
이 글에서는 패턴 검색을 위한 유한 자동 알고리즘을 실행하는 프로그램에 대해 논의할 것입니다. 텍스트[0...n-1]와 패턴[0...m-1]이 제공됩니다. text[]에서 pattern[]의 모든 항목을 찾아야 합니다. 이를 위해 우리는 text[]를 전처리하고 그것을 나타내기 위해 2차원 배열을 만들 것입니다. 그 다음에는 text[]의 요소와 오토마타의 여러 상태 사이를 순회하기만 하면 됩니다. 예시 #include<stdio.h> #include<string.h> #define total_chars 2
이 기사에서는 주어진 배열의 각 요소에 대한 계수가 동일하도록 정수 k를 찾는 프로그램에 대해 논의할 것입니다. 예를 들어 배열이 주어졌다고 가정해 보겠습니다. arr = {12, 22, 32} 그러면 출력 값은 k =1, 2, 5, 10입니다. y)에 있는 두 값의 경우를 취합니다. 그러면 (y+차이)%k =y%k가 됩니다. 이 문제를 해결하면 difference%k = 0 따라서 배열의 최대 및 최소 요소의 차이에 대한 모든 제수를 찾은 다음 나머지가 배열의 모든 요소에 대해 동일한지 여부를 각 제수에 대해 확인합니다. 예
이 기사에서는 Great Circle Distance 공식을 사용하여 약 50km 미만의 택시를 찾는 프로그램에 대해 설명합니다. 택시가 필요한 사람들의 이름과 좌표, 사용 가능한 모든 택시의 좌표가 포함된 JSON 파일을 받았다고 가정해 보겠습니다. 이를 해결하기 위해 GPS 좌표를 이중으로 변환합니다. 이중 형식에서 최종적으로 도 단위를 라디안으로 변환합니다. 그런 다음 궁극적으로 Great Circle Distance 공식을 적용하여 사용자 위치에서 50km 떨어진 곳에서 사용할 수 있는 택시를 찾을 수 있습니다. 입력
이 기사에서는 첫 번째 충돌 지점, 즉 두 시리즈가 모두 갖는 첫 번째 지점을 찾는 프로그램에 대해 논의할 것입니다. 여기에서 5개의 변수 a, b, c, d 및 n이 주어집니다. 각각 n자리를 갖는 두 개의 산술 진행 시리즈를 만들어야 합니다. b, b+a, b+2a, ….b+(n-1)a d, d+c, d+2c, ….. d+(n-1)c 그리고 주어진 두 시리즈가 가지고 있는 첫 번째 공통점을 찾으세요. 이를 해결하기 위해 첫 번째 시리즈의 숫자를 생성합니다. 그리고 각 숫자에 대해 두 번째 시리즈의
이 기사에서는 이진 검색을 사용하여 주어진 그래프의 최소 정점 커버 크기를 찾는 프로그램에 대해 논의할 것입니다. 최소 정점 커버는 그래프의 모든 모서리가 해당 세트의 정점 중 하나에 발생하도록 주어진 그래프의 정점 세트입니다. 예를 들어, 그래프 2 ---- 4 ---- 6 | | | | | | 3 ---- 5 여기에서 최소 정점 커버는 정점 3과 4를 포함합니다. 그래프의 모든 모서리는 그래프의 3 또는 4 정점에 입사합니다. 예시 #include<bits/stdc++.h>
이 기사에서 우리는 합 자체가 한 자릿수가 되고 더 이상 합산할 수 없을 때까지 숫자의 자릿수의 합을 찾는 프로그램에 대해 논의할 것입니다. 예를 들어, 숫자 14520의 경우를 가정합니다. 이 숫자의 자릿수를 더하면 1 + 4 + 5 + 2 + 0 =12가 됩니다. 이것은 한 자리 숫자가 아니므로 받은 숫자의 자릿수를 더 추가합니다. . 그것들을 더하면 1 + 2 =3이 됩니다. 이제 3은 한 자리 숫자 자체이고 더 이상 더할 수 없기 때문에 최종 답입니다. 이를 해결하기 위해 우리는 9로 나누어 떨어지는 수의 자릿수 합이
이 기사에서는 주어진 점을 덮는 가장 적합한 직사각형을 찾는 프로그램에 대해 논의할 것입니다. 이 문제에서 한 점의 좌표(x,y)와 길이/너비 =l/b(말하자면)의 비율이 제공됩니다. 주어진 점을 포함하고 치수가 주어진 비율을 따르는 직사각형의 좌표를 찾아야 합니다. 여러 개의 직사각형이 존재하는 경우 유클리드의 중심과 주어진 점 사이의 거리가 가장 짧은 것을 선택해야 합니다. 이를 해결하기 위해 먼저 비율 l/b를 최소화합니다. 그 후 min(n/l,m/b) 값이 (n,m) 영역(2d 공간 허용)에 머물도록 합니다. 먼저 (x
이 기사에서 우리는 주어진 배열의 요소들의 곱에서 첫 번째 숫자를 찾는 프로그램에 대해 논의할 것입니다. 예를 들어 배열이 주어졌다고 가정해 보겠습니다. arr = {12, 5, 16} 그런 다음 이러한 요소의 제품은 12*5*16 =960이 됩니다. 따라서 결과, 즉 이 경우 제품의 첫 번째 숫자는 9가 됩니다. 예시 #include <bits/stdc++.h> using namespace std; int calc_1digit(int arr[], int x) { long long int pro
이 글에서는 주어진 가로선과 세로선의 교차점을 연결하여 만들 수 있는 삼각형의 개수를 찾는 프로그램에 대해 설명합니다. 예를 들어 다음과 같은 선분을 받았다고 가정해 보겠습니다. 여기에는 3개의 교차점이 있습니다. 따라서 이 점을 사용하여 만들 수 있는 삼각형의 수는 3입니다. C2 . | ---|--------|-- | | | --|---| |
이 기사에서는 주어진 숫자 N의 패리티를 찾는 프로그램에 대해 논의할 것입니다. 패리티는 숫자의 이진 표현에서 설정된 비트 수(1의 수)로 정의됩니다. 바이너리 표현에서 1의 개수가 짝수이면 패리티를 짝수 패리티라고 하고, 바이너리 표현에서 1의 개수가 홀수이면 패리티를 홀수 패리티라고 합니다. 주어진 숫자가 N이면 다음 연산을 수행할 수 있습니다. 1) 2) 4) 8) 16) 이러한 모든 작업이 완료되면 y의 가장 오른쪽 비트가 숫자의 패리티를 나타냅니다. 비트가 1이면 패리티가 홀수이고 비트가 0이면 패리티가
이 글에서는 Markov chain에서 주어진 시간 안에 초기 상태에서 최종 상태에 도달할 확률을 구하는 프로그램에 대해 논의할 것입니다. 마르코프 체인은 다양한 상태와 한 상태에서 다른 상태로 이동할 관련 확률로 구성된 무작위 프로세스입니다. 한 상태에서 다른 상태로 이동하는 데 단위 시간이 걸립니다. Markov Chain은 방향 그래프로 나타낼 수 있습니다. 문제를 해결하기 위해 주어진 마르코프 체인에서 행렬을 만들 수 있습니다. 해당 행렬에서 (a,b) 위치의 요소는 a 상태에서 b 상태로 이동할 확률을 나타냅니다. 이
이 기사에서는 방정식의 계수가 주어졌을 때 포물선의 꼭짓점, 초점 및 방향을 찾는 프로그램에 대해 논의할 것입니다. 포물선은 곡선의 모든 점이 초점이라는 단일 점에서 등거리에 있는 곡선입니다. 포물선에 대한 일반 방정식은 다음과 같습니다. y = ax2 + bx + c 이 방정식의 경우 다음과 같이 정의됩니다. Vertex -(-b/2a, 4ac - b2/4a) Focus - (-b/2a, 4ac - b2+1/4a) Directrix - y = c - (b2 +1)4a 예시 #include <iostream> usi
이 기사에서는 두 개의 평행선만 주어진 모든 좌표점을 가질 수 있는지 여부를 찾는 프로그램에 대해 논의할 것입니다. 이를 위해 좌표가 (i,rr[i])가 되도록 배열이 제공됩니다. 배열이 주어졌다고 가정해 봅시다. arr = {2,6,8,12,14} 그런 다음 이 점을 두 개의 평행선에 가질 수 있습니다. 첫 번째 줄에는 (1,2), (3,8)이 포함됩니다. 및 (5,14) . 나머지 좌표가 있는 두 번째 줄, 즉 (2,6) 및 (4,12). 이 문제는 주어진 선에 의해 만들어진 선의 기울기를 비교하여 해결할 수 있습니다.
이 기사에서는 주어진 행렬에서 두 셀 사이에 경로가 존재하는지 여부를 찾는 프로그램에 대해 논의할 것입니다. 가능한 값이 0, 1, 2 및 3인 정방 행렬이 주어졌다고 가정해 보겠습니다. 여기에서 0은 빈 벽을 의미합니다. 1은 소스를 의미합니다. 2는 목적지를 의미합니다. 3은 빈 셀을 의미합니다. 매트릭스에는 하나의 소스와 대상만 있을 수 있습니다. 이 프로그램은 주어진 행렬에서 대각선이 아닌 가능한 모든 방향으로 움직이는 소스에서 목적지까지 가능한 경로가 있는지 확인하는 것입니다. 예시 #include<bits/s
배열로 표현되는 숫자는 배열의 단일 요소에 숫자의 각 자릿수를 저장합니다. 배열의 길이는 배열의 자릿수와 같습니다. 즉, 4자리 숫자의 경우 길이 =3입니다. 배열의 각 요소는 한 자리 숫자입니다. 숫자는 마지막 요소가 숫자의 최하위 숫자를 저장하는 방식으로 저장됩니다. 그리고 첫 번째 요소는 숫자의 최상위 숫자를 저장합니다. 예를 들어, 숫자 − 351932는 {3,5,1,9,3,2}로 저장됩니다. 이 숫자에 1을 추가하려면 배열의 마지막 요소에 1을 추가해야 하며 캐리를 전파해야 하는지 여부를 확인합니다. 마지막 비트의 숫자
배열은 데이터 유형이 동일한 여러 요소의 컨테이너입니다. 요소의 인덱스는 0부터 시작합니다. 즉, 첫 번째 요소의 인덱스는 0입니다. 이 문제에서는 두 개의 짝수 인덱스 숫자와 두 개의 홀수 인덱스 숫자 사이의 절대 차이를 찾아야 합니다. 짝수 인덱스 번호 =0,2,4,6,8…. 홀수 색인 번호 =1,3,5,7,9… 절대 차이는 두 요소 간의 차이 계수입니다. 예를 들어, 15와 7의 절대 차이 =(|15 - 7|) =8 Input: arr = {1 , 2, 4, 5, 8} Output : Absolute differen
각도 두 광선이 한 점에서 만날 때 형성됩니다. 이 광선이 만나는 평면상의 점이 정점입니다. 호 원의 일부는 각도로 설명되는 원주의 일부입니다. 이 문제에서는 원의 각도가 주어집니다. 그리고 주어진 원의 지름을 사용하여 호의 길이를 찾아야 합니다. 예를 들어, Input : Angle = 45° Diameter = 28 Output : Arc = 11 설명 호의 길이 =(원주) X (각도/360°) =(π * d)*(각도/360°) 주어진 각도와 지름으로부터 호의 길이를 계산하는 프로그램을 만들기 위해 우리는 이 공
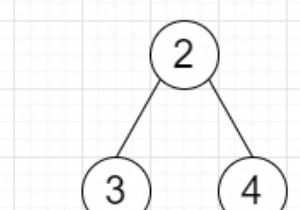
이진 트리의 반시계 방향 나선 순회는 순회하면 나선을 만들지만 역순으로 트리의 요소를 순회하는 것입니다. 다음 그림은 이진 트리의 반시계 방향 나선형 순회를 보여줍니다. 이진 트리의 나선형 탐색에 대해 정의된 알고리즘은 다음과 같은 방식으로 작동합니다. - 두 개의 변수 i와 j가 초기화되고 값은 i =0 및 j =변수의 높이와 같습니다. 플래그는 섹션이 인쇄되는 동안 확인하는 데 사용됩니다. 플래그는 초기에 false로 설정됩니다. i
배열은 동일한 데이터 유형의 요소 모음입니다. 정렬된 배열 오름차순 또는 내림차순으로 저장된 요소가 있는 배열입니다. 고유 개수는 동일하지 않은 요소의 수입니다. 절대 고유 개수는 요소, 즉 부호가 없는 요소(부호 없는 값)의 절대값에 대한 고유 개수입니다. 이 프로그램에서 우리는 정렬된 배열에서 절대 고유 개수를 찾을 것입니다. 즉, 배열의 각 요소의 절대값을 고려하면 고유한 값의 수를 계산합니다. 예를 들어, Input : [-3 , 0 , 3 , 6 ] Output : 3 배열에는 3개의 고유한 절대값이 있으며 요소는
null 문자를 사용하여 종료되는 문자 배열에 대한 포인터를 반환하는 basic_string c_str 함수입니다. null 문자 종료가 있는 문자열 값을 갖는 내장 메소드입니다. C++에서 c_str 함수를 정의하는 구문 - const Char ptr* c_str() const 기능 정보 C++ STL 라이브러리에 내장된 메서드입니다. 메소드에 매개변수를 전달할 수 없습니다. char 포인터를 반환합니다. 이 포인터는 NULL로 끝나는 문자 배열을 가리킵니다. 예시 #include <bits/stdc++.h> #in