Selenium webdriver를 사용하여 요소와 해당 텍스트를 찾을 수 있습니다. 우선 id, classname, css 등과 같은 로케이터를 사용하여 요소를 식별해야 합니다. 그런 다음 텍스트를 얻으려면 텍스트의 도움을 받아야 합니다. 방법. 구문 s = driver.find_element_by_css_selector("h4").text 여기 드라이버 웹드라이버 객체입니다. find_element_by_css_selector 메소드 css 로케이터 유형으로 요소를 식별하는 데 사용되며 로케이터 값은 메서드에
Python 라이브러리 API를 사용하여 컨테이너, 이미지, 클러스터, 스웜 등과 같은 도커 객체에 액세스, 관리 및 조작할 수 있습니다. docker 명령이 허용하는 거의 모든 작업을 수행할 수 있습니다. 이것은 django 또는 flask와 같은 Python 앱을 사용하고 애플리케이션에 사용하는 것과 동일한 Python 스크립트를 사용하여 도커 컨테이너를 유지하려는 경우에 매우 편리합니다. docker용 python 라이브러리 API를 사용하려면 docker−py라는 패키지를 설치해야 합니다. 다음 pip 명령을 사용하여 그렇
문제 문자열을 필드로 분할해야 하지만 구분 기호가 문자열 전체에서 일관되지 않습니다. 해결책 파이썬에서 여러 구분 기호의 문자열 또는 문자열을 분할할 수 있는 여러 가지 방법이 있습니다. 가장 쉽고 간편한 방법은 split() 메서드를 사용하는 것이지만 간단한 경우를 처리하기 위한 것입니다. re.split() is more flexible than the normal `split()` method in handling complex string scenarios. re.split()을 사용하면 구분 기호에 대해 여러 패턴을
문제 가장 자주 발생하는 항목을 순서대로 식별해야 합니다. 해결책 카운터를 사용하여 항목을 순서대로 추적할 수 있습니다. 카운터란 무엇입니까? 카운터는 각 키에 대한 정수 개수를 보유하는 매핑입니다. 기존 키를 업데이트하면 키가 추가됩니다. 이 개체는 해시 가능한 개체의 인스턴스를 계산하는 데 사용되거나 다중 집합으로 사용됩니다. 카운터는 데이터 분석을 수행할 때 가장 친한 친구 중 하나입니다. 이 개체는 Python에 꽤 오랫동안 존재해 왔으며 많은 분들이 이 내용을 빠르게 검토하게 될 것입니다. 컬렉션에서 Counter
이 기사는 Python으로 가장 크거나 작은 항목을 찾고자 하는 개발자를 대상으로 합니다. 몇 가지 사용 방법을 보여주고 가장 적합한 방법을 결론지을 것입니다. 방법 – 1:목록에 대한 슬라이스 접근 N =1과 같이 가장 작거나 큰 단일 항목을 단순히 찾으려면 min() 및 max()를 사용하는 것이 더 빠릅니다. 임의의 정수를 생성하는 것으로 시작하겠습니다. import random # Create a random list of integers random_list = random.sample(range(1,10),9) ran
소개 Pandas에는 인덱스 위치를 사용하거나 인덱스 레이블을 사용하여 데이터 하위 집합을 선택하는 이중 선택 기능이 있습니다. 이 게시물에서는 인덱스 레이블을 사용하여 색인 레이블을 사용하여 데이터의 하위 집합 선택하는 방법을 보여 드리겠습니다. 파이썬 사전과 목록은 인덱스 레이블이나 byindex 위치를 사용하여 데이터를 선택하는 내장 데이터 구조라는 것을 기억하십시오. 사전의 키는 문자열, 정수 또는 튜플이어야 하며 목록은 정수(위치) 또는 선택을 위해 슬라이스 객체를 사용해야 합니다. 판다에는 고유한 방식으로 인덱스 작
소개 Pandas에는 인덱스 위치를 사용하거나 인덱스 레이블을 사용하여 데이터 하위 집합을 선택하는 이중 선택 기능이 있습니다. 이 게시물에서는 사전 슬라이싱을 사용하여 데이터 부분 집합 선택 방법을 보여 드리겠습니다. Google은 데이터 세트로 가득 차 있습니다. kaggle.com에서 영화 데이터세트를 검색합니다. 이 게시물은 kaggle의 영화 데이터 세트를 사용합니다. 방법 이 예에 필요한 열만 있는 영화 데이터세트를 가져옵니다. import pandas as pd import numpy as np movi
소개 Pandas에는 인덱스 위치를 사용하거나 인덱스 레이블을 사용하여 데이터 하위 집합을 선택하는 이중 선택 기능이 있습니다. 이 게시물에서는 사전 슬라이싱을 사용하여 데이터 부분 집합 선택 방법을 보여 드리겠습니다. Google은 데이터 세트로 가득 차 있습니다. kaggle.com에서 영화 데이터세트를 검색합니다. 이 게시물은 kaggle의 영화 데이터 세트를 사용합니다. 방법 1. 이 예에 필요한 열만 있는 영화 데이터세트를 가져옵니다. import pandas as pd import numpy as np movies
데이터를 분석하는 동안 데이터를 바로 삭제하는 대신 중복 행을 살펴보고 데이터에 대해 더 많이 이해해야 하는 경우가 있습니다. 운 좋게도 pandas에서는 복제본을 처리할 수 있는 방법이 거의 없습니다. .dupliated() 이 방법을 사용하면 DataFrame에서 중복 행을 추출할 수 있습니다. 중복이 있는 새 데이터 세트를 사용합니다. 링크에서 Hr Dataset을 다운로드했습니다. import pandas as pd import numpy as np # Import HR Dataset with certain column
문제 웹 페이지에서 HTML 테이블을 추출해야 합니다. 소개 인터넷과 월드 와이드 웹(WWW)은 오늘날 가장 눈에 띄는 정보 소스입니다. 너무 많은 정보가 있으므로 많은 옵션 중에서 콘텐츠를 선택하는 것이 매우 어렵습니다. 그 정보의 대부분은 HTTP를 통해 검색할 수 있습니다. 그러나 이러한 작업을 프로그래밍 방식으로 수행하여 정보를 자동으로 검색하고 처리할 수도 있습니다. Python을 사용하면 표준 라이브러리 HTTP 클라이언트를 사용하여 이를 수행할 수 있지만 requests 모듈은 웹 페이지 정보를 매우 쉽게 얻는
Python Pandas에서 템플릿을 사용하여 DataFrame에 새 행을 추가하는 방법. 소개 데이터 엔지니어링 전문가이기 때문에 분석을 위해 데이터를 생성하고 나에게 보내는 역할은 다른 데이터베이스 전문가가 처리해야 하기 때문에 종종 행보다 파생된 열을 더 많이 생성하게 됩니다. 그러나 항상 사실은 아닙니다. 데이터 전문가 팀이 데이터를 보낼 때까지 기다리기보다 샘플 행을 만들어야 합니다. 이 주제에서 나는 행을 생성하는 깔끔한 트릭을 보여줄 것입니다. 그것을 하는 방법.. 이 레시피에서는 .loc 속성을 사용하여 작은 데
문제 파이썬에서 압축 파일을 만들고 싶습니다. 소개 ZIP 파일은 다른 많은 파일의 압축된 내용을 담을 수 있습니다. 파일을 압축하면 디스크 크기가 줄어들어 인터넷을 통해 또는 Control-m AFT 또는 Connect direct 또는 scp를 사용하여 시스템 간에 파일을 전송할 때 유용합니다. Python 프로그램은 zipfile 모듈의 함수를 사용하여 ZIP 파일을 생성합니다. 방법... 1. 우리는 zipfile과 io 패키지를 사용할 것입니다. 시스템에 패키지가 누락된 경우 pip를 사용하여 설치합니다. 확실하지
소개 세상은 엑셀이 지배하는 것 같습니다. 데이터 엔지니어링 작업에서 얼마나 많은 동료들이 의사 결정을 위한 중요한 도구로 Excel을 사용하는지 보고 놀랐습니다. 저는 MS Office 및 Excel 스프레드시트의 열렬한 팬은 아니지만 큰 Excel 스프레드시트를 효과적으로 처리하는 깔끔한 트릭을 보여 드리겠습니다. 그것을 하는 방법.. 프로그램을 직접 시작하기 전에 Pandas로 Excel 스프레드시트를 처리하는 몇 가지 기본 사항을 이해하겠습니다. 1. 설치. 계속해서 openpyxl 및 xlwt를 설치하십시오. pyth
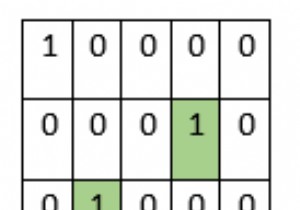
이제 주어진 행렬의 각 0에 대해 숫자의 2D 행렬이 있다고 가정하고 행과 열의 모든 값을 0으로 바꾸고 최종 행렬을 반환합니다. 따라서 입력이 행렬과 같으면 0번째, 2번째 및 3번째 행에 0이 포함되고 최종 행렬에 해당 행에 0이 포함되므로 출력은 행렬이 됩니다. 마찬가지로 0번째, 1번째 및 2번째 열에는 0이 포함되고 최종 행렬에는 해당 열에 0이 포함됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. n := row count, m := column count res := make a matrix of size n
소개 Python에는 스레드, 하위 프로세스, 생성기 및 동시 프로그래밍을 위한 기타 트릭을 사용하는 것과 같은 다양한 접근 방식이 있습니다. 계속해서 스레드를 구현하기 전에 동시성이 정확히 무엇인지 이해하겠습니다. 동시성은 별도의 I/O 스트림, 실행 중인 SQL 쿼리 등을 포함하여 실행이 서로 동시적이고 독립적인 것처럼 보이는 방식으로 여러 고유한 실행 경로를 열 수 있는 단일 프로그램 내에서 논리의 한 부분입니다. . 그것을 하는 방법.. 먼저 사이트 URL을 통과하는 단일 스레드를 만들고 나중에 스레딩 개념을 사용하여
소개 목록 이해를 사용하면 소스 목록을 쉽게 가져오고 표현식을 적용하여 파생 목록을 얻을 수 있습니다. 예를 들어 목록의 각 요소에 5를 곱하고 싶다고 가정해 보겠습니다. 여기서는 간단한 for 루프를 사용하여 이 작업을 수행합니다. a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] multiply_by_5 = [] for x in a: multiply_by_5.append(x*5) print(f"Output \n *** {multiply_by_5}") 출력 *** [5, 10, 15, 20, 25
과정 이해 - Windows, MAC 또는 Linux에서 프로그램을 코딩하고 실행할 때 운영 체제는 프로세스(단일)를 생성합니다. 운영 체제는 CPU, RAM, 디스크 공간 및 운영 체제 커널의 데이터 구조와 같은 시스템 리소스를 사용합니다. 프로세스는 다른 프로세스와 격리되어 다른 프로세스가 수행하는 작업을 확인하거나 방해할 수 없습니다. 참고: 이 코드는 시스템과 같은 Linux에서 실행되어야 합니다. Windows에서 실행하면 예외가 발생할 수 있습니다. 운영 체제의 목표 - OS의 주요 두 가지 목표는 프로세스 작업을
초기 보드를 나타내는 2048 게임 보드와 스와이프 방향을 나타내는 문자열 방향이 있다고 가정하면 다음 보드 상태를 찾아야 합니다. 2048 게임에서 알 수 있듯이 우리는 4개의 방향(U, D, L 또는 R). 스와이프하면 모든 숫자가 가능한 한 그 방향으로 이동하고 동일한 인접 숫자가 정확히 한 번 더됩니다. 따라서 입력이 다음과 같으면 방향 =L, 출력은 이 문제를 해결하기 위해 다음 단계를 따릅니다. 방향이 R과 같으면 보드 :=보드를 시계 반대 방향으로 두 번 회전 그렇지 않으면 방향이 U와
문제 원하는 수의 입력 인수를 허용하는 함수를 작성하려고 합니다. 해결책 python의 * 인수는 여러 인수를 허용할 수 있습니다. 주어진 두 개 이상의 숫자의 평균을 찾는 예를 통해 이것을 이해할 것입니다. 아래 예에서 rest_arg는 전달된 모든 추가 인수(이 경우 숫자)의 튜플입니다. 함수는 평균 계산을 수행할 때 인수를 시퀀스로 처리합니다. # Sample function to find the average of the given numbers def define_average(first_arg, *rest_arg):
소개 Pandas는 NumPy NaN(np.nan) 객체를 사용하여 누락된 값을 나타냅니다. 이 Numpy NaN 값에는 몇 가지 흥미로운 수학적 속성이 있습니다. 예를 들어, 자신과 같지 않습니다. 그러나 Python None 객체는 자신과 비교할 때 True로 평가됩니다. 그것을 하는 방법.. np.nan이 어떻게 작동하는지 이해하기 위해 몇 가지 예를 살펴보겠습니다. pdimport numpy as np# Python None으로 판다 가져오기 self.print(fOutput \n *** {None ==None} ) 출력