

문자열 s와 dict라는 문자열 목록이 있다고 가정하고 해당 dict에 있는 s의 하위 문자열을 래핑하기 위해 굵은 굵은 태그 및 의 닫힌 쌍을 추가해야 합니다. 두 개의 하위 문자열이 겹칠 때 닫힌 볼드 태그 한 쌍으로만 함께 포장해야 합니다. 또한 굵은 태그로 묶인 두 개의 하위 문자열이 연속적이면 결합해야 합니다. 따라서 입력이 s =abcxyz123 dict is [abc,123]인 경우 출력은 abcxyz123 이 문제를 해결하기 위해 다음 단계를 따릅니다. − n :=s의 크기 n 크기의 굵게 배열 정의
양의 정수 x가 있다고 가정하고 각 숫자의 곱이 x와 같은 가장 작은 양의 정수 b를 찾아야 합니다. 그러한 응답이 없으면 0을 반환합니다. 따라서 입력이 48과 같으면 출력은 68이 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − ret :=0, mul :=1 <2인 경우: 반환 =2일 때 업데이트(i를 1만큼 감소), − mod i가 0과 같을 때 − ret :=i * mul + ret mul :=mul * 10 a :=a / i 반환(a <2이고 ret
1에서 n까지의 n개의 숫자로 구성된 배열이 오름차순으로 있다고 가정하면 생성할 수 있는 혼란의 수를 찾아야 합니다. 조합 수학에서 교란은 집합의 요소가 원래 위치에 나타나지 않도록 하는 순열이라는 것을 알고 있습니다. 답은 매우 클 수 있으므로 출력 모드 10^9 + 7을 반환합니다. 따라서 입력이 3과 같으면 원래 배열이 [1,2,3]이므로 출력은 2가 됩니다. 두 가지 교란은 [2,3,1] 및 [3,1,2]입니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − m :=10^9 + 7 add() 함수를 정의
키보드를 사용하여 문자 A를 쓰려고 한다고 가정해 보겠습니다. 우리의 목표는 4개의 키만 사용하고 텍스트 필드에 최대 A를 쓰는 것입니다. 키는 A, C, V, Ctrl입니다. 최대 개수의 A를 작성하려면 Ctrl + A를 사용하여 모두를 선택하고 Ctrl + C를 사용하여 복사하고 Ctrl + V를 사용하여 붙여넣습니다. 따라서 입력이 키 입력 횟수가 7과 같으면 A를 세 번 누를 때 출력이 9가 됩니다. 그런 다음 Ctrl+A, Ctrl+C, Ctrl+V, Ctrl+V 이 문제를 해결하기 위해 다음 단계를 따릅니다. −
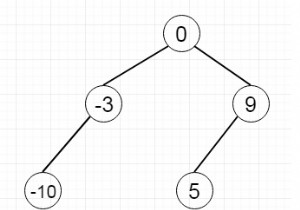
n개의 노드가 있는 이진 트리가 있다고 가정하고 원래 트리에서 정확히 한 모서리를 삭제한 후 값의 합이 동일한 두 개의 트리로 트리를 분할하는 것이 가능한지 확인하는 것입니다. 따라서 입력이 다음과 같으면 그러면 출력이 true가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − 하나의 스택 정의 solve() 함수를 정의하면 노드가 필요합니다. 노드가 null이면 - 0 반환 leftSum :=해결(노드 왼쪽) rightSum :=해결(노드 오른쪽) curr :=va
깊이가 5보다 작은 이진 트리를 나타내는 정수 목록이 있다고 가정합니다. 트리의 깊이가 5보다 작으면 이 트리는 세 자리 정수 목록으로 나타낼 수 있습니다. 이 목록의 각 정수에 대해 - 100자리는 이 노드의 깊이 D, 1 <=D <=4를 나타냅니다. 10자리는 1에서 8까지의 범위에 속하는 레벨에서 이 노드의 위치 P를 나타냅니다. 위치는 전체 이진 트리의 위치와 동일합니다. 단위 자릿수는 이 노드의 값 V를 나타내는 데 사용됩니다. 0 <=V <=9. 루트에서 잎으로 가는 모든 경로의 합을 찾아야 합니다.
HH:MM 형식으로 표시되는 시간이 있다고 가정하고 현재 숫자를 재사용하여 다음으로 가장 가까운 시간을 생성해야 합니다. 숫자를 무제한으로 사용할 수 있습니다. 따라서 입력이 19:34와 같으면 숫자 1, 9, 3, 4에서 선택하는 다음으로 가장 가까운 시간이 19:39이므로 출력은 19:39가 됩니다. 이것은 23시간 59분 후에 발생하기 때문에 19:33이 아닙니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − eval() 함수를 정의하면 x가 필요합니다. a :=x[0]을 문자열로 변환 a :=a +
이진 2D 어레이 그리드가 있다고 가정합니다. 여기에서 섬은 4방향(수평 또는 수직)으로 연결된 1(랜드) 그룹입니다. 그리드의 네 모서리가 모두 물로 둘러싸여 있다고 가정할 수 있습니다. 우리는 별개의 섬의 수를 세어야 합니다. 한 섬이 다른 섬과 동일하게 변환될 수 있고(회전하거나 반사되지 않음) 섬은 다른 섬과 동일한 것으로 간주됩니다. 따라서 입력이 다음과 같으면 1 1 0 1 1 1 0 0 0 0 0 0 0 0 1 1 1 0 1 1 그러면 출력은 3이 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다
배열이 있고 오름차순으로 정렬되어 있다고 가정하면 대상을 숫자로 검색하는 함수를 정의해야 합니다. 대상이 있으면 해당 인덱스를 반환하고, 그렇지 않으면 -1을 반환합니다. 배열 크기를 알 수 없습니다. ArrayReader 인터페이스를 사용해서만 배열에 액세스할 수 있습니다. ArrayReader.get(k)와 같은 get 함수가 있습니다. 이것은 인덱스 k에 있는 배열의 요소를 반환합니다. 따라서 입력이 array =[-1,0,3,5,9,12], target =9와 같으면 9가 숫자로 존재하고 인덱스가 4이므로 출력은 4가 됩
오름차순으로 정렬된 순환 연결 목록의 노드가 있다고 가정하고 정렬된 순환 목록을 유지하도록 insertVal 값을 목록에 삽입하는 함수를 정의해야 합니다. 노드는 목록의 단일 노드에 대한 참조일 수 있으며 순환 목록의 첫 번째 값일 필요는 없습니다. 삽입하기에 적합한 위치가 여러 개인 경우 새 값을 삽입할 위치를 선택할 수 있습니다. 목록이 비어 있으면 새로운 단일 순환 목록을 만들고 해당 단일 노드에 대한 참조를 반환해야 합니다. 그렇지 않으면 원래 주어진 노드를 반환해야 합니다. 따라서 입력이 head =[3,4,1], in
두 개의 배열 words1, words2가 주어졌다고 가정하고 이들은 문장으로 간주되며 유사한 단어 쌍의 목록은 두 문장이 유사한지 여부를 확인해야 합니다. 따라서 입력이 words1 =[great, acting, skills] 및 words2 =[fine, drama, talent]인 경우 유사한 단어 쌍이 =[[훌륭하다, 좋다], [좋다, 좋다], [연기,드라마], [실력,재능]]. 유사성 관계는 전이적입니다. 예를 들어 훌륭하다와 좋다가 비슷하고 좋다와 좋다가 비슷하면 훌륭하다와 좋다도 비슷합니다. 그리고 유사도도 대칭입니다
정수 대기열이 있다고 가정하고 해당 대기열에서 첫 번째 고유 정수를 검색해야 합니다. FirstUnique라는 클래스를 구현해야 합니다. 이 클래스는 대기열의 숫자로 초기화됩니다. 하나의 함수 showFirstUnique()를 정의하면 대기열의 첫 번째 고유 정수 값을 반환하고 해당 정수가 없으면 -1을 반환합니다. 또 다른 방법은 add(value)입니다. 이것은 큐에 값을 삽입합니다. 따라서 입력이 다음과 같으면 [2,3,4]로 초기화한 다음 다음과 같이 함수를 호출합니다. - showFirstUnique()
루트에서 잎으로 가는 각 경로가 유효한 시퀀스를 형성하는 이진 트리가 있다고 가정하면 주어진 문자열이 이러한 이진 트리에서 유효한 시퀀스인지 확인해야 합니다. 정수 배열 arr의 연결에서 주어진 문자열을 얻고 경로를 따라 노드의 모든 값을 연결하면 시퀀스가 생성됩니다. 다음과 같은 이진 트리가 있다고 가정합니다. 0 이 문제를 해결하기 위해 다음 단계를 따릅니다. − solve() 함수를 정의하면 노드, 배열 v, idx가 0으로 초기화됩니다. 노드가 null이면 - 거짓을 반환 =v의 크기인
숫자만 포함하는 문자열이 있다고 가정하고 가능한 모든 유효한 IP 주소 조합을 반환하여 문자열을 복원해야 합니다. 유효한 IP 주소는 단일 포인트로 구분된 정확히 4개의 정수(각 정수의 범위는 0~255)로 구성됩니다. 따라서 입력이 25525511135와 같으면 출력은 [255.255.11.135, 255.255.111.35]가 됩니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − convertToNum() 함수를 정의하면 s, start, end,가 필요합니다. 숫자 :=0 initialize i :=
이진 트리가 있고 값 v와 깊이 d가 있다고 가정하면 주어진 깊이 d에서 값 v를 갖는 노드 행을 추가해야 합니다. 루트 노드는 깊이 1에 있습니다. 이 작업을 수행하려면 이 규칙을 따라야 합니다 - 깊이 d를 알고 있는 것처럼 깊이 d-1의 각 유효한 트리 노드 N에 대해 값 v를 N의 왼쪽 하위 트리 루트와 오른쪽 하위 트리 루트로 사용하여 두 개의 트리 노드를 만들어야 합니다. 그리고 N의 원래 왼쪽 하위 트리는 새 왼쪽 하위 트리 루트의 왼쪽 하위 트리가 되고 원래 오른쪽 하위 트리는 새 오른쪽 하위 트리 루트의 오른쪽 하
뿌리가 없는 나무가 하나 있다고 가정합니다. 이것은 주기가 없는 하나의 무방향 그래프입니다. 주어진 입력은 하나의 추가 에지가 추가된 N개의 노드(노드의 값은 1에서 N까지의 고유한 값임)가 있는 트리로 시작된 그래프입니다. 추가된 가장자리는 1에서 N까지 선택된 두 개의 다른 정점을 가지며 이미 존재하는 가장자리가 아닙니다. 최종 그래프는 에지의 2D 배열로 제공됩니다. 모서리의 각 요소는 쌍 [u, v]입니다. 여기서 u
m개의 항공편으로 연결된 n개의 도시가 있다고 가정합니다. 각 항공편은 u에서 시작하여 가격이 w인 v에 도착합니다. 시작 도시 src 및 목적지 dst와 함께 모든 도시와 항공편이 있는 경우 여기에서 우리의 임무는 최대 k 정거장으로 src에서 dst까지 가장 저렴한 가격을 찾는 것입니다. 해당 경로가 없으면 -1을 반환합니다. 따라서 입력이 n =3, edge =[[0,1,100],[1,2,100],[0,2,500]], src =0, dst =2, k =1인 경우 출력은 다음과 같습니다. 200 이 문제를 해결하기 위해
이진 트리, 대상 노드 및 1 값 K가 있다고 가정합니다. 대상 노드에서 거리가 K인 모든 노드의 값 목록을 찾아야 합니다. 따라서 입력이 root =[3,5,1,6,2,0,8,null,null,7,4], target =5, K =2와 같으면 출력은 [7,4 ,1], 대상 노드에서 거리가 2인 노드의 값이 7, 4, 1이기 때문입니다. 이 문제를 해결하기 위해 다음 단계를 따릅니다. − dfs() 함수를 정의합니다. 이것은 노드를 가져오고, pa는 NULL로 초기화합니다. 노드가 null이면 - 반환
음이 아닌 정수인 점수 배열이 있다고 가정합니다. 첫 번째 플레이어는 배열의 양쪽 끝에서 숫자 중 하나를 선택한 다음 두 번째 플레이어, 첫 번째 플레이어 등의 순서로 숫자 중 하나를 선택합니다. 플레이어가 번호를 선택할 때마다 다른 플레이어는 해당 번호를 사용할 수 없습니다. 이것은 모든 점수가 선택될 때까지 계속됩니다. 최대 점수를 얻은 플레이어가 승리합니다. 따라서 점수 배열이 있는 경우 플레이어 1이 승자인지 예측해야 합니다. 따라서 입력이 [1, 5, 233, 7]과 같으면 첫 번째 플레이어가 1을 선택했으므로 출력은 T
문자열 목록이 있다고 가정합니다. 우리는 그들 중에서 가장 길고 드문 부분 수열을 찾아야 합니다. 가장 길고 흔하지 않은 하위 시퀀스는 실제로 이러한 문자열 중 하나의 가장 긴 하위 시퀀스이며 이 하위 시퀀스는 다른 문자열의 하위 시퀀스가 아니어야 합니다. 하위 시퀀스는 나머지 요소의 순서를 변경하지 않고 일부 문자를 삭제하여 하나의 시퀀스에서 파생될 수 있는 시퀀스라는 것을 알고 있습니다. 여기서 우리는 문자열 목록을 가져오고 출력은 가장 길고 드문 부분 시퀀스의 길이여야 합니다. 가장 긴 uncommon 하위 시퀀스가