
Excel은 단순성과 유연성으로 인해 많은 데이터 분석가가 선호하는 도구입니다. 그러나 규모가 크고 반복적이거나 복잡한 데이터 작업의 경우 Python은 속도, 자동화 및 고급 분석을 제공합니다. Excel과 Python을 통합하면 두 가지 장점을 모두 활용할 수 있습니다.
이 튜토리얼에서는 강력한 데이터 과학 워크플로를 위해 Excel과 Python을 결합하는 방법을 보여줍니다.
필수 도구 및 설정
Excel과 Python을 결합하기 전에 환경을 설정하십시오. 이를 통해 첫 단계부터 작업 흐름이 원활하고 생산적으로 진행될 수 있습니다.
전제조건:
- 마이크로소프트 엑셀 :초기 데이터 검토 및 보고용.
- 파이썬 3.x :데이터 과학 워크플로를 위한 엔진
- Python 라이브러리 :
- 판다 데이터 분석을 위해.
- 매트플롯립 음모를 꾸미기 위해.
- openpyxl (선택사항, Excel 파일 작성용).
- 너무 (숫자).
- matplotlib/seaborn 시각화를 위해.
Python 라이브러리 설치:
pip install pandas matplotlib openpyxl
1. Python으로 데이터 읽기
Pandas를 사용하여 Python에 데이터를 로드할 수 있으므로 표 형식 데이터를 쉽게 조작하고 분석할 수 있습니다.
import pandas as pd
# Read data from Excel file
df = pd.read_excel('SalesData.xlsx')
# Preview data
print(df.head()) # Show the first 5 rows of the data
print(df.info()) # Show info about columns, datatypes, and missing values
- pd.read_csv() Excel 파일을 Pandas DataFrame으로 읽습니다.
- df.head() 처음 5개 행을 표시하므로 빠르게 확인하는 데 좋습니다.
- df.info() 행, 열 및 데이터 유형의 수를 표시합니다.
다음과 같은 요약과 함께 판매 데이터의 처음 몇 행이 표시됩니다.
TransactionID Date CustomerID ProductID ProductName Category Quantity UnitPrice Region Channel SalesRep 0 100001 2024-01-02 C-100 P-101 Laptop Electronics 2.0 800.0 East Online Smith 1 100002 2024-01-02 C-101 P-102 Printer Electronics 1.0 200.0 West Retail Johnson 2 100003 2024-01-03 C-102 P-103 Mouse Electronics 5.0 25.0 North Online Lee 3 100004 2024-01-04 C-103 P-104 Desk Furniture 1.0 150.0 South Retail Brown 4 100005 2024-01-05 C-104 P-105 Monitor Electronics 3.0 175.0 NaN Online Davis <class 'pandas.core.frame.DataFrame'> RangeIndex: 63 entries, 0 to 62 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 TransactionID 63 non-null int64 1 Date 62 non-null datetime64[ns] 2 CustomerID 62 non-null object 3 ProductID 61 non-null object 4 ProductName 63 non-null object 5 Category 61 non-null object 6 Quantity 61 non-null float64 7 UnitPrice 62 non-null float64 8 Region 62 non-null object 9 Channel 62 non-null object 10 SalesRep 62 non-null object dtypes: datetime64[ns](1), float64(2), int64(1), object(7) memory usage: 5.5+ KB None
2. 데이터 정리 및 변환
원시 데이터는 분석 준비가 거의 되어 있지 않습니다. 이 단계에서는 누락된 값을 수정하고, 열을 올바른 유형으로 변환하고, 새로운 계산된 필드를 추가합니다.
중복 제거:
# Remove Duplicates df = df.drop_duplicates()
- 중복된 값을 삭제합니다.
누락된 값 확인:
# Print count of missing values per column print(df.isnull().sum())
- 각 열에 누락된(NaN) 값이 몇 개 있는지 표시합니다. 발견된 경우 삭제하거나 채울 수 있습니다.
#Output: TransactionID 0 Date 1 CustomerID 1 ProductID 2 ProductName 0 Category 2 Quantity 2 UnitPrice 1 Region 1 Channel 1 SalesRep 1 dtype: int64
데이터 유형 변환:
# Convert 'Date' column to pandas datetime type for easier filtering/grouping df['Date'] = pd.to_datetime(df['Date'])
- 더 쉬운 필터링과 그룹화를 위해 날짜 열을 텍스트에서 팬더 날짜/시간 형식으로 변환합니다.
'TotalSales' 열 만들기:
# Add a new column: total value for each transaction df['TotalSales'] = df['Quantity'] * df['UnitPrice']
- 각 거래의 총 가치를 표시하는 새 열을 추가합니다.
시계열 분석을 위한 추출 월:
df['Month'] = df['Date'].dt.to_period('M')
- 이렇게 하면 월별 매출을 그룹화하고 분석할 수 있는 월 열이 생성됩니다.
- 이제 print(df.head())를 사용하여 정리된 데이터를 미리 봅니다.
#Ouput: TransactionID Date CustomerID ProductID ProductName Category ... UnitPrice Region Channel SalesRep TotalSales Month 0 100001 2024-01-02 C-100 P-101 Laptop Electronics ... 800.0 East Online Smith 1600.0 2024-01 1 100002 2024-01-02 C-101 P-102 Printer Electronics ... 200.0 West Retail Johnson 200.0 2024-01 2 100003 2024-01-03 C-102 P-103 Mouse Electronics ... 25.0 North Online Lee 125.0 2024-01 3 100004 2024-01-04 C-103 P-104 Desk Furniture ... 150.0 South Retail Brown 150.0 2024-01 4 100005 2024-01-05 C-104 P-105 Monitor Electronics ... 175.0 NaN Online Davis 525.0 2024-01
3. 데이터 분석
이제 깨끗한 데이터 세트를 사용하여 비즈니스 가치를 창출하는 통찰력을 생성할 수 있습니다. 여기에는 월별, 제품별, 지역별 판매량 집계가 포함됩니다.
월별 총 매출:
# Group by month and sum the total sales for each month
monthly_sales = df.groupby('Month')['TotalSales'].sum()
print(monthly_sales)
- 데이터를 월별로 그룹화하고 각 월의 TotalSales를 합산합니다.
#Output: Month 2024-01 9075.0 2024-02 9800.0 2024-03 9075.0 Freq: M, Name: TotalSales, dtype: float64
가장 많이 팔리는 제품:
# Group by product, sum total sales, and sort from highest to lowest
product_sales = df.groupby('ProductName')['TotalSales'].sum().sort_values(ascending=False)
print(product_sales)
- 제품별 판매량을 합산한 다음 가장 인기 있는 것부터 가장 인기 없는 것 순으로 정렬합니다.
#Output: ProductName Laptop 15200.0 Monitor 3850.0 Printer 3200.0 Desk 2550.0 Chair 2325.0 Mouse 1125.0 Name: TotalSales, dtype: float64
지역별 매출:
# Group by region and sum total sales per region
region_sales = df.groupby('Region')['TotalSales'].sum()
print(region_sales)
- 지역별 총 매출을 집계합니다.
#Output: Region East 6075.0 North 5925.0 South 8225.0 West 7500.0
4. 주요 통찰력 시각화
데이터는 시각화될 때 더욱 강력해집니다. 귀하와 이해관계자들이 주요 동향을 한눈에 파악하는 데 도움이 되는 빠른 차트를 만들어 보겠습니다.
4.1. 월간 판매 동향
import matplotlib.pyplot as plt # Import for plotting
# Create a bar chart of sales by month
monthly_sales.plot(
kind='bar',
title='Total Sales by Month',
ylabel='Sales ($)',
xlabel='Month'
)
plt.tight_layout() # Avoid label overlap
plt.savefig('monthly_sales.png') # Save the figure as a PNG file
plt.show() # Display the chart - 월별 매출을 막대 차트로 표시합니다.
- plt.savefig는 보고서용 차트를 저장합니다
- 막대 차트에는 매월 매출 변화가 표시됩니다.
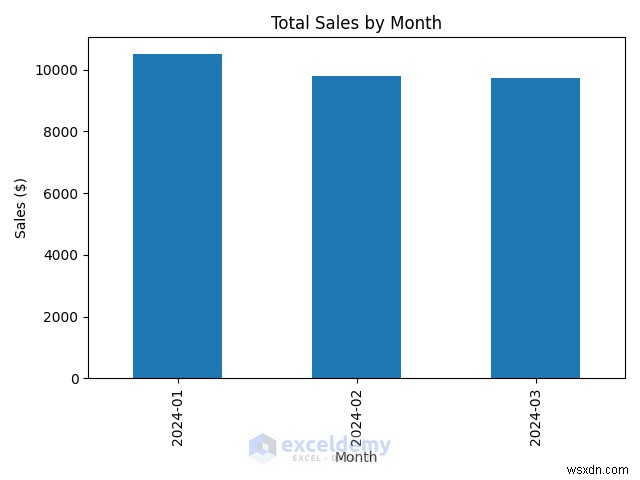
4.2. 지역별 매출
# Pie chart of sales by region
region_sales.plot(
kind='pie',
autopct='%1.1f%%',
title='Sales Distribution by Region'
)
plt.ylabel('') # Remove default y-label
plt.tight_layout()
plt.savefig('region_sales.png')
plt.show()
- 지역별 판매 원형 차트로 관리 또는 마케팅에 적합합니다.
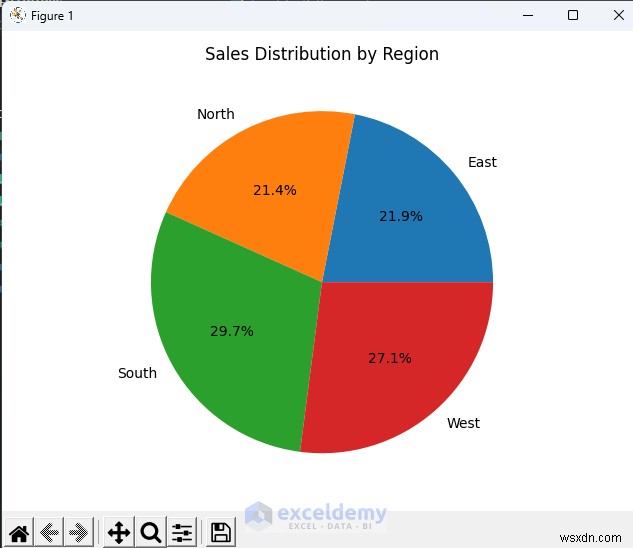
5. 고급 분석 및 모델링
기본적인 그룹화 및 요약 외에도 Python을 사용하면 단 몇 줄의 코드만으로 고급 통계 분석, 피벗 테이블, 심지어 기계 학습까지 가능합니다. 더 많은 통찰력을 얻기 위해 데이터를 더 깊이 파고들어 보겠습니다.
5.1. 기술통계
기술 통계는 데이터 세트에 대한 빠른 요약을 제공하여 숫자 열의 평균, 표준 편차 및 분위수를 표시합니다.
# Show summary statistics for numeric columns (mean, std, min, max, quartiles, etc.) print(df.describe())
- df.describe() 모든 숫자 열(예:Quantity, UnitPrice, TotalSales)을 빠르게 요약합니다.
#Output: TransactionID Quantity UnitPrice TotalSales count 61.000000 59.000000 60.000000 59.000000 mean 100030.180328 2.542373 262.083333 478.813559 std 17.497150 1.534905 277.339497 527.085627 min 100001.000000 1.000000 25.000000 75.000000 25% 100015.000000 1.000000 75.000000 162.500000 50% 100030.000000 2.000000 175.000000 300.000000 75% 100045.000000 3.000000 200.000000 525.000000 max 100060.000000 7.000000 800.000000 2400.000000
5.2. 팬더의 피벗 테이블
피벗 테이블은 Excel의 대화형 보고에 강력하며 Pandas도 이를 수행할 수 있습니다.
# Create a pivot table: sum TotalSales for each Region pivot = df.pivot_table(index='Region', values='TotalSales', aggfunc='sum') print(pivot)
- pivot_table() Excel의 피벗 테이블과 유사하게 각 지역의 TotalSales를 요약합니다.
#Output TotalSales Region East 6075.0 North 5925.0 South 8225.0 West 7500.0
5.3. 간단한 머신러닝 예시
간단한 선형 회귀(머신러닝) 모델을 사용해 판매량만으로 총 판매량을 예측할 수 있는지 살펴보겠습니다.
from sklearn.linear_model import LinearRegression # Import linear regression from scikit-learn
# Prepare features and target variable
X = df[['Quantity']] # Feature: Quantity sold
y = df['TotalSales'] # Target: Total sales value
# Create and fit the regression model
model = LinearRegression()
model.fit(X, y)
# Print the regression coefficient (slope)
print('Coefficient:', model.coef_)
# Print the intercept (base value when Quantity=0)
print('Intercept:', model.intercept_) - scikit-learn에서 선형 회귀를 가져옵니다.
- 수량을 사용하여 TotalSales를 예측합니다.
- 모델을 맞추고 계수(추가 단위 판매당 매출 증가량)를 인쇄합니다.
#Output: Coefficient: [-37.65294772] Intercept: 596.8483500185391
6. 정리/분석된 데이터를 Excel로 다시 내보내기
데이터를 정리, 분석 및 모델링한 후 요약 테이블과 통찰력을 다중 시트 Excel 파일로 내보낼 수 있습니다. 이렇게 하면 모든 주요 결과를 함께 모아 Excel에서 검토할 수 있습니다.
# Export summary and advanced analysis tables to a multi-sheet Excel file
with pd.ExcelWriter('sales_summary.xlsx') as writer:
# Monthly summary
monthly_sales.to_frame().to_excel(writer, sheet_name='Monthly Sales')
# Product summary
product_sales.to_frame().to_excel(writer, sheet_name='Product Sales')
# Region summary
region_sales.to_frame().to_excel(writer, sheet_name='Region Sales')
# Pivot table (total sales by region)
pivot.to_excel(writer, sheet_name='Pivot Table')
# Optionally, you can export descriptive statistics
df.describe().to_excel(writer, sheet_name='Descriptive Stats')
- 컨텍스트 관리자(작성자로 … 사용): Excel 파일이 올바르게 저장되고 쓰기 후에 닫혔는지 확인합니다.
- .to_excel() 각 테이블에 대해: 쉽게 액세스할 수 있도록 각 DataFrame 또는 요약을 자체 시트에 저장합니다.
- 맞춤 시트 이름: 각 시트의 이름은 분석 단계와 일치하도록 명확성을 위해 지정되었습니다.
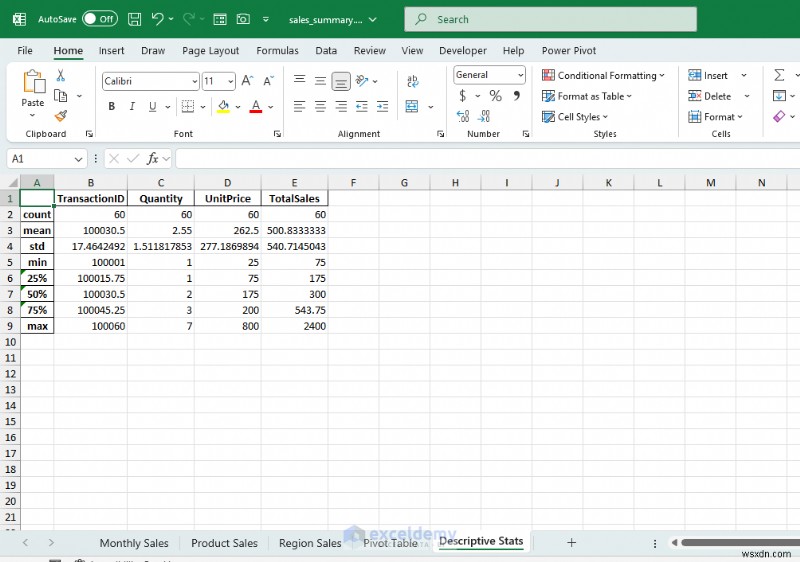
- sales_summary.xlsx를 엽니다. 엑셀에서.
- 월별 매출, 제품 매출, 지역 매출, 피벗 테이블 및 기술 통계에 대한 별도의 시트가 표시됩니다.
7. 작업 흐름 자동화 및 확장
Python을 사용하면 반복 보고서나 분석을 자동화할 수 있습니다. 다음에 새 Excel 파일을 받으면 파일을 바꾸고 스크립트를 다시 실행하세요. 모든 분석 및 보고서는 즉시 새로 고쳐집니다.
- 모든 분석 코드를 하나의 Python 파일에 보관하세요.
- 보고서를 업데이트하려면 CSV를 바꾸고 다음을 실행하세요.
python Excel_to_Python.py
- 더 많은 기능을 사용하려면 이 작업을 주별/월별 작업으로 예약할 수 있습니다.
결론
Excel의 직관적인 데이터 입력 및 보고 기능과 Python의 데이터 과학 기능을 결합하면 크고 지저분한 데이터 세트를 효율적으로 처리하고 분석할 수 있습니다. 반복적인 보고 작업을 자동화합니다. 기계 학습 및 고급 시각화를 잠금 해제합니다. 하루아침에 Python 전문가가 될 필요는 없습니다. 하나의 간단한 작업으로 시작하세요. 작동하면 한 단계를 더 추가하세요. 당신이 알기도 전에 복잡한 보고서를 자동화하게 될 것입니다.
솔루션이 포함된 무료 고급 Excel 연습을 받아보세요!