
Excel은 기본적인 기계 학습 작업을 위한 놀랍도록 강력한 도구입니다. 머신러닝 플랫폼은 아니지만 내장된 함수와 솔버를 사용하여 선형 및 로지스틱 회귀와 같은 기본 ML 개념을 입증하는 데 효과적으로 사용할 수 있습니다.
이 튜토리얼에서는 해 찾기 및 수식을 사용하여 Excel에서 간단한 기계 학습 모델을 구축하는 방법을 보여줍니다.
- 선형 회귀: 연속 값(판매 수익, 주택 가격, 시험 점수 등)을 예측합니다.
- 로지스틱 회귀: 예/아니요 결과(고객 구매, 대출 불이행, 의료 진단, 합격/실패 등)를 예측합니다.
전제조건:
- Microsoft Excel(2016 이상 권장).
- 해석 추가 기능을 활성화합니다.
- 파일 로 이동 탭>> 옵션 선택>> 추가 기능을 선택합니다.>> Excel 추가 기능을 선택합니다. .
- 이동을 클릭하세요. .
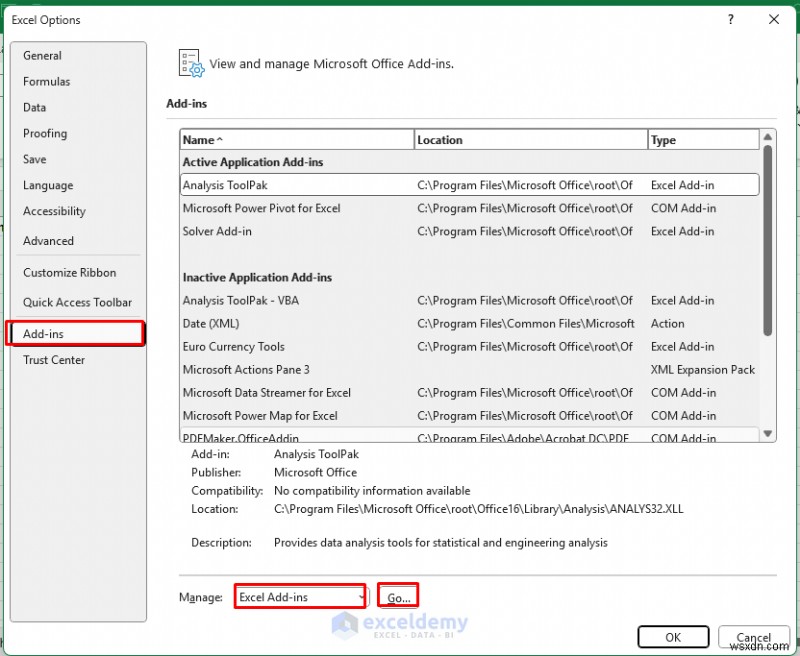
- 해 찾기 추가 기능 선택 .
- 확인을 클릭하세요. .
- 회귀 개념에 대한 기본 이해
1부:선형 회귀 모델
선형 회귀는 데이터 포인트를 통해 연속적인 수치 값을 예측하기 위한 최적의 직선을 찾습니다. 광고 지출(X)이 판매 수익(Y)을 예측하는 간단한 비즈니스 시나리오를 모델링하겠습니다. 각 데이터 포인트는 한 달 간의 비즈니스 데이터를 나타냅니다.
1단계:샘플 데이터 설정
입력(광고 지출(천 단위))과 출력(판매 수익(천 단위)) 사이의 명확한 선형 관계를 보여주는 현실적인 데이터세트를 만듭니다.
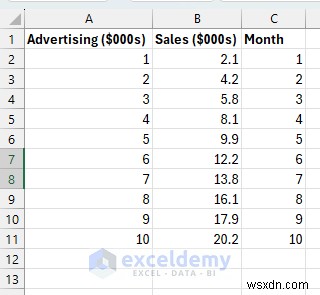
각 행은 한 달 간의 비즈니스 데이터입니다. 광고 지출이 증가하면 판매 수익도 증가하지만 완벽하지는 않습니다(일부 임의성이 존재하며 현실적입니다).
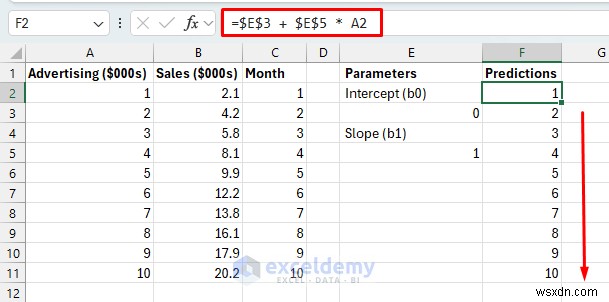
2단계:예측 수식 만들기
최적의 선을 찾기 위해 모델이 조정할 수학적 "노브"를 설정합니다. 선형 회귀에는 두 가지 매개변수가 필요합니다:
- 가로채기(b0) :선이 Y축과 교차하는 위치(광고비가 0인 기준 매출)
- 경사도(b1) :광고비가 1,000달러 증가할 때마다 매출이 얼마나 증가하는지.
별도의 셀에 모델 매개변수를 설정하세요:
모델 매개변수:
Predicted Y = b0 + b1 * X
- 가로채기(b0)
- 초기값 0
- 기울기(b1)
- 초기값 1
우리는 이 선형 방정식을 사용하여 광고 지출을 기반으로 매출을 예측할 것입니다. 이것이 모델의 핵심으로, 광고금액을 가져와 매출이 얼마나 되어야 할지 추정하는 것입니다.
수학적 의미:
- b0 =0.5이고 b1 =2이면 광고에 3,000달러를 지출하면 매출이 0.5 + 2*3 =6,500달러로 예측됩니다.
- 모델은 데이터에서 b0 및 b1에 대한 최상의 값을 학습합니다.
예측 공식:
- 셀을 선택하고 다음 수식을 삽입하세요.
- 이 수식을 F11로 드래그하세요.
4단계:잔차와 오차 계산
우리의 예측이 얼마나 틀린지 측정해 보세요. 모델은 이러한 오류를 최소화하려고 노력하여 학습하기 때문에 이는 매우 중요합니다.
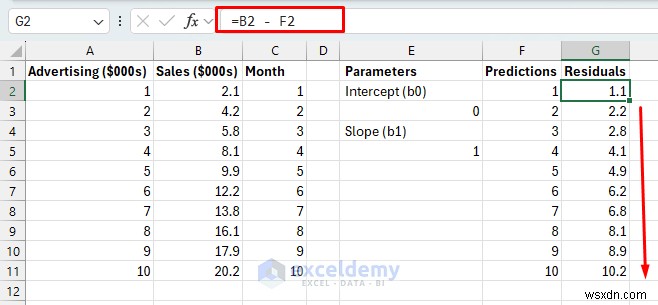
- 잔차: 매월 실제 판매량과 예상 판매량의 차이
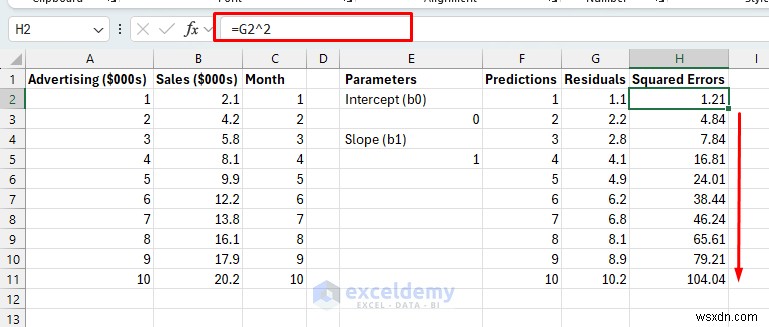
- 제곱 오류: 잔차 제곱(모든 오류를 양수로 만들고 큰 오류에 더 많은 페널티를 주기 위해).
잔차:
- 수식을 G11로 드래그하세요.
제곱 오류:
- 수식을 H11로 드래그하세요.
5단계:오류 측정항목 계산
비즈니스에 의미 있는 모델 성능 측정을 생성합니다. 이러한 측정항목은 모델이 실제 사용에 충분한지 이해하는 데 도움이 됩니다.
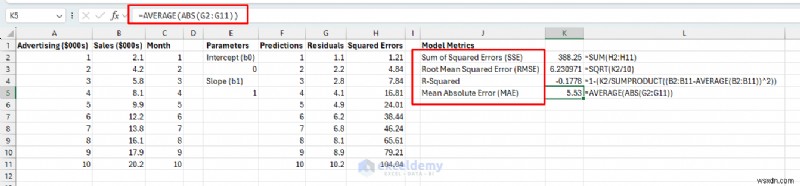
지정된 영역에서 주요 측정항목을 설정하세요.
오류 측정항목:
- 오차 제곱합(SSE): 모든 예측에 대한 총 오류 – 낮을수록 좋습니다.
- RMSE(제곱 평균 오차): 원래 단위($000초)의 평균 오류 - 해석하기 더 쉽습니다.
- R 제곱: 광고로 설명되는 매출 변동률(0~100%, 높을수록 좋음)
=1-(K2/SUMPRODUCT((B2:B11-AVERAGE(B2:B11))^2))
- 평균 절대 오차(MAE): 평균 절대 오차 – RMSE보다 이상값에 덜 민감합니다.
6단계:솔버를 사용하여 매개변수 최적화
Excel에서 예측 오류를 최소화하는 최적의 절편 및 기울기 값을 자동으로 찾도록 합니다.
- 데이터 로 이동 탭>> 해 찾기 선택 .
- 목표 설정:K2 (SSE 셀).
- 받는사람:최소 .
- 변수 셀 변경:E3,E5 (귀하의 매개변수).
- 해결을 클릭하세요. .
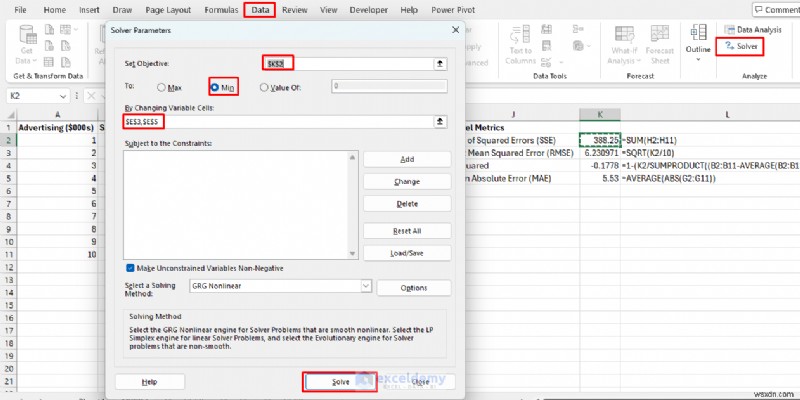
- 확인을 클릭하세요. .
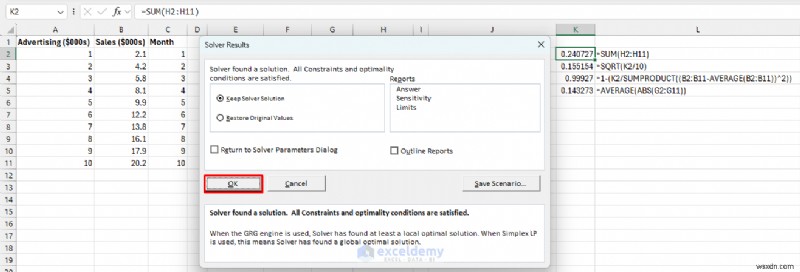
- b0과 b1의 수백만 가지 조합을 시도합니다.
- 각 조합의 총 오류를 계산합니다.
- 오류가 가장 낮은 조합을 찾을 때까지 계속 조정합니다.
- 이것은 추측보다 훨씬 빠르고 정확합니다.

7단계:시각화 생성
모델의 시각적 검증이 의미가 있습니다. 대부분의 데이터 포인트에 가깝게 지나가는 예측 선을 살펴보겠습니다.
- 광고 및 판매 항목을 선택하세요.
- 삽입으로 이동 탭>> 차트에서>> 산점도를 선택합니다. .
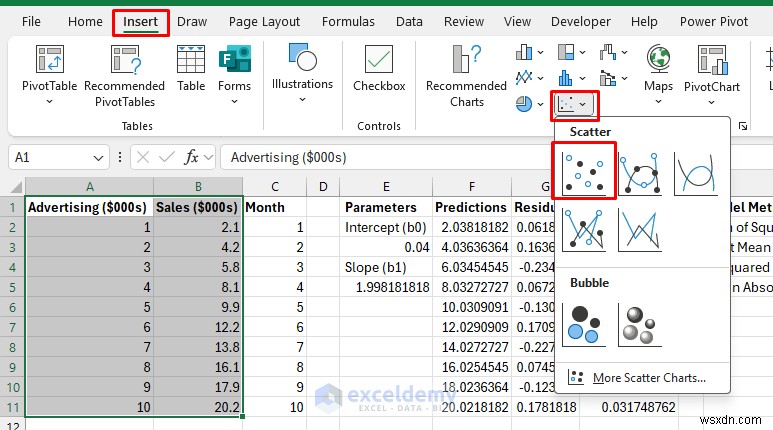
- 차트를 마우스 오른쪽 버튼으로 클릭하고>> 데이터 를 선택합니다.>> 시리즈 추가를 선택하세요. .
- 시리즈 이름: F1 셀을 선택하세요.
- 시리즈 X 값: X 값 선택(예:B2:B11)
- 계열 Y 값: 클릭하여 예측값 F2:F11을 선택하세요.
- 예측 계열을 선으로 형식화합니다.
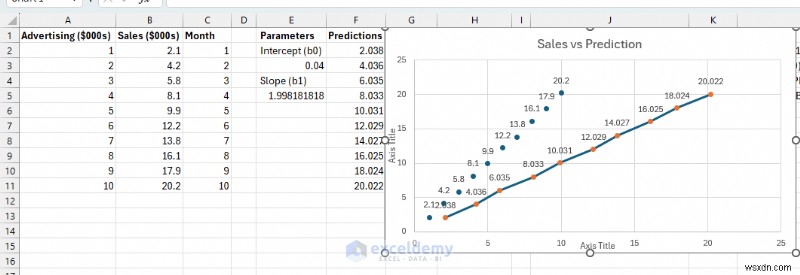
- 예측선은 데이터 포인트의 일반적인 추세를 따릅니다.
- 점은 선 주위에 흩어져 있습니다(모두 위나 아래가 아님).
- 잔차에 뚜렷한 패턴이 없습니다.
2부:로지스틱 회귀 모델
로지스틱 회귀는 예/아니요 결정의 확률을 예측합니다. 정확한 숫자를 예측하는 선형 회귀와 달리 로지스틱 회귀는 어떤 일이 일어날 가능성을 예측합니다(0-100%).
1단계:이진 분류 데이터 준비
고객의 구매 행동을 모델링해 보겠습니다. 고객 소득 수준(X)을 기준으로 고객이 프리미엄 제품을 구매할지(1), 구매하지 않을지(0) 예측하고 싶습니다. 이는 마케팅 타겟팅, 의료 진단 또는 이분법적인 결정에 일반적입니다.
로지스틱 회귀를 위한 데이터 설정:
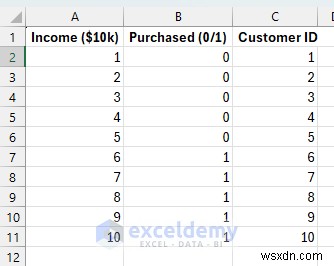
고객 소득 수준($10,000 단위) 및 구매 결정. 저소득 고객(1~5)은 구매(0)를 구매하지 않는 경향이 있는 반면, 고소득 고객(6~10)은 구매(1)를 구매하는 경향이 있습니다. 이는 현실적인 구매 패턴을 반영합니다.
2단계:로지스틱 예측 공식 생성
물류 모델 매개변수 초기화:
로지스틱 기능에 대한 매개변수를 설정합니다. 선형 회귀와 달리 이러한 매개변수는 보다 복잡한 수학적 변환(시그모이드 함수)을 통해 작동합니다.
- 가로채기(b0) :임계값을 왼쪽이나 오른쪽으로 이동합니다(50% 확률 발생).
- 경사도(b1) :'가능성 없음'에서 '가능성 있음'으로의 전환이 얼마나 가파른지 제어합니다.
- 시작 값 :합리적인 추측으로 시작합니다. 솔버가 이를 최적화합니다.
물류 매개변수:
Probability = 1 / (1 + e^(-(b0 + b1×X)))
- 가로채기(b0)
- -2 (초기값)
- 기울기(b1)
- 0.5(초기값)
로지스틱 예측 공식 만들기:
시그모이드 함수를 사용하여 선형 조합을 확률로 변환합니다. 이것은 0과 1 사이의 예측을 유지하는 수학적 마법입니다.
- 선형 조합 :b0 + b1*X (선형 회귀와 동일).
- 시그모이드 변환 :1/(1+e^(-(선형 조합)))은 모든 숫자를 0-1 범위로 변환합니다.
- 결과 :확률을 나타내는 부드러운 S-곡선입니다. 확률이 0.7이면 이 고객이 구매할 확률은 70%입니다.
확률 예측:
- 선형 조합:
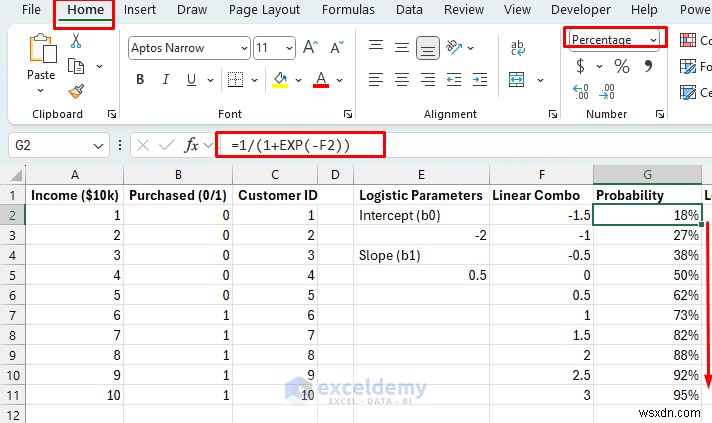
- 확률 예측:
- 셀 형식을 백분율(%)로 지정합니다. .
4단계:로그 가능성 계산
확률 예측이 실제 결과와 얼마나 잘 일치하는지 측정합니다. 이는 정확한 값이 아닌 확률을 다루기 때문에 단순한 오류보다 더 복잡합니다.
로그 가능성 구성요소:
=IF(B2=1,LN(MAX(G2,0.0001)),LN(MAX(1-G2,0.0001)))

- 이진 결과의 경우 단순 뺄셈(실제 – 예측)을 사용할 수 없습니다.
- 대신, 우리의 예측에 따른 실제 결과가 얼마나 '놀랐는지'를 측정합니다.
- 구매 확률을 90%로 예측하고 고객이 구매하더라도 놀라지 않습니다(좋은 모델).
- 구매 확률을 10%로 예측했는데 고객이 구매한다면 우리는 매우 놀라게 됩니다(나쁜 모델).
5단계:물류 모델 지표 설정
분류 성능에 대한 비즈니스 관련 측정값을 만듭니다. 이러한 지표는 모델이 실제 비즈니스 결정을 내리는 데 충분한지 결정하는 데 도움이 됩니다.
정밀도가 높다는 것은 낭비되는 마케팅 비용이 적다는 것을 의미합니다(낮은 오탐). 회상률이 높다는 것은 잠재 고객을 놓치지 않는다는 것을 의미합니다(낮은 거짓음성).
물류 측정항목:
- 모델 적합성/음수 로그 우도: 값이 낮을수록 확률 예측이 더 좋습니다.
- 정확도: 올바르게 분류된 고객의 비율(50%를 기준으로 사용하는 경우)
=SUMPRODUCT((G2:G11>0.5)*(B2:B11=1)+(G2:G11<=0.5)*(B2:B11=0))/10
- 정밀도: 우리가 예측한 고객 중 몇 퍼센트가 구매할 것이며, 몇 퍼센트가 구매했을까요?
=IF(SUMPRODUCT((G2:G11>0.5))=0,"No Predictions",SUMPRODUCT((G2:G11>0.5)*(B2:B11=1))/SUMPRODUCT((G2:G11>0.5)))
- 회상: 구매한 고객의 몇 퍼센트, 몇 퍼센트를 식별했나요?
=SUMPRODUCT((G2:G11>0.5)*(B2:B11=1))/SUMPRODUCT(B2:B11)
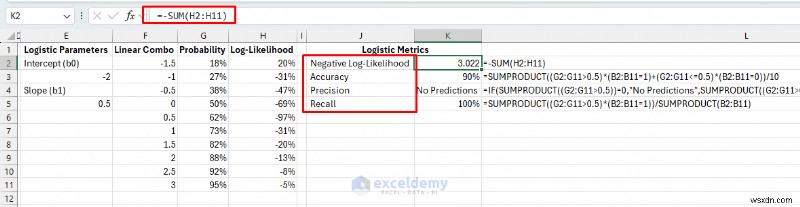
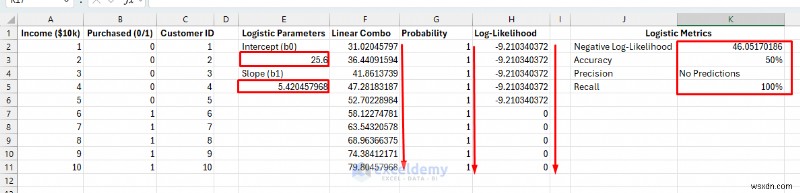
6단계:솔버로 물류 모델 최적화
데이터의 확률 패턴에 가장 잘 맞는 매개변수 값을 찾습니다. 솔버는 음의 로그 가능성을 최소화하여 실제 데이터를 관찰할 확률을 최대화합니다.
- 데이터 로 이동 탭>> 해 찾기 선택 .
- 목표 설정:K2 (음수 로그 가능성).
- 받는사람:최소 .
- 변수 셀 변경:E3,E5 .
- 해결을 클릭하세요. .
일반적인 문제 해결
- 솔버가 수렴하지 않음 :다른 초기값을 시도하거나 반복 횟수를 늘리십시오.
- 음의 R 제곱 :데이터 입력 오류나 모델 사양을 확인하세요.
- 물류의 완벽한 분리 :특성 값을 줄이거나 정규화를 추가합니다.
결론
이 자습서에서는 Excel에서 직접 기계 학습 모델을 구축하는 단계별 절차를 보여줍니다. Excel은 전문적인 ML 도구에 비해 한계가 있지만 모델 메커니즘을 이해하기 위한 투명성과 접근성을 제공합니다. Excel의 해 찾기 및 기본 수식을 사용하면 이러한 경량 기계 학습 모델을 신속하게 구현하고 예측을 시각화하며 간단하면서도 통찰력 있는 방법을 통해 모델 정확도를 이해할 수 있습니다. 여기에 표시된 기술은 더 복잡한 시나리오로 확장될 수 있으며 회귀 개념을 학습하기 위한 교육 도구 역할을 할 수 있습니다.
솔루션이 포함된 무료 고급 Excel 연습을 받아보세요!