합니다. 이진 트리(데이터 구조 및 알고리즘에서
때로는 본질적으로 숫자인 특정 열의 평균 값을 가져와야 할 수도 있습니다. 여기서 mean 함수를 사용할 수 있습니다. 평균을 계산해야 하는 열은 데이터 프레임에 인덱싱될 수 있으며, 여기서 점 연산자를 사용하여 평균 함수를 호출할 수 있습니다. 평균을 찾기 위해 열의 인덱스를 전달할 수도 있습니다. mean()이라는 용어는 모든 값의 합을 찾아 데이터 세트의 총 값 수로 나누는 것을 말합니다. 동일한 시연을 봅시다 - 예시 import pandas as pd my_data = {'Name':pd.Series([
표준 편차는 데이터 세트의 값이 분산되는 방식을 알려줍니다. 또한 데이터 세트의 값이 데이터 세트의 열 산술 평균에서 얼마나 멀리 떨어져 있는지 알려줍니다. 때로는 본질적으로 숫자인 특정 열의 표준 편차를 가져와야 할 수도 있습니다. 여기서 std() 함수를 사용할 수 있습니다. 평균을 계산해야 하는 열은 데이터 프레임에 인덱싱될 수 있으며, 여기서 점 연산자를 사용하여 평균 함수를 호출할 수 있습니다. 표준편차를 찾기 위해 컬럼의 인덱스를 전달할 수도 있습니다. 동일한 시연을 봅시다 - 예시 판다를 pdmy_data로 가져오
데이터에 대한 다양한 기능을 사용하여 데이터에 대한 많은 정보를 얻을 수 있습니다. 그러나 데이터에 대한 모든 정보를 얻고 싶다면 설명 기능을 사용할 수 있습니다. 이 함수는 개수, 평균, 표준편차, 25번째 백분위수, 50번째 백분위수 및 75번째 백분위수와 같은 정보를 제공합니다. 예 import pandas as pd my_data = {'Name':pd.Series(['Tom','Jane','Vin','Eve','Will']), '
데이터 프레임의 축을 따라 특정 기능을 적용해야 하는 경우가 있습니다. 축을 지정할 수 있습니다. 그렇지 않으면 기본 축이 열 단위로 간주되고 모든 열이 배열로 간주됩니다. 축이 지정되면 데이터에 대해 행 단위로 작업이 수행됩니다. 적용 기능은 데이터 프레임의 점 연산자와 함께 사용할 수 있습니다. 예를 들어 보겠습니다 - 예시 import pandas as pd import numpy as np my_data = {'Age':pd.Series([45, 67, 89, 12, 23]),'value':p
데이터 프레임의 요소를 따라 특정 기능을 적용해야 하는 경우가 있습니다. 모든 기능을 벡터화할 수 없습니다. 여기서 applymap 기능이 등장합니다. 단일 값을 입력으로 사용하고 단일 값을 출력으로 반환합니다. 예시 판다를 pdimport numpy로 npmy_df =pd.DataFrame(np.random.randn(5,5),columns=[col_1,col_2,col_3, col_4, col_5])으로 가져오기 print(생성된 데이터 프레임은 )print(my_df)my_df.applymap(lambda x:x*11.45)
데이터 전처리는 데이터 정리, 유효하지 않은 데이터 제거, 노이즈 제거, 데이터를 관련 값으로 교체하는 등의 작업을 의미합니다. 이것이 항상 텍스트 데이터를 의미하는 것은 아닙니다. 또한 이미지 또는 비디오 처리도 가능합니다. 이는 머신 러닝 파이프라인에서 중요한 단계입니다. 데이터 전처리는 기본적으로 모든 데이터(다양한 리소스 또는 단일 리소스에서 수집됨)를 공통 형식 또는 단일 데이터 세트(데이터 유형에 따라 다름)로 수집하는 작업을 말합니다. 이는 학습 알고리즘이 이 데이터 세트에서 학습하고 높은 정확도로 관련 결과를 제