
![Tkinter 창에서 종료(또는 [ X ]) 비활성화](/article/uploadfiles/202204/2022040619470686_S.jpg)
대기열은 선입선출 데이터 구조입니다. 대기열은 그래프 탐색 알고리즘 너비 우선 검색 등을 위해 다른 영역에서 사용됩니다. 대기열에는 몇 가지 기본 작업이 있습니다. 여기서 우리는 이러한 queue 작업을 볼 것이고, queue ADT를 사용하는 한 가지 예를 볼 것입니다. ADT(추상 데이터 유형)는 특정 종류의 데이터 유형으로, 그 동작은 값 집합과 연산 집합에 의해 정의됩니다. 이러한 데이터 유형을 사용할 수 있으므로 추상이라는 키워드가 사용되며 다른 작업을 수행할 수 있습니다. 그러나 이러한 작업이 작동하는 방식은 사용자에게
걸음 수 방법은 알고리즘을 분석하는 방법 중 하나입니다. 이 방법에서는 하나의 명령어가 실행되는 횟수를 계산합니다. 그로부터 알고리즘의 복잡성을 찾으려고 노력할 것입니다. 순차 검색을 수행하는 알고리즘이 하나 있다고 가정합니다. 각 명령어가 c1, c2, … 실행하는 데 시간이 걸리면 이 알고리즘의 시간 복잡도를 알아내려고 합니다. 알고리즘 횟수 비용 seqSearch(arr, n, 키) 나는 :=0 내가
이 섹션에서는 두 행렬을 곱하는 방법을 살펴보겠습니다. 행렬 곱셈은 이 조건을 만족하는 경우에만 수행할 수 있습니다. 두 행렬이 A와 B이고 차원이 A(m x n) 및 B(p x q)라고 가정하면 n =p인 경우에만 결과 행렬을 찾을 수 있습니다. 그러면 결과 행렬 C의 차수는 (m x q)가 됩니다. 알고리즘 matrixMultiply(A, B): Assume dimension of A is (m x n), dimension of B is (p x q) Begin if n is not same as p, t
상각 분석 이 분석은 간헐적 작업이 매우 느리지만 매우 자주 실행되는 대부분의 작업이 더 빠를 때 사용됩니다. 데이터 구조에서 해시 테이블, 분리 집합 등에 대한 분할 상환 분석이 필요합니다. Hash-table에서 탐색 시간 복잡도는 대부분 O(1)이지만 가끔 O(n) 연산을 수행하기도 한다. 대부분의 경우 해시 테이블에서 요소를 검색하거나 삽입하려는 경우 작업을 수행하는 데 일정한 시간이 소요되지만 충돌이 발생하면 충돌 해결을 위해 O(n)배 작업이 필요합니다. 집계 방법 집계 방법은 총 비용을 찾는 데 사용됩니다. 많은
여기서 우리는 배열 데이터 구조의 몇 가지 기본 작업을 볼 것입니다. 이러한 작업은 - 횡단 삽입 삭제 검색 업데이트 트래버스는 배열의 모든 요소를 스캔합니다. 삽입 작업은 배열의 지정된 위치에 일부 요소를 추가하는 것이고 삭제는 배열에서 요소를 삭제하고 삭제 후 다른 요소의 각 위치를 업데이트하는 것입니다. 검색은 배열에 있는 일부 요소를 찾는 것이고 업데이트는 주어진 위치에서 요소의 값을 업데이트하는 것입니다. 더 나은 아이디어를 얻기 위해 하나의 C++ 예제 코드를 살펴보겠습니다. 예시 #include<iostr
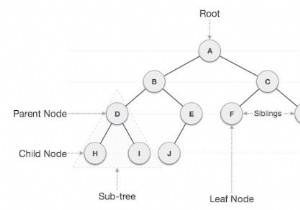
여기에서 우리는 컴퓨터 메모리에서 이진 트리를 표현하는 방법을 볼 것입니다. 나타내는 두 가지 방법이 있습니다. 배열을 사용하고 연결 리스트를 사용하고 있습니다. 다음과 같은 트리가 하나 있다고 가정해 보겠습니다. - 배열 표현은 레벨 순서 방식을 사용하여 요소를 스캔하여 트리 데이터를 저장합니다. 따라서 레벨별로 노드를 저장합니다. 일부 요소가 누락된 경우 공백이 남습니다. 위 트리의 표현은 아래와 같다 - 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 10 5 16 - 8 15 20 - - - - -
이 섹션에서 우리는 하나의 이진 트리 데이터 구조의 몇 가지 중요한 속성을 볼 것입니다. 이와 같은 이진 트리가 있다고 가정합니다. 일부 속성은 - 레벨 l의 최대 노드 수는 $2^{l-1}$ 입니다. 여기서 레벨은 루트 자체를 포함하여 루트에서 노드까지의 경로에 있는 노드 수입니다. 루트 수준을 1로 고려하고 있습니다. 높이 h의 이진 트리에 존재하는 최대 노드 수는 $2^{h}-1$입니다. 여기서 높이는 루트에서 리프 경로의 최대 노드 수입니다. 여기서 우리는 노드가 하나인 트리의 높이가 1이라고 생각합니다. n개의 노드
이 섹션에서는 이진 검색 트리에 있는 키를 탐색하는 다양한 탐색 알고리즘을 볼 것입니다. 이러한 순회는 Inorder 순회, Preorder 순회, Postorder 순회 및 레벨 순서 순회입니다. 다음과 같은 트리가 하나 있다고 가정해 보겠습니다. - Inorder 순회 시퀀스는 다음과 같습니다. − 5 8 10 15 16 20 23 선주문 순회 시퀀스는 다음과 같습니다. − 10 5 8 16 15 20 23 Postorder 순회 시퀀스는 다음과 같습니다. − 8 5 15 23 20 16 10 레벨 순서 순회 시퀀스
이 섹션에서는 이진 검색 트리에 대한 수준 순서 탐색 기술을 볼 것입니다. 다음과 같은 트리가 하나 있다고 가정해 보겠습니다. - 순회 순서는 다음과 같습니다:10, 5, 16, 8, 15, 20, 23 알고리즘 levelOrderTraverse(root): Begin define queue que to store nodes insert root into the que. while que is not empty, do
이 섹션에서는 이진 검색 트리에 대한 후위 순회 기술(재귀)을 볼 것입니다. 다음과 같은 트리가 하나 있다고 가정해 보겠습니다. - 순회 순서는 다음과 같습니다:8, 5, 15, 23, 20, 16, 10 알고리즘 postorderTraverse(root): Begin if root is not empty, then postorderTraversal(left of root) postorderTraversal(right of ro
이 섹션에서는 이진 검색 트리에 대한 선주문 순회 기술(재귀)을 볼 것입니다. 다음과 같은 트리가 하나 있다고 가정해 보겠습니다. - 순회 순서는 10, 5, 8, 16, 15, 20, 23과 같습니다. 알고리즘 preorderTraverse(root): Begin if root is not empty, then print the value of root preorderTraversal(left of root) &n
이진 검색 트리는 몇 가지 속성이 있는 이진 트리입니다. 이러한 속성은 다음과 같습니다 - 모든 이진 검색 트리는 이진 트리입니다. 모든 왼쪽 자식은 루트보다 낮은 값을 갖습니다. 모든 올바른 자식은 루트보다 더 큰 가치를 가질 것입니다. 이상적인 이진 검색 트리는 동일한 값을 두 번 유지하지 않습니다. 다음과 같은 트리가 하나 있다고 가정해 보겠습니다. - 이 트리는 하나의 이진 검색 트리입니다. 언급된 모든 속성을 따릅니다. 요소를 중위 순회 모드로 순회하면 5, 8, 10, 15, 16, 20, 23을 얻을 수 있습
이 섹션에서는 그래프 데이터 구조가 무엇인지, 그리고 이 구조의 탐색 알고리즘을 살펴보겠습니다. 그래프는 하나의 비선형 데이터 구조입니다. 그것은 일부 노드와 연결된 가장자리로 구성됩니다. 가장자리는 방향성이 있거나 방향이 없을 수 있습니다. 이 그래프는 G(V, E)로 나타낼 수 있습니다. 다음 그래프는 G({A, B, C, D, E}, {(A, B), (B, D), (D, E), (B, C), (C, A )}) 그래프에는 두 가지 유형의 탐색 알고리즘이 있습니다. 이를 너비 우선 탐색과 깊이 우선 탐색이라고 합니다. BF
여기서 우리는 그래프의 DFS 및 BFS 알고리즘의 다른 응용 프로그램이 무엇인지 볼 것입니다. DFS 또는 깊이 우선 탐색은 여러 곳에서 사용됩니다. 몇 가지 일반적인 용도는 - 무가중 그래프에서 DFS를 수행하면 모든 쌍의 최단 경로 트리에 대한 최소 스패닝 트리가 생성됩니다. DFS를 사용하여 그래프에서 주기를 감지할 수 있습니다. BFS 동안 하나의 백 에지를 얻는다면 하나의 주기가 있어야 합니다. DFS를 사용하여 주어진 두 정점 u와 v 사이의 경로를 찾을 수 있습니다. 우리는 작업 간의 주어진 종속성에서 작업을 예약
스패닝 트리 모든 정점이 최소 모서리 수로 연결된 무방향 그래프의 하위 집합입니다. 모든 정점이 하나의 그래프에 연결되어 있으면 적어도 하나의 스패닝 트리가 존재합니다. 그래프에는 하나 이상의 스패닝 트리가 있을 수 있습니다. 최소 스패닝 트리 최소 스패닝 트리(MST) 모든 정점을 가능한 최소 총 간선 가중치로 연결하는 연결된 가중치 무방향 그래프의 간선 부분 집합입니다. MST를 유도하기 위해서는 Prim의 알고리즘이나 Kruskal의 알고리즘을 사용할 수 있습니다. 따라서 이 장에서는 Prim의 알고리즘에 대해 설명합니다.
베르누이 분포는 x =0 및 x =1로 레이블이 지정된 두 가지 가능한 결과를 갖는 이산 분포입니다. x =1은 성공이고 x =0은 실패입니다. q =1 – p와 같이 성공은 확률 p로 발생하고 실패는 확률 q로 발생합니다. 그래서 $$P\lgroup x\rgroup=\begin{cases}1-p\:for &x =0\\p\:for &x =0\end{cases}$$ 이것은 다음과 같이 쓸 수도 있습니다. - $$P\l그룹 x\r그룹=p^{n}\l그룹1-p\r그룹^{1-n}$$ 예시 #include <iostream>
이항 분포는 N개의 베르누이 트레일에서 n개의 성공을 얻는 이산 확률 분포 Pp(n | N)입니다(x =0 및 x =1로 레이블이 지정된 두 가지 가능한 결과를 가짐. x =1은 성공이고 x =0은 실패. 성공은 확률 p로 발생하고 실패는 확률 q로 q =1 – p입니다.) 따라서 이항 분포는 다음과 같이 쓸 수 있습니다. $$P_{p}\lgroup n\:\arrowvert\ N\rgroup=\left(\begin{array}{c}N\\ n\end{array}\right) p^{n}\lgroup1-p \r그룹^{N-n}$$ 예시
기하학적 분포는 n =0, 1, 2, …에 대한 이산 확률 분포입니다. 확률 밀도 함수가 있습니다. $$P\l그룹 n\r그룹=p\l그룹1-p\r그룹^{n}$$ 분포 함수는 - $$D\l그룹 n\rgroup=\displaystyle\sum\limits_{i=0}^n P\l그룹 i \rgroup=1-q^{n+1}$$ 예시 #include <iostream> #include <random> using namespace std; int main(){ const int nrolls = 10
음의 이항 분포는 음의 이항 이산 분포에 따라 정수를 생성하는 난수 분포입니다. 이것은 파스칼 분포로 알려져 있으므로 음의 이항 분포는 다음과 같이 쓸 수 있습니다. $$P\l그룹 i\arrowvert k,p\rgroup=\l그룹 \frac{k+i-1}{i}\r그룹 p^{k}\l그룹 1-p\rgroup^{i}$$ 예시 #include <iostream> #include <random> using namespace std; int main(){ const int nrolls = 10000
정수 세트가 정렬된 순서로 제공되고 다른 배열 freq는 빈도 수로 지정됩니다. 우리의 임무는 모든 검색에 대한 최소 비용을 찾기 위해 해당 데이터로 이진 검색 트리를 만드는 것입니다. 보조 배열 비용[n, n]은 하위 문제의 솔루션을 해결하고 저장하기 위해 생성됩니다. 비용 매트릭스는 상향식 방식으로 문제를 해결하기 위한 데이터를 보유합니다. 입력 − 노드와 빈도로 키 값입니다. Keys = {10, 12, 20} Frequency = {34, 8, 50} 출력 − 최소 비용은 142입니다. 주어진 값에서 가능한 BST