

이 프로그램에서는 C++를 사용하여 섭씨를 화씨로 변환하는 방법을 볼 것입니다. 공식은 간단합니다. 알고리즘 Begin Take the Celsius temperature in C calculate F = (9C/5)+32 return F End 예시 코드 #include<iostream> using namespace std; main() { float f, c; cout << "Enter temperature in Celsius: "; cin >> c; f
피보나치 수열은 다음과 같습니다. 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55,…… 이 시퀀스에서 n번째 항은 (n-1)th의 합입니다. 및 (n-2)번째 약관. 생성하기 위해 재귀 접근 방식을 사용할 수 있지만 동적 프로그래밍에서는 절차가 더 간단합니다. 모든 피보나치 수를 테이블에 저장할 수 있으며 해당 테이블을 사용하여 이 시퀀스에서 다음 항을 쉽게 생성할 수 있습니다. 입력 − 용어 번호를 입력으로 사용합니다. 10이라고 말하세요. 출력 − 10 피비나치 항은 55 알고리즘
기수 정렬은 비비교 정렬 알고리즘입니다. 이 정렬 알고리즘은 동일한 위치와 값을 공유하는 숫자를 그룹화하여 정수 키에서 작동합니다. 기수는 숫자 체계의 기초입니다. 십진법에서 기수 또는 밑이 10이라는 것을 알고 있듯이 일부 십진법을 정렬하려면 숫자를 저장할 10개의 위치 상자가 필요합니다. 기수 정렬 기법의 복잡성 시간 복잡도:O(nk) 공간 복잡도:O(n+k) Input − The unsorted list: 802 630 20 745 52 300 612 932 78 187 Output − Da
버킷 정렬 기술에서 데이터 항목은 버킷 세트로 분산됩니다. 각 버킷은 유사한 유형의 데이터를 보유할 수 있습니다. 배포 후 각 버킷은 다른 정렬 알고리즘을 사용하여 정렬됩니다. 그런 다음 모든 요소를 기본 목록으로 모아 정렬된 형식을 얻습니다. 버킷 정렬 기법의 복잡성 시간 복잡도:최상의 경우와 평균적인 경우는 O(n + k), 최악의 경우는 O(n2 )입니다. 공간 복잡도:최악의 경우 O(nk) 입력 - 정렬되지 않은 데이터의 목록:0.25 0.36 0.58 0.41 0.29 0.22 0.45 0.79 0.01
버블 정렬은 비교 기반 정렬 알고리즘입니다. 이 알고리즘에서는 인접한 요소를 비교하고 교환하여 올바른 순서를 만듭니다. 이 알고리즘은 다른 알고리즘보다 간단하지만 몇 가지 단점도 있습니다. 이 알고리즘은 많은 수의 데이터 세트에 적합하지 않습니다. 정렬 작업을 해결하는 데 시간이 많이 걸립니다. 버블 정렬 기법의 복잡성 시간 복잡도:최상의 경우 O(n), O(n2 ) 평균 및 최악의 경우 공간 복잡도:O(1) Input − A list of unsorted data: 56 98 78 12 30 51 Outp
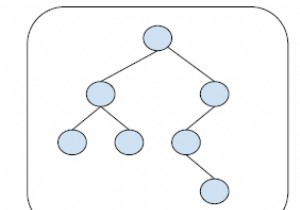
힙은 최소 힙 또는 최대 힙인 완전한 이진 트리입니다. 최대 힙에서 루트의 키는 힙에 있는 모든 키 중에서 최대여야 합니다. 이 속성은 이진 트리의 모든 노드에 대해 재귀적으로 true여야 합니다. Min Heap은 MinHeap과 유사합니다. 기능 설명 void BHeap::Insert(int ele): 힙에 요소를 삽입하려면 삽입 작업을 수행합니다. 무효 BHeap::DeleteMin(): 힙에서 최소값을 삭제하려면 삭제 작업을 수행합니다. int BHeap::ExtractMin(): 힙에서 최소값을 추출하는 작업을 수행합
병합 정렬 기법은 분할 정복 기법을 기반으로 합니다. while 데이터 세트를 더 작은 부분으로 나누고 정렬된 순서로 더 큰 부분으로 병합합니다. 이 알고리즘은 최악의 경우에도 시간 복잡도가 낮기 때문에 최악의 경우에도 매우 효과적입니다. 병합 정렬 기법의 복잡성 시간 복잡도:모든 경우에 대해 O(n log n) 공간 복잡도:O(n) Input − The unsorted list: 14 20 78 98 20 45 Output − Array after Sorting: 14 20 20 45 78 98
선택 정렬 기술에서 목록은 두 부분으로 나뉩니다. 한 부분에서는 모든 요소가 정렬되고 다른 부분에서는 항목이 정렬되지 않습니다. 처음에는 배열에서 최대 또는 최소 데이터를 가져옵니다. 데이터를 가져온 후(최소값이라고 함) 첫 번째 데이터를 최소 데이터로 교체하여 목록의 시작 부분에 배치합니다. 수행 후 어레이가 작아지고 있습니다. 이렇게 정렬 기술이 완성됩니다. 선택 정렬 기법의 복잡성 시간 복잡도:O(n2 ) 공간 복잡도:O(1) Input − The unsorted list: 5 9 7 23 78 20
이 정렬 기술은 카드 정렬 기술과 유사합니다. 즉, 삽입 정렬 메커니즘을 사용하여 카드를 정렬합니다. 이 기술의 경우 데이터 세트에서 하나의 요소를 선택하고 데이터 요소를 이동하여 선택한 요소를 데이터 세트에 다시 삽입할 위치를 만듭니다. 삽입 정렬 기법의 복잡성 시간 복잡도:최상의 경우 O(n), 평균 및 최악의 경우 O(n2) 공간 복잡도:O(1) Input − The unsorted list: 9 45 23 71 80 55 Output − Array after Sorting: 9 23 45
쉘 정렬 기술은 삽입 정렬을 기반으로 합니다. 삽입 정렬에서 때때로 올바른 위치에 항목을 삽입하기 위해 큰 블록을 이동해야 합니다. 쉘 정렬을 사용하면 많은 수의 이동을 피할 수 있습니다. 정렬은 특정 간격으로 수행됩니다. 각 패스 후에 간격이 줄어들어 간격이 더 작아집니다. 쉘 정렬 기법의 복잡성 시간 복잡도:최상의 경우 O(n log n), 다른 경우 간격 시퀀스에 따라 다릅니다. 공간 복잡도:O(1) 입력 - 정렬되지 않은 목록:23 56 97 21 35 689 854 12 47 66출력 - 정렬 후 배열:12
카운팅 정렬은 작은 숫자의 키에 따라 개체를 정렬하는 데 사용되는 안정적인 정렬 기술입니다. 키 값이 동일한 키의 수를 계산합니다. 이 정렬 기술은 서로 다른 키 간의 차이가 크지 않을 때 효율적이고 그렇지 않으면 공간 복잡성을 증가시킬 수 있습니다. 정렬 기법 계산의 복잡성 시간 복잡도:O(n+r) 공간 복잡도:O(n+r) 입력 − 정렬되지 않은 데이터 목록:2 5 6 2 3 10 3 6 7 8 출력 − 정렬 후 배열:2 2 3 3 5 6 6 7 8 10 알고리즘 countingSort(배열, 크기) 입력 :데
이진 검색 기술의 경우 목록은 동일한 부분으로 나뉩니다. 보간 검색 기술의 경우 절차는 보간 공식을 사용하여 정확한 위치를 찾으려고 시도합니다. 예상 위치를 찾은 후 해당 위치를 사용하여 목록을 분리할 수 있습니다. 매번 정확한 위치를 찾으려 하므로 검색 시간이 줄어듭니다. 이 기술은 항목이 균일하게 분포되어 있으면 항목을 쉽게 찾을 수 있습니다. 보간 검색 기법의 복잡성 시간 복잡도:O(log2 (로그2 n)) 평균 경우, O(n) 최악의 경우(항목이 기하급수적으로 분포되는 경우) 공간 복잡도:O(1) Input −
그래프의 연결성을 확인하기 위해 순회 알고리즘을 사용하여 모든 노드를 순회하려고 합니다. 순회 완료 후 방문하지 않은 노드가 있으면 그래프가 연결되지 않습니다. 방향 그래프의 경우 연결을 확인하기 위해 모든 노드에서 순회를 시작합니다. 때때로 한 가장자리에는 바깥쪽 가장자리만 있고 안쪽 가장자리는 없을 수 있으므로 해당 노드는 다른 시작 노드에서 방문하지 않습니다. 이 경우 순회 알고리즘은 재귀적 DFS 순회입니다. 입력 :그래프의 인접 행렬 0 1 0 0 0 0 0 1 0 0 0 0 0 1 1 1 0 0 0 0 0
방향 그래프에서 구성 요소는 한 구성 요소의 각 꼭짓점 쌍 사이에 경로가 있을 때 강하게 연결되어 있다고 합니다. 이 알고리즘을 해결하기 위해 먼저 DFS 알고리즘을 사용하여 각 정점의 종료 시간을 구하고 이제 전치된 그래프의 종료 시간을 찾은 다음 정점을 토폴로지 정렬에 따라 내림차순으로 정렬합니다. 입력 :그래프의 인접 행렬입니다. 0 0 1 1 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 출력 :다음은 주어진 그래프에서 강력하게 연결된 구성 요소입니다 - 0 1 2 3 4 알
오일러 사이클/회로는 경로입니다. 이를 통해 모든 가장자리를 정확히 한 번 방문할 수 있습니다. 같은 정점을 여러 번 사용할 수 있습니다. 오일러 회로는 특수한 유형의 오일러 경로입니다. 오일러 경로의 시작 꼭짓점과 해당 경로의 끝 꼭짓점이 연결되어 있는 경우 이를 오일러 회로라고 합니다. 그래프가 오일러인지 아닌지 확인하려면 두 가지 조건을 확인해야 합니다. - 그래프가 연결되어 있어야 합니다. 각 꼭짓점의 내차수와 외차수는 같아야 합니다. 입력 − 그래프의 인접 행렬. 0 1 0 0 0 0 0 1 0 0
여기서 우리는 문제의 까다로운 솔루션을 볼 것입니다. 세미콜론을 사용하지 않고 1에서 N까지 일부 숫자를 인쇄합니다. 우리는 두 가지 다른 방법으로 이 문제를 해결할 수 있습니다. 첫 번째는 Iterative 방식이고 두 번째는 Recursive 방식입니다. 방법 1 printf() 함수는 0이 아닌 값이 되도록 문자열의 길이를 반환합니다. 결과를 출력하는 조건으로 논리적 AND를 수행할 수 있습니다. 그런 다음 카운터 값을 높이십시오. 예시 코드 #include<stdio.h> #define N 20 int main
선형 합동 생성기는 난수 생성기의 매우 간단한 예입니다. 가장 오래되고 가장 잘 알려진 의사 난수 생성기 알고리즘 중 하나입니다. 이 메소드에서 사용되는 함수 - Xn+1=(aXn + C) mod m 여기서 X는 의사 난수 값의 시퀀스이고 m,0<m— the “modulus" a,0<a<m — the "multiplier" c,0<c<m — the "increment" X0, 0<x0<m — th
이 섹션에서는 여러 문장을 작성하지 않고 자릿수 합을 찾는 방법을 살펴보겠습니다. 즉, 단일 명령문에서 자릿수 합을 찾습니다. 우리가 알고 있듯이, 자릿수의 합을 찾기 위해 숫자를 10으로 나눈 후 나머지를 취하여 마지막 자릿수를 자르고 숫자가 0이 될 때까지 숫자를 10으로 계속해서 나눕니다. 단일 문에서 이러한 작업을 수행하려면 for 루프를 사용할 수 있습니다. 우리가 알고 있듯이 for 루프에는 세 개의 다른 섹션이 있습니다. 초기화 단계에서 우리는 이 경우 아무 것도 하지 않고 조건 확인 단계에서 숫자가 0보다 큰지 여
중간제곱법은 난수를 생성하는 가장 간단한 방법 중 하나입니다. 이 방법은 동일한 번호를 반복적으로 생성하기 시작하거나 시퀀스의 이전 번호로 순환하고 무한 루프합니다. n자리 난수 생성기의 경우 기간은 n보다 길 수 없습니다. 중간 n자리가 모두 0이면 Generator는 영원히 0을 출력하지만 이러한 0의 실행은 감지하기 쉽지만 이 방법을 실용적으로 사용하기에는 너무 자주 발생합니다. Input − Enter the digit for random number:4 Output − The random numbers
확률 밀도 함수(pdf)는 이 랜덤 변수가 주어진 값을 취할 상대적 가능성을 설명하는 함수입니다. 연속 확률 변수의 밀도라고도 합니다. 확률 변수가 값의 특정 범위에 속할 확률은 해당 범위에 대한 이 변수의 밀도의 적분에 의해 주어집니다. 따라서 밀도 함수 아래이지만 수평 축 위에 있고 가장 낮은 값과 가장 큰 값 사이의 면적으로 주어집니다. 범위의. 확률 분포는 이 확률 밀도 함수를 기반으로 합니다. 알고리즘 Begin Declare n pdf=0 할당 i =0 ~ n에 대해 pdf =rand() mod 200 pdf가 360보