


문자열에 존재하는 단어와 문자의 수를 계산해야 하는 경우, 아래는 동일한 데모입니다. 예시 my_string = "Hi there, how are you Will ? " print("The string is :") print(my_string) my_chars=0 my_words=1 for i in my_string: my_chars=my_chars+1 if(i==' '): my_words=my_w
순서 순회를 사용하여 트리에서 가장 큰 값을 찾아야 할 때 루트 요소를 설정하는 메서드로 이진 트리 클래스를 만들고 재귀를 사용하여 순서 순회를 수행하는 등의 방법을 사용합니다. 클래스의 인스턴스가 생성되고 메서드에 액세스하는 데 사용할 수 있습니다. 아래는 동일한 데모입니다 - 예시 class BinaryTree_Struct: def __init__(self, key=None): self.key = key self.left = N
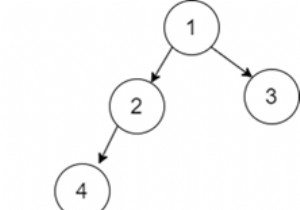
후위 순회를 이용하여 깊이 우선 탐색을 구현해야 하는 경우 요소 추가, 특정 요소 검색, 후위 순회 등을 수행하는 메소드로 트리 클래스가 생성됩니다. 클래스의 인스턴스가 생성되고 메서드에 액세스하는 데 사용할 수 있습니다. 아래는 동일한 데모입니다 - 예시 class Tree_Struct:def __init__(self, key=None):self.key =key self.children =[] def add_elem(self, node):self.children.append(node) def search_elem(self, ke
트리의 미러 복사본을 만들고 너비 우선 검색을 사용하여 표시해야 하는 경우 루트 요소를 설정하고, 요소를 왼쪽에 삽입하고, 요소를 오른쪽에 삽입하고, 특정 요소를 검색하고, 주문 후 순회 등을 수행합니다. 클래스의 인스턴스가 생성되고 메서드에 액세스하는 데 사용할 수 있습니다. 아래는 동일한 데모입니다 - 예 class BinaryTree_struct:def __init__(self, key=None):self.key =key self.left =None self.right =None def set_root(self, key):s
두 개의 문자열을 가져와서 내장 함수를 사용하지 않고 더 큰 문자열을 표시해야 하는 경우 간단한 반복과 == 연산자를 사용할 수 있습니다. 아래는 동일한 데모입니다 - 예 string_1 = "Malala" string_2 = "Male" count_1 = 0 count_2 = 0 print("The first string is :") print(string_1) print("The second string is :") print(string_2) for i
문자열의 소문자 수를 계산해야 하는 경우 문자열을 반복할 수 있습니다. 소문자인지 확인이 가능하며, 카운터를 증가시킬 수 있습니다. 아래는 동일한 데모입니다 - 예시 my_string = "Hi there how are you" print("The string is :") print(my_string) my_counter=0 for i in my_string: if(i.islower()): my_counter=my_counter+1 p
주어진 문자열의 처음 두 문자와 마지막 두 문자로 새로운 문자열을 구성해야 하는 경우 카운터를 정의할 수 있으며 인덱싱을 사용하여 특정 범위의 요소에 액세스할 수 있습니다. 아래는 동일한 데모입니다 - 예시 my_string = "Hi there how are you" my_counter = 0 for i in my_string: my_counter = my_counter + 1 new_string = my_string[0:2] + my_string [my_counter - 2: my_
재귀를 사용하지 않고 사전순으로 문자열의 모든 순열을 인쇄해야 하는 경우 문자열을 매개변수로 사용하는 메서드가 정의됩니다. 간단한 for 루프를 사용하여 문자열 요소를 반복하고 while 조건을 사용하여 특정 제약 조건을 확인합니다. 아래는 동일한 데모입니다 - 예시 from math import factorial def lex_permutation(my_string): for i in range(factorial(len(my_string))): print(''.join(my_string))
왼쪽 하위 트리의 노드를 인쇄해야 하는 경우 루트 노드를 설정하고, 순서대로 탐색을 수행하고, 루트 노드의 오른쪽에 요소를 삽입하고, 왼쪽에 요소를 삽입하는 메서드로 구성된 클래스를 만들 수 있습니다. 루트 노드 등이 있습니다. 클래스의 인스턴스가 생성되고 메서드를 사용하여 필요한 작업을 수행할 수 있습니다. 아래는 동일한 데모입니다 - 예시 class BinaryTree_struct: def __init__(self, data=None): self.key = data
재귀를 사용하여 사전순으로 문자열의 모든 순열을 인쇄해야 하는 경우 for 루프를 사용하여 요소 시퀀스를 반복하고 join 방법을 사용하여 요소를 결합하는 방법이 정의됩니다. 아래는 동일한 데모입니다 - 예시 from math import factorial def lexicographic_permutation_order(s): my_sequence = list(s) for _ in range(factorial(len(my_sequence))):
너비 우선 탐색 순회를 사용하여 트리의 노드를 표시해야 하는 경우 클래스가 생성되며 여기에는 루트 노드 설정, 트리에 요소 추가, 특정 요소 검색, bfs 수행( 너비 우선 탐색) 등이 있습니다. 이러한 메서드에 액세스하고 사용하기 위해 클래스의 인스턴스를 만들 수 있습니다. 아래는 동일한 데모입니다 - 예 class Tree_struct: def __init__(self, data=None): self.key = data self.
트리의 모든 노드의 합을 구해야 할 때 클래스를 생성하고 루트 노드를 설정하고 트리에 요소를 추가하고 특정 요소를 검색하고 트리의 요소를 추가하는 메소드를 포함합니다. 합계 등을 찾습니다. 이러한 메서드에 액세스하고 사용하기 위해 클래스의 인스턴스를 만들 수 있습니다. 아래는 동일한 데모입니다 - 예시 class Tree_struct: def __init__(self, data=None): self.key = data self.chi
트리의 모든 노드의 합을 구해야 할 때 클래스를 생성하고 루트 노드를 설정하고 트리에 요소를 추가하고 특정 요소를 검색하고 트리의 요소를 추가하는 메소드를 포함합니다. 합계 등을 찾습니다. 이러한 메서드에 액세스하고 사용하기 위해 클래스의 인스턴스를 만들 수 있습니다. 아래는 동일한 데모입니다 - 예시 from collections import deque def add_edge(v, w): global visited_node, adj adj[v].append(w) &n
트리의 모든 노드의 합을 구해야 할 때 클래스를 생성하고 루트 노드를 설정하고 트리에 요소를 추가하고 특정 요소를 검색하고 트리의 요소를 추가하는 메소드를 포함합니다. 합계 등을 찾습니다. 이러한 메서드에 액세스하고 사용하기 위해 클래스의 인스턴스를 만들 수 있습니다. 아래는 동일한 데모입니다 - 예시 class Graph_structure: def __init__(self, V): self.V = V self.adj = [[] f
트리의 모든 노드의 합을 구해야 할 때 클래스를 생성하고 루트 노드를 설정하고 트리에 요소를 추가하고 특정 요소를 검색하고 트리의 요소를 추가하는 메소드를 포함합니다. 합계 등을 찾습니다. 이러한 메서드에 액세스하고 사용하기 위해 클래스의 인스턴스를 만들 수 있습니다. 아래는 동일한 데모입니다 - 예 from collections import deque def add_edge(adj: list, u, v): adj[u].append(v) adj[v].append(u) def det
Kadane의 알고리즘을 사용하여 최대 하위 배열을 찾아야 할 때 하위 배열의 최대값을 찾는 데 도움이 되는 방법을 정의합니다. 반복자는 최대 하위 배열을 추적하는 데 사용됩니다. 아래는 동일한 데모입니다 - 예시 def find_max_sub_array(my_list, beg, end): max_end_at_i = max_seen_till_now = my_list[beg] max_left_at_i = max_left_till_now = beg max_right
비어 있지 않은 문자열에서 특정 인덱스 문자를 제거해야 하는 경우 반복할 수 있으며 인덱스가 일치하지 않는 경우 해당 문자를 다른 문자열에 저장할 수 있습니다. 아래는 동일한 데모입니다 - 예시 my_string = "Hi there how are you" print("The string is :") print(my_string) index_removed = 2 changed_string = '' for char in range(0, len(my_string)):
첫 번째 문자와 마지막 문자가 교환되는 새로운 문자열을 형성해야 하는 경우 인덱싱을 사용하여 새 문자열을 형성하는 메소드를 정의할 수 있습니다. 아래는 동일한 데모입니다 - 예시 def exchange_val(my_string): return my_string[-1:] + my_string[1:-1] + my_string[:1] my_string = “Hi there how are you” print(“The string is :”) print(my_string)
라이브러리 메서드를 사용하지 않고 문자열의 길이를 계산해야 하는 경우 카운터를 사용하여 문자열의 요소를 만날 때마다 증분합니다. 아래는 동일한 데모입니다 - 예시 my_string =Hi Willprint(문자열은 :)print(my_string)my_counter=0for i in my_string:my_counter=my_counter+1print(문자열의 길이는 )print(my_counter) 출력 문자열은 :Hi Will문자열의 길이는 7입니다. 설명 문자열이 정의되고 콘솔에 표시됩니다. 카운터는 0으로 초기화
무방향 그래프에서 깊이 우선 탐색을 사용하여 연결된 모든 구성 요소를 찾아야 하는 경우 값을 초기화하고, 깊이 우선 탐색을 수행하고, 연결된 구성 요소를 찾고, 그래프에 노드를 추가하는 등의 메서드가 포함된 클래스가 정의됩니다. 클래스의 인스턴스를 생성하고 메서드에 액세스하고 작업을 수행할 수 있습니다. 아래는 동일한 데모입니다 - 예시 class Graph_struct: def __init__(self, V): self.V = V