
Excel의 Python은 Excel 셀 내에서 직접 Python 코드를 작성하고 실행할 수 있는 강력한 Microsoft 365 기능입니다. Python 분석의 강력한 기능을 Excel에 적용합니다. Python을 셀에 직접 입력하면 Python 계산이 Microsoft Cloud에서 실행되고 결과가 워크시트에 반환됩니다. 스프레드시트를 종료하거나 로컬에 아무것도 설치하지 않고도 데이터 분석, 정리, 통계 및 시각화를 위한 Python의 풍부한 생태계와 Excel의 친숙한 인터페이스 및 재계산을 결합할 수 있습니다.
이 튜토리얼에서는 Excel에서 Python을 사용하는 방법과 Python이 언제 어떻게 유용한지 보여줍니다. Jupyter나 VS Code와 같은 다른 도구로 전환하는 대신 Excel에서 Python을 직접 사용할 수 있습니다.
요구사항 및 가용성
- Microsoft 365 구독: 다양한 유료 요금제(소비자 가족/개인, 상업, 교육, 기업)에서 사용할 수 있습니다. 일부 기능 이상의 컴퓨팅에는 추가 기능이 필요할 수 있습니다.
- 플랫폼: 주로 Windows 데스크톱 Excel에서 사용할 수 있습니다. 지원은 웹, Mac, 모바일에 따라 다릅니다. iPad용 Excel, iPhone용 Excel 또는 Android용 Excel에서는 사용할 수 없습니다.
- 로컬 Python이 필요하지 않음: 모든 것이 사전 설치된 라이브러리를 통해 클라우드에서 실행됩니다. Excel에서 Python을 사용하기 위해 로컬 버전의 Python이 필요하지 않습니다. 컴퓨터에 로컬 버전의 Python이 설치되어 있는 경우 해당 설치에 대한 사용자 지정 내용은 Excel 계산의 Python에 반영되지 않습니다.
중요: Excel에서 Python을 사용하려면 인터넷 연결이 필요합니다. 이는 Excel의 Python 계산이 Python 언어의 표준 버전을 사용하여 Microsoft Cloud에서 실행되기 때문입니다.
Excel에서 Python 사용 시작하기
셀에서 Python 활성화:
- 셀 선택
- 수식으로 이동 탭>> Python 삽입을 선택합니다.
- 또는 =PY를 입력하세요. 셀에서 Tab을 누릅니다.
- 수식 입력줄이 녹색으로 바뀌어 Python 모드를 나타냅니다.
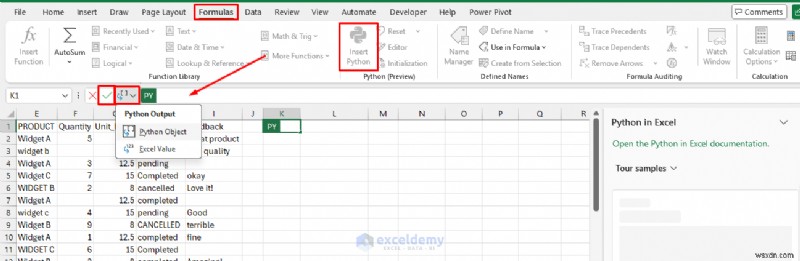
xl() 함수:Excel과 Python 연결
Excel에서 Python을 사용하는 데 있어 핵심은 Python 코드가 스프레드시트에서 직접 데이터를 읽을 수 있게 해주는 xl() 함수입니다.
- 수정 모드에서 클릭하고 드래그하여 셀이나 범위(예:A1:D100)를 선택합니다.
- Excel은 xl(“A1:D100”) 또는 이와 유사한 참조를 삽입합니다.
# 범위를 팬더 DataFrame으로 참조
df =xl(“A1:D100”, headers=True)
# 단일 셀 값 참조
대상 =xl(“F1”)
이것이 Python이 스프레드시트 데이터를 "보는" 방법입니다. 이것을 =PY() 셀 안에 작성하고 결과를 일반 Python 객체로 사용합니다.
출력 옵션:
- 수식 입력줄의 드롭다운을 사용하여 Excel 값으로 반환 (기본 Excel 셀/테이블로 변환) 또는 Python 개체로 유지 (다른 Python 셀 연결용)
- Ctrl + Alt + Shift + M 누르기 출력 유형을 전환하려면
- 어떤 경우에는 디버깅이나 출력을 위해 print()를 사용하세요
재계산: Python 셀은 입력이 변경되면 다른 수식과 마찬가지로 자동으로 다시 계산됩니다(자동 모드에서).
도움말: 작게 시작하십시오. 데이터를 선택하고 Python을 삽입하고 이를 DataFrame으로 변환한 다음 .head(), .describe() 또는 간단한 작업을 사용하여 탐색하세요.
Excel의 Python이 유용한 경우
1. 고급 데이터 정리 및 변환
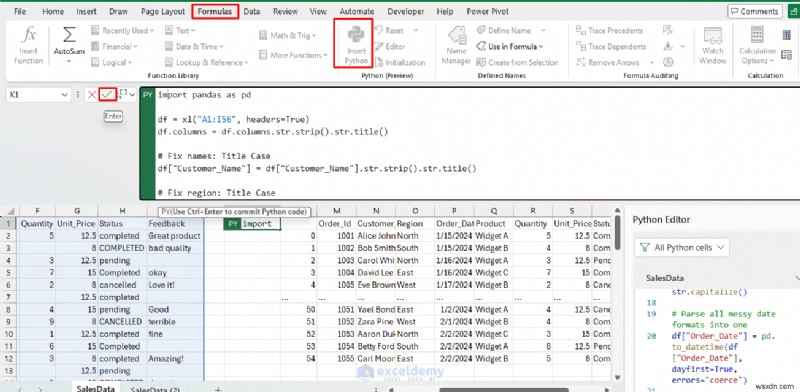
Python은 지저분한 날짜를 쉽게 수정하고, 텍스트(대문자 사용, 공백)를 표준화하고, Null 및 중복을 처리하고, 넓은 데이터를 긴 형식으로 피벗 해제하고, 일관되지 않은 형식이나 누락된 값을 관리할 수 있습니다. Pandas는 이러한 작업을 간결하고 재현 가능하게 만듭니다.
파이썬:
import pandas as pd
df = xl("A1:I56", headers=True)
df.columns = df.columns.str.strip().str.title()
# Fix names: Title Case
df["Customer_Name"] = df["Customer_Name"].str.strip().str.title()
# Fix region: Title Case
df["Region"] = df["Region"].str.strip().str.title()
# Standardize product: Title Case
df["Product"] = df["Product"].str.strip().str.title()
# Standardize status and feedback
df["Status"] = df["Status"].str.strip().str.capitalize()
df["Feedback"] = df["Feedback"].str.strip().str.capitalize()
# Parse all messy date formats into one
df["Order_Date"] = pd.to_datetime(df["Order_Date"], dayfirst=True, errors="coerce")
# Fill missing quantity with median
df["Quantity"] = pd.to_numeric(df["Quantity"], errors="coerce")
df["Quantity"] = df["Quantity"].fillna(df["Quantity"].median())
df
- 체크 표시를 클릭하세요. 또는 Ctrl+Enter를 누르세요. 코드를 실행하려면
- 출력 셀에서 카드 아이콘을 클릭하고>> 배열 미리보기를 선택합니다.
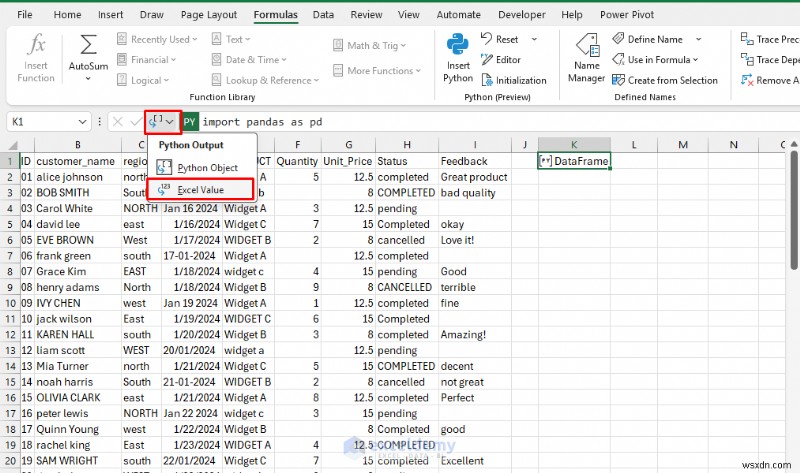
정리된 DataFrame은 자동으로 시트에 다시 쏟아집니다. 추가 분석 및 계산을 위해 깨끗한 데이터를 사용하려면 결과를 Excel 값으로 반환합니다.
- 수식 입력줄에서 드롭다운을 확장합니다.>> Excel 값을 선택합니다.
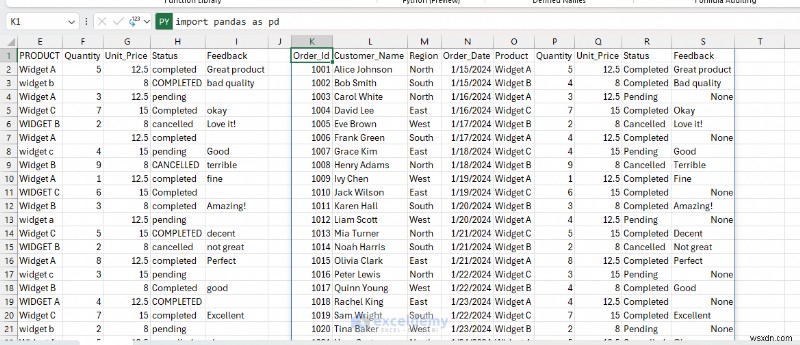
- 이제 다른 예에서 새로 정리된 데이터를 사용하세요
2. 복잡한 데이터 분석 및 통계
Python을 사용하면 복잡한 그룹화, 다단계 변환, 통계 요약 등 Excel에 내장된 기능 이상의 작업을 수행할 수 있습니다. 또한 시계열 분석, 회귀, 클러스터링, 이상치 감지, 텍스트에 대한 감정 분석 및 몬테카를로 시뮬레이션을 지원합니다.
파이썬:
import pandas as pd
# Load data from the SalesData sheet
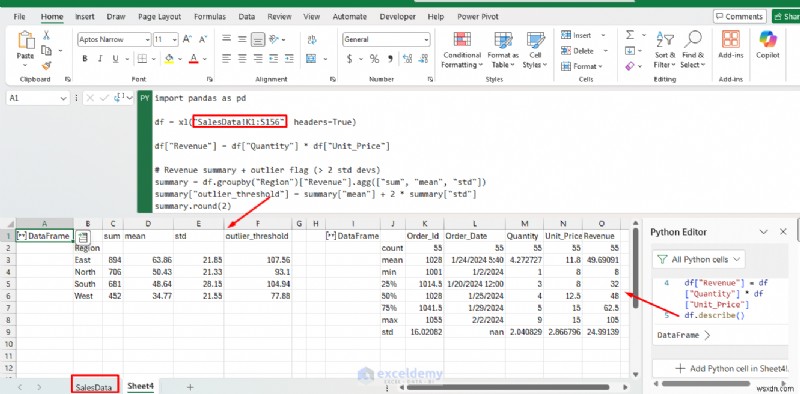
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
# Revenue summary + outlier flag (> 2 std devs)
summary = df.groupby("Region")["Revenue"].agg(["sum", "mean", "std"])
summary["outlier_threshold"] = summary["mean"] + 2 * summary["std"]
summary.round(2)
결과는 테이블로 시트에 직접 다시 쏟아집니다. df.describe()를 사용할 수도 있습니다. 전체 DataFrame에 대한 요약 통계를 표시합니다.
파이썬:
import pandas as pd
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
df.describe()
3. 더 나은 차트 및 시각화
Matplotlib, Seaborn 또는 Plotnine을 사용하면 밀도 플롯, 군집 플롯, 단어 구름 또는 작은 배수와 같은 전문적인 플롯을 쉽게 생성할 수 있습니다. 이는 Excel 차트보다 훨씬 더 유연합니다. matplotlib 및 seaborn을 사용하여 Excel의 기본 차트를 뛰어넘으세요.
파이썬:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
fig, ax = plt.subplots(figsize=(8, 4))
sns.boxplot(data=df, x="Region", y="Revenue", palette="Set2", ax=ax)
ax.set_title("Revenue Distribution by Region")
ax.set_xlabel("Region")
ax.set_ylabel("Revenue ($)")
fig
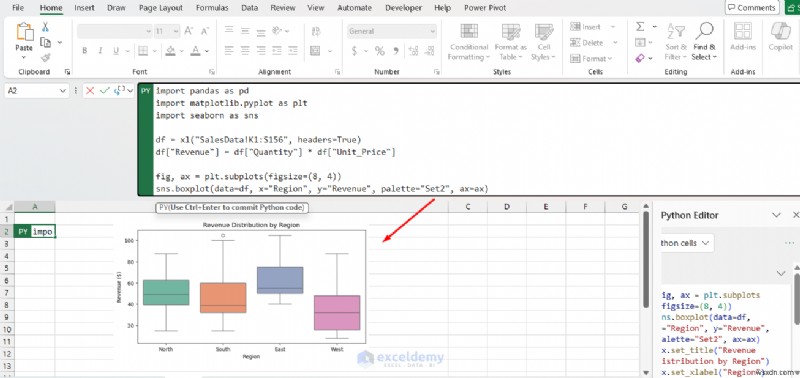
차트는 워크시트에서 직접 이미지 개체로 렌더링되며 Excel 차트처럼 크기 조정 및 위치 변경이 가능합니다.
4. 스프레드시트 데이터에 대한 기계 학습
Python은 예측 모델링 및 예측을 가능하게 합니다. Excel 데이터에서 직접 통계 모델이나 scikit-learn을 사용하여 보다 정확한 예측이나 간단한 기계 학습 모델을 구축할 수 있습니다.
Excel을 종료하지 않고 예측 모델 실행:
파이썬:
import pandas as pd
from sklearn.linear_model import LinearRegression
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
# Convert to numeric and fill missing values with median
df["Quantity"] = pd.to_numeric(df["Quantity"], errors="coerce")
df["Unit_Price"] = pd.to_numeric(df["Unit_Price"], errors="coerce")
df["Quantity"] = df["Quantity"].fillna(df["Quantity"].median())
df["Unit_Price"] = df["Unit_Price"].fillna(df["Unit_Price"].median())
# Calculate Revenue
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
# One-hot encode Product
X = pd.get_dummies(df[["Product", "Unit_Price"]], drop_first=True)
y = df["Revenue"]
# Fit the Linear Regression model
model = LinearRegression().fit(X, y)
# Add predictions
df["Predicted_Revenue"] = model.predict(X).round(2)
# Create final result with useful columns
result = df[["Order_Id", "Product", "Revenue", "Predicted_Revenue"]].copy()
result["Difference"] = (result["Revenue"] - result["Predicted_Revenue"]).round(2)
# Optional: Show model performance
print("Model R² Score:", round(model.score(X, y), 4))
result
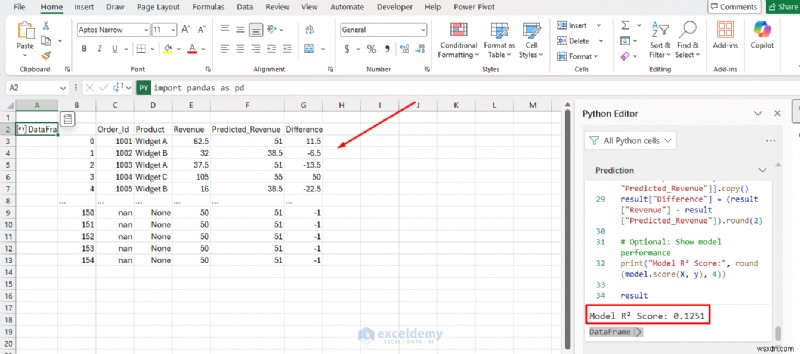
비즈니스 분석가는 별도의 환경으로 전환하지 않고도 기존 데이터에 머신러닝 모델을 적용할 수 있습니다.
5. 롤링 계산 및 시계열
이동 평균, 누적 합계 또는 시차 특성을 계산하는 것은 Excel 수식만으로는 어렵습니다. Python은 이러한 작업을 단순화합니다.
파이썬:
import pandas as pd
# Load your full sales data
df = xl("SalesData!K1:S156", headers=True)
# Calculate Daily Revenue
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
# Rolling Calculations (Time Series)
# Sort by date first (important for time series)
df = df.sort_values("Order_Date").reset_index(drop=True)
# 7-day Rolling Metrics on Revenue (weekly trend)
df["Revenue_7d_Mean"] = df["Revenue"].rolling(window=7, min_periods=1).mean().round(2)
df["Revenue_7d_Sum"] = df["Revenue"].rolling(window=7, min_periods=1).sum().round(2)
df["Revenue_7d_Max"] = df["Revenue"].rolling(window=7, min_periods=1).max().round(2)
df["Revenue_7d_Std"] = df["Revenue"].rolling(window=7, min_periods=1).std().round(2)
# 30-day Rolling Mean (monthly trend)
df["Revenue_30d_Mean"] = df["Revenue"].rolling(window=30, min_periods=1).mean().round(2)
# Cumulative Revenue (running total)
df["Cumulative_Revenue"] = df["Revenue"].cumsum().round(2)
# Select columns to display
result = df[["Order_Id", "Order_Date", "Product", "Revenue",
"Revenue_7d_Mean", "Revenue_7d_Sum", "Revenue_30d_Mean",
"Cumulative_Revenue"]]
result
이 접근 방식은 판매 추세를 분석하고 일일 또는 주간 변동을 완화하고 이상 현상을 감지하고 모멘텀을 예측하는 데 유용합니다.
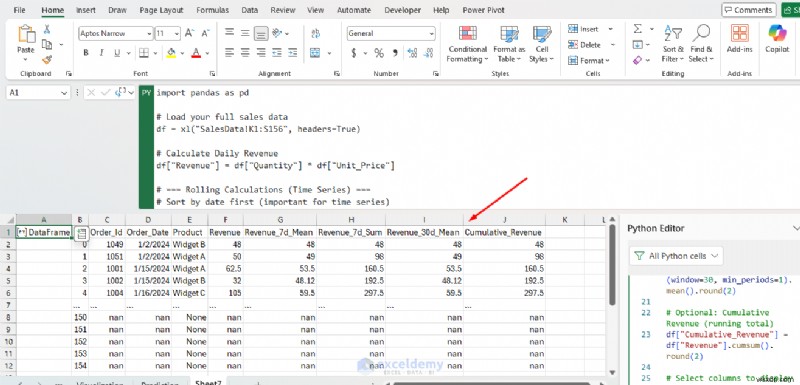
- 수익_7일_평균: 7일 이동 평균(주간 판매 추세를 완화)
- Revenue_7d_Sum: 지난 7일 동안의 총 수익
- 수익_30일_평균: 30일 이동 평균(장기 추세)
- 누적_수익: 해당 날짜까지의 모든 수익 누계
팁 및 모범 사례
- 사슬 세포: 이전 Python 개체(변수로 표시됨)를 참조하여 단일 셀을 복잡하게 하지 않고 다단계 워크플로를 구축하세요.
- 성능: 계산량이 많은 경우 클라우드 할당량에 유의하세요. 대규모 작업을 여러 단계로 나누거나 필요한 경우 프리미엄 컴퓨팅을 사용하세요.
- 보안: 코드는 격리된 클라우드 컨테이너에서 실행됩니다. 민감한 작업을 피하세요. Microsoft는 개인정보를 관리합니다
- 디버깅: print()를 사용하거나 DataFrame을 단계별로 출력하세요. 셀에 오류가 나타납니다
- Excel과 결합: 무거운 작업에는 Python을 사용하고 형식 지정, 피벗 또는 대시보드에는 Excel을 사용합니다.
- 학습 곡선: Python을 처음 사용하는 경우 먼저 팬더에 집중하세요. 다양한 무료 튜토리얼과 샘플 파일을 사용할 수 있습니다
- 공유: 호환되는 Microsoft 365를 사용하는 수신자는 결과를 보거나 새로 고칠 수 있습니다. 그렇지 않으면 결과가 정적 값으로 변환됩니다.
알아야 할 제한 사항
- 클라우드 전용 실행; 인터넷 연결이 필요합니다
- 표준 요금제의 계산 할당량
- Python 환경은 Anaconda로 관리됩니다. 자체 패키지를 설치하거나 로컬 사용자 정의를 사용할 수 없습니다.
- 모바일 및 웹 지원은 데스크톱에 비해 제한적입니다.
- 매우 큰 데이터 세트 또는 장기 실행 코드는 시간 초과에 도달할 수 있습니다.
결론
Excel의 Python은 작업이 기본적으로 스프레드시트 기반이지만 분석 자체가 더욱 발전할 때 가장 유용합니다. 데이터 정리, DataFrame 스타일 분석, 고급 통계 및 시각화에 탁월합니다. Excel이 이미 잘 처리하고 있는 일상적인 스프레드시트 작업에는 덜 유용합니다. Excel의 Python은 스프레드시트 사용자와 데이터 과학자 사이의 격차를 해소하여 익숙한 워크플로를 방해하지 않고 고급 분석에 액세스할 수 있도록 해줍니다. Excel을 Python으로 대체하는 대신 분석이 수식만으로는 너무 복잡해지면 선택적으로 Python을 사용하세요.
솔루션이 포함된 무료 고급 Excel 연습을 받아보세요!