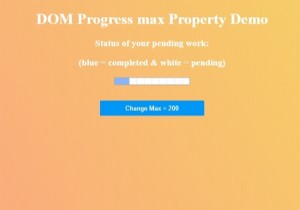

우리는 모든 크기의 배열이 주어지고 인접한 요소 사이의 차이가 0 또는 1인 요소를 사용하여 주어진 배열의 하위 배열을 찾는 작업을 수행합니다. 입력 - 정수 arr[] ={ 2, 1, 5, 6, 3, 4, 7, 6} 출력 − 인접 요소 간의 차이가 0 또는 1인 최대 길이 하위 배열은 − 2 설명 − 차이가 0 또는 1인 배열의 인접 요소는 {2, 1}, {5, 6}, { 3, 4} 및 {7.6}입니다. 따라서 하위 배열의 최대 길이는 2입니다. 입력 - 정수 arr[] ={ 2, 1, 7, 6, 5} 출력 − 인접 요소
우리는 모든 크기의 배열이 주어지며, 주어진 배열에서 인접 요소 간의 차이가 0 또는 1인 요소를 사용하여 하위 시퀀스를 찾는 작업을 수행합니다. 입력 - 정수 arr[] ={ 2, 1, 5, 6, 3, 4, 7, 6} 출력 − 인접 요소 간의 차이가 0 또는 1인 최대 길이 부분 수열은 − 3 설명 − 차이가 0 또는 1인 배열에서 인접한 요소의 부분열은 {2, 1}입니다. 따라서 하위 시퀀스의 최대 길이는 2입니다. 입력 - 정수 arr[] ={ 2, 1, 7, 6, 5} 출력 − 인접 요소 간의 차이가 0 또는 1인
우리는 모든 크기의 배열이 주어지며, 주어진 배열에서 인접 요소 간의 차이가 0 또는 1인 요소를 사용하여 하위 시퀀스를 찾는 작업을 수행합니다. 입력 - 정수 arr[] ={ 2, 1, 5, 6, 3, 4, 7, 6} 출력 − 인접 요소 간의 차이가 0 또는 1인 최대 길이 부분 수열은 다음과 같습니다. 3 설명 − 차이가 0 또는 1인 배열에서 인접한 요소의 부분열은 {2, 1}입니다. 따라서 하위 시퀀스의 최대 길이는 2입니다. 입력 - 정수 arr[] ={ 2, 1, 7, 6, 5} 출력 − 인접 요소 간의 차이가
주어진 작업은 힘으로 죽일 수 있는 최대 사람 수를 찾는 것입니다. P. 무한한 사람이 있는 행을 고려하고 각 사람은 1부터 시작하는 색인 번호를 갖습니다. s번째의 강점 사람은 s2로 표시됩니다. . s의 힘을 가진 사람을 죽이면 당신의 힘도 s만큼 감소합니다. 이제 예제를 사용하여 무엇을 해야 하는지 이해합시다 - 입력 P = 20 출력 3 설명 Strength of 1st person = 1 * 1 = 1 < 20, therefore 1st person can be killed. Remaining strength
주어진 작업은 문자열에서 주어진 하위 시퀀스의 최대 제거 수를 찾는 것입니다. Astring s가 주어지고 문자열에서 제거할 수 있는 하위 시퀀스 abc의 최대 수를 찾아야 합니다. 이제 예제를 사용하여 수행해야 하는 작업을 이해해 보겠습니다. 입력 s = ‘dnabcxy’ 출력 1 설명 − 주어진 문자열(dnabcxy)에서 abc의 하위 시퀀스 하나만 찾을 수 있으므로 출력은 1입니다. 입력 s = ‘zcabcxabc’ 출력 2 (‘zcabcxabc’) 아래 프로
주어진 작업은 주어진 포인트를 포함할 수 있는 최대 세그먼트를 찾는 것입니다. 크기가 n1인 배열 a1[]이 주어지고 두 개의 정수 A와 B가 제공됩니다. 주어진 배열 a1[]에서 n1개의 선분은 시작점과 끝점을 각각 1[i] – A 및 a1[i] + Brespectively로 구성할 수 있습니다. 또 다른 배열 a2[]에는 n2개의 포인트가 있습니다. 이러한 점은 점에 할당된 것보다 선분의 수가 최대가 되도록 선분에 할당되어야 합니다. 단일 점은 주어진 선분에 한 번만 할당될 수 있습니다. 이제 예제를 사용하여 수행해야 하는
주어진 과제는 밑변이 s인 직각 이등변 삼각형 안에 들어갈 수 있는 변 a를 갖는 정사각형의 최대 수를 찾는 것입니다(이등변 삼각형은 최소한 2개의 동일한 변을 가집니다). 이제 예제를 사용하여 수행해야 하는 작업을 이해해 보겠습니다. 입력 s=5, a=1 출력 10 설명 - 밑변의 제곱수는 s를 a로 나누고 1을 빼서 계산할 수 있습니다. 따라서 밑변의 제곱수 =5/1 – 1 =4입니다. 유사하게 하단 4개의 정사각형이 배치되면 밑변이 있는 새로운 이등변 삼각형을 얻은 다음(s-a) 동일한 절차를 반복하고 단일 정사각형이 맨
주어진 작업은 길이가 K인 부분 문자열의 최대 개수를 찾는 것입니다. 동일한 문자로 구성됩니다. 주어진 문자열 s와 다른 정수 K , 우리는 K 크기의 하위 문자열의 발생을 계산해야 합니다. 같은 문자가 있습니다. 발견된 부분 문자열 중에서 가장 많이 발생하는 부분 문자열을 선택해야 합니다. 이제 예제를 사용하여 무엇을 해야 하는지 이해합시다 - 입력 s = ”tuuxyyuuc”, K = 2 출력 2 설명 여기에서 길이가 2이고 동일한 문자를 갖는 하위 문자열은 uu 및 yy이지만 yy는 1번만 발생하고
주어진 작업은 주어진 정사각형 이진 배열의 왼쪽 상단 요소에서 오른쪽 하단 요소까지의 경로, 즉 인덱스 [0][0]에서 시작하여 인덱스까지 이동하는 동안 얻을 수 있는 최대 정수 값을 찾는 것입니다. [n - 1][n - 1]. 경로를 덮는 동안 오른쪽([i][j + 1]) 또는 아래쪽([i + 1][j])으로만 이동할 수 있습니다. 정수 값은 통과한 경로의 비트를 사용하여 계산됩니다. 이제 예제를 사용하여 무엇을 해야 하는지 이해합시다 - 입력 m ={ {1, 1, 1, 1}, {0, 0, 1, 0}, {1, 0, 1, 1}
주어진 작업은 주어진 이진 문자열에서 하위 문자열을 찾은 다음 0과 1의 수 사이의 최대 차이를 찾는 것입니다. 이제 예제를 사용하여 무엇을 해야 하는지 이해합시다 - 입력 str = “10010110” 출력 2 설명 위치 1에서 4(0010)까지의 하위 배열에서 0과 1의 차이 =3 – 1 =2로 찾을 수 있는 최대값입니다. 입력 str = “00000” 출력 5 아래 프로그램에서 사용하는 접근 방식은 다음과 같습니다. main() 함수에서 str 문자열을 만듭니다. 바이너리
주어진 작업은 주어진 이진 문자열에서 하위 문자열을 찾은 다음 0과 1의 수 사이의 최대 차이를 찾는 것입니다. 이제 예제를 사용하여 무엇을 해야 하는지 이해합시다 - 입력 str = “100100110” 출력 2 설명 위치 1에서 5까지의 하위 배열(00100)에서 0과 1의 차이 =4 – 1 =3이며 찾을 수 있는 최대값입니다. 입력 str = “00000” 출력 5 아래 프로그램에서 사용하는 접근 방식은 다음과 같습니다. main() 함수에서 str 문자열을 만듭니다. 바이
주어진 작업은 주어진 문자열에서 두 개의 대문자 사이에 존재하는 고유한 소문자 알파벳의 최대 수를 찾는 것입니다. 이제 예제를 사용하여 무엇을 해야 하는지 이해합시다 - 입력 str = “JKyubDoorG” 출력 3 설명 yub는 두 개의 대문자 K와 D 사이에 있으므로 카운트가 3이 됩니다. oor는 두 개의 대문자 D와 G 사이에도 존재하므로 2를 o가 반복되는 알파벳으로 만들고 우리는 별개의 알파벳을 찾고 있습니다. 따라서 출력은 3입니다. 입력 str = “ABcefsTaRpaep&r
주어진 작업은 최대 k 번 요소를 증가시킨 후 주어진 배열에서 동일하게 만들 수 있는 요소의 최대 수를 찾는 것입니다. 이제 예제를 사용하여 무엇을 해야 하는지 이해합시다 - 입력 a[] = {1, 3, 8}, k = 4 출력 2 설명 여기서 우리는 1을 3번 증가시키고 3을 4번 증가시켜 두 개의 4를 얻을 수 있습니다. 그러면 a[] ={4, 4, 8} 입력 arr = {2, 5, 9}, k = 2 출력 0 아래 프로그램에서 사용하는 접근 방식은 다음과 같습니다. main() 함수에서 int a[], 크기 초기화 및 k
주어진 바이너리 배열 arr[] 및 두 개의 변수 a 및 b 일부 초기 값으로. arr[] 배열의 요소를 교차하려면 두 가지 방법이 있습니다 - arr[i] ==1이면 a에서 1단위를 사용할 수 있습니다. , b 변경 없음 . b에서 1단위를 사용하는 경우 , 다음 1 단위 증가합니다. (참고로 의 값은 원래 값보다 증가할 수 없습니다.) arr[i] ==0이면 a에서 1단위를 사용할 수 있습니다. 또는 b . 이제 예제를 사용하여 무엇을 해야 하는지 이해합시다 - 입력 arr[] = {0, 0, 0, 1, 1},
먼저 비트마스킹과 동적 프로그래밍에 대해 배운 다음 구현과 관련된 질문을 해결할 관련 문제를 해결할 것입니다. 비트마스크 마스크라고도 함 우리 컬렉션의 하위 집합을 인코딩하는 N 비트 시퀀스입니다. 마스크의 요소는 설정되거나 설정되지 않을 수 있습니다(즉, 0 또는 1). 이것은 비트마스크에서 선택된 요소의 가용성을 나타냅니다. 예를 들어, 마스크의 i번째 비트가 설정되면 요소 i를 부분 집합에서 사용할 수 있습니다. N 요소 집합의 경우 2N이 있을 수 있습니다. 하위 집합에 해당하는 각각을 마스크합니다. 따라서 문제를 해결하
바이토닉 정렬은 최상의 구현을 위해 생성된 병렬 정렬 알고리즘이며 하드웨어 및 병렬 프로세서 어레이와 함께 최적으로 사용됩니다. . 병합 정렬과 비교할 때 가장 효과적인 것은 아닙니다. 그러나 병렬 구현에는 좋습니다. 이는 정렬할 데이터와 독립적으로 비교를 수행하는 미리 정의된 비교 순서 때문입니다. 바이토닉 정렬이 효과적으로 작동하려면 요소 수는 특정 유형의 수량(예:2^n 순서)이어야 합니다. . bitonic 정렬의 주요 부분 중 하나는 요소 값이 먼저 증가하는 시퀀스인 bitonic 시퀀스입니다. 그런 다음 감소 .
먼저 about 비트를 기억하고 비트 연산자가 짧습니다. 비트 이진수입니다. 컴퓨터가 이해할 수 있는 가장 작은 데이터 단위입니다. In은 0(OFF를 나타냄) 및 1(ON을 나타냄) 두 값 중 하나만 가질 수 있습니다. . 비트 연산자 프로그램에서 비트 수준으로 작동하는 연산자입니다. 이 연산자는 프로그램의 비트를 조작하는 데 사용됩니다. C에는 6개의 비트 연산자가 있습니다 - 비트 AND(&) 비트 OR(OR) 비트 XOR(XOR) 비트 왼쪽 시프트( ) 비트 단위 아님(~) http
이 문제에서는 두 개의 정수 값과 b가 제공됩니다. 그리고 우리의 임무는 비트 단위 및 (&) 범위에서 b까지를 찾는 것입니다. . 이것은 우리가 &a+1 &a+2 &… b-1 &b의 값을 찾아야 한다는 것을 의미합니다. 문제를 이해하기 위해 예를 들어보겠습니다. 입력 - a =3, b =8 출력 - 0 설명 − 3 &4 &5 &6 &7 &8 =0 이 문제를 해결하기 위해 간단한 해법은 에서 시작하여 1을 b로 증가시켜 모든 숫자의 비트를 찾는 것입니다. 더 효과적인 솔루션 이것은 보다 효과적인 솔루션이며 −를 사용
이 문제에서는 크기가 n인 이진 문자열의 배열 bin[]이 제공됩니다. 우리의 임무는 N 바이너리 문자열의 비트 AND(&)를 찾는 프로그램을 만드는 것입니다. 여기서 우리는 모든 숫자를 가져와서 비트 AND를 찾습니다. 즉, bin[0] &bin[1] &... bin[n-2] &bin[n] 문제를 이해하기 위해 예를 들어보겠습니다. 입력 - bin[] = {“1001”, “11001”, “010101”} 출력 - 000001 설명 − 모든 이진 문자열의 비
이 문제에서는 크기가 n이고 정수 k인 배열 arr[]이 제공됩니다. 우리의 임무는 인덱스 i에서 j까지의 하위 배열을 찾고 모든 요소의 비트 AND를 계산하는 것입니다. 이 후 abs(K-(하위 배열의 비트 AND))의 최소값을 인쇄합니다. 문제를 이해하기 위해 예를 들어보겠습니다. 입력 - arr[] ={5, 1}, k =2 출력 - 문제를 해결하기 위해 몇 가지 방법이 있을 수 있습니다. 한 가지 간단한 솔루션은 직접 방법을 사용하는 것입니다. 모든 하위 배열에 대해 비트 AND를 찾은 다음 |K-X|를 찾습니다.