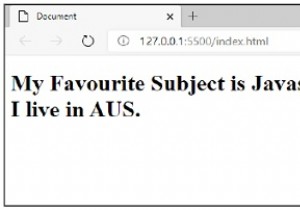

평문의 각 문자를 다른 문자로 대체하여 암호문을 구성하는 단일 알파벳 암호입니다. 가장 단순한 형태의 대체 암호 체계입니다. 이 암호 시스템을 일반적으로 시프트 암호라고 합니다. 개념은 각 알파벳을 0에서 25 사이의 고정된 숫자만큼 이동하는 다른 알파벳으로 바꾸는 것입니다. 이러한 유형의 체계에서는 발신자와 수신자 모두 알파벳 이동을 위한 비밀 이동 번호에 동의합니다. 이 0~25 사이의 숫자가 암호화 키가 됩니다. 3의 시프트가 사용될 때 시프트 암호를 설명하기 위해 Caesar Cipher라는 이름이 가끔 사용됩니다. 프
이 방식에서는 단순 치환 암호의 경우와 같이 한 글자가 아닌 한 쌍의 글자를 암호화한다. playfair cipher에서는 처음에 키 테이블이 생성됩니다. 키 테이블은 일반 텍스트를 암호화하는 키 역할을 하는 5×5 알파벳 그리드입니다. 25개의 알파벳 각각은 고유해야 하며 26개 대신 25개의 알파벳만 필요하므로 테이블에서 알파벳의 한 글자(보통 J)가 생략됩니다. 일반 텍스트에 J가 포함되어 있으면 I로 대체됩니다. 보낸 사람과 받는 사람이 특정 키에 대해 자습서라고 말합니다. 키 테이블에서 테이블의 첫 번째 문자(왼쪽에서
이 방식에서는 단순 치환 암호의 경우와 같이 한 글자가 아닌 한 쌍의 글자를 암호화한다. playfair cipher에서는 처음에 키 테이블이 생성됩니다. 키 테이블은 일반 텍스트를 암호화하는 키 역할을 하는 5×5 알파벳 그리드입니다. 25개의 알파벳 각각은 고유해야 하며 26개 대신 25개의 알파벳만 필요하므로 테이블에서 알파벳의 한 글자(보통 J)가 생략됩니다. 일반 텍스트에 J가 포함되어 있으면 I로 대체됩니다. 보낸 사람과 받는 사람이 특정 키에 대해 자습서라고 말합니다. 키 테이블에서 테이블의 첫 번째 문자(왼쪽에서
RSA는 공개 키와 개인 키의 두 가지 키에서 작동하는 비대칭 암호화 알고리즘입니다. 알고리즘 Begin 1. Choose two prime numbers p and q. 2. Compute n = p*q. 3. Calculate phi = (p-1) * (q-1). 4. Choose an integer e such that 1 < e < phi(n) and gcd(e, phi(n)) = 1; i.e., e and phi(n) a
선형 대수를 기반으로 하는 Hill cipher는 암호화에서 다중 그래픽 대체 암호입니다. 메시지를 암호화하려면: 키 스트링과 메시지 스트링은 매트릭스 형태로 표현된다. 그런 다음 모듈로 26에 대해 곱합니다. 키 행렬은 메시지를 해독하기 위해 역행렬을 가져야 합니다. 메시지를 해독하려면: 암호화된 메시지는 암호 해독 메시지를 얻기 위해 모듈로 26에 대한 암호화에 사용되는 역 키 행렬을 곱합니다. 예를 들어 키 매트릭스 1 0 1 2 4 0 3 5 6 행렬 형식의 메시지 문자열 ABC - 0 1 2 암호화 위의 두 행렬을
Vigenere Cipher는 알파벳 텍스트를 암호화하는 일종의 다중 알파벳 대체 방법입니다. Vigenere Cipher Table은 A부터 Z까지의 알파벳을 26행으로 쓰는 방식으로 암호화와 복호화를 위해 사용됩니다. 암호화 키: 환영합니다 메시지: Thisistutorialspoint 여기서 우리는 길이가 원래 메시지 길이와 같아질 때까지 주어진 키를 반복하여 키를 얻어야 합니다. 암호화를 위해 메시지의 첫 글자와 키(예:T 및 W)를 사용합니다. T 행과 W 열이 일치하는 Vigenere Cipher Table(
Affine 암호에서 알파벳의 각 문자는 해당 숫자로 매핑되며 단일 알파벳 대체 암호의 한 유형입니다. 암호화는 간단한 수학 함수를 사용하여 수행되고 다시 문자로 변환됩니다. m 크기의 알파벳 문자는 먼저 Affine 암호에서 0 ... m-1 범위의 정수에 매핑됩니다. Affine 암호의 키는 a와 b의 2개의 숫자로 구성됩니다. a는 m에 대해 상대적으로 소수가 되도록 선택해야 합니다. 암호화 정수를 변환하기 위해 각 일반 텍스트 문자가 암호문 문자에 해당하는 또 다른 정수에 해당하는 모듈식 산술을 사용합니다. 단일 문자에
Kadane의 알고리즘은 정수 배열에서 최대 하위 배열 합계를 찾는 데 사용됩니다. 여기에서 우리는 이 알고리즘을 구현하기 위한 C++ 프로그램에 대해 논의할 것입니다. 알고리즘 Begin Function kadanes(int array[], int length): Initialize highestMax = 0 currentElementMax = 0 for i = 0 to length-1 currentE
여기서 우리는 시퀀스 세트의 모든 시퀀스에 공통적인 가장 긴 부분 시퀀스를 찾는 C++ 프로그램에 대해 논의할 것입니다. 알고리즘 Begin Take the array of strings as input. function matchedPrefixtill(): find the matched prefix between string s1 and s2 : n1 = store length of string s1. n2 = store length of string s2. f
여기에서는 두 개 이상의 시퀀스를 부분 시퀀스로 포함하는 최단 시퀀스를 찾는 C++ 프로그램에 대해 설명합니다. 알고리즘 Begin function ShortestSubSeq() returns supersequence of A and B: 1) Declare an array ss[i][j] which contains length of shortest supersequence for A[0 .. i-1] and B[0 .. j-1]. 2) Find the lengt
여기서 우리는 시퀀스 세트의 모든 시퀀스에 공통적인 가장 긴 부분 시퀀스를 찾는 C++ 프로그램에 대해 논의할 것입니다. 알고리즘 Begin Take the array of strings as input. function matchedPrefixtill(): find the matched prefix between string s1 and s2 : n1 = store length of string s1. n2 = store length of string s2. f
여기에서는 각 단어가 회문(Palindrome)이 되는 방식으로 단어를 분할하는 여러 가지 방법을 찾는 C++ 프로그램에 대해 논의할 것입니다. 알고리즘 Begin Take the word as input. Function partitionadd(vector<vector<string> > &u, string &s, vector<string> &tmp, int index): if (index == 0)
여기서 우리는 Trie를 구현하는 C++ 프로그램에 대해 논의할 것입니다. 큰 문자열 데이터 세트에서 키를 효율적으로 검색하는 데 사용되는 트리 기반 데이터 구조입니다. 함수 및 의사코드 Begin function insert() : If key not present, inserts key into trie. If the key is prefix of trie node, just mark leaf node. End Begin function deleteNode() If tree is e
C에서는 qsort() 함수를 얻습니다. 이것은 퀵 정렬 기술을 사용하여 일부 배열을 정렬하는 데 사용됩니다. 이 함수에서 우리는 비교기 함수를 전달해야 합니다. 이 비교기 함수는 두 개의 인수를 취합니다. 그런 다음 그것들을 비교하고 그들 사이의 상대적인 순서를 얻습니다. 이 두 인수는 포인터이며 유형은 const void*로 캐스트됩니다. 구문은 아래와 같습니다 - int comparator(const void* p1, const void* p2); 반환 값은 세 가지 유형입니다 - 0 미만. p1이 가리키는 요소가 두 번째
C 또는 C++에서 우리는 다양한 종류의 오류에 직면합니다. 이러한 오류는 5가지 유형으로 분류할 수 있습니다. 다음과 같습니다 - 구문 오류 런타임 오류 링커 오류 논리적 오류 의미적 오류 이러한 오류를 하나씩 살펴보겠습니다 − 구문 오류 이러한 종류의 오류는 C++ 작성 기술이나 구문의 규칙을 위반할 때 발생합니다. 이러한 종류의 오류는 일반적으로 컴파일 전에 컴파일러에 의해 표시됩니다. 때때로 이것을 컴파일 시간 오류라고 합니다. 이 예에서는 한 줄 뒤에 세미콜론을 넣지 않으면 구문 오류가 발생하는 방법을 볼 수 있습
getopt()는 명령줄 옵션을 사용하는 데 사용되는 내장 C 함수 중 하나입니다. 이 함수의 구문은 다음과 같습니다 - getopt(int argc, char *const argv[], const char *optstring) opstring은 문자 목록입니다. 각각은 단일 문자 옵션을 나타냅니다. 이 함수는 많은 값을 반환합니다. 다음과 같습니다 - 옵션이 값을 취하는 경우 해당 값은 optarg에 의해 지정됩니다. 더 이상 처리할 옵션이 없으면 -1을 반환합니다. 인식할 수 없는 옵션임을 나타내기 위해 ?를 반환하고 op
이 mbrtowc() 함수는 멀티바이트 시퀀스를 와이드 문자열로 변환하는 데 사용됩니다. 멀티바이트 문자의 길이를 바이트 단위로 반환합니다. 구문은 아래와 같습니다. mbrtowc (wchar_t* wc, const char* s, size_t max, mbstate_t* ps) 인수는 - wc는 결과 와이드 문자가 저장될 위치를 가리키는 포인터입니다. 입력으로 멀티바이트 문자열에 대한 포인터입니다. max는 검사할 수 있는 s의 최대 바이트 수입니다. ps는 멀티바이트 문자열을 해석할 때 변환 상태를 가리키고 있습니다. 예시
분할 오류는 잘못된 배열 인덱스에 액세스하거나 제한된 주소를 가리키는 등의 메모리 액세스 위반으로 인해 발생하는 런타임 오류 중 하나입니다. 이 기사에서는 GDB 도구를 사용하여 이러한 유형의 오류를 감지하는 방법을 살펴보겠습니다. . 오류를 찾기 위한 코드와 해당 단계를 살펴보겠습니다. 예 #include main() { int* ptr =NULL; *ptr =1; //알 수 없는 메모리 위치에 접근을 시도합니다. printf(%p\n, ptr);} gcc –g program_name.c를 사용하여 코드를 컴파일하고 ./a.o
고정밀 타이머를 생성하기 위해 크로노 라이브러리를 사용할 수 있습니다. 이 라이브러리에는 고해상도 시계가 있습니다. 나노초 단위로 계산할 수 있습니다. 이 프로그램에서 우리는 나노초 단위의 실행 시간을 볼 것입니다. 처음에 시간 값을 취한 다음 마지막에 다른 시간 값을 취한 다음 경과 시간을 얻기 위해 차이를 찾습니다. 여기서 우리는 때때로 효과를 일시 중지하기 위해 공백 루프를 사용하고 있습니다. 예시 #include <iostream> #include <chrono> typedef std::chrono::
여기서는 C를 사용하여 주어진 범위에서 난수를 생성하는 방법을 볼 것입니다. 이 문제를 해결하기 위해 srand() 함수를 사용할 것입니다. 현재 시간은 srad() 함수를 시드하는 데 사용됩니다. 이 함수는 임의의 범위에서 난수를 생성할 수 없으며 0에서 일부 값 사이의 숫자를 생성할 수 있습니다. 따라서 이를 위해서는 한 가지 트릭을 따라야 합니다. 0에서 (상한 – 하한 + 1) 사이의 난수를 생성한 다음 상쇄를 위한 하한을 추가합니다. 예시 #include <stdio.h> #include <stdlib.h