
게시일:2026년 4월 30일 오전 10시 30분(EDT)
Yasir는 MUO에서 Windows, 생산성, 보안 및 인터넷을 다루는 기술에 대해 글을 쓰는 기계 엔지니어입니다. 자율 시스템에 대한 관심으로 인해 그는 하드웨어와 소프트웨어 모두에 끊임없이 관심을 갖고 있습니다.
그의 기술 글쓰기 여정은 엔지니어링 3학년 때 시작되어 MUO에 합류하기 전에 Android Police로 이어졌습니다. 그는 Windows 문제 해결, 생산성 도구 탐색, 일반 영어로 보안 위험 설명 등 기술에 대한 접근성을 높이는 데 중점을 두고 있습니다. Yasir의 경우 이를 수행하는 가장 좋은 방법은 실제로 도구를 사용하여 독자가 직면하는 것과 동일한 문제에 직면하는 것입니다.
Yasir가 글을 쓰거나 엔지니어링 작업을 하지 않을 때 Impractical Jokers를 시청하고 이전에 수십 번 본 장난을 보고 진심으로 웃는 모습을 볼 수 있습니다.
내가 아는 대부분의 Excel 사용자는 나와 같은 방식으로 공식을 배웠습니다. 즉, 이미 알고 있는 내용 위에 한 번에 하나의 함수를 추가하는 것입니다. 동적 배열 기능은 이러한 기술을 대체하지 않습니다. 그들은 많은 해결 방법을 불필요하게 만듭니다. 나는 한동안 TAKE 및 DROP을 사용하여 자체 업데이트되는 상위 5개 목록을 실행해 왔고 아래의 네 가지 기능에서도 동일한 변화가 발생했습니다. 각각은 제가 반사적으로 수행했던 다단계 루틴을 하나의 공식으로 줄였습니다.
 관련
관련
FILTER는 도우미 열과 배열 수식의 전체 의식을 대체했습니다.
이제 하나의 공식이 여러 함수를 분할하는 데 사용되는 작업을 수행합니다.
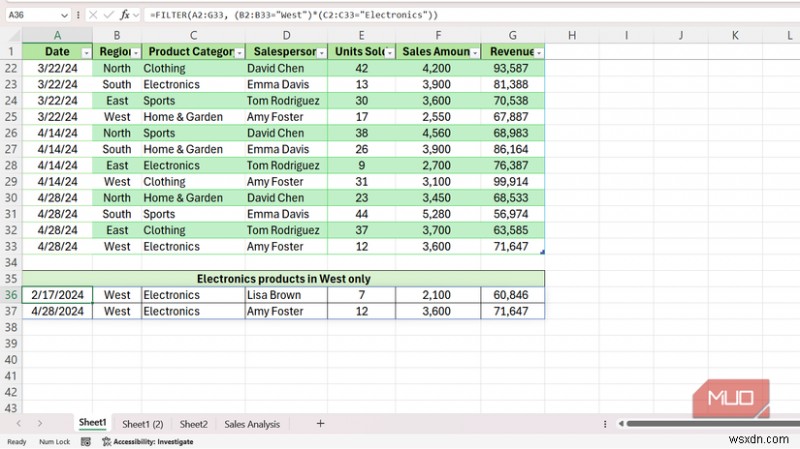
이전 Excel에서 일치하는 행을 가져오는 것은 중첩된 INDEX, MATCH, SMALL 및 IFERROR 수식을 작성하고 Ctrl + Shift + Enter를 사용하여 입력하는 것을 의미했습니다. 효과가 있었지만 나중에 유지하는 것이 문제였습니다. 다른 옵션은 자동 필터를 적용하고 표시되는 행을 복사하여 다른 곳에 정적 값으로 붙여넣는 것입니다. 소스 데이터가 변경되기 전까지는 괜찮았습니다.
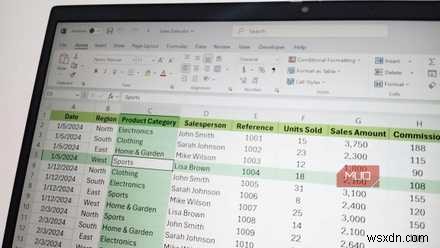
FILTER 함수는 한 줄에서 동일한 작업을 수행합니다. 지역, 제품 범주, 영업사원에 걸쳐 32개의 행이 있는 내 영업 스프레드시트에서 서부 지역의 모든 전자제품 판매를 가져오는 것은 다음과 같습니다.
=FILTER(A2:G33, (B2:B33="West")*(C2:C33="Electronics"))
첫 번째 인수는 반환하려는 범위입니다. 두 번째는 조건이며, 두 검사 사이의 곱셈은 AND 역할을 합니다. 둘 다 참이어야 합니다. 별표를 더하기 기호로 전환하면 OR이 되고 결과가 자동으로 유출됩니다. 소스에 새 행을 추가하면 Enter를 누르는 순간 유출된 출력이 업데이트됩니다.
빈 결과를 처리하기 위해 세 번째 인수를 사용하여 IFERROR의 FILTER를 래핑할 수 있습니다. =FILTER(range, condition, "No matches") 시트에 #CALC가 표시되지 않도록 합니다! 적합한 행이 없으면 오류가 발생합니다.
UNIQUE는 3단계 중복 제거 루틴을 단일 셀로 전환했습니다.
중복 제거 기능은 좋지만 자동으로 업데이트된 적이 없습니다.
데이터 탭 아래의 중복 항목 제거 옵션은 일회성 정리에 적합합니다. 문제는 정적 목록을 생성한다는 것입니다. 열을 새 위치에 복사하거나, 대화 상자를 실행하거나, 결과를 정렬하는 경우 다음에 누군가 행을 추가할 때 모든 작업을 다시 실행해야 합니다. 셀 수 없을 만큼 많이 그런 일을 했습니다.
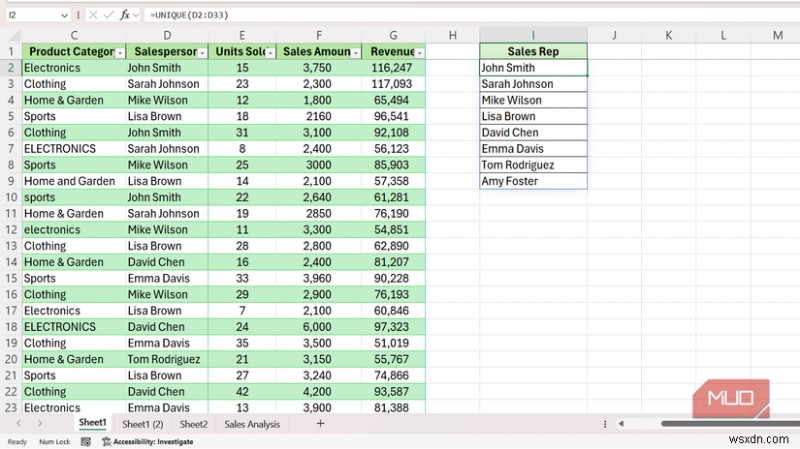
UNIQUE는 모든 단계를 건너뜁니다. 내 영업 스프레드시트의 영업사원 열을 가리키면 다음과 같습니다.
=UNIQUE(D2:D33)
그 결과 John Smith, Sarah Johnson, Mike Wilson, Lisa Brown, David Chen, Emma Davis, Tom Rodriguez 및 Amy Foster가 나왔습니다. 대화 상자가 없는 8개의 이름입니다. =SORT(UNIQUE(D2:D33))로 래핑 동일한 목록을 알파벳순으로 반환합니다. 출력은 소스에 연결된 상태로 유지되므로 데이터에 새 이름을 추가하면 유출된 목록이 자동으로 확장됩니다.
이 설정은 또한 데이터 유효성 검사 드롭다운 목록에 대한 깔끔한 소스를 만듭니다. D35#와 같은 해시로 유출된 범위를 참조하는 경우 , 소스 데이터에 새 이름이 나타나면 드롭다운이 저절로 커집니다.
SORTBY로 복사-붙여넣기-정렬 셔플을 완전히 종료했습니다.
소스 데이터를 건드리지 않고 뷰 정렬
Excel에서의 정렬에는 항상 작은 위험이 따릅니다. 소스를 재배열하면 고정 행을 참조하는 수식이 깨질 수 있으므로 안전한 곳에 청크를 복사하고 복사본을 정렬하는 것이 대안이었습니다. SORT가 도움이 되었지만 정렬한 모든 열을 표시하는 것이 즐거웠을 때만 가능했습니다.
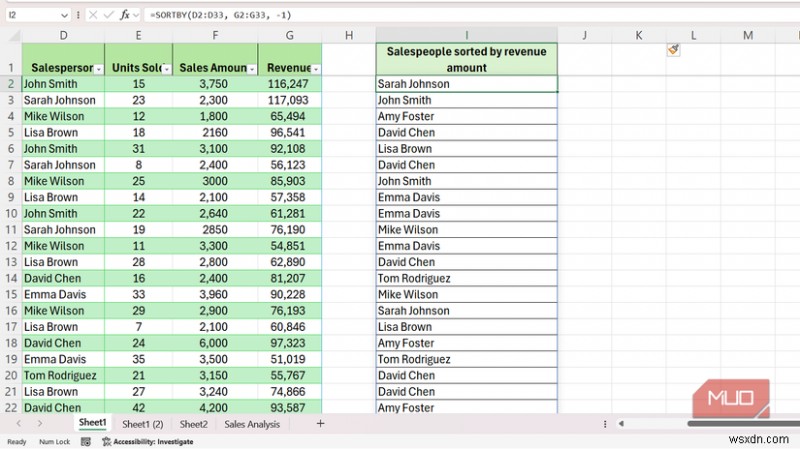
SORTBY는 해당 제약 조건을 제거합니다. 다른 범위의 값을 사용하여 한 범위를 정렬하며 두 번째 범위는 출력에 나타날 필요가 없습니다. 나는 내 데이터세트에서 수익을 기준으로 영업사원의 순위를 매기기 위해 다음 공식을 사용했습니다.
=SORTBY(D2:D33, G2:G33, -1)
첫 번째 인수는 반환하려는 항목(판매원)이고, 두 번째 인수는 정렬 기준(판매 수익)이며, -1은 순서를 내림차순으로 설정합니다. 이름은 가장 높은 판매량에서 가장 낮은 순으로 순위가 매겨지며, 사용자가 요청하지 않는 한 판매량 열은 출력에 나타나지 않습니다.
또한 FILTER와도 깔끔하게 페어링됩니다. 포장 FILTER(D2:G33, B2:B33="North") 내부 SORTBY는 북부 지역의 기록만 높은 순으로 정렬하여 한 번에 반환합니다. 소스 데이터는 그대로 유지됩니다.
SORTBY는 여러 정렬 수준을 허용합니다. 더 많은 범위/주문 쌍을 추가하여 먼저 지역별로 정렬한 다음 각 지역 내 판매 수익별로 정렬할 수 있습니다.
SEQUENCE는 제가 자랑스러워했던 채우기 핸들과 ROW 트릭을 대체했습니다.
단일 셀을 드래그하지 않고 시리즈 생성
인내심을 잃을 때까지 채우기 핸들을 드래그하거나 =ROW(A1)를 쓰는 것을 의미하는 데 사용되는 번호가 매겨진 시리즈를 생성합니다. 그리고 그것을 복사해 갑니다. 둘 다 작동하지만 기본 데이터가 변경될 때 크기가 조정되지 않습니다.
SEQUENCE는 단일 셀에서 동일한 작업을 처리하며 인수에 따라 행, 열 또는 전체 그리드를 생성합니다. 구문은 다음과 같습니다:
=SEQUENCE(rows, [columns], [start], [step])
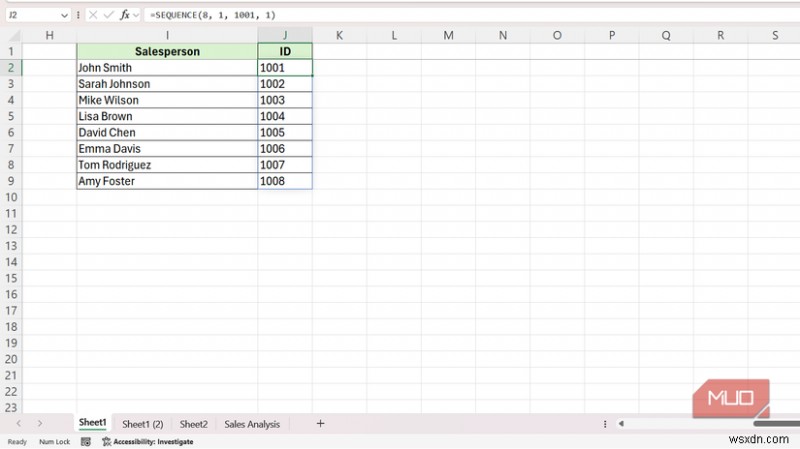
내 데이터에서 1001부터 시작하는 8명의 영업사원의 번호를 매기기 위해 다음 공식을 사용했습니다.
=SEQUENCE(8, 1, 1001, 1)
단일 열에 1001부터 1008까지 반환됩니다. 열을 1로 설정하고 단계를 1로 설정하면 연속된 정수가 있는 세로 목록으로 유지됩니다. SEQUENCE가 그 자리를 차지하는 곳은 다른 함수 내부입니다. 2026년 1월을 31일 기간으로 설정하려면 다음 공식을 사용하세요.
=DATE(2026, 1, SEQUENCE(31))
유출된 배열을 TEXT, INDEX 또는 범위를 기대하는 기타 함수에 입력하면 도우미 열이 필요했던 항목이 축소됩니다. SEQUENCE를 사용하여 날짜 열을 채우는 방법에 대해 글을 쓸 때 이 내용을 더 자세히 다루었는데, 이 방법을 사용하면 내가 작성한 모든 달력이나 일정에서 시간이 절약됩니다.
다음에 파헤쳐보고 싶은 기능
이전 방법 중 어느 것도 깨지지 않았습니다. 저와 나중에 통합 문서를 여는 다른 사람 모두에게 시간이 더 오래 걸리고 유지 관리가 더 어려운 파일을 생성합니다. 나에게 변화는 기본적으로 내가 도달하는 것입니다. 새로운 스프레드시트는 동적 배열 사고로 시작되며, 이전 도구 상자는 내가 다른 사람의 파일을 편집할 때만 나타납니다. 다음 목록에는 문자열 분리를 위한 TEXTSPLIT, 범위 결합을 위한 VSTACK 및 HSTACK, 피벗 테이블을 완전히 건너뛰는 PIVOTBY 및 GROUPBY가 있습니다. 각 릴리스마다 또 다른 습관이 사라지는 것 같은데, 저는 괜찮습니다.