

단어 목록이 있다고 가정합니다. 여기에서 각 단어는 각 문자의 모스 부호를 연결하여 작성할 수 있습니다. 예를 들어 cba라는 단어는 -.-..--...로 쓸 수 있습니다. 이것은 연결 -.-.입니다. | -... | .-). 이러한 연결을 단어 변환이라고 합니다. 국제 모스 부호는 다음과 같이 각 문자가 일련의 점과 대시에 매핑되는 표준 인코딩을 정의한다는 것을 알고 있습니다. a는 .-에 매핑되고, b는 -...에 매핑되고, c 는 -.-.에 매핑됩니다. 다음은 영어 알파벳의 26자 전체 목록입니다. - [.-,-...,-
문자열 S가 있고 주어진 문자열의 문자를 왼쪽에서 오른쪽으로 줄에 써야 한다고 가정합니다. 여기서 각 줄의 최대 너비는 100단위이며, 글자를 쓰면 줄의 너비가 100단위를 초과하면 다음 줄에 기록됩니다. 우리는 또한 배열 너비를 가지고 있습니다. 여기에서 widths[0]은 a의 너비이고, widths[1]은 b의 너비입니다. 우리는 두 가지 질문에 대한 답을 찾아야 합니다 - S의 문자가 하나 이상 포함된 줄 수 마지막 줄에 사용된 너비는 얼마입니까? 답은 길이가 2인 정수 목록으로 반환됩니다. 따라서 입력이 [4,10
평면에 점 목록이 있다고 가정합니다. 세 점으로 만들 수 있는 가장 큰 삼각형의 면적을 찾아야 합니다. 따라서 입력이 [[0,0],[0,1],[1,0],[0,2],[2,0]]과 같으면 출력은 2가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − res :=0 N :=포인트 목록의 크기 0 ~ N - 2 범위의 i에 대해 i + 1 ~ N - 1 범위의 j에 대해 i + 2 ~ N 범위의 k에 대해 (x1, y1) :=포인트[i], (x2, y2) :=포인트[j], (x3, y3) :=포인트[k] res :
소문자로 된 문자열 S가 있다고 가정하고 이러한 문자는 동일한 문자의 연속적인 그룹을 형성합니다. 따라서 S와 같은 문자열이 abbxxxxzyy와 같을 때 그룹은 a, bb, xxxx, z 및 yy입니다. 그룹은 3자 이상의 문자가 있는 경우 큰 그룹이 됩니다. 우리는 모든 대규모 그룹의 시작 위치와 끝 위치를 원합니다. 따라서 입력이 abcdddeeeeaabbbcd와 같으면 출력은 [[3,5],[6,9],[12,14]]가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − ans :=새 목록 csum :=0 각, b
이진 행렬 A가 있다고 가정하고 이것이 이미지의 표현이고 이미지를 수평으로 뒤집고 반전한 후 최종적으로 결과 이미지를 반환하려고 합니다. 이미지를 수평으로 뒤집으려면 이미지의 각 행이 반전됩니다. 그리고 이미지를 반전시키려면 각각의 0이 1로 대체되고 각각의 1이 0으로 대체됩니다. 따라서 입력이 다음과 같으면 1 1 0 1 0 1 0 0 0 그러면 출력은 1 0 0 0 1 0 1 1 1 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 결과:=새 목록 A의 각 행 i에 대해 다음을 수행합니다. 역방향:=
목록 [x1, y1, x2, y2]로 표시되는 직사각형이 있다고 가정합니다. 여기서 (x1, y1)은 왼쪽 하단 모서리의 좌표이고 (x2, y2)는 상단의 좌표입니다. 오른쪽 모서리. 이제 교차 영역이 양수이면 두 개의 직사각형이 겹칩니다. 따라서 모서리나 모서리에서만 닿는 두 개의 직사각형이 겹치지 않는다는 것을 이해할 수 있습니다. 두 개의 (축 정렬) 사각형이 있는 경우 겹치는지 여부를 확인해야 합니다. 따라서 입력이 R1 =[0,0,2,2], R2 =[1,1,3,3]과 같으면 출력은 True가 됩니다. 이 문제를 해결하
소문자로 된 두 개의 문자열 A와 B가 있다고 가정합니다. 결과가 B와 같도록 A에서 두 글자를 바꿀 수 있는지 확인해야 합니다. 따라서 입력이 A =ba, B =ab와 같으면 출력은 True가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − A의 크기가 B의 크기와 같지 않으면 거짓을 반환 그렇지 않고 A와 B에 공통적이지 않은 요소가 있으면 거짓을 반환 그렇지 않고 A가 B와 동일하고 A에서 모든 문자가 구별되는 경우 거짓을 반환 그렇지 않으면 개수:=0 0~A 크기 범위의 i에 대해 A[i]
레모네이드 판매대가 있다고 가정하고 각 레모네이드의 가격은 $5입니다. 이제 고객들은 매장에서 물건을 구매하고 한 번에 하나씩 주문하기 위해 줄을 서 있습니다. 각 고객은 레모네이드를 하나만 사서 $5, $10 또는 $20 지폐로 지불할 수 있습니다. 고객이 $5를 지불하는 순 거래가 되도록 각 고객에게 정확한 변경 사항을 제공해야 합니다. 그리고 처음에는 잔고가 없습니다. 모든 고객에게 올바른 변경을 제공할 수 있는지 확인해야 합니다. 따라서 입력이 [5,5,5,10,20]과 같으면 출력은 True가 됩니다. 처음 3명의 고
양의 정수 N이 있다고 가정하고 N의 이진 표현에서 두 개의 연속 1 사이의 가장 긴 거리를 찾아야 합니다. 두 개의 연속 1이 없으면 0을 반환합니다. 따라서 입력이 22와 같으면 출력은 2가 됩니다. 이진법의 22는 10110이기 때문입니다. 22의 이진법 표현에는 세 개의 1이 있고 1의 두 개의 연속 쌍이 있습니다. 첫 번째 연속 쌍의 거리가 2이고 두 번째 연속 1 쌍의 거리가 1입니다. 답변은 이 두 거리 중 가장 큰 거리인 2가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − K :=N의 이진 표현 비
점 (0, 0)에서 시작하는 무한 그리드에 로봇이 있다고 가정합니다. 북향을 향하고 있습니다. 이제 로봇은 세 가지 가능한 명령 유형 중 하나를 받을 수 있습니다. -2:좌회전 90도 -1:우회전 90도 x 단위 앞으로 이동하려면 1에서 9 사이의 값 장애물이 되는 격자 사각형이 있습니다. 우리는 또한 장애물이라는 또 다른 배열을 가지고 있습니다. 이것은 i번째 장애물이 그리드 포인트에 있음을 나타냅니다(장애물[i][0], 장애물[i][1]). 로봇이 장애물 위로 이동하려는 경우 로봇은 계속 켜져 있습니다. 대신 이전 그리드
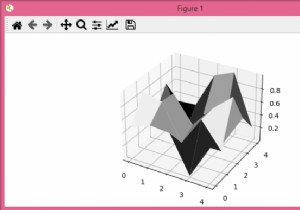
N x N 그리드가 있다고 가정하고 x, y 및 z와 축 정렬된 1 x 1 x 1 큐브를 배치합니다. 여기서 각 값 v =grid[i][j]는 그리드 셀(i, j) 위에 배치된 v 큐브의 타워를 보여줍니다. xy, yz 및 zx 평면에 대한 이러한 큐브의 투영을 봅니다. 여기에서 큐브를 위에서 볼 때, 정면에서, 측면에서 볼 때 투영을 보고 있습니다. 세 가지 투영의 전체 면적을 찾아야 합니다. 따라서 입력이 [[1,2],[3,4]]와 같은 경우 그러면 출력은 17이 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다.
N x N 그리드가 있다고 가정하고 1 x 1 x 1 큐브를 배치합니다. 그 안에. 이제 각 값에 대해 v =grid[i][j]는 그리드 셀(i, j) 위에 배치된 v 큐브의 탑을 나타냅니다. 결과 모양의 전체 표면적을 찾아야 합니다. 따라서 입력이 [[1,2],[3,4]]와 같으면 출력은 34가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − insideArea() 함수를 정의합니다. 이것은 연속으로 걸릴 것입니다 면적:=0 0~1행의 범위에 있는 i에 대해 행[i] 및 행[i + 1]이 0이 아니면 면적 :
A라는 문자열 배열이 있다고 가정합니다. S로 한 번 이동하면 S의 짝수 인덱스 문자 2개 또는 S의 홀수 인덱스 문자 2개를 교체하는 것으로 구성됩니다. 이제 두 개의 문자열 S와 T는 S로 여러 번 이동한 후 S가 T와 같으면 특별 동등합니다. 따라서 S =zzxy 및 T =xyzz인 경우 이동을 할 수 있기 때문에 특수 동등합니다. zzxy를 xzzy에서 xyzz로 바꿔 S[0]과 S[2]를 교환한 다음 S[1]과 S[3]을 교환합니다. 이제 A의 특수 등가 문자열 그룹은 다음과 같은 A의 비어 있지 않은 하위 집합입니다.
정수 배열 A가 있다고 가정하고 이제 각 정수 A[i]에 대해 [-K ~ K] 범위의 x를 선택한 다음 A[i]에 x를 추가할 수 있습니다. 이제 이 과정 후에 배열 B가 생겼습니다. B의 최대값과 B의 최소값 사이에서 가능한 가장 작은 차이를 찾아야 합니다. 따라서 입력이 A =[0,10], K =2와 같으면 출력은 B =[2,8]과 같이 6이 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − MAX :=(최대 A) - K MIN :=(최소 A) + K 차이:=MAX - MIN 차이 <0이 0이 아니면 0을 반환
최근 요청을 계산하기 위해 RecentCounter라는 클래스를 작성한다고 가정합니다. 이 클래스에는 ping(t) 메서드가 하나만 있습니다. 여기서 t는 밀리초 단위의 시간을 나타냅니다. 이것은 3000밀리초 전부터 지금까지 이루어진 핑 수를 반환합니다. 현재 핑을 포함하여 시간이 [t - 3000, t]인 모든 핑이 계산됩니다. 그리고 모든 콜 토핑이 이전보다 엄격하게 더 큰 t 값을 사용한다는 것이 보장됩니다. 따라서 입력이 Call ping 4번 ping(1), ping(100), ping(3001), ping(3002)과
로그 배열이 있다고 가정합니다. 해당 배열에서 각 항목은 공백으로 구분된 단어 문자열입니다. 각 로그의 첫 번째 단어는 영숫자 식별자입니다. 그런 다음 아래와 같은 다양한 유형의 문자열이 있습니다 - id 뒤의 각 단어는 소문자로만 구성됩니다. id 뒤의 각 단어는 숫자로만 구성됩니다. 이 두 가지 유형의 로그를 각각 문자 로그 및 숫자 로그라고 합니다. 그리고 ti는 각 로그의 id 뒤에 적어도 하나의 단어가 있음을 보장합니다. 모든 문자 로그가 숫자 로그보다 먼저 유지되도록 로그를 재정렬해야 합니다. 그리고 편지 로그는
=3의 크기 A에 −와 같은 인덱스 i가 있습니다. A[0]
I(증가를 나타냄) 또는 D(감소를 나타냄)만 포함하는 문자열 S가 있다고 가정하고 N =S의 크기라고 가정합니다. [0, 1, ...의 순열 A를 반환해야 합니다. , N] 범위 0, ..., N-1 −의 모든 i에 대해 S[i]가 I이면 A[i]
N개의 소문자 문자열 배열이 있고 배열 이름이 A이고 모든 문자열의 길이가 같다고 가정합니다. 이제 삭제 인덱스 세트를 선택할 수 있으며 각 문자열에 대해 해당 인덱스의 모든 문자를 삭제합니다. 예를 들어 [abcdef,uvwxyz]와 같은 배열 A가 있고 삭제 인덱스가 {0, 2, 3}인 경우 삭제 후 최종 배열은 [bef, vyz]가 됩니다. A의 나머지 열은 [b,v], [e,y] 및 [f,z]입니다. 삭제 후 삭제 인덱스 D 집합을 선택했다고 가정하고 A의 나머지 각 열은 내림차순으로 정렬되지 않습니다. D의 길이의 가능
=0에 대해 x^i + y^j와 같으면 정수가 강력하다고 말할 수 있습니다. 모든 목록을 찾아야 합니다. - bound보다 작거나 같은 값을 갖는 강력한 정수. 따라서 입력이 x =2 및 y =3이고 경계가 10이면 출력은 2 =2^0 + 3^과 같이 [2,3,4,5,7,9,10]이 됩니다. 0 3 =2^1 + 3^0 4 =2^0 + 3^1 5 =2^1 + 3^1 7 =2^2 + 3^1 9 =2^3 + 3^0 10 =2^ 0 + 3^2 이 문제를 해결하기 위해 다음 단계를 따릅니다. − a, b를 0으로 초기화 res:=새 목