
정규식(regex)은 처음에는 복잡해 보일 수 있지만 패턴 일치 및 텍스트 조작을 위한 강력한 도구입니다. Excel에서는 복잡한 패턴을 기반으로 데이터를 검색, 추출 및 바꿀 수 있으므로 데이터 정리, 유효성 검사, 구문 분석과 같은 작업을 훨씬 더 효율적으로 수행할 수 있습니다. 기본 사항을 익히면 정보를 정리하고 검증하고 추출하는 데 드는 시간을 절약할 수 있습니다. 정규식을 지원하기 위해 Excel에서는 REGEXTEST, REGEXEXTRACT 및 REGEXREPLACE와 같은 기능을 제공합니다.
이것은 Excel 고급 사용자를 위한 정규식 집중 강좌입니다.
정규식이란 무엇인가요?
Regex(정규 표현식)는 텍스트의 패턴 언어입니다. 정확한 단어를 검색하거나 일치시키는 대신 정규식을 사용하면 텍스트의 모양을 설명할 수 있습니다. Excel에서 정규식은 하나의 패턴으로 텍스트를 검증, 추출 또는 정리할 수 있는 강력한 FIND + MID + SUBSTITUTE 결합과 같습니다.
정규식을 사용하여 Excel의 일반적인 구조(이메일 주소, 전화번호, 다양한 형식의 날짜 또는 규칙을 따르는 모든 ID)를 일치시킬 수 있습니다.
최신 Excel에서는 주로 다음과 함께 사용합니다.
- REGEXTEST(패턴이 존재하는지 확인)
- REGEXEXTRACT(일치하는 부분 가져오기)
- REGEXREPLACE(일치 항목 바꾸기/정리)
정규식 기본:패턴 작성
정규식 패턴은 찾고 있는 것을 정의하는 문자열입니다. 이는 리터럴 문자(예:"abc")와 특수 메타 문자를 결합합니다. 이 표를 빠른 참조로 사용할 수 있습니다.
주요 메타문자 및 구문:
- 사용
- 수량자 (*, +, ?, {})는 그 앞의 요소에 적용됩니다.
- 플래그: Excel의 정규식 함수는 패턴에서 (?i)와 같은 인라인 플래그를 지원하지 않습니다. 대소문자 구분을 위한 함수 인수(예:REGEXTEST의 세 번째 인수)를 사용하거나 문자 클래스(예:[Aa])를 사용하세요.
- 욕심 많은 사람과 게으른 사람: 기본적으로 수량자는 탐욕적입니다(최대한 많이 일치함). 추가하다 ? 게으르게 만들기 위해 수량자 뒤에 붙입니다(예:.*?).
Excel의 정규식 함수
Excel은 기본적으로 세 가지 정규식 기능을 제공합니다. 이러한 함수는 텍스트 문자열과 정규식 패턴을 입력으로 사용하고 패턴을 기반으로 텍스트의 유효성을 검사하거나 변환합니다. 강좌를 시작하기 전에 각 기능에 대해 알아봅시다.
구문:
=REGEXTEST(text, pattern, [case_sensitivity])
이 함수는 패턴이 제공된 텍스트의 일부와 일치하는지 확인합니다. 패턴이 텍스트의 어느 부분과 일치하면 TRUE를 반환합니다. 그렇지 않으면 거짓입니다.
- 텍스트: 테스트하려는 텍스트 또는 셀 참조.
- 패턴: 일치시키려는 텍스트를 설명하는 정규식(regex) 패턴.
- [대소문자 구분]: 일치 항목이 대소문자를 구분하는지 여부를 결정합니다. 기본적으로 일치 여부는 대소문자를 구분합니다.
- 0: 대소문자 구분
- 1: 대소문자를 구분하지 않음
이 함수는 A1에 세 개의 연속 숫자가 포함되어 있으면 TRUE를 반환합니다.
구문:
=REGEXEXTRACT(text, pattern, [return_mode], [case_sensitivity])
이 기능은 일치하는 텍스트를 추출합니다.
- [반환_모드]: 추출하려는 문자열을 지정하는 숫자입니다. 기본적으로 반환 모드는 0입니다.
- 0: 패턴과 일치하는 첫 번째 문자열을 반환합니다
- 1: 패턴과 일치하는 모든 문자열을 배열로 반환
- 2: 첫 번째 일치 항목의 캡처링 그룹을 배열로 반환
=REGEXEXTRACT(A1, "\d{3}-\d{3}-\d{4}")
'123-456-7890'과 같은 전화번호를 추출합니다.
구문:
=REGEXREPLACE(text, pattern, replacement, [occurrence], [case_sensitivity])
이 기능은 일치하는 항목을 새 텍스트로 바꿉니다.
- 교체: 패턴 대신 사용할 텍스트입니다. $1, $2 등으로 캡처 그룹을 참조할 수 있습니다.
- 발생: 바꾸려는 패턴의 인스턴스를 지정합니다. 기본적으로 발생은 0이며 모든 인스턴스를 대체합니다. 음수는 해당 인스턴스를 대체하여 끝부터 검색합니다.
=REGEXREPLACE(A1, "\d{3}", "***")
모든 3자리 시퀀스를 마스킹합니다.
이러한 함수는 배열을 반환하는 경우(예:다중 추출) 유출됩니다.
Excel 고급 사용자를 위한 실제 사례
지저분한 데이터가 있다고 가정해 보겠습니다. 일반적인 시나리오에 정규식을 적용해 보겠습니다.
예 1:이메일 주소 확인
REGEXTEST를 사용하여 유효한 회사 이메일에 플래그를 지정할 수 있습니다(대소문자를 구분하지 않는 일치가 더 안전한 경우가 많습니다).
다음 패턴을 사용하여 이메일을 확인하세요.
- 패턴: ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$
=REGEXTEST(A2, "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$")
잘못된 이메일을 강조하기 위해 조건부 서식 사용:
- 홈으로 이동 탭>> 조건부 서식을 선택합니다.>> 새 규칙을 선택합니다.
- 수식을 사용하여 서식을 지정할 셀 결정을 선택합니다.
- 다음 수식을 삽입하세요
- 형식 선택>> 채우기 색상 선택>> 확인 클릭
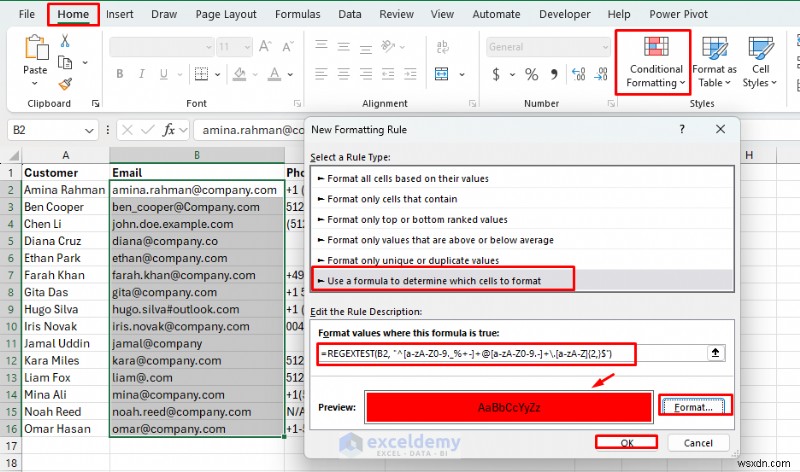
- 잘못된 이메일 주소는 빨간색으로 강조표시됩니다.
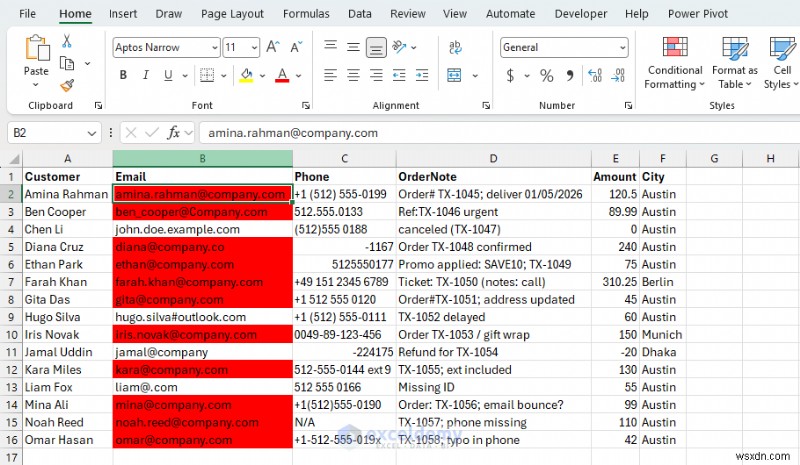
REGEXTEST를 사용하여 유효한 회사 이메일에 플래그를 지정할 수도 있습니다.
=REGEXTEST(B2,"@company\.com$",1)
- 세 번째 인수(1 ) 대소문자를 구분하지 않으므로 Company.com 여전히 통과
- \. 점을 벗어납니다. 평범한 . "모든 문자"를 의미합니다
예 2:지저분한 메모에서 데이터 추출
메모에 주문 ID나 전화번호 등의 데이터가 혼합되어 있다고 가정해 보겠습니다. REGEXEXTRACT 함수를 사용하여 전화번호나 주문 ID를 추출할 수 있습니다.
주문 ID 추출:
=REGEXEXTRACT(D2,"TX-\d{4}")
- 일부 행에 없으면 IFERROR로 래핑하세요.
=IFERROR(REGEXEXTRACT(D2,"TX-\d{4}"),"")
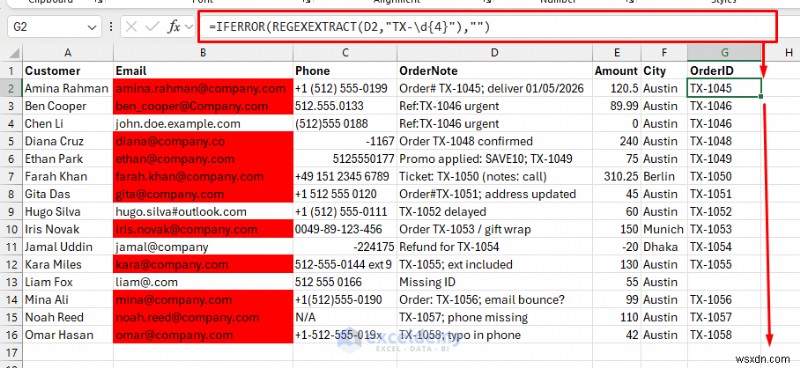
전화번호 추출:
- 데이터: “123-456-7890 또는 (987) 654-3210으로 전화주세요.”
- 패턴: (\d{3}[-. )]+){2}\d{4}
=REGEXEXTRACT(A2, "(\d{3}[-. )]+){2}\d{4}", 0, 1)
이 수식은 텍스트에서 전화번호를 추출합니다.
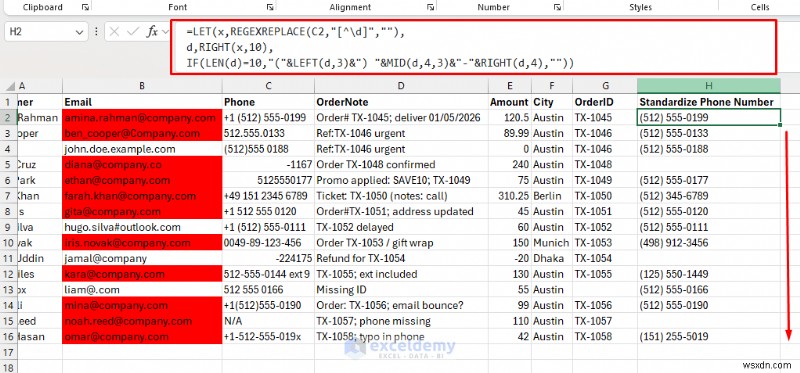
예 3:숫자가 아닌 숫자를 제거하여 전화번호 표준화
- 먼저 숫자 전용 버전을 만드세요.
=REGEXREPLACE(C2,"[^\d]","")
- 이제 형식을 지정할 수 있습니다(예:사용 가능한 경우 마지막 10자리를 미국 번호로 사용).
=LET(x,REGEXREPLACE(C2,"[^\d]",""),
d,RIGHT(x,10),
IF(LEN(d)=10,"("&LEFT(d,3)&") "&MID(d,4,3)&"-"&RIGHT(d,4),""))
이 접근 방식은 숫자가 아닌 문자를 모두 제거하고 결과 전화번호의 형식을 지정합니다.
예 4:날짜 구문 분석 및 형식 재지정
날짜를 구문 분석하고 정규식을 사용하여 형식을 다시 지정할 수 있습니다.
- 패턴: (\d{1,2})/(\d{1,2})/(\d{4})
=REGEXREPLACE(A2, "(\d{1,2})/(\d{1,2})/(\d{4})", "$3-$2-$1")
이 수식은 날짜를 구문 분석한 다음 유효한 ISO와 유사한 형식으로 다시 포맷합니다. 또한 캡처 그룹()을 사용하여 교체 부품을 참조할 수도 있습니다.
예 5:지저분한 데이터 정리(예:추가 공백 제거)
정규식을 사용하면 불필요한 공백을 제거하고 서식을 정규화하는 등 지저분한 데이터를 정리할 수 있습니다.
추가 공백을 제거하려면 다음 패턴을 사용하세요.
- 패턴: \s+
=REGEXREPLACE(A2, "\s+", " ")
이 공식은 공백을 단일 공백으로 대체합니다.
예 6:괄호 안의 내용 제거(괄호 포함)
- 셀을 선택하고 다음 수식을 삽입하세요.
=REGEXREPLACE(D2,"\s*\(.*?\)","")
- .*? 탐욕스럽지 않습니다 일치합니다. 마지막 닫는 괄호 대신 첫 번째 닫는 괄호에서 중지됩니다.
이 수식은 괄호 자체를 포함하여 괄호 안의 모든 데이터를 제거합니다.
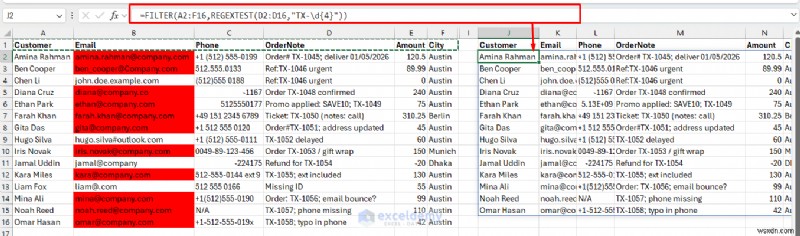
예 7:주문 ID가 포함된 행 필터링
=FILTER(A2:F16,REGEXTEST(D2:D16,"TX-\d{4}"))
이 수식은 정규식 패턴을 기반으로 데이터를 필터링합니다.
Excel의 고급 정규식 기술
- 미리보기/뒤돌아보기: 텍스트를 소비하지 않고 조건을 주장합니다.
- 긍정적 예측:(?=…) 예:% 기호 앞의 숫자에 대해 \d+(?=%)$.
- REGEXEXTRACT에서 가격 추출에 사용:\d+\.\d{2}(?=\sUSD)
- 비캡처 그룹: (?:…) 캡처 없이 그룹화하는 경우
- 교체: 옵션의 경우, 예를 들어 URL의 경우 (http|https)://\S+입니다.
- 배열 처리: REGEXEXTRACT가 여러 그룹을 반환하는 경우 INDEX 또는 분산 범위를 사용하세요.
- 다른 기능과 결합: 강력한 워크플로우를 위해 IF, FILTER 또는 LAMBDA를 중첩하세요.
팁 및 모범 사례
- 테스트 패턴: "ECMAScript" 버전(Excel의 정규식과 가장 유사)을 갖춘 regex101.com과 같은 온라인 도구를 사용하세요.
- 성능: 대규모 데이터 세트에서는 Regex가 느려질 수 있습니다. 먼저 샘플을 테스트해 보세요.
- 오류: 일치하는 항목이 없으면 REGEXEXTRACT는 #N/A를 반환합니다. IFNA 또는 IFERROR로 처리하세요.
- 제한사항: Excel의 정규식은 완전한 PCRE 지원 없이 하위 집합을 기반으로 하므로 재귀와 같은 고급 기능을 사용하지 마세요.
- 자세히 알아보기: 실제 데이터 세트로 연습해 보세요. 정규 표현식을 사용하면 더욱 쉬워집니다!
연습 문제집 다운로드
마무리
Excel 고급 사용자는 정규식 충돌 과정을 따라 데이터 정리, 검증 및 자동화를 가속화할 수 있습니다. 기본 빌딩 블록에 익숙해지면 보다 정교한 패턴 일치를 위해 미리보기와 뒤돌아보기를 탐색하세요. 이 집중 강좌를 통해 시작해보세요. 먼저 표현식을 이해한 다음 빈 통합 문서에서 패턴을 실험해 보세요. Regex는 Excel에서 텍스트를 처리하는 방법을 변화시킬 수 있습니다!
솔루션이 포함된 무료 고급 Excel 연습을 받아보세요!