
파이썬에서 일부 데이터를 처리한 결과를 인쇄할 때 특정 매력적인 형식이나 수학적 정밀도로 출력해야 할 수도 있습니다. 이 기사에서는 결과를 출력할 수 있는 다양한 옵션이 무엇인지 알아볼 것입니다. 형식 사용 이 접근 방식에서는 format이라는 내장 함수를 사용합니다. 형식으로 제공될 값의 자리 표시자로 {}를 사용합니다. 기본적으로 위치는 형식 함수에서 오는 동일한 값 시퀀스로 채워집니다. 그러나 인덱스로 0부터 시작하는 위치에 대한 값을 강제할 수도 있습니다. 예시 weather = ['sunny','ra
Python에서 Selenium webdriver로 프록시를 실행할 수 있습니다. 프록시는 현지화 테스트를 수행하는 데 필수적인 구성 요소입니다. 전자 상거래 응용 프로그램을 사용하여 표시되는 언어와 통화가 사용자 위치에 맞는지 확인할 수 있습니다. 테스트 내 프록시의 도움으로 웹 사이트 사용자 인터페이스가 위치와 일치하는지 확인할 수 있습니다. 아래 단계에 따라 프록시를 설정해야 합니다. - Selenium 패키지에서 웹 드라이버를 가져옵니다. 프록시 서버 주소를 정의합니다. ChromeOptions 클래스의 개
파이썬에서 우리는 변수, 함수, 라이브러리 및 모듈 등을 다룹니다. 사용하려는 변수의 이름이 이미 다른 변수의 이름으로 또는 다른 함수 또는 다른 메서드의 이름으로 존재할 가능성이 있습니다. 이러한 시나리오에서 우리는 이 모든 이름이 파이썬 프로그램에 의해 관리되는 방법에 대해 배워야 합니다. 이것이 네임스페이스의 개념입니다. 다음은 네임스페이스의 세 가지 범주입니다. 로컬 네임스페이스:프로그램에 의해 선언된 함수 및 변수의 모든 이름은 이 네임스페이스에 보관됩니다. 이 네임스페이스는 프로그램이 실행되는 동안 존재합니다.
python의 netrc 클래스는 사용자의 홈 firectory에 있는 유닉스 시스템의 .netrc 파일에서 데이터를 읽는 데 사용됩니다. 사용자의 로그인 자격 증명 세부 정보가 포함된 숨김 파일입니다. 이것은 ftp, curl 등과 같은 도구가 ,netrc 파일을 성공적으로 읽고 작업에 사용하는 데 유용합니다. 아래 프로그램은 파이썬의 netrc 모듈을 사용하여 .netrc 파일을 읽는 방법을 보여줍니다. 예시 import netrc netrc = netrc.netrc() remoteHostName = "hostname
Python은 cx_Oracle이라는 python 패키지를 사용하여 oracle에 연결할 수 있습니다. Oracle은 유명하고 널리 사용되는 데이터베이스 중 하나이며 Python의 데이터 처리 기능은 이 연결을 사용하여 잘 활용됩니다. 이 기사에서는 Oracle 데이터베이스에 연결하고 DB를 쿼리하는 방법을 살펴봅니다. cx_Oracle 설치 아래 명령을 사용하여 연결을 설정하는 데 사용할 수 있는 python 패키지를 설치할 수 있습니다. 예시 pip install cx_Oracle 오라클에 연결 이제 이 모듈을 사용하여 Or
os.path 모듈은 시스템의 다른 위치에서 파일을 처리할 때 편리한 매우 광범위하게 사용되는 모듈입니다. python에서 경로 이름을 병합, 정규화 및 검색하는 것과 같은 다양한 목적으로 사용됩니다. 이러한 모든 함수는 바이트 또는 문자열 개체만 매개변수로 허용합니다. 결과는 실행 중인 OS에 따라 다릅니다. os.path.basename 이 기능은 폴더 또는 파일 이름이 될 수 있는 경로의 마지막 부분을 제공합니다. 백슬래시와 슬래시 측면에서 Windows와 Linux에서 경로가 언급되는 방식의 차이를 알려주세요. 예시 imp
다형성은 여러 형태를 의미합니다. 파이썬에서 우리는 여러 형태를 취하는 동일한 연산자나 함수를 찾을 수 있습니다. 동일한 이름의 클래스 메소드를 갖는 다른 클래스를 생성할 때도 유용합니다. 이는 많은 코드를 다시 사용하고 코드 복잡성을 줄이는 데 도움이 됩니다. 다형성은 아래의 몇 가지 예에서 볼 수 있듯이 상속과도 연결됩니다. 연산자의 다형성 + 연산자는 두 개의 입력을 받아 입력이 무엇인지에 따라 결과를 제공할 수 있습니다. 아래 예에서 우리는 정수 입력이 정수를 산출하는 방법과 입력 중 하나가 float이면 결과가 float
Pygorithm 모듈은 다양한 알고리즘의 구현을 포함하는 교육용 모듈입니다. 이 모듈의 가장 좋은 용도는 파이썬을 사용하여 구현된 알고리즘의 코드를 얻는 것입니다. 그러나 주어진 데이터 세트에 다양한 알고리즘을 적용할 수 있는 실제 프로그래밍에도 사용할 수 있습니다. 데이터 구조 찾기 Python 환경에 모듈을 설치한 후 패키지에 있는 다양한 데이터 구조를 찾을 수 있습니다. 예시 from pygorithm import data_structures help(data_structures 위의 코드를 실행하면 다음과 같은 결과가
목록을 사용하여 데이터를 분석하는 동안 주어진 요소가 주어진 목록에서 N번 이상 존재하는지 알아내야 하는 상황을 여러 번 접하게 됩니다. 예를 들어 5가 목록에 세 번 이상 있는지 여부를 나타냅니다. 이 기사에서는 이를 달성하는 방법에 대한 2가지 접근 방식을 볼 것입니다. 발생 횟수 계산 아래 접근 방식에서는 숫자와 발생 횟수를 입력으로 사용합니다. 그런 다음 우리는 발생 횟수를 유지하기 위해 디자이너를 따릅니다. 카운트 값이 필요한 값보다 크거나 같으면 결과를 true로 출력하고 그렇지 않으면 false로 출력합니다. 예시 =
파이썬으로 데이터를 분석할 때 키 값이 동일한 요소의 값을 추가하는 방식으로 두 개의 사전을 병합해야 하는 상황에 직면합니다. 이 기사에서 우리는 그러한 두 개의 사전이 추가되는 것을 보게 될 것입니다. For 루프와 | 연산자 이 접근 방식에서 우리는 두 사전에 있는 키 값의 존재를 확인하고 추가하는 for 루프를 설계합니다. 마지막으로 |를 사용하여 두 사전을 병합합니다. 사전에 사용할 수 있는 연산자입니다. 예시 dictA = {'Mon': 23, 'Tue': 11, 'Sun': 6
Python 사전에는 키와 값이 있습니다. 중첩된 사전을 병합할 두 개 이상의 사전이 있는 경우 아래 접근 방식을 사용할 수 있습니다. 올해는 중첩된 사전의 키가 될 새 키와 함께 사전이 제공됩니다. 키 할당 이 접근 방식에서 우리는 새로운 빈 사전을 만들 것입니다. 그런 다음 각 새 키에 지정된 사전을 할당했습니다. 결과 사전은 키가 할당된 중첩 사전이 됩니다. 예시 dictA ={Sun:1, Mon:2}dictB ={Tue:3, Sun:5}# 주어진 Dictionariesprint(DictA :,dictA)print(DictB
중첩 목록이 주어지면 요소가 트리 데이터 구조의 일부로 간주될 수 있는 사전으로 변환하려고 합니다. 이 기사에서는 데이터 구조와 같은 트리를 나타내는 요소를 갖는 사전을 추가하기 위해 중첩 목록을 변환하는 두 가지 접근 방식을 볼 것입니다. 슬라이싱 사용 목록의 항목을 슬라이싱하여 뒤집은 다음 항목이 목록에 있는지 확인합니다. 존재하지 않으면 무시하고 트리에 추가합니다. 예시 def CreateTree(lst): new_tree = {} for list_item in lst: &nbs
파이썬의 목록은 일반적으로 요소가 차례로 나열되는 1D 목록입니다. 그러나 2D 목록에서는 외부 목록 내부에 중첩된 목록이 있습니다. 이 기사에서는 주어진 1D 목록에서 2D 목록을 만드는 방법을 볼 것입니다. 또한 2D 목록 내의 요소 수에 대한 값을 프로그램에 제공합니다. 추가 및 색인 사용 이 접근 방식에서 우리는 2D 목록의 각 요소를 반복하는 for 루프를 만들고 생성할 새 목록의 인덱스로 사용합니다. 인덱스 값은 0에서 시작하여 2D 목록에서 받은 요소에 추가하여 계속 증가시킵니다. 예시 # Given list list
파이썬을 사용한 데이터 분석에서 두 개의 목록을 병합해야 하는 상황을 만날 수 있습니다. 그러나 해당 목록에 있는 중복 요소를 처리하는 것이 어려울 수 있습니다. 이 기사에서는 첫 번째 목록의 모든 요소를 유지하고 두 번째 목록의 고유한 요소만 유지하여 두 목록을 결합하는 방법을 볼 것입니다. 확장 사용 이 접근 방식에서는 첫 번째 목록을 가져와 결과 목록을 만듭니다. 그런 다음 두 번째 목록에서 첫 번째 목록의 요소가 있는지 확인하는 for 루프를 설계하고 두 번째 목록에서 요소를 찾을 수 없으면 확장 기능을 사용하여 결과
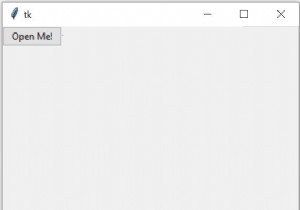
Kivy는 멀티 터치 앱과 같은 혁신적인 사용자 인터페이스를 사용하는 애플리케이션의 신속한 개발을 위한 펜 소스 Python 라이브러리입니다. Android 애플리케이션 및 데스크탑 애플리케이션을 개발하는 데 사용됩니다. 이 기사에서는 Kivy를 통해 생성된 창에 레이블을 추가하는 방법을 살펴보겠습니다. 라벨 생성 아래 예제에서는 uix.lable 모듈에서 사용할 수 있는 Label 기능을 사용하여 창을 만들고 사용자 지정 레이블을 지정합니다. 이 코드로 앱을 실행하면 사용자 정의 레이블을 표시하는 새 창이 나타납니다. 예 fro
왼쪽 아래 모서리 점과 오른쪽 위 모서리 점 2개로 표시되는 직사각형이 있다고 가정합니다. 주어진 점(x, y)이 이 사각형 안에 존재하는지 여부를 확인해야 합니다. 따라서 입력이 bottom_left =(1, 1), top_right =(8, 5), point =(5, 4)와 같으면 출력은 True 이 문제를 해결하기 위해 다음 단계를 따릅니다. − solve() 함수를 정의합니다. bl, tr, p가 필요합니다. bl의 x 및 p의 x bl의 y 및 p의 y
소수 n이 있다고 가정합니다. n을 x + y로 표현할 수 있는지 확인해야 합니다. 여기서 x와 y는 두 개의 소수이기도 합니다. 따라서 입력이 n =19와 같으면 19 =17 + 2와 같이 표현할 수 있으므로 출력은 True가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − isPrime() 함수를 정의합니다. 시간이 걸립니다 숫자가 <=1이면 거짓을 반환 숫자가 2와 같으면 참 반환 숫자가 짝수이면 거짓을 반환 범위 3에서 ((숫자의 제곱근) + 1)의 정수 부분까지 i에 대해 2만큼 증가, do 숫
체스판에 여왕과 상대에 대한 두 개의 좌표가 있다고 가정합니다. 이 점은 각각 Q와 O입니다. 퀸이 상대를 공격할 수 있는지 여부를 확인해야 한다. 퀸은 같은 행, 같은 열, 대각선으로 공격할 수 있다는 것을 알고 있습니다. 따라서 입력이 Q =(1, 1) O =(4, 4)와 같으면 Q가 대각선으로 (4, 4) 갈 수 있으므로 출력은 True가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − Q의 x가 O의 x와 같으면 참 반환 Q의 y가 O의 y와 같으면 참 반환 Q의 |x - O의 x| Q의 y -
처음 n개의 자연수(정렬되지 않음)가 있는 대기열이 있다고 가정합니다. 주어진 Queue 요소가 스택을 사용하여 다른 Queue에서 감소하지 않는 순서로 정렬될 수 있는지 확인해야 합니다. 이 문제를 해결하기 위해 다음 작업을 사용할 수 있습니다. - 스택에서 요소 푸시 또는 팝 주어진 대기열에서 요소를 삭제합니다. 다른 대기열에 요소를 삽입합니다. 따라서 입력이 Que =[6, 1, 2, 3, 4, 5]와 같으면 Que에서 6을 꺼낸 다음 스택에 푸시할 수 있으므로 출력은 True가 됩니다. 이제 나머지 모든 요소를 Qu
숫자 배열이 있고 또 다른 숫자 k가 있다고 가정하면 주어진 배열이 모든 쌍의 합이 k가 되도록 쌍으로 나눌 수 있는지 확인해야 합니다. 따라서 입력이 arr =[1, 2, 3, 4, 5, 6], k =7과 같으면 출력은 (2, 5), (1, 6)과 같은 쌍을 취할 수 있으므로 True가 됩니다. 및 (3, 4). 이 문제를 해결하기 위해 다음 단계를 따릅니다. − n :=arr의 크기 n이 홀수이면 거짓을 반환 낮음 :=0, 높음 :=n - 1 낮은 동안 <높은, do arr[low] + arr[high]가 k와 같지