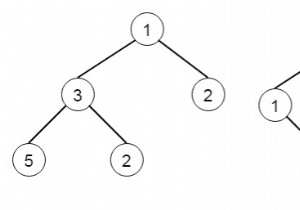

이진 트리가 있다고 가정합니다. 지그재그 수준의 순서 순회를 찾아야 합니다. 따라서 첫 번째 행의 경우 왼쪽에서 오른쪽으로 스캔한 다음 두 번째 행에서 오른쪽에서 왼쪽으로 스캔한 다음 다시 왼쪽에서 오른쪽으로 스캔합니다. 따라서 트리가 다음과 같다면 - 순회 시퀀스는 [[3],[20,9],[15,7]]입니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 트리가 비어 있으면 빈 목록을 반환합니다. queue :=큐를 만들고 루트를 큐에 삽입하고 두 개의 빈 목록 res 및 res2를 만들고 플래그를 Tr
간단한 표현식 문자열을 평가하기 위해 기본 계산기를 구현해야 한다고 가정합니다. 표현식 문자열은 음수가 아닌 정수, +, -, *, / 및 빈 공간과 같은 일부 연산자만 보유합니다. 정수 나누기는 몫 부분만 취해야 합니다. 따라서 입력이 3+2*2와 같으면 출력은 7이 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 스택 정의 s, i :=0, x :=빈 문자열 s의 각 문자 j에 대해 j가 공백 문자가 아닌 경우 x에 j 추가 s :=x, n :=x의 길이 내가
배열 A가 있다고 가정하고 중복 없이 숫자 집합을 섞어야 합니다. 따라서 입력이 [1,2,3]과 같으면 셔플의 경우 [1,3,2]가 되고 재설정 후 다시 셔플하면 [2,3,1] 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 다양한 방법이 있을 것입니다. 이들은 init(), reset(), shuffle()입니다. 다음과 같이 작동합니다 - 초기화는 다음과 같습니다 - 원본 :=주어진 배열의 복사본 temp :=숫자 인덱스 :=0부터 숫자 길이까지의 숫자 목록 – 1 reset()은 원래 배열
이진 트리의 루트가 있다고 가정하고 각 노드에는 0에서 25 사이의 값이 포함되어 있으며 이 값은 a에서 z까지의 문자를 나타냅니다. 값 0은 a를 나타내고 값 1은 b를 나타냅니다. , 등등. 우리는 이 트리의 잎에서 시작하여 루트에서 끝나는 사전식으로 가장 작은 문자열을 검색해야 합니다. 트리가 다음과 같다면 - 그런 다음 시퀀스가 [0,3,25]이므로 출력은 adz가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 다음과 같이 dfs 순회 방법을 정의합니다. 노드가 null이 아니면
주어진 선주문 순회와 일치하는 이진 검색 트리를 생성해야 한다고 가정합니다. 따라서 선주문 순회가 [8,5,1,7,10,12]와 같으면 출력은 [8,5,10,1,7,null,12]가 되므로 트리는 - 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 루트 :=0번째 선주문 순회 목록의 노드 stack :=스택, 스택에 루트 푸시 선주문 목록의 두 번째 요소에서 각 요소 i에 대해 i :=값이 i인 노드 만약 i의 값이 <스택 상단 요소의 상단이면 스택 상단 노드의 왼쪽 :=i 스택에 i 삽입 그렇지 않으면 스택이 비
D일 이내에 한 항구에서 다른 항구로 배송될 패키지가 컨베이어 벨트에 있다고 가정합니다. 여기에서 컨베이어 벨트의 i번째 패키지는 weight[i]의 무게를 갖습니다. 매일 우리는 벨트에 소포를 싣고 배를 싣습니다. 우리는 선박의 최대 중량 용량보다 더 많은 중량을 적재하지 않을 것입니다. 컨베이어 벨트에 있는 모든 패키지가 D일 이내에 배송되도록 하는 선박의 최소 중량 용량을 찾아야 합니다. 따라서 입력이 [3,2,2,4,1,4]이고 D =3이면 출력은 6이 됩니다. 6의 배송 용량은 3일 안에 모든 패키지를 배송하는 최소값이기
서점 소유자가 몇 분의 고객 목록 항목에 대해 상점을 연다고 가정합니다. 1분마다 몇 명의 고객(customers[i])이 매장에 들어오고, 그 고객은 모두 그 시간이 지나면 나옵니다. 몇 분 동안 주인은 심술 궂습니다. 이제 i번째 분에 주인이 심술궂으면 grumpy[i] =1, 그렇지 않으면 grumpy[i] =0입니다. 서점 주인이 심술하면 그 순간의 고객은 불행하고 그렇지 않으면 행복합니다. 서점 주인은 X분 동안 심술을 부리지 않는 방법을 알고 있습니다. 그 기술은 두 번 이상 사용할 수 없습니다. 하루 종일 행복할 수 있
이진 트리가 있다고 가정합니다. 이 노드를 교차하는 모든 루트에서 리프 경로로의 합이 제한보다 작으면 노드가 충분하지 않은 것으로 알려져 있습니다. 불충분한 모든 노드를 동시에 삭제하고 결과 바이너리 트리의 루트를 반환해야 합니다. 트리가 같음이고 한계가 1 −인 경우 그러면 출력 트리는 -가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − solve() 메서드를 정의하면 뿌리를 내리고 제한됩니다. 노드에 왼쪽 및 오른쪽 하위 트리가 없으면 루트 값이 1보다 작으면 null 반환, 그렇지 않으면 루트 루
텍스트가 있다고 가정하고 텍스트의 모든 고유한 문자를 정확히 한 번 포함하는 사전순으로 가장 작은 텍스트 하위 시퀀스를 찾아야 합니다. 따라서 입력이 cdadbcc와 같으면 출력은 adbc가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − stack st를 정의하고 두 개의 맵을 last_o로 간주하고 처음에는 비어 있음 i의 경우 텍스트 길이 범위 - 1에서 0까지 text[i]가 last_o에 없는 경우 - last_o[text[i]] :=나 고려[text[i]] :=거짓 i :=0 동안 i <텍스트의 길이
R개의 행과 C개의 열이 있는 정수의 행렬 A가 있다고 가정하고 [0,0]에서 시작하여 [R-1,C-1]에서 끝나는 경로의 최대 점수를 찾아야 합니다. 여기에서 스코어링 기술은 해당 경로의 최소값이 됩니다. 예를 들어, 경로 8 → 4 → 5 → 9의 값은 4입니다. 경로는 방문한 한 셀에서 방문하지 않은 이웃 셀로 4가지 기본 방향(북쪽, 동쪽, 서쪽, 남쪽) 중 하나로 몇 번 이동합니다. . 예를 들어 그리드가 다음과 같은 경우 - 5 4 5 1 2 6 7 4 6 주황색 셀이 경로가 됩니다. 출력은 4입니다. 이
일련의 책이 있다고 가정합니다. 여기서 i 번째 책에는 두께 책[i][0]과 높이 책[i][1]이 있습니다. 전체 너비가 shelf_width인 책장에 이 책을 순서대로 배치하려는 경우. 이 선반에 놓을 책 중 일부를 선택하면(두께의 합이 <=shelf_width가 되도록), 책장의 총 높이가 최대 높이만큼 증가한 책장의 다른 수준의 선반을 만듭니다. 우리가 내려놓을 수 있는 책. 더 이상 배치할 책이 없을 때까지 이 과정을 반복합니다. 위 과정의 각 단계에서 우리가 놓는 책의 순서는 주어진 책의 순서와 같은 순서라는 것을 명심해야
이진 트리의 루트가 있고 트리의 각 노드에 고유한 값이 있다고 가정합니다. to_delete에 값이 있는 모든 노드를 제거하면 포리스트가 남습니다. 우리는 남은 숲에서 나무의 뿌리를 찾아야 합니다. 따라서 입력이 다음과 같은 경우 to_delete 배열이 [3,5]와 같으면 출력은 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 배열 해상도 정의 solve() 메서드를 정의하면 노드, to_delete 배열 및 노드가 루트인지 여부를 알려주는 부울 유형 정보가 필요합니다. 이 메서드는 아래와 같이 작동합니다- 노드가
문자열이 있다고 가정하고 해당 문자열은 ( 및 ) 문자로만 구성되고 이러한 속성을 충족하는 경우에만 유효한 괄호 문자열(VPS로 표시)입니다 - 빈 문자열이거나 AB로 쓸 수 있습니다. 여기서 A와 B는 VPS 또는 (A)로 쓸 수 있습니다. 여기서 A는 VPS입니다. 우리는 또한 아래와 같이 모든 VPS S의 중첩 깊이 깊이(S)를 정의할 수 있습니다 - 깊이() =0 깊이(A + B) =깊이(A)의 최대값, 깊이(B), 여기서 A와 B는 VPS depth(( + A + )) =1 + dept
양의 정수 배열 arr이 있다고 가정하고 모든 이진 트리를 다음과 같이 고려합니다. - 각 노드에는 0 또는 2개의 자식이 있습니다. arr 배열의 값은 트리의 inorder traversal에서 각 잎의 값에 해당합니다. 잎이 아닌 각 노드의 값은 각각 왼쪽 및 오른쪽 하위 트리에서 가장 큰 잎 값의 곱과 같습니다. 고려되는 모든 가능한 이진 트리 중에서 잎이 아닌 각 노드 값의 가능한 가장 작은 합을 찾아야 합니다. 따라서 입력 arr이 [6,2,4]이면 두 개의 트리가 있을 수 있으므로 출력은 32가 됩니다. 이 문
0에서 numCourses-1까지 레이블이 지정된 총 numCourses 코스가 있다고 가정합니다. 일부 코스에는 전제 조건이 있을 수 있습니다. 예를 들어 코스 0을 수강하려면 먼저 [0,1] 쌍을 사용하여 표현되는 코스 1을 수강해야 합니다. 제공되는 총 과정의 수와 전제 조건 쌍 목록이 있다고 가정하면 모든 과정을 완료할 수 있는지 확인해야 합니다. 따라서 입력이 − numCourses =2이고 전제 조건 =[[1, 0]]인 경우 총 2개의 코스가 있기 때문에 결과는 true가 됩니다. 코스 1을 수강하려면 코스 0을 완료해
총 n개의 코스가 있다고 가정하고 0에서 n-1까지 레이블이 지정됩니다. 일부 코스에는 선행 조건이 있을 수 있습니다. 총 코스 수와 선행 조건 쌍 목록이 주어지면 모든 코스를 완료하기 위해 수강해야 하는 코스 순서를 찾아야 합니다. 올바른 주문이 여러 개 있을 수 있으며 그 중 하나만 찾으면 됩니다. 모든 과정을 마치는 것이 불가능한 경우 빈 배열을 반환하십시오. 따라서 입력이 2, [[1, 0]]과 같으면 결과는 [0,1]이 됩니다. 총 2과목을 수강하실 수 있습니다. 1번 과정을 수강하려면 0번 과정을 마쳐야 합니다. 따라서
내포된 정수 목록이 있다고 가정합니다. 우리는 그것을 평평하게 하기 위해 반복자를 구현해야 합니다. 각 요소는 정수 또는 목록입니다. 해당 목록의 요소는 정수 또는 기타 목록일 수도 있습니다. 따라서 입력이 [[1, 1], 2, [1, 1]]과 같으면 출력은 [1, 1, 2, 1, 1]이 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 초기화 섹션에서는 중첩 목록을 사용하며 다음과 같이 작동합니다. - res를 빈 목록으로 설정, index :=0, getVal(nestedList) 호출 getVal(
평균 O(1) 시간에 다음 작업을 모두 지원하는 데이터 구조가 있다고 가정합니다. insert(val) - 이미 존재하지 않는 경우 항목 val을 세트에 삽입합니다. remove(val) - 존재하는 경우 세트에서 항목 val을 제거합니다. getRandom - 현재 요소 집합에서 임의의 요소를 반환합니다. 각 요소는 반환될 확률이 같아야 합니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 초기화를 위해 부모 맵과 요소 배열을 정의합니다. insert() 함수의 경우 val을 입력으로 사용합
화면에 숫자가 표시된 고장난 계산기가 있다고 가정하면 두 가지 작업만 수행할 수 있습니다. Double - 디스플레이의 숫자에 2를 곱하거나; Decrement - 표시되는 숫자를 1씩 줄입니다. 처음에 계산기는 숫자 X를 표시합니다. 우리는 숫자 Y를 표시하는 데 필요한 최소 연산 수를 찾아야 합니다. 따라서 입력이 X =5이고 Y가 8인 경우 출력은 2가 됩니다. 감소하면 한 번, 두 배로 증가합니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 해상도 :=0 X 동안 res :=re
한 사회 집단에 0에서 N-1까지의 고유 정수 ID를 가진 N명의 다른 사람들이 있다고 가정합니다. 여기에 로그 목록이 있습니다. 여기서 각 logs[i] =[time, id_A, id_B]에는 음수가 아닌 정수 타임스탬프와 서로 다른 두 사람의 ID가 포함됩니다. 각 로그는 서로 다른 두 사람이 친구가 된 시간을 보여줍니다. A가 B와 친구라면 B는 A와 친구다. A가 B와 친구이거나 A가 B와 아는 사람의 친구인 경우 A라는 사람이 B와 아는 사이라고 하자. 가장 빠른 시간을 찾아야 한다. 모든 사람이 다른 모든 사람과 알게 된