컨볼루션 신경망 구성에서 iOS에 OCR 배포까지
프로젝트 동기 ✍️ ??
몇 달 전에 MNIST 데이터 세트에 대한 딥 러닝 모델을 만드는 방법을 배우는 동안 필기 문자를 인식하는 iOS 앱을 만들었습니다.
제 친구 모모세 카이치(Kaichi Momose)는 일본어 학습 앱인 누콘(Nukon)을 개발 중이었습니다. 그는 우연히도 비슷한 기능을 갖고 싶었습니다. 그런 다음 우리는 협력하여 숫자 인식기보다 더 정교한 일본어 문자(히라가나 및 가타카나)용 OCR(광학 문자 인식/리더)을 구축했습니다.

Nukon을 개발하는 동안 일본어로 필기 인식에 사용할 수 있는 API가 없었습니다. 우리는 우리 자신의 OCR을 구축할 수밖에 없었습니다. 처음부터 하나를 구축하여 얻은 가장 큰 이점은 오프라인에서 작동한다는 것입니다. 사용자는 인터넷 없이 깊은 산속에서도 일본어 학습의 일상을 유지하기 위해 Nukon을 열 수 있습니다. 이 과정에서 많은 것을 배웠지만 더 중요한 것은 사용자에게 더 나은 제품을 제공하게 되어 기쁩니다.
이 기사에서는 iOS 앱용 일본어 OCR을 구축하는 과정을 설명합니다. 다른 언어/기호용으로 빌드하려는 경우 데이터 세트를 변경하여 자유롭게 사용자 정의할 수 있습니다.
더 이상 고민하지 않고 무엇을 다룰지 살펴보겠습니다.
파트 1️⃣:데이터세트 가져오기 및 이미지 전처리
2부️⃣:CNN(Convolutional Neural Network) 구축 및 훈련
파트 3️⃣:학습된 모델을 iOS에 통합
데이터세트 가져오기 및 이미지 사전 처리 ?
데이터 세트는 손으로 쓴 문자 및 기호의 이미지 세트 9개가 포함된 ETL 문자 데이터베이스에서 가져옵니다. 히라가나용 OCR을 구축할 예정이므로 ETL8이 우리가 사용할 데이터 세트입니다.
데이터베이스에서 이미지를 가져오려면 .npz에서 이미지를 읽고 저장하는 몇 가지 도우미 함수가 필요합니다. 형식.
import struct
import numpy as np
from PIL import Image
sz_record = 8199
def read_record_ETL8G(f):
s = f.read(sz_record)
r = struct.unpack('>2H8sI4B4H2B30x8128s11x', s)
iF = Image.frombytes('F', (128, 127), r[14], 'bit', 4)
iL = iF.convert('L')
return r + (iL,)
def read_hiragana():
# Type of characters = 70, person = 160, y = 127, x = 128
ary = np.zeros([71, 160, 127, 128], dtype=np.uint8)
for j in range(1, 33):
filename = '../../ETL8G/ETL8G_{:02d}'.format(j)
with open(filename, 'rb') as f:
for id_dataset in range(5):
moji = 0
for i in range(956):
r = read_record_ETL8G(f)
if b'.HIRA' in r[2] or b'.WO.' in r[2]:
if not b'KAI' in r[2] and not b'HEI' in r[2]:
ary[moji, (j - 1) * 5 + id_dataset] = np.array(r[-1])
moji += 1
np.savez_compressed("hiragana.npz", ary)
hiragana.npz이 있으면 저장되면 파일을 로드하고 이미지 크기를 32x32픽셀로 변경하여 이미지 처리를 시작하겠습니다. . 또한 회전 및 확대/축소되는 추가 이미지를 생성하기 위해 데이터 증강을 추가할 것입니다. 우리 모델이 다양한 각도에서 캐릭터 이미지에 대해 훈련되면 우리 모델은 사람들의 필기에 더 잘 적응할 수 있습니다.
import scipy.misc
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.models import Sequential
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
# 71 characters
nb_classes = 71
# input image dimensions
img_rows, img_cols = 32, 32
ary = np.load("hiragana.npz")['arr_0'].reshape([-1, 127, 128]).astype(np.float32) / 15
X_train = np.zeros([nb_classes * 160, img_rows, img_cols], dtype=np.float32)
for i in range(nb_classes * 160):
X_train[i] = scipy.misc.imresize(ary[i], (img_rows, img_cols), mode='F')
y_train = np.repeat(np.arange(nb_classes), 160)
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2)
# convert class vectors to categorical matrices
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
# data augmentation
datagen = ImageDataGenerator(rotation_range=15, zoom_range=0.20)
datagen.fit(X_train)CNN 구축 및 훈련 ?️
이제 재미있는 부분이 나옵니다! Keras를 사용하여 모델에 대한 CNN(Convolutional Neural Network)을 구성합니다. 모델을 처음 만들 때 하이퍼 매개변수를 실험하고 여러 번 조정했습니다. 아래 조합은 98.77%의 가장 높은 정확도를 제공했습니다. 다양한 매개변수를 직접 사용해 보십시오.
model = Sequential()
def model_6_layers():
model.add(Conv2D(32, 3, 3, input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model_6_layers()
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
model.fit_generator(datagen.flow(X_train, y_train, batch_size=16),
samples_per_epoch=X_train.shape[0],
nb_epoch=30, validation_data=(X_test, y_test))다음은 모델의 성능이 불만족스러운 경우의 몇 가지 도움말입니다. 교육 단계에서:
모델이 과적합
이는 모델이 잘 일반화되지 않았음을 의미합니다. 직관적인 설명은 이 기사를 확인하세요.
과적합을 감지하는 방법 :acc (정확도)는 계속 올라가지만 val_acc (검증 정확도)는 훈련 과정에서 반대입니다.
과적합에 대한 몇 가지 솔루션 :정규화(ex. dropouts), 데이터 증대, 데이터셋 품질 향상
모델이 "학습" 중인지 확인하는 방법
val_loss인 경우 모델이 학습하지 않습니다. (validation loss)는 훈련이 진행됨에 따라 증가하거나 감소하지 않습니다.
TensorBoard 사용 — 시간 경과에 따른 모델 성능에 대한 시각화를 제공합니다. 매 에포크를 살펴보고 끊임없이 값을 비교해야 하는 번거로운 작업을 없애줍니다.
정확도에 만족하므로 가중치 및 모델 구성을 파일로 저장하기 전에 드롭아웃 레이어를 제거합니다.
for k in model.layers:
if type(k) is keras.layers.Dropout:
model.layers.remove(k)
model.save('hiraganaModel.h5')
iOS 부분으로 이동하기 전에 남은 작업은 hiraganaModel.h5을 변환하는 것뿐입니다. CoreML 모델로.
import coremltools
output_labels = [
'あ', 'い', 'う', 'え', 'お',
'か', 'く', 'こ', 'し', 'せ',
'た', 'つ', 'と', 'に', 'ね',
'は', 'ふ', 'ほ', 'み', 'め',
'や', 'ゆ', 'よ', 'ら', 'り',
'る', 'わ', 'が', 'げ', 'じ',
'ぞ', 'だ', 'ぢ', 'づ', 'で',
'ど', 'ば', 'び',
'ぶ', 'べ', 'ぼ', 'ぱ', 'ぴ',
'ぷ', 'ぺ', 'ぽ',
'き', 'け', 'さ', 'す', 'そ',
'ち', 'て', 'な', 'ぬ', 'の',
'ひ', 'へ', 'ま', 'む', 'も',
'れ', 'を', 'ぎ', 'ご', 'ず',
'ぜ', 'ん', 'ぐ', 'ざ', 'ろ']
scale = 1/255.
coreml_model = coremltools.converters.keras.convert('./hiraganaModel.h5',
input_names='image',
image_input_names='image',
output_names='output',
class_labels= output_labels,
image_scale=scale)
coreml_model.author = 'Your Name'
coreml_model.license = 'MIT'
coreml_model.short_description = 'Detect hiragana character from handwriting'
coreml_model.input_description['image'] = 'Grayscale image containing a handwritten character'
coreml_model.output_description['output'] = 'Output a character in hiragana'
coreml_model.save('hiraganaModel.mlmodel')
output_labels 나중에 iOS에서 볼 수 있는 모든 출력입니다.
재미있는 사실:일본어를 이해한다면 출력 문자의 순서가 히라가나의 "알파벳 순서"와 일치하지 않는다는 것을 알 수 있습니다. ETL8의 이미지가 "알파벳 순서"가 아니라는 것을 깨닫는 데 시간이 걸렸습니다. 데이터셋은 일본 대학에서 수집했지만...?
학습된 모델을 iOS에 통합하시겠습니까?
우리는 마침내 모든 것을 통합합니다! 드래그 앤 드롭 hiraganaModel.mlmodel Xcode 프로젝트로. 그러면 다음과 같은 내용이 표시됩니다.
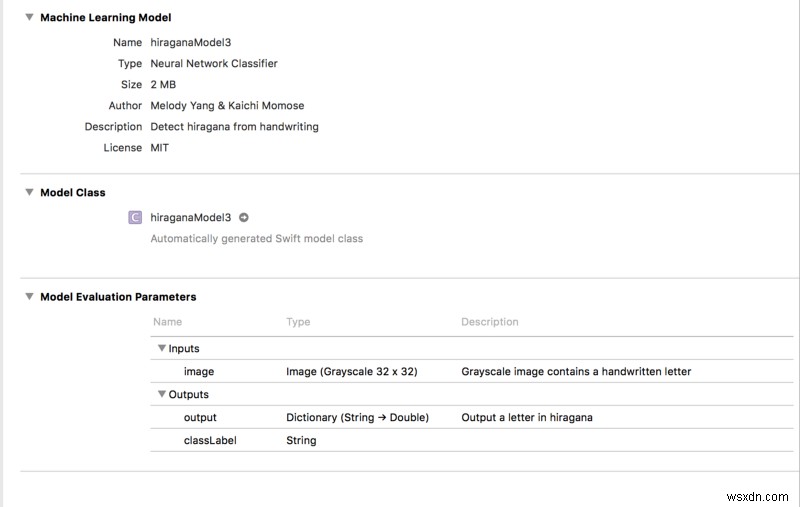
참고 :Xcode는 모델을 복사할 때 작업 공간을 생성합니다. 코딩 환경을 작업 공간으로 전환해야 합니다. 그렇지 않으면 ML 모델이 작동하지 않습니다!
최종 목표는 히라가나 모델이 이미지를 전달하여 문자를 예측하도록 하는 것입니다. 이를 위해 사용자가 쓸 수 있도록 간단한 UI를 만들고 사용자의 글을 이미지 형식으로 저장합니다. 마지막으로 이미지의 픽셀 값을 검색하여 모델에 제공합니다.
차근차근 해봅시다:
UIView에 "그리기" 문자UIBezierPath사용
import UIKit
class viewController: UIViewController {
@IBOutlet weak var canvas: UIView!
var path = UIBezierPath()
var startPoint = CGPoint()
var touchPoint = CGPoint()
override func viewDidLoad() {
super.viewDidLoad()
canvas.clipsToBounds = true
canvas.isMultipleTouchEnabled = true
}
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
startPoint = point
}
}
override func touchesMoved(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
touchPoint = point
}
path.move(to: startPoint)
path.addLine(to: touchPoint)
startPoint = touchPoint
draw()
}
func draw() {
let strokeLayer = CAShapeLayer()
strokeLayer.fillColor = nil
strokeLayer.lineWidth = 8
strokeLayer.strokeColor = UIColor.orange.cgColor
strokeLayer.path = path.cgPath
canvas.layer.addSublayer(strokeLayer)
}
// clear the drawing in view
@IBAction func clearPressed(_ sender: UIButton) {
path.removeAllPoints()
canvas.layer.sublayers = nil
canvas.setNeedsDisplay()
}
}
strokeLayer.strokeColor 모든 색상이 될 수 있습니다. 그러나 canvas의 배경색은 검은색이어야 합니다. . 우리의 훈련 이미지는 흰색 배경과 검은색 획을 가지고 있지만 ML 모델은 이 스타일의 입력 이미지에 잘 반응하지 않습니다.
2. UIView 회전 UIImage으로 CVPixelBuffer를 사용하여 픽셀 값 검색
확장에는 두 가지 도우미 기능이 있습니다. 함께 이미지를 픽셀 값과 동일한 픽셀 버퍼로 변환합니다. width 입력 및 height 둘 다 32여야 합니다. 우리 모델의 입력 치수가 32 x 32 픽셀이기 때문입니다.
pixelBuffer이 있는 즉시 , model.prediction()를 호출할 수 있습니다. pixelBuffer을 전달합니다. . 그리고 우리는 간다! classLabel의 출력을 가질 수 있습니다. !
@IBAction func recognizePressed(_ sender: UIButton) {
// Turn view into an image
let resultImage = UIImage.init(view: canvas)
let pixelBuffer = resultImage.pixelBufferGray(width: 32, height: 32)
let model = hiraganaModel3()
// output a Hiragana character
let output = try? model.prediction(image: pixelBuffer!)
print(output?.classLabel)
}
extension UIImage {
// Resizes the image to width x height and converts it to a grayscale CVPixelBuffer
func pixelBufferGray(width: Int, height: Int) -> CVPixelBuffer? {
return _pixelBuffer(width: width, height: height,
pixelFormatType: kCVPixelFormatType_OneComponent8,
colorSpace: CGColorSpaceCreateDeviceGray(),
alphaInfo: .none)
}
func _pixelBuffer(width: Int, height: Int, pixelFormatType: OSType,
colorSpace: CGColorSpace, alphaInfo: CGImageAlphaInfo) -> CVPixelBuffer? {
var maybePixelBuffer: CVPixelBuffer?
let attrs = [kCVPixelBufferCGImageCompatibilityKey: kCFBooleanTrue,
kCVPixelBufferCGBitmapContextCompatibilityKey: kCFBooleanTrue]
let status = CVPixelBufferCreate(kCFAllocatorDefault,
width,
height,
pixelFormatType,
attrs as CFDictionary,
&maybePixelBuffer)
guard status == kCVReturnSuccess, let pixelBuffer = maybePixelBuffer else {
return nil
}
CVPixelBufferLockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
let pixelData = CVPixelBufferGetBaseAddress(pixelBuffer)
guard let context = CGContext(data: pixelData,
width: width,
height: height,
bitsPerComponent: 8,
bytesPerRow: CVPixelBufferGetBytesPerRow(pixelBuffer),
space: colorSpace,
bitmapInfo: alphaInfo.rawValue)
else {
return nil
}
UIGraphicsPushContext(context)
context.translateBy(x: 0, y: CGFloat(height))
context.scaleBy(x: 1, y: -1)
self.draw(in: CGRect(x: 0, y: 0, width: width, height: height))
UIGraphicsPopContext()
CVPixelBufferUnlockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
return pixelBuffer
}
}
3. 출력을 UIAlertController로 표시
이 단계는 완전히 선택 사항입니다. 처음에 GIF처럼 결과를 알려주기 위해 경고 컨트롤러를 추가했습니다.
func informResultPopUp(message: String) {
let alertController = UIAlertController(title: message,
message: nil,
preferredStyle: .alert)
let ok = UIAlertAction(title: "Ok", style: .default, handler: { action in
self.dismiss(animated: true, completion: nil)
})
alertController.addAction(ok)
self.present(alertController, animated: true) { () in
}
}짜잔! 데모용(및 앱스토어용) OCR을 구축했습니다! ??
결론 ?
OCR을 구축하는 것은 그렇게 어렵지 않습니다. 보시다시피 이 문서는 단계와 문제로 구성되어 있으며 이 프로젝트를 빌드하는 동안 마주쳤습니다. iOS와 연결하여 많은 Python 코드를 시연할 수 있도록 만드는 과정이 즐거웠고 앞으로도 계속 할 생각입니다.
이 기사가 OCR을 구축하고 싶지만 어디서부터 시작해야 할지 막막하신 분들에게 유용한 정보가 되었기를 바랍니다.
소스 코드를 찾을 수 있습니다. 여기.
보너스 :얕은 알고리즘을 실험하는 데 관심이 있다면 계속 읽으십시오!
[선택 사항] 얕은 알고리즘으로 훈련 ?
CNN을 구현하기 전에 Kaichi와 저는 다른 기계 학습 알고리즘이 작업을 완료할 수 있는지 알아보기 위해 다른 기계 학습 알고리즘을 테스트했습니다(그리고 약간의 컴퓨팅 비용을 절약할 수 있습니다!). 우리는 KNN과 Random Forest를 선택했습니다.
성능을 평가하기 위해 기준 정확도를 1/71 =0.014로 정의했습니다.
일본어에 대한 지식이 없는 사람이 문자를 맞힐 확률은 1.4%라고 가정했습니다.
따라서 정확도가 1.4%를 초과할 수 있다면 모델이 잘 작동할 것입니다. 그랬는지 봅시다. ?
KNN
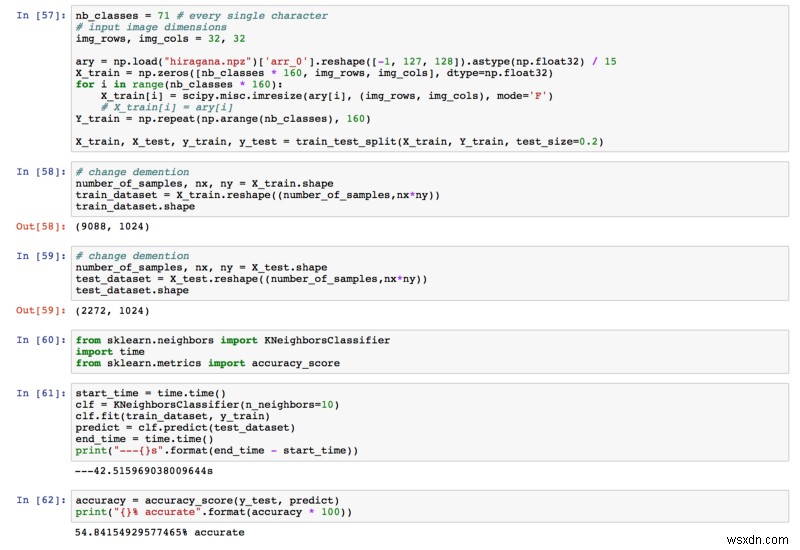
우리가 얻은 최종 정확도는 54.84%였습니다. 이미 1.4%보다 훨씬 높습니다!
랜덤 포레스트
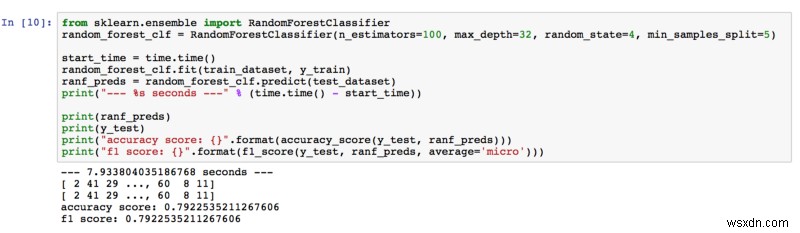
79.23%의 정확도로 Random Forest는 우리의 기대치를 초과했습니다. 하이퍼 매개변수를 조정하는 동안 추정기의 수와 트리의 깊이를 늘려 더 나은 결과를 얻었습니다. 우리는 숲에 더 많은 나무(추정기)가 있다는 것은 이미지의 더 많은 특징이 학습되었다는 것을 의미한다고 생각했습니다. 또한 트리가 깊을수록 기능에서 더 많은 세부 정보를 배웠습니다.
더 자세히 알고 싶으시면 Random Forest로 이미지 분류에 대해 설명하는 이 논문을 찾았습니다.
읽어주셔서 감사합니다. 모든 생각과 피드백을 환영합니다!