
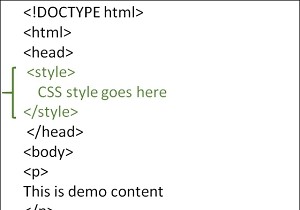
C++11에서 람다가 도입되었습니다. 람다는 기본적으로 다른 함수 호출 문 안에 중첩될 수 있는 코드의 일부입니다. 람다식을 auto 키워드와 결합하면 나중에 사용할 수 있습니다. C++14에서는 이러한 람다 식이 개선되었습니다. 여기에서 일반화된 람다를 얻을 수 있습니다. 예를 들어 정수를 추가하고 숫자를 추가하고 문자열을 연결할 수 있는 람다를 만들고 싶다면 이 일반화된 람다를 사용해야 합니다. 람다 식의 구문은 다음과 같습니다. [](auto x, auto y) { return x + y; } 더 나은 아이디어를 얻기 위
여기서는 C로 자체 파괴 코드를 만드는 방법을 살펴보겠습니다. 자체 파괴 코드는 기본적으로 코드를 실행한 다음 실행한 후 실행 파일을 제거하는 것입니다. 이 작업은 매우 간단합니다. 제거하려면 실행 파일 이름을 가져와야 합니다. 명령줄 인수를 사용할 수 있습니다. argv[0]은 실행 가능한 파일 이름을 보유합니다. 그런 다음 remove() 함수를 사용하여 제거할 수 있습니다. 프로그램에서 해당 파일을 제거한 후 한 줄이 인쇄되는 것을 볼 수 있습니다. 이제 현재 파일이 존재하지 않는 동안 다음 줄이 어떻게 실행되는지에 대한
세마포는 프로세스 또는 스레드 동기화의 개념입니다. 여기에서 실제 프로그램에서 세마포어를 사용하는 방법을 볼 것입니다. Linux 시스템에서는 POSIX 세마포어 라이브러리를 얻을 수 있습니다. 그것을 사용하려면 semaphores.h 라이브러리를 포함해야 합니다. 다음 옵션을 사용하여 코드를 컴파일해야 합니다. gcc program_name.c –lpthread -lrt sem_wait()를 사용하여 잠그거나 기다릴 수 있습니다. 그리고 sem_post() 잠금을 해제합니다. 세마포는 IPC(프로세스 간 통신)를 위
여기서는 C를 사용하여 자체 헤더 파일을 만드는 방법을 살펴보겠습니다. 헤더 파일을 만들려면 이름과 확장자가 (*.h)인 파일을 하나 만들어야 합니다. 그 함수에는 main() 함수가 없습니다. 해당 파일에 일부 변수, 일부 기능 등을 넣을 수 있습니다. 해당 헤더 파일을 사용하려면 프로그램이 있는 동일한 디렉토리에 있어야 합니다. 이제 #include를 사용하여 헤더 파일 이름을 넣어야 합니다. 이름은 큰따옴표 안에 있습니다. 포함 구문은 다음과 같습니다. #include”header_file.h” 아이디
여기에서 우리는 하나의 클라이언트와 서버를 만들고 클라이언트가 하나의 문자열을 서버에 보낼 수 있고 서버는 문자열을 역전시켜 클라이언트로 되돌아가는 시스템을 만드는 방법을 볼 것입니다. 여기서 우리는 소켓 프로그래밍의 개념을 사용할 것입니다. 클라이언트 서버에 연결하려면 포트를 생성해야 합니다. 포트 번호는 소켓에서 사용할 수 있는 임의의 번호입니다. 연결을 설정하려면 클라이언트와 서버에 동일한 포트를 사용해야 합니다. 프로그램을 시작하려면 먼저 서버 프로그램을 시작하십시오 - gcc Server.c –o server
여기서 우리는 C++의 문자열 스트림을 볼 것입니다. 문자열 스트림은 문자열 개체를 문자열과 연결합니다. 이것을 사용하여 문자열에서 마치 cin과 같은 스트림인 것처럼 읽을 수 있습니다. Stringstream에는 다른 방법이 있습니다. 다음과 같습니다 - 지우기(): 스트림을 지우는 데 사용 str(): 스트림에 콘텐츠가 있는 문자열 개체를 가져오고 설정하려면 연산자 <<: 이것은 stringstream에 하나의 문자열을 추가합니다 : stringstream 개체에서 읽는 데 사용됩니다. 문자열 스트림의 두 가지 예를
여기에서 일부 문자열을 일부 바이너리 코드로 숨기는 방법을 볼 것입니다(여기서 바이너리 코드는 16진수로 표시됨). 접근 방식은 매우 간단합니다. 문자열 스트림을 사용하여 10진수를 16진수로 변환할 수 있습니다. 이제 문자열에서 각 문자를 읽고 ASCII 값을 취합니다. 이 ASCII 값은 16진수 값으로 변환됩니다. 그런 다음 하나씩 인쇄할 수 있습니다. 예시 #include<iostream> #include<sstream> using namespace std; string dec_to_hex(int de
C에서 문자열은 기본적으로 문자 배열입니다. C++에서 std::string은 해당 배열의 발전입니다. 기존 문자 배열에는 몇 가지 추가 기능이 있습니다. null로 끝나는 문자열은 기본적으로 일련의 문자이며 마지막 요소는 하나의 null 문자(\0로 표시)입니다. 큰따옴표(...)를 사용하여 문자열을 작성하면 컴파일러에서 null로 끝나는 문자열로 변환됩니다. 문자열의 크기는 배열 크기보다 작을 수 있지만 해당 배열 내부에 null 문자가 있는 경우 해당 문자열의 끝으로 처리됩니다. 다음 예를 참조하십시오. 여기에서 std::
여기서는 C++에서 문자열을 자르는 방법을 살펴보겠습니다. 자르기 문자열은 문자열의 왼쪽과 오른쪽 부분에서 공백을 제거하는 것을 의미합니다. C++ 문자열을 다듬기 위해 부스트 문자열 라이브러리를 사용합니다. 해당 라이브러리에는 trim_left() 및 trim_right()라는 두 가지 다른 메서드가 있습니다. 문자열을 완전히 자르려면 둘 다 사용할 수 있습니다. 예시 #include<iostream> #include<boost/algorithm/string.hpp> using namespace std; m
여기서는 C 또는 C++를 사용하여 두 개의 부동 소수점 데이터 또는 두 개의 이중 데이터를 비교하는 방법을 살펴보겠습니다. 부동 소수점/이중 비교는 정수 비교와 유사하지 않습니다. 두 개의 부동 소수점 또는 이중 값을 비교하려면 비교의 정밀도를 고려해야 합니다. 예를 들어 두 숫자가 3.1428과 3.1415이면 정밀도 0.01까지는 같지만 그 이후에는 0.001처럼 같지 않습니다. 이 기준을 사용하여 비교하려면 부동 소수점 수에서 부동 소수점 수를 빼서 절대값을 찾은 다음 결과가 정밀도 값보다 작은지 여부를 확인합니다. 이것
여기에서 정수 포인터 정수 상수와 정수 상수 포인터를 기반으로 하는 몇 가지 다른 유형의 변수 선언을 볼 수 있습니다. 그것들을 결정하기 위해 우리는 시계 방향/나선형 규칙을 사용할 것입니다. 용어를 논의함으로써 규칙도 이해할 수 있습니다. 상수 정수 * . 이것은 컴파일러에게 이것이 포인터 유형 변수이며 상수 int의 주소를 저장할 수 있음을 알리는 데 사용됩니다. 시계 규칙은 다음과 같이 말합니다 - 이제 다른 하나는 const int * const입니다. 이것은 이것이 다른 상수 정수의 주소를 저장할 수 있는 하나의
extern C 키워드는 C++의 함수 이름에 C 연결을 갖도록 만드는 데 사용됩니다. 이 경우 컴파일러는 함수를 맹글링하지 않습니다. 먼저 C++에서 맹글링이 무엇인지 살펴보고 extern C 키워드에 대해 논의할 수 있습니다. C++에서는 함수 오버로딩 기능을 사용할 수 있습니다. 이 기능을 사용하여 같은 이름의 함수를 만들 수 있습니다. 유일한 차이점은 인수 유형과 인수 수입니다. 반환 유형은 여기에서 고려되지 않습니다. 이제 문제는 C++가 개체 코드에서 오버로드된 함수를 구별하는 방법입니다. 개체 코드에서 인수에 대한
복사 초기화는 복사 생성자의 개념을 사용하여 수행할 수 있습니다. 생성자가 객체를 초기화하는 데 사용된다는 것을 알고 있습니다. 다른 객체의 복사본을 만들기 위해 복사 생성자를 만들 수 있습니다. 즉, 다른 객체의 값으로 현재 객체를 초기화할 수 있습니다. 반면에 직접 초기화는 할당 연산을 사용하여 수행할 수 있습니다. 이 두 가지 초기화 유형의 주요 차이점은 복사 초기화가 새 개체에 대해 별도의 메모리 블록을 생성한다는 것입니다. 그러나 직접 초기화는 새로운 메모리 공간을 만들지 않습니다. 참조 변수를 사용하여 이전 메모리 블록
C++에서 인라인 키워드는 다른 곳에서 사용됩니다. 인라인 변수 또는 인라인 네임스페이스를 생성하고 인라인 메서드 또는 함수를 생성합니다. C++ 인라인 함수는 일반적으로 클래스와 함께 사용되는 강력한 개념입니다. 함수가 인라인이면 컴파일러는 컴파일 시간에 함수가 호출되는 각 지점에 해당 함수의 코드 복사본을 배치합니다. 인라인 함수를 변경하면 컴파일러가 모든 코드를 다시 한 번 교체해야 하므로 함수의 모든 클라이언트를 다시 컴파일해야 할 수 있습니다. 그렇지 않으면 이전 기능이 계속 사용됩니다. 함수를 인라인하려면 inlin
C++에서 리틀 엔디안 값을 빅 엔디안으로 또는 빅 엔디안 값을 리틀 엔디안으로 변환하는 방법을 살펴보겠습니다. 본격적인 논의에 앞서 빅 엔디안과 리틀 엔디안이 무엇인지 알아볼까요? 다른 아키텍처에서 멀티바이트 데이터는 두 가지 다른 방식으로 저장할 수 있습니다. 때로는 상위 바이트가 먼저 저장되는 경우가 있는데, 이 경우 빅 엔디안이라고 하고 하위 바이트를 먼저 저장한 다음 리틀 엔디안이라고 합니다. 예를 들어 숫자가 0x9876543210이면 빅 엔디안은 -가 됩니다. 리틀 엔디안은 다음과 같습니다 - 이 섹션에서
이 섹션에서는 C++의 nullptr을 볼 것입니다. nullptr은 포인터 리터럴을 나타냅니다. std::nullptr_t 유형의 prvalue입니다. nullptr에서 모든 포인터 유형의 null 포인터 값 및 멤버 유형에 대한 포인터로의 암시적 변환 속성이 있습니다. 이 개념을 이해하기 위해 하나의 프로그램을 살펴보겠습니다. 예시 #include<iostream> using namespace std; int my_func(int N){ //function with integer type parameter &nbs
여기서는 C++를 사용하여 두 부동 소수점 데이터를 비교하는 방법을 살펴보겠습니다. 부동 소수점 비교는 정수 비교와 유사하지 않습니다. 두 부동 소수점 값을 비교하려면 비교의 정밀도를 고려해야 합니다. 예를 들어 두 숫자가 3.1428과 3.1415이면 정밀도 0.01까지는 같지만 그 이후에는 0.001처럼 같지 않습니다. 이 기준을 사용하여 비교하려면 부동 소수점 수에서 부동 소수점 수를 빼서 절대값을 찾은 다음 결과가 정밀도 값보다 작은지 여부를 확인합니다. 이것으로 우리는 그것들이 동등한지 아닌지를 결정할 수 있습니다. 예
Visual Studio 2012에서 라이브러리를 추가하는 방법에는 두 가지가 있습니다. 첫 번째는 수동 방식입니다. 두 번째는 코드에서 라이브러리를 추가하는 것입니다. 먼저 수동 방법을 살펴보겠습니다. 라이브러리를 추가하려면 다음 5단계를 따라야 합니다. 적절한 선언과 함께 필요한 파일에 #include 문을 추가합니다. 예를 들어 - #include “library.h” 컴파일러 조회를 위한 포함 디렉토리 추가, 구성 속성/VC++ 디렉터리/포함 디렉터리로 이동 그런 다음 클릭하여 수정하고 새 항
file_name.h 또는 file_name.cpp와 같은 여러 파일을 한 번에 컴파일하려면 목록처럼 파일을 차례로 사용할 수 있습니다. 구문은 다음과 같습니다 - g++ abc.h xyz.cpp 프로그램을 실행하기 위해 다음을 사용할 수 있습니다 - ./a.out 예시 float area(float r){ return (3.1415*r*r); //area of a circle } float area(float l, float w){ return (l * w); //area of a
여기에서 C++11에서 스레드를 종료하는 방법을 살펴보겠습니다. C++11에는 스레드를 종료하는 직접적인 방법이 없습니다. std::future는 쓰레드에 사용될 수 있으며, 미래의 값을 사용할 수 있을 때 종료되어야 합니다. 쓰레드에 시그널을 보내고 싶지만 실제 값을 보내지 않는다면 void 타입 객체를 전달할 수 있다. 하나의 promise 객체를 생성하려면 다음 구문을 따라야 합니다 - std::promise<void> exitSignal; 이제 main 함수에서 생성된 promise 개체에서 연결된 futur