
Excel은 데이터 분석을 위한 가장 강력한 도구 중 하나이지만 한계가 있습니다. 데이터 세트가 수백만 행으로 늘어나거나, 보고서를 자동으로 실행해야 하거나, 분석에 기계 학습이 필요한 경우 Excel만으로도 수명이 표시되기 시작합니다. Python은 이러한 격차를 많이 해소합니다. Python 통합을 통해 Excel은 기존 스프레드시트 도구에서 더욱 강력한 데이터 분석 플랫폼으로 변모되었습니다. Excel 내에서 직접 Python을 사용할 수 있으므로 분석가는 이제 통합 문서를 떠나지 않고도 고급 계산을 수행하고, 예측 모델을 구축하고, 정교한 시각화를 생성할 수 있습니다.
이 튜토리얼에서는 모든 전문가가 사용해야 하는 고급 Excel 데이터 분석을 위한 5개의 Python 라이브러리를 보여줍니다. 이러한 라이브러리를 사용하면 Excel 내에서 직접 고급 데이터 조작, 시각화 및 기계 학습을 수행할 수 있습니다.
1. Pandas - 데이터 조작 및 분석의 핵심
엑셀 분석을 위한 Python 라이브러리 하나만 배운다면 Pandas를 배워보세요 먼저. Pandas는 Python의 거의 모든 고급 Excel 관련 작업의 기반입니다. Excel 데이터를 강력한 DataFrames로 변환합니다. 대규모 데이터 세트를 효율적으로 정리, 변환, 필터링, 그룹화, 병합, 집계 및 탐색하는 데 사용됩니다.
Excel 전문가의 주요 강점:
- pd.read_excel()을 사용하여 기본적으로 Excel 파일을 읽고 씁니다. 및 df.to_excel()
- 복잡한 데이터 처리:중복 제거, 누락된 값 채우기, 형식 표준화
- 피벗 테이블 이상의 논리로 고급 그룹화 및 집계 수행
- 여러 시트 또는 파일 병합 또는 결합
- df.describe()를 사용하여 통계 요약을 생성합니다.
- 몇 줄의 코드를 실행하면 매번 동일한 결과를 얻습니다.
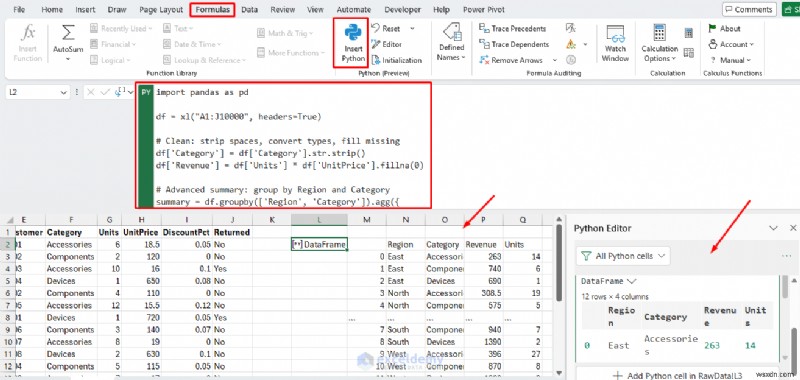
예:지저분한 데이터 정리
Excel에서 흔히 발생하는 골치 아픈 문제는 유형이 혼합되어 있고 값이 누락되었으며 형식이 일관되지 않은 데이터를 수신하는 것입니다. Pandas를 사용하면 반복 가능한 하나의 스크립트로 모든 것을 수정할 수 있습니다.
Excel의 Python:
import pandas as pd
df = xl("A1:J10000", headers=True)
# Clean: strip spaces, convert types, fill missing
df['Category'] = df['Category'].str.strip()
df['Revenue'] = df['Units'] * df['UnitPrice'].fillna(0)
# Advanced summary: group by Region and Category
summary = df.groupby(['Region', 'Category']).agg({
'Revenue': 'sum',
'Units': 'sum'
}).reset_index()
summary
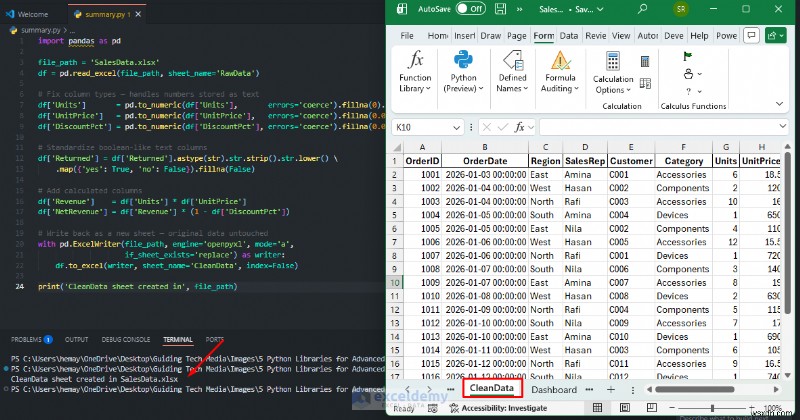
VS Code의 Python:
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='RawData')
# Fix column types — handles numbers stored as text
df['Units'] = pd.to_numeric(df['Units'], errors='coerce').fillna(0).astype(int)
df['UnitPrice'] = pd.to_numeric(df['UnitPrice'], errors='coerce').fillna(0.0)
df['DiscountPct'] = pd.to_numeric(df['DiscountPct'], errors='coerce').fillna(0.0)
# Standardize boolean-like text columns
df['Returned'] = df['Returned'].astype(str).str.strip().str.lower() \
.map({'yes': True, 'no': False}).fillna(False)
# Add calculated columns
df['Revenue'] = df['Units'] * df['UnitPrice']
df['NetRevenue'] = df['Revenue'] * (1 - df['DiscountPct'])
# Write back as a new sheet — original data untouched
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
df.to_excel(writer, sheet_name='CleanData', index=False)
print('CleanData sheet created in', file_path)
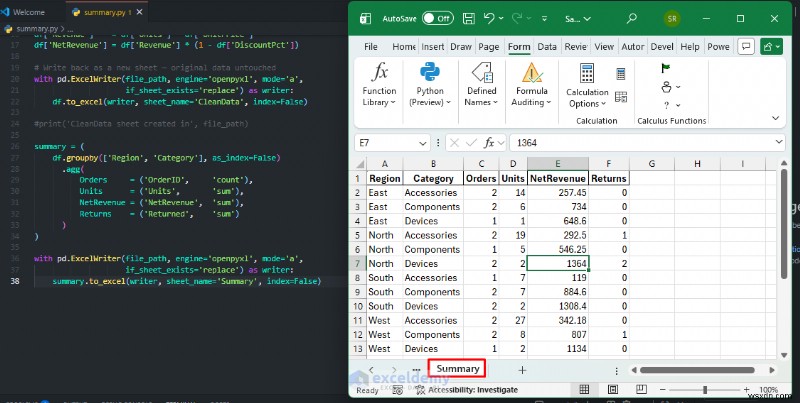
요약 보고서 자동화
수동 피벗 테이블을 Pandas groupby로 교체 몇 초 안에 실행되며 데이터가 업데이트될 때마다 공유 가능한 시트를 내보내는 워크플로:
summary = (
df.groupby(['Region', 'Category'], as_index=False)
.agg(
Orders = ('OrderID', 'count'),
Units = ('Units', 'sum'),
NetRevenue = ('NetRevenue', 'sum'),
Returns = ('Returned', 'sum')
)
)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
summary.to_excel(writer, sheet_name='Summary', index=False)
사용 시기: 피벗 테이블 스타일의 출력을 얻지만 정리와 논리는 동일한 워크플로에서 발생합니다. 즉, 깨진 보고서가 줄어들고 수동 개입이 줄어듭니다. 고급 사용자는 Pandas를 사용하여 기본 Excel에 비해 너무 크거나 복잡한 데이터 세트를 처리합니다. 특히 데이터 세트가 수천 행을 초과하는 경우, 정리 또는 요약 단계를 반복해야 하는 경우 또는 여러 소스의 데이터를 자동으로 병합해야 하는 경우에 그렇습니다.
2. OpenPyXL – 고급 Excel 파일 조작 및 기본 형식 지정
Pandas가 데이터를 처리하는 동안 OpenPyXL .xlsx에 대한 세밀한 제어에 탁월합니다. 파일:Excel 기본 기능을 그대로 유지하면서 셀 서식을 지정하고 차트, 표, 스타일, 수식 및 이미지를 추가합니다. .xlsx로 직접 작업할 수 있습니다. 파일을 생성하므로 Python 워크플로는 원시 분석만 수행하는 대신 Excel에서 바로 사용할 수 있는 출력을 생성할 수 있습니다.
Excel 전문가의 주요 강점:
- 프로그래밍 방식으로 통합 문서 생성 및 수정
- 정리된 표를 새 시트로 내보내기
- 자동으로 업데이트되는 전문 차트를 Excel 형식으로 직접 추가
- 이전 보고서 탭을 자동으로 교체
- 특정 셀에 조건부 서식, 테두리, 글꼴, 스타일 적용
- =SUM()과 같은 Excel 수식 삽입 또는 =VLOOKUP() 셀에
- 프로그래밍 방식으로 시트 보호, 창 고정, 열 너비 설정
- Python을 사용하지 않는 사용자를 위한 통합 문서 기반 결과물 구축
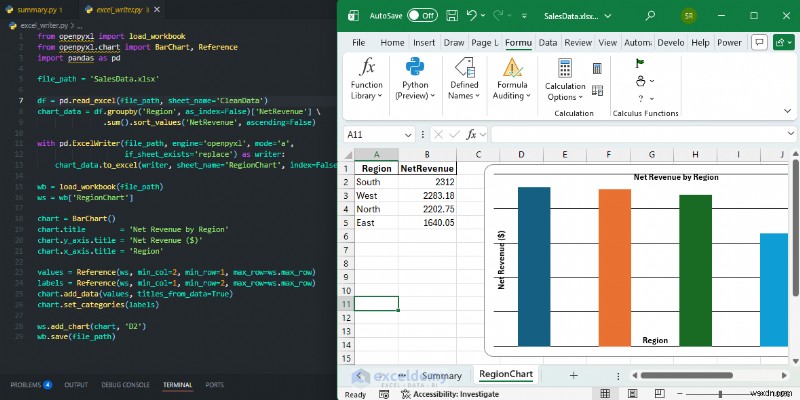
예:통합 문서에 기본 차트 추가
Pandas로 깨끗한 데이터를 생성한 후 Excel을 수동으로 열지 않고도 openpyxl을 사용하여 전문적인 막대 차트를 추가할 수 있습니다.
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='CleanData')
chart_data = df.groupby('Region', as_index=False)['NetRevenue'] \
.sum().sort_values('NetRevenue', ascending=False)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
chart_data.to_excel(writer, sheet_name='RegionChart', index=False)
wb = load_workbook(file_path)
ws = wb['RegionChart']
chart = BarChart()
chart.title = 'Net Revenue by Region'
chart.y_axis.title = 'Net Revenue ($)'
chart.x_axis.title = 'Region'
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, 'D2')
wb.save(file_path)
사용 시기: Pandas는 데이터 분석을 도와줍니다. openpyxl은 이를 제공하는 데 도움이 됩니다. 손으로 만든 것처럼 보이는 보고서 및 대시보드와 같이 픽셀 단위까지 완벽한 Excel 출력이 필요하고 결과가 .xlsx에 있어야 하는 경우 OpenPyXL을 사용하세요. 동료가 계속 편집할 수 있는 기본 Excel 차트와 서식이 포함된 파일입니다.
3. Matplotlib – Excel 차트를 뛰어넘는 강력한 시각화
Excel 차트는 편리하지만 Matplotlib 분석가에게 훨씬 더 많은 제어권을 제공합니다. Matplotlib는 정적인 출판 품질 플롯을 생성하기 위한 라이브러리입니다. 이는 사용자 정의가 가능하며 빠른 탐색 분석을 위해 Pandas와 잘 통합됩니다.
Excel 전문가의 주요 장점:
- 히트맵, 추세선이 포함된 산점도, 상자 그림, 히스토그램, 3D 차트와 같은 고급 그림 만들기
- 글꼴, 색상, 격자선, 눈금 표시 및 범례를 더 효과적으로 제어할 수 있습니다.
- 한 번에 여러 차트를 표시하는 다중 패널 하위 플롯 레이아웃 구축
- 이미지, PDF 또는 SVG로 내보내거나 OpenPyXL을 사용하여 Excel에 시각적 요소를 다시 삽입하세요.
- 맞춤 라벨과 화살표로 데이터 포인트에 주석 달기
예:다중 패널 판매 대시보드 만들기
왼쪽에 월별 수익 추세가 있고 오른쪽에 카테고리 분석이 있는 2패널 차트를 만들어 보겠습니다. 그런 다음 어떤 보고서에도 사용할 수 있도록 고해상도 이미지로 저장하겠습니다.
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
df['Month'] = pd.to_datetime(df['OrderDate']).dt.to_period('M')
monthly = df.groupby('Month')['NetRevenue'].sum()
cat_rev = df.groupby('Category')['NetRevenue'].sum().sort_values(ascending=True)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
fig.suptitle('Sales Performance Dashboard', fontsize=16, fontweight='bold')
# Left panel — monthly revenue line chart
ax1.plot(list(monthly.index.astype(str)), monthly.values,
marker='o', color='#1E5FAD', linewidth=2)
ax1.set_title('Monthly Net Revenue')
ax1.set_xlabel('Month')
ax1.set_ylabel('Revenue ($)')
ax1.yaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
ax1.tick_params(axis='x', rotation=45)
ax1.grid(axis='y', linestyle='--', alpha=0.5)
# Right panel — revenue by category horizontal bar chart
ax2.barh(cat_rev.index, cat_rev.values, color='#217346')
ax2.set_title('Revenue by Category')
ax2.set_xlabel('Revenue ($)')
ax2.xaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
plt.tight_layout()
plt.savefig('sales_dashboard.png', dpi=150, bbox_inches='tight')
print('Dashboard saved as sales_dashboard.png')
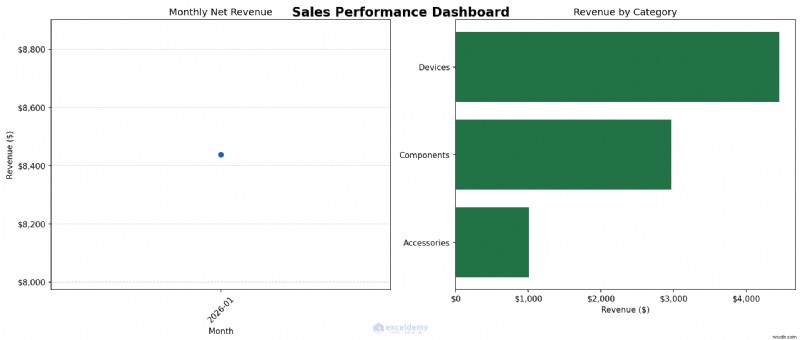
사용 시기: 먼저 Python을 사용하여 분석 차트를 생성합니다. 그런 다음 차트를 Python 출력으로 유지해야 하는지 또는 최종 대시보드 형식화를 위해 요약된 데이터를 Excel로 반환해야 하는지 결정합니다. 보고서나 프리젠테이션을 위한 차트가 필요하거나 일관된 스타일로 업데이트된 데이터에서 동일한 차트를 반복적으로 생성해야 하는 경우 Matplotlib를 사용하세요.
4. Seaborn – 통계 데이터 시각화
시본 Matplotlib을 기반으로 하며 통계 시각화에 중점을 둡니다. 패턴과 상관관계를 강조하는 시각적으로 매력적인 차트 생성을 단순화합니다. Matplotlib에서는 세련된 차트를 위해 수십 줄이 필요할 수 있지만 Seaborn은 종종 매력적인 기본 스타일을 사용하여 한두 줄로 비슷한 결과를 얻을 수 있습니다. 데이터에 숨겨진 분포, 상관관계, 패턴을 찾아내는 데 탁월합니다.
Excel 전문가의 주요 장점:
- 통계 차트를 빠르게 생성
- 탐색적 데이터 분석에 적합
- 상관관계 히트맵을 작성하여 열이 서로 어떻게 연관되어 있는지 확인
- 밀도 곡선이 내장된 분포도 생성
- 상자 그림과 바이올린 그림을 사용하여 그룹을 시각적으로 비교
- 숫자 열 전체에 걸쳐 자동 산점도 행렬을 위한 쌍 도표 생성
- 한 줄에 신뢰 구간이 포함된 회귀 도표 생성
예:상관관계 히트맵 생성
Excel 데이터에서 숨겨진 패턴을 찾으십시오. 어떤 변수가 함께 이동합니까? 히트맵은 이 문제에 신속하게 답할 수 있으며 일반적으로 Excel에 내장된 도구가 제공하는 것 이상을 제공합니다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
correlation = df.select_dtypes(include='number').corr()
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation,
annot=True, # show correlation values in each cell
fmt='.2f',
cmap='coolwarm', # red = positive, blue = negative
center=0,
square=True,
linewidths=0.5
)
plt.title('Correlation Matrix — Sales Variables', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('correlation_heatmap.png', dpi=150)
print('Heatmap saved!')
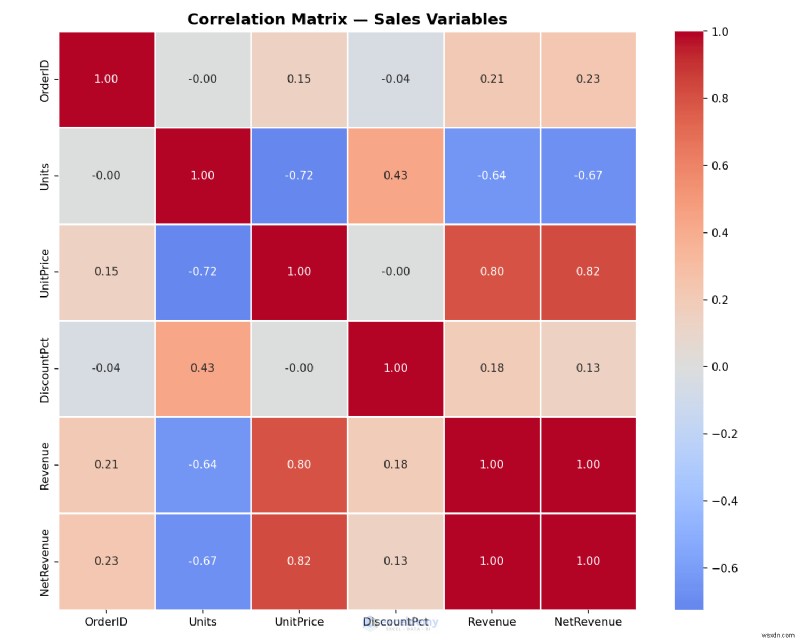
예:한 줄로 상자 그림 만들기
지역별 수익 분포를 비교하여 이상값을 즉시 찾아보세요.
plt.figure(figsize=(10, 6))
sns.boxplot(data=df, x='Region', y='NetRevenue', hue='Region', palette='Set2', legend=False)
plt.title('Revenue Distribution by Region')
plt.ylabel('Net Revenue ($)')
plt.tight_layout()
plt.savefig('region_boxplot.png', dpi=150)
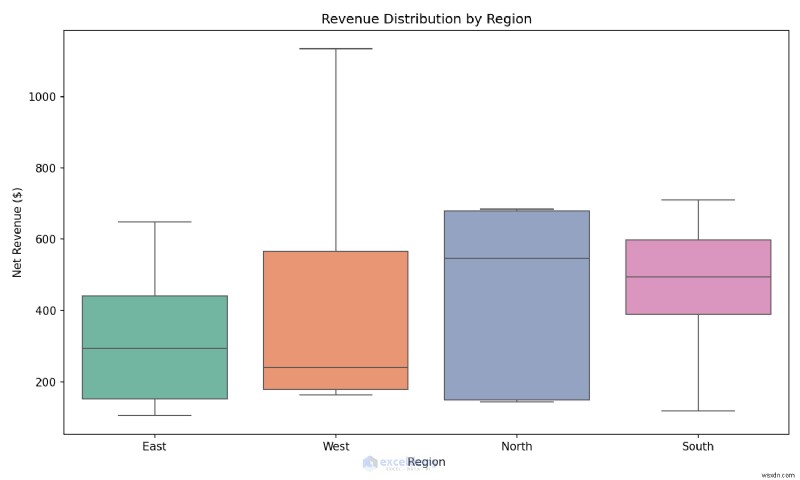
사용 시기: 공식 보고서를 작성하기 전에 분포, 이상값 및 관계를 빠르게 이해하려는 경우 탐색적 분석 중에 Seaborn을 사용하세요.
5. Scikit-learn – Excel 데이터에서 직접 머신러닝
이는 보고에서 의사 결정 지원으로 이동하는 라이브러리입니다. Scikit 학습 Excel 워크플로에 전문적인 기계 학습을 제공합니다. 기본 Excel에서는 쉽게 처리할 수 없는 회귀, 분류, 클러스터링 및 예측을 포함하여 Excel 사용자를 위한 예측 분석이 가능합니다. 데이터에서 발생한 일만 설명하는 것이 아니라 판매 예측부터 고객 분류, 이상 징후 감지에 이르기까지 다음에 일어날 일을 예측하는 데 도움이 됩니다.
Excel 전문가의 주요 강점:
- 이탈 위험이나 판매 예측과 같은 수치적 결과나 범주를 예측하기 위한 선형 및 로지스틱 회귀
- 해석 가능한 예측을 위한 의사결정 트리 및 랜덤 포레스트
- K-유사한 레코드를 자동으로 그룹화하는 클러스터링을 의미함
- 모델 정확도 측정을 위한 학습 테스트 분할 및 교차 검증
- 기능 확장, 인코딩, 전처리 파이프라인
- 필터링 및 정렬을 위해 예측을 Excel로 반환
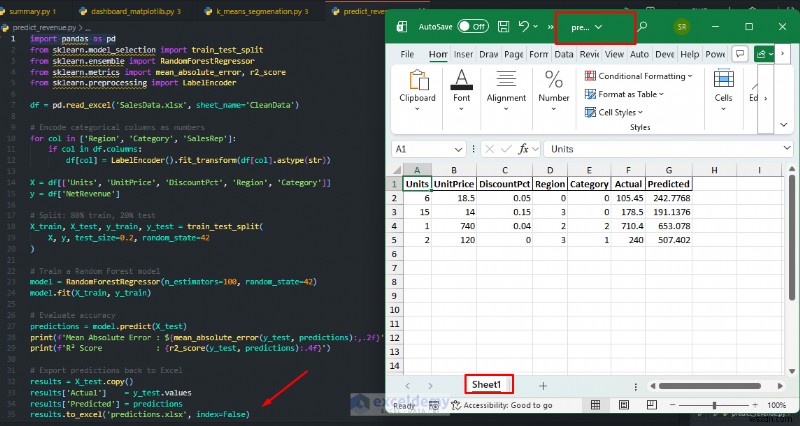
예:순수익 예측
과거 판매 데이터에 대한 모델을 훈련한 다음 이를 사용하여 새로운 주문에 대한 수익을 예측합니다. 이는 Excel에서 기본적으로 수행할 수 없는 분석입니다.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.preprocessing import LabelEncoder
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
# Encode categorical columns as numbers
for col in ['Region', 'Category', 'SalesRep']:
if col in df.columns:
df[col] = LabelEncoder().fit_transform(df[col].astype(str))
X = df[['Units', 'UnitPrice', 'DiscountPct', 'Region', 'Category']]
y = df['NetRevenue']
# Split: 80% train, 20% test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train a Random Forest model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Evaluate accuracy
predictions = model.predict(X_test)
print(f'Mean Absolute Error: ${mean_absolute_error(y_test, predictions):,.2f}')
print(f'R² Score: {r2_score(y_test, predictions):.4f}')
# Export predictions back to Excel
results = X_test.copy()
results['Actual'] = y_test.values
results['Predicted'] = predictions
results.to_excel('predictions.xlsx', index=False)
print('Predictions exported to predictions.xlsx')
K-평균 고객 세분화:
수동 기준 없이 구매 행동에 따라 고객을 그룹으로 자동 분류합니다.
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
customer = df.groupby('Customer').agg(
TotalOrders = ('OrderID', 'count'),
TotalRevenue = ('NetRevenue', 'sum'),
AvgDiscount = ('DiscountPct', 'mean')
).reset_index()
X_scaled = StandardScaler().fit_transform(
customer[['TotalOrders', 'TotalRevenue', 'AvgDiscount']]
)
customer['Segment'] = KMeans(n_clusters=3, random_state=42, n_init=10) \
.fit_predict(X_scaled)
customer.to_excel('customer_segments.xlsx', index=False)
print('Segmentation complete! See customer_segments.xlsx')
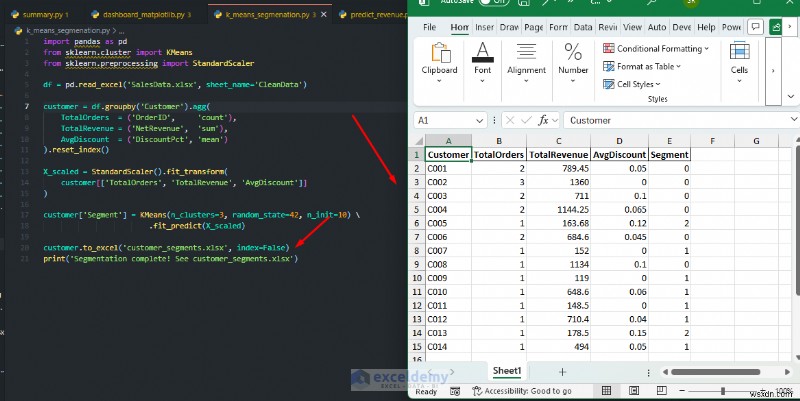
사용 시기: 예측을 워크시트에 다시 작성한 다음 Excel 사용자가 결과를 수식 및 조건부 서식을 사용하여 필터링, 정렬, 차트로 작성하거나 결합하도록 할 수 있습니다. 이를 통해 전문가는 기계 학습 통찰력을 스프레드시트에 직접 추가할 수 있습니다. 미래 가치를 예측하거나, 기록을 분류하거나, 피벗 테이블에서 공개할 수 없는 자연스러운 그룹화를 발견해야 할 때 Scikit-learn을 사용하세요.
보너스:Xlwings – 양방향 자동화 및 실시간 Excel 통합
xlwings 라이브러리는 실시간으로 Excel 인스턴스를 실행합니다. Python과 Excel을 연결하여 진정한 자동화를 가능하게 합니다. openpyxl이 정적 파일을 읽고 쓰는 동안 xlwings는 Excel을 열고, 실시간으로 조작하고, 값을 Python으로 다시 읽고, Excel 버튼에서 Python 함수를 트리거하고, 셀에 나타나는 전체 UDF(사용자 정의 함수)를 구축할 수 있습니다. 이는 많은 VBA 기반 워크플로우에 대한 현대적인 대안입니다.
Excel 전문가의 주요 강점:
- 라이브 Excel 세션 제어:프로그래밍 방식으로 통합 문서 열기, 읽기, 쓰기 및 닫기
- Excel 셀에서 직접 호출할 수 있는 Python 함수를 UDF로 작성
- 데이터 새로 고침, 보고서 생성 등 반복적인 작업 자동화
- Pandas DataFrames 및 Matplotlib 차트를 명명된 범위에 직접 푸시
- Excel 버튼으로 트리거되는 Python 스크립트 실행
- Windows와 macOS 모두에서 작업
- 데스크톱 워크플로용 Excel에서 Python에 대한 강력한 대안 또는 보완 역할을 합니다.
Excel과의 실시간 양방향 상호 작용이 필요할 때, VBA 매크로를 교체할 때, 대화형 대시보드를 구축할 때 또는 기술 지식이 없는 동료가 버튼 클릭으로 Python 분석을 트리거하도록 허용할 때 xlwings를 사용할 수 있습니다.
다양한 Excel 전문가를 위한 최고의 라이브러리 스택 선택
모든 분석가가 한 번에 다섯 개의 라이브러리를 모두 필요로 하는 것은 아닙니다. 이를 채택하는 실용적인 방법은 역할별로 하는 것입니다.
- 보고 분석가의 경우: 이 조합을 사용하면 데이터를 정리하고, 요약을 만들고, 차트를 생성하고, 세련된 통합 문서 출력을 내보낼 수 있습니다.
- 판다
- 매트플롯립
- 오픈pyxl
- 재무 및 운영 분석가용: 이 스택은 모델링, KPI 계산, 할당 및 반복 가능한 월별 보고에 적합합니다.
- 판다
- 시본
- 오픈pyxl
- 고급 분석 팀의 경우: 이 조합은 데이터 준비부터 예측 채점, 통합 문서 제공까지 전체 파이프라인을 제공합니다.
- 판다
- 매트플롯립
- Scikit 학습
- 오픈pyxl
- 시본
최종 생각
모든 전문가가 사용해야 하는 고급 Excel 데이터 분석을 위한 5가지 Python 라이브러리입니다. 이러한 도구를 익히면 Excel을 단순한 스프레드시트 응용 프로그램에서 더욱 유능한 분석 플랫폼으로 전환할 수 있습니다. 합리적인 학습 경로는 Pandas로 시작한 다음 openpyxl을 추가하고 Matplotlib와 Seaborn을 함께 배우고 그 후에 Scikit-learn을 다루는 것입니다. 각 라이브러리는 동일한 .xlsx로 작동합니다. 이미 사용하고 있는 파일입니다. 더욱 유능한 데이터 분석가가 되기 위해 탐구를 시작해 보세요.
솔루션이 포함된 무료 고급 Excel 연습을 받아보세요!