

칵테일 정렬은 양방향 버블 정렬, 칵테일 셰이커 정렬, 셰이커 정렬(선택 정렬의 변형이라고도 함), 리플 정렬, 셔플 정렬이라고도 하는 안정적인 정렬 알고리즘이자 비교 정렬인 버블 정렬의 변형입니다. , 또는 셔틀 정렬. 이 알고리즘은 목록을 통과할 때마다 양방향으로 정렬된다는 점에서 버블 정렬과 다릅니다. Input:53421 Output:12345 설명 칵테일에서 정렬 배열은 정렬되지 않은 요소로 구성됩니다. 칵테일 정렬은 목록을 통과할 때마다 양방향으로 작동합니다. 버블 정렬을 사용하여 배열을 앞뒤로 한 번 정렬합니다. 예
두 숫자의 공약수는 두 숫자의 약수입니다. 예를 들어, 12의 제수는 1, 2, 3, 4, 6, 12입니다. 18의 제수는 1, 2, 3, 6, 9, 18입니다. 따라서 12와 18의 공약수는 1, 2, 3, 6입니다. 이들 중 가장 큰 것은 아마도 12와 18의 최대 공약수라고 불리는 것입니다. 두 정수 a와 b의 최대 공약수에 대한 일반적인 수학적 표기법은 (a, b)로 표시됩니다. 따라서 (12, 18) =6. 최대공약수는 여러 가지 이유로 중요합니다. 예를 들어, 두 숫자의 LCM, 즉 이 숫자의 배수인 가장 작은
빗 정렬은 거품 정렬 및 칵테일 정렬과 유사합니다. 콤 정렬은 인접한 요소를 살펴보는 것으로 시작하지 않고 대신 특정 인덱스 수만큼 떨어져 있는 요소를 살펴봅니다. 이를 간격이라고 합니다. 간격은 [n/c]로 정의되며, 여기서 n은 요소 수이고 c는 축소 계수입니다. 각 반복 후에 이 숫자는 c로 나누어지고 결국 알고리즘이 인접한 요소를 볼 때까지 내림됩니다. Input:53421 Output:12345 설명 콤 정렬은 [n/c]로 정의되는 간격이 있는 두 요소를 비교합니다. 여기서 n은 요소 수이고 c는 축소 계수(즉, 1.3)
두 숫자의 공약수는 두 숫자의 약수입니다. 예를 들어, 12의 제수는 1, 2, 3, 4, 6, 12입니다. 18의 제수는 1, 2, 3, 6, 9, 18입니다. 따라서 12와 18의 공약수는 1, 2입니다. , 3, 6. 이들 중 가장 큰 것은 아마도 12와 18이라고 불리는 것입니다. 두 정수 a와 b의 최대 공약수에 대한 일반적인 수학적 표기법은 (a, b)로 표시됩니다. 따라서 (12, 18) =6. 최대공약수는 여러 가지 이유로 중요합니다. 예를 들어 두 숫자, 즉 이 숫자의 배수인 가장 작은 양의 정수를 계산하는 데
Gnome 정렬은 요소를 적절한 위치로 이동하는 것이 버블 정렬에서와 같이 일련의 교체에 의해 수행된다는 점을 제외하면 삽입 정렬과 유사한 정렬 알고리즘입니다. Input: 53421 Output: 12345 설명 요소를 적절한 위치로 이동하는 정렬 알고리즘은 버블 정렬에서와 같이 일련의 교환에 의해 수행됩니다. 단순히 루프가 필요합니다. 예시 #include <iostream> using namespace std; int main() { int temp; int arr[]
두 개의 정수 X와 K가 주어집니다. K는 정수의 자릿수입니다. 논리는 X로 나눌 수 있는 가장 큰 K 자리 숫자를 찾는 것입니다. Input: X = 30, K = 3 Output: 980 설명 980은 30으로 나눌 수 있는 가장 큰 세 자리 숫자입니다. K를 10의 거듭제곱으로 취하여 1로 빼면 가장 큰 K 자리 숫자가 나온 다음 가장 큰 숫자를 구하려고 합니다. X로 나눈 값입니다. 예시 #include <iostream> #include <math.h> using namespace std; int m
인덱스 i에서 인덱스 j까지 요소의 합을 계산해야 합니다. i 및 j 인덱스 값으로 구성된 쿼리는 여러 번 실행됩니다. 입력:arr[] ={5, 6, 3, 4, 1 } i =1, j =3출력:13 설명 6 + 3 + 4 =13합[] ={5, 6+5, 3+6+5, 4+3+6+5, 1+4+3+6+5 }합[]={5 ,11,14,18,19}합[j]-합[i-1]=합[3]-합[1-1]=합[3]-합[0]=18-5=13 논리는 j 인덱스까지 루프 형태 i 인덱스를 시작하고 해당 인덱스 사이의 요소를 합산하는 매우 기본적입니다. 그러나 우리
버블 정렬에서는 인접한 쌍을 비교하고 순서가 잘못된 경우 교체합니다. 이러한 유형의 버블 정렬에서는 자신을 호출하는 재귀 함수를 사용합니다. Input:53421 Output:12345 설명 재귀(자체 호출) 기능을 사용하면 인접한 쌍을 비교하고 배열이 순서가 될 때까지 순서가 잘못된 경우 교체합니다. 예시 #include <iostream> using namespace std; void bubbleSort(int arr[], int n) { for (int i = 0; i < n - 1;
이 섹션에서는 경쟁 프로그래밍을 위한 코드 단축 전략의 몇 가지 예를 볼 것입니다. 많은 양의 코드를 작성해야 한다고 가정합니다. 그 코드에서 우리는 그것들을 더 짧게 만드는 몇 가지 전략을 따를 수 있습니다. 유형 이름을 변경하여 짧게 만들 수 있습니다. 아이디어를 얻으려면 코드를 확인하세요. 예시 코드 #include <iostream> using namespace std; int main() { long long x = 10; long long y = 50;
여기서 우리는 STL과 관련된 C++의 숨겨진 트릭을 볼 것입니다. 중괄호 {}를 사용하여 쌍의 값을 할당합니다. 튜플에 할당하는 데 사용할 수도 있습니다. pair<int, int> my_pair = make_pair(10, 20); pair<int, int> my_pair2 = { 10, 20 }; //using braces pair<int, <char, int> > my_pair3 = { 10, { 'A', 20 } }; //complex pair 때때로 우리는 많은
여기에서 우리는 C++에서 배열보다 벡터의 장점과 단점을 볼 것입니다. 벡터는 템플릿 클래스입니다. 이것은 C++ 전용 구문입니다. 배열은 기본 제공 언어 구조입니다. 배열은 다른 언어로 제공됩니다. 벡터는 목록 인터페이스를 사용하여 동적 배열로 구현되며 배열은 기본 데이터 유형을 사용하여 정적 또는 동적 방식을 사용하여 구현할 수 있습니다. 예시 #include<iostream> #include<vector> using namespace std; int main() { i
여기서 우리는 한 가지 흥미로운 문제를 보게 될 것입니다. 몇 가지 요소가 있는 배열이 있습니다. 하나의 합계 값이 제공됩니다. 우리의 임무는 배열에서 합이 주어진 합과 같은 삼중항을 찾는 것입니다. 배열이 {4, 8, 63, 21, 24, 3, 6, 1, 0}이고 합계 값이 S =18이라고 가정합니다. 따라서 삼중항은 {4, 6, 8}이 됩니다. 삼중항이 두 개 이상 있으면 모두 표시됩니다. 알고리즘 getTriplets(arr, n, 합계) - Begin define one array to store t
여기서 우리는 변이 주어진 삼각형의 외접원의 면적을 구하는 방법을 볼 것입니다. 여기서 변 AB는 a, BC는 b, CA는 c, 반지름은 r입니다. 반경 r은 −와 같습니다. 예시 #include <iostream> #include <cmath> using namespace std; float area(float a, float b, float c) { if (a < 0 || b < 0 || c < 0) //if values are is negative it is
여기서 우리는 타원에 내접할 수 있는 가장 큰 정사각형의 면적을 볼 것입니다. 타원의 사각형은 아래와 같습니다 - 타원의 면적은 - 이제 x와 y가 같으면 따라서 면적은 - 예시 #include <iostream> #include <cmath> using namespace std; float area(float a, float b) { if (a < 0 || b < 0 ) //if values are is negative it is invalid
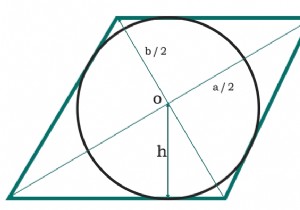
여기서 우리는 정육각형으로 내접된 가장 큰 삼각형의 면적을 볼 것입니다. 육각형의 각 변은 a이고 삼각형의 각 변은 b입니다. 이 다이어그램에서 육각형의 한 변을 사용하여 하나의 삼각형을 만들면 이 두 삼각형이 각 변을 두 부분으로 만들고 있음을 알 수 있습니다. 우리는 두 개의 직각 삼각형도 볼 수 있습니다. 피타고루스 공식에서 우리는 다음과 같이 말할 수 있습니다 - 따라서 면적은 - 예시 #include <iostream> #include <cmath> using namespace std;
C++11부터 STL에 다른 기능이 추가되었습니다. 이러한 기능은 알고리즘 헤더 파일에 있습니다. 여기서 우리는 이것의 몇 가지 기능을 볼 것입니다. all_of() 함수는 컨테이너의 모든 요소에 대해 참인 하나의 조건을 확인하는 데 사용됩니다. 아이디어를 얻기 위해 코드를 살펴보겠습니다. 예시 #include <iostream> #include <algorithm> using namespace std; main() { int arr[] = {2, 4, 6, 8, 10}; &nb
여기서 우리는 하나의 배열이 주어진다고 가정할 때 하나의 문제를 보게 될 것입니다. n개의 요소가 있습니다. 왼쪽의 짝수의 빈도와 오른쪽의 짝수의 빈도가 같거나 왼쪽의 홀수의 빈도와 오른쪽의 홀수의 빈도가 같은 하나의 인덱스를 찾아야 합니다. 그러한 결과가 없으면 -1을 반환합니다. 배열이 {4, 3, 2, 1, 2, 4}와 같다고 가정합니다. 출력은 2입니다. 인덱스 2의 요소는 2이고 왼쪽에 홀수가 하나만 있고 오른쪽에도 홀수가 하나만 있습니다. 이 문제를 해결하기 위해 왼쪽 및 오른쪽 정보를 저장할 두 쌍의 벡터를 생성합니
여기에서 우리는 한 가지 문제를 볼 것입니다. 이 문제에서 트리의 한 모서리와 합 S가 주어집니다. 작업은 가중치 측면에서 가장 긴 경로가 최소화되도록 다른 모든 가중치에 가중치를 할당하는 것입니다. 할당된 가중치의 합은 S와 같습니다. 접근 방식은 간단합니다. 경로에 최대 두 개의 리프 노드가 있을 수 있는 트리의 속성입니다. 이는 솔루션을 얻는 데 사용됩니다. 따라서 리프 노드를 연결하는 가장자리에만 가중치를 할당하고 다른 가장자리를 0으로 할당하면 리프 노드에 연결하는 모든 가장자리는 다음과 같이 할당됩니다. 경로는 최
재귀적 방식으로 새 노드를 BST에 삽입할 수 있습니다. 이 경우 각 하위 트리의 루트 주소를 반환합니다. 여기에서 부모 포인터를 유지 관리해야 하는 또 다른 접근 방식을 볼 수 있습니다. 부모 포인터는 노드 등의 조상을 찾는 데 도움이 됩니다. 아이디어는 왼쪽 및 오른쪽 하위 트리의 주소를 저장하는 것입니다. 재귀 호출 후 반환된 포인터의 부모 포인터를 설정합니다. 이것은 삽입하는 동안 모든 상위 포인터가 설정되었음을 확인합니다. 루트의 부모는 null로 설정됩니다. 알고리즘 삽입(노드, 키) - begin &nb
삭제는 변수의 저장 공간을 해제하는 데 사용되는 연산자입니다. 이 포인터는 비정적 멤버 함수 내부에서만 접근할 수 있는 일종의 포인터로, 멤버 함수를 호출한 객체의 주소를 가리킨다. 이 포인터는 현재 개체의 주소를 보유합니다. 간단히 말해서 이 포인터가 클래스의 현재 개체를 가리킨다고 말할 수 있습니다. 객체를 통해 멤버 함수를 호출할 때마다 컴파일러는 해당 객체를 호출한 주소를 멤버 함수의 첫 번째 매개변수로 비밀리에 this 포인터로 전달합니다. 일반적으로 이 포인터에는 삭제 연산자를 사용하면 안 됩니다. 만약 사용한다면