
Excel은 강력한 데이터 관리 및 분석 도구입니다. 빠른 보고 및 계산에 적합하지만 작업이 지저분하거나 반복적이거나 너무 큰 경우에는 Python이 도움이 됩니다. Python은 Excel의 기본 제공 기능을 뛰어넘는 자동화, 고급 분석 및 통합 가능성을 열어줍니다. pandas와 같은 Python 라이브러리 데이터 조작 및 openpyxl 직접 Excel 파일을 처리하려면 이 작업을 원활하게 수행하세요.
이 튜토리얼에서는 Excel과 Python을 사용하여 수행할 수 있는 5가지 작업을 보여줍니다.
샘플 판매 데이터를 고려하여 Excel과 Python으로 할 수 있는 5가지 작업을 살펴보세요.
1. 지저분한 Excel 데이터 정리 및 표준화(반복적으로)
실제 데이터는 정리된 경우가 거의 없기 때문에 Excel에서는 지저분한 데이터를 갖는 것이 일반적입니다. 데이터에는 추가 공백, 대문자 혼합, 텍스트로 저장된 숫자, 일관되지 않은 서식, 누락된 값, 중복된 항목 또는 분석 전에 재구성이 필요한 데이터가 포함되는 경우가 많습니다. 이 문제는 공식과 분석을 망칩니다.
Python은 데이터 정리 작업에 탁월합니다. 다양한 파일의 데이터 형식을 표준화하고, 지능형 방법을 사용하여 누락된 값을 채우고, 중복 항목을 제거하고, 패턴에 따라 열을 분할 또는 결합하고, 비즈니스 규칙에 따라 데이터의 유효성을 검사하는 스크립트를 작성할 수 있습니다. 이러한 단계를 수행하려면 Excel에서 수동으로 찾기 및 바꾸기 작업을 수행하는 데 몇 시간이 걸릴 수 있습니다. Python을 사용하면 수천 개의 행을 몇 초 만에 처리하는 반복 가능한 스크립트를 만들 수 있습니다.
지저분한 판매 데이터를 받았다고 가정해 보겠습니다. 지저분한 데이터를 읽고, 열을 정리 및 표준화하고, 계산된 필드를 추가하는 Python 스크립트를 사용해 보겠습니다.
- 수익 =단위 * 단위 가격
- 순수익 =수익 * (1 – 할인율)
import pandas as pd
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="Sales Data")
# Clean types
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
df["DiscountPct"] = pd.to_numeric(df["DiscountPct"], errors="coerce").fillna(0.0)
df["Returned"] = (
df["Returned"].astype(str).str.strip().str.lower()
.map({"yes": True, "no": False})
.fillna(False)
)
# Add calculated fields
df["Revenue"] = df["Units"] * df["UnitPrice"]
df["NetRevenue"] = df["Revenue"] * (1 - df["DiscountPct"])
# Write back into the SAME file as a NEW sheet
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="CleanData", index=False)
print("Saved CleanData sheet inside:", file_path)
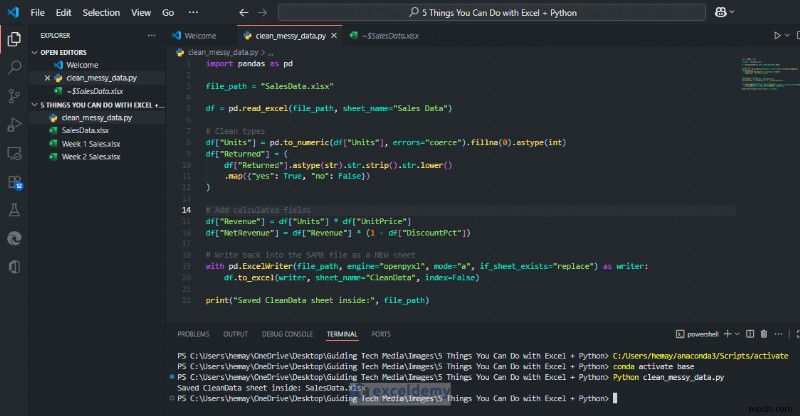
피벗, 차트 또는 조회가 중단되지 않는 깨끗한 데이터 세트가 포함된 새 시트를 얻게 됩니다. Excel에서는 정리된 데이터의 피벗/차트를 계속 사용할 수 있으므로 매 실행 시 일관성이 유지됩니다.
2. 자동으로 요약 생성(반복 가능한 보고서)
Excel에는 행 제한이 있으며 복잡한 계산으로 인해 속도가 느려질 수 있습니다. Python의 판다 라이브러리는 대규모 데이터 세트를 효율적으로 처리하고 계산을 훨씬 빠르게 수행합니다.
팬더와 함께 를 사용하면 수백만 개의 레코드가 포함된 데이터 세트로 작업하고, 복잡한 그룹화 및 집계 작업을 수행하고, Excel에서는 실용적이지 않을 수 있는 통계 분석을 실행할 수 있습니다. Python은 피벗 스타일 요약을 생성하고 이를 Excel로 내보낼 수 있습니다. 지역 및 카테고리별로 빠른 요약을 원하지만 매번 피벗을 다시 작성하고 싶지는 않다고 가정해 보겠습니다.
import pandas as pd
file_path = "SalesData.xlsx"
clean_sheet = "CleanData"
out_sheet = "Summary"
df = pd.read_excel(file_path, sheet_name=clean_sheet)
summary = (
df.groupby(["Region", "Category"], as_index=False)
.agg(
Orders=("OrderID", "count"),
Units=("Units", "sum"),
NetRevenue=("NetRevenue", "sum"),
Returns=("Returned", "sum")
)
)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
summary.to_excel(writer, sheet_name=out_sheet, index=False)
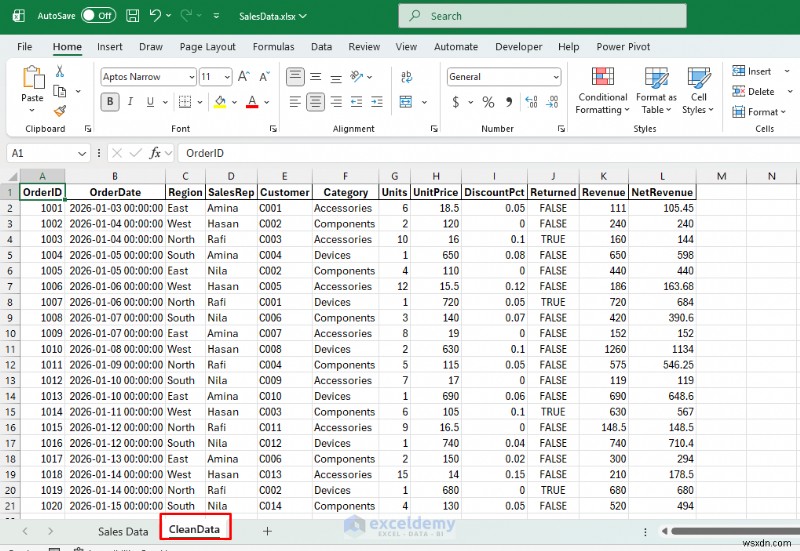
print(f"✅ Saved '{out_sheet}' sheet inside: {file_path}")
스크립트를 다시 실행할 때마다 업데이트되는 즉시 공유 가능한 피벗 스타일 시트인 지역별 수익 요약을 받게 됩니다.
3. Excel 데이터에서 차트 생성(수동 서식 지정 없음)
차트는 보고에서 가장 시간이 많이 걸리는 부분인 경우가 많습니다. Excel은 표준 차트를 제공하지만 Matplotlib와 같은 Python의 시각화 라이브러리는 , 시본 및 Plotly 훨씬 더 많은 유연성과 정교함을 제공합니다. 데이터가 변경되면 자동으로 업데이트되는 사용자 정의 시각화를 생성하거나, 사용자가 탐색할 수 있는 대화형 대시보드를 생성하거나, 모든 요소를 정밀하게 제어하여 출판 품질의 그래픽을 생성할 수 있습니다.
지역별 실적(지역별 순수익)을 시각화해 보겠습니다.
import pandas as pd
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
file_path = "SalesData.xlsx"
source_sheet = "CleanData"
output_sheet = "RegionChart" # data + chart in this one sheet
# Prepare chart data (NetRevenue by Region)
df = pd.read_excel(file_path, sheet_name=source_sheet)
chart_data = (
df.groupby("Region", as_index=False)["NetRevenue"]
.sum()
.sort_values("NetRevenue", ascending=False)
)
# Write chart data into output_sheet (same workbook)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
chart_data.to_excel(writer, sheet_name=output_sheet, index=False)
# Add the native Excel chart on the same sheet
wb = load_workbook(file_path)
ws = wb[output_sheet]
chart = BarChart()
chart.title = "Net Revenue by Region"
chart.y_axis.title = "Net Revenue"
chart.x_axis.title = "Region"
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, "D2") # place chart to the right of the data table
wb.save(file_path)
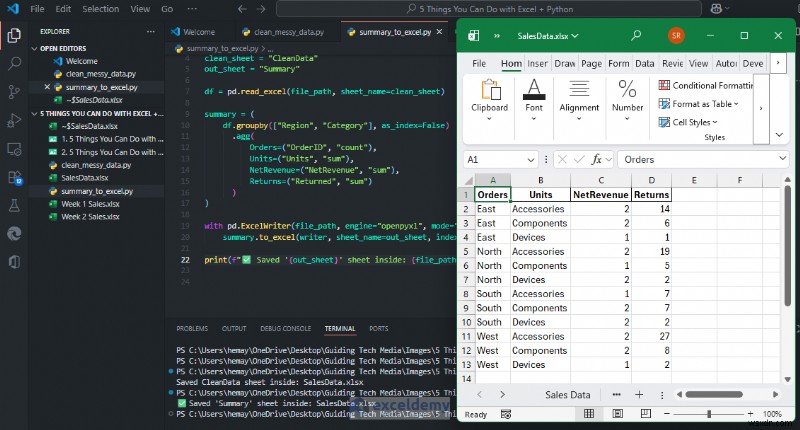
print(f"✅ Chart Created: {output_sheet}")
이제 막대 차트와 함께 지역별 수익 요약을 확인할 수 있습니다.
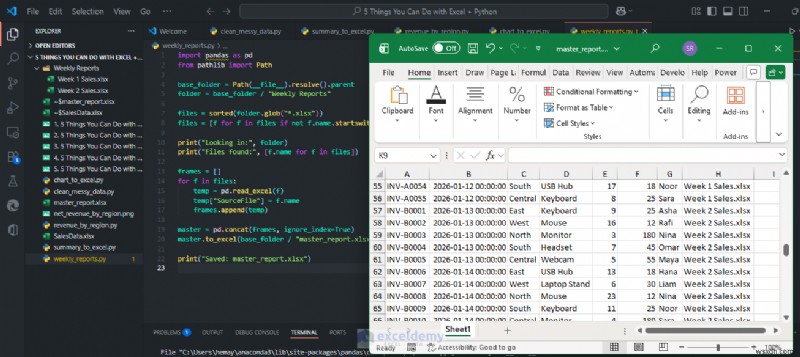
4. 여러 Excel 파일을 하나의 마스터 테이블로 병합
다양한 소스의 주간, 월간, 분기별 데이터를 병합하는 것이 일반적입니다. 다른 사람이나 팀의 Excel 파일을 병합하는 것은 느리고 오류가 발생하기 쉽습니다. Python은 몇 초 만에 이를 결합하고 소스 파일을 추적할 수 있습니다.
주간 파일을 Weekly Reports/라는 폴더에 병합해 보겠습니다. (모두 동일한 열을 사용함).
import pandas as pd
from pathlib import Path
base_folder = Path(__file__).resolve().parent
folder = base_folder / "Weekly Reports"
files = sorted(folder.glob("*.xlsx"))
files = [f for f in files if not f.name.startswith("~$")] # ignore Excel lock files
print("Looking in:", folder)
print("Files found:", [f.name for f in files])
frames = []
for f in files:
temp = pd.read_excel(f)
temp["SourceFile"] = f.name
frames.append(temp)
master = pd.concat(frames, ignore_index=True)
master.to_excel(base_folder / "master_report.xlsx", index=False)
print("Saved: master_report.xlsx")
SourceFile이 포함된 하나의 통합 테이블을 얻게 됩니다. 감사용 열입니다. 매주 스크립트를 실행하기만 하면 됩니다.
5. Excel이 쉽게 수행할 수 없는 작업 예측(기계 학습 예)
패턴(할인, 카테고리, 단위, 가격)을 사용하여 반품 위험을 추정한 다음 Excel 사용자가 필터링하고 정렬할 수 있도록 확률을 다시 작성할 수 있습니다. Python은 이러한 기계 학습 작업을 쉽게 수행할 수 있습니다.
우리의 데이터세트는 작은 데이터세트입니다. 그래도 작업 흐름을 보여줍니다.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="CleanData")
X = df[["Region", "SalesRep", "Category", "Units", "UnitPrice", "DiscountPct"]]
y = df["Returned"].astype(int)
cat_cols = ["Region", "SalesRep", "Category"]
num_cols = ["Units", "UnitPrice", "DiscountPct"]
preprocess = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(handle_unknown="ignore"), cat_cols),
("num", "passthrough", num_cols),
]
)
model = Pipeline(steps=[
("prep", preprocess),
("clf", LogisticRegression(max_iter=1000))
])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model.fit(X_train, y_train)
# Predict probability of return for all rows
df["ReturnProb"] = model.predict_proba(X)[:, 1]
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="WithReturnRisk", index=False)
Excel에서 WithReturnRisk를 탐색하세요. ReturnProb를 필터링하고 높은 순서에서 낮은 순서로 위험해 보이는 주문을 확인하세요.
Excel의 Python(Excel에서 사용 가능한 경우)
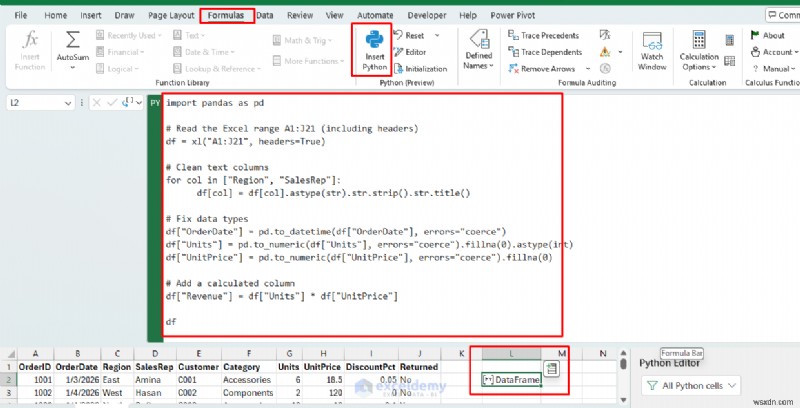
컴퓨터의 Excel에 Python(미리 보기)이 있는 경우 셀에서 직접 Python을 실행하고 결과를 시트에 반환할 수 있습니다. (Microsoft의 Excel의 Python 개요 참조) .) 다음은 작은 범위를 읽고, 텍스트를 정리하고, 수익을 계산하고, 정리된 테이블을 반환하는 간단한 예입니다.
- Excel에서 데이터세트를 입력하세요
- 빈 셀을 클릭하세요
- 수식으로 이동 탭>> Python 삽입을 선택합니다.
- Python 스크립트 붙여넣기
import pandas as pd
# Read the Excel range A1:J21 (including headers)
df = xl("A1:J21", headers=True)
# Clean text columns
for col in ["Region", "SalesRep"]:
df[col] = df[col].astype(str).str.strip().str.title()
# Fix data types
df["OrderDate"] = pd.to_datetime(df["OrderDate"], errors="coerce")
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
# Add a calculated column
df["Revenue"] = df["Units"] * df["UnitPrice"]
df
DataFrame을 반환합니다. , 이는 Python의 테이블 객체입니다. Excel에서는 이를 테이블 미리보기(및 카드)로 표시합니다.
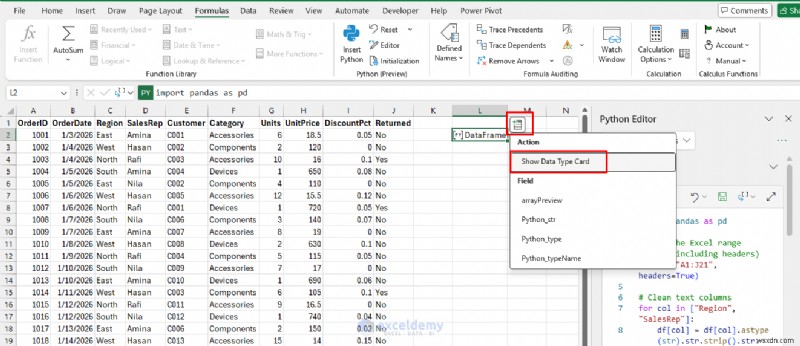
이제 출력을 깨끗한 테이블처럼 셀에 "쏟아냅니다".
- 데이터 삽입을 클릭하세요. DataFrame에서>> DataType 카드 표시를 선택합니다. 테이블을 미리 보려면
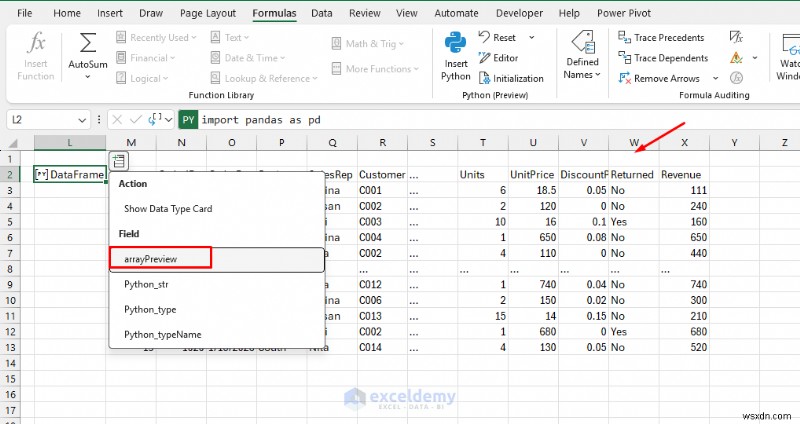
- 배열 미리보기 선택 테이블을 Excel로 가져오려면
- 이제 표준화된 텍스트와 새로운 수익이 생겼습니다. 열
결론
이 문서에서는 Excel과 Python을 사용하여 수행할 수 있는 5가지 작업을 보여줍니다. Excel은 Python을 통해 더욱 강력해졌습니다. 지저분한 데이터 세트를 정리하고, 피벗 스타일 요약을 생성하고, 차트를 자동화하고, 많은 Excel 파일을 병합하고, 간단한 기계 학습 통찰력을 추가하는 것이 더 쉬워졌습니다. Excel과 Python을 결합하면 데이터 가져오기/내보내기부터 자동화 및 시각화까지 워크플로가 간소화됩니다. 작은 스크립트로 시작하여 더 많은 라이브러리를 실험해보세요.
솔루션이 포함된 무료 고급 Excel 연습을 받아보세요!