오늘날의 세상에서 데이터는 돈이라고 정당하게 말했습니다. 앱 기반 세계로의 전환과 함께 데이터가 기하급수적으로 증가합니다. 그러나 대부분의 데이터는 비정형이므로 데이터에서 유용한 정보를 추출하고 이를 이해하고 사용할 수 있는 형태로 변환하는 프로세스와 방법이 필요합니다.
데이터 마이닝 또는 "데이터베이스에서 지식 발견"은 인공 지능, 기계 학습, 통계 및 데이터베이스 시스템을 사용하여 대규모 데이터 세트에서 패턴을 발견하는 프로세스입니다.
무료 데이터 마이닝 도구는 Knime 및 Orange와 같은 완전한 모델 개발 환경에서 Java, C++ 및 주로 Python으로 작성된 다양한 라이브러리에 이르기까지 다양합니다. 일반적으로 데이터 마이닝과 관련된 네 가지 종류의 작업이 있습니다.
- 분류:익숙한 구조를 일반화하여 새로운 데이터에 적용하는 작업
- 클러스터링:데이터에서 명시된 구조를 사용하지 않고 데이터에서 어떤 방식으로든 동일한 그룹과 구조를 찾는 작업입니다.
- 연관 규칙 학습:변수 간의 관계 찾기
- 회귀:가장 작은 오류가 있는 데이터를 모델링하는 함수를 찾는 것을 목표로 합니다.
데이터 마이닝을 위한 무료 소프트웨어 도구 목록 –
2022년 최고의 무료 데이터 마이닝 도구 목록:-
1. 래피드 마이너 –
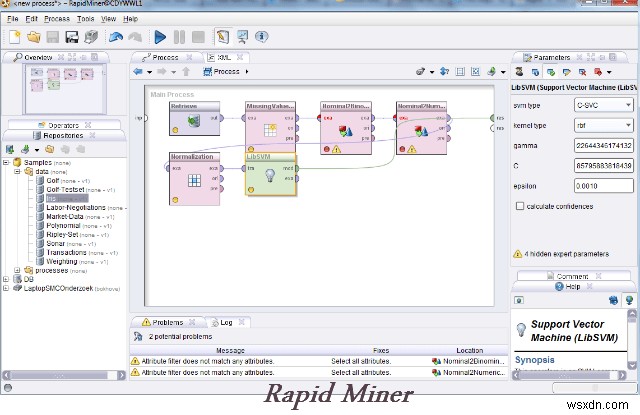
예전에는 YALE(Yet another Learning Environment)로 불렸던 Rapid Miner는 연구 및 실제 데이터 마이닝 작업 모두에 활용되는 기계 학습 및 데이터 마이닝 실험을 위한 환경입니다. . 의심할 여지 없이 데이터 마이닝을 위한 세계 최고의 오픈 소스 시스템입니다. 자바 프로그래밍 언어로 작성된 이 도구는 템플릿 기반 프레임워크를 통해 고급 분석 기능을 제공합니다.
XML 파일에 자세히 설명되어 있고 Rapid Miner의 그래픽 사용자 인터페이스로 만들어진 수많은 임의 중첩 가능 연산자로 실험을 구성할 수 있습니다. 가장 좋은 점은 사용자가 코드를 작성할 필요가 없다는 것입니다. 이미 데이터를 쉽게 분석할 수 있는 템플릿과 기타 도구가 많이 있습니다.
2. IBM SPSS 모델러 –
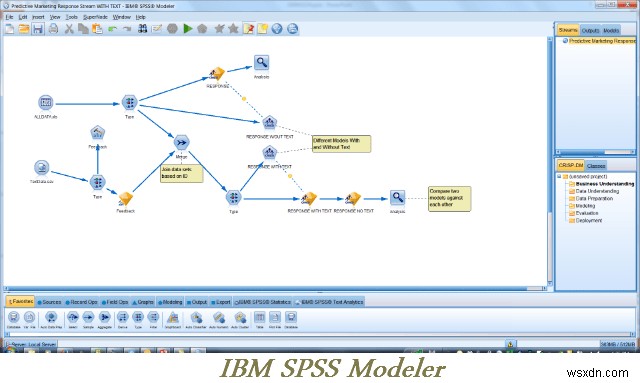
IBM SPSS Modeler 도구 워크벤치는 텍스트 분석과 같은 대규모 프로젝트 작업에 가장 적합하며 시각적 인터페이스는 매우 유용합니다. 프로그래밍 없이 다양한 데이터 마이닝 알고리즘을 생성할 수 있습니다. 역전파 학습과 함께 다층 퍼셉트론을 사용하는 이상 탐지, 베이지안 네트워크, CARMA, Cox 회귀 및 기본 신경망에도 사용할 수 있습니다. 마음이 약한 사람에게는 적합하지 않습니다.
3. 오라클 데이터 마이닝 –
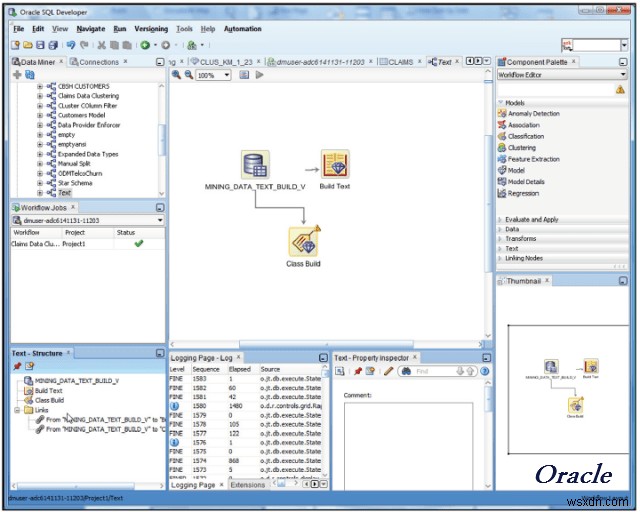
데이터 마이닝 영역의 또 다른 큰 타자는 Oracle입니다. As part of their Advanced Analytics Database option, Oracle data mining allows its users to discover insights, make predictions and leverage their Oracle data. You can build models to discover customer behavior target best customers and develop profiles.
The Oracle Data Miner GUI enables data analysts, business analysts and data scientists to work with data inside a database using a rather elegant drag and drop solution. It can also create SQL and PL/SQL scripts for automation, scheduling and deployment throughout the enterprise.
4. Teradata –
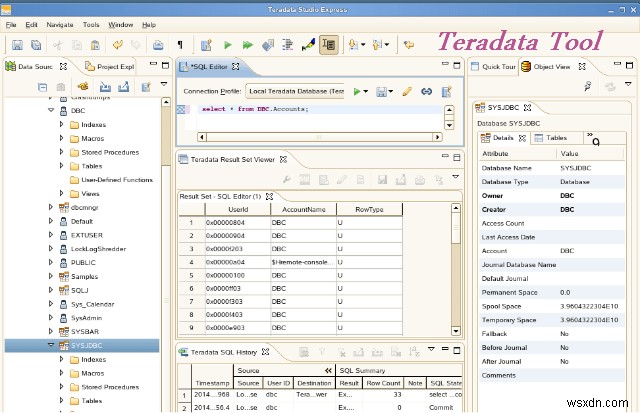
Teradata recognizes the fact that, although big data is awesome, if you don’t actually know how to analyze and use it, it’s worthless. Imagine having millions upon millions of data points without the skills to query them. That’s where Teradata comes in. They provide end-to-end solutions and services in data warehousing, big data and analytics and marketing applications.
Teradata also offers a whole host of services including implementation, business consulting, training and support.
5. Framed Data –
It’s a fully managed solution which means you don’t need to do anything but sit back and wait for insights. Framed Data takes data from businesses and turns it into actionable insights and decisions. They train, optimize, and store product ionized models in their cloud and provide predictions through an API, eliminating infrastructure overhead. They provide dashboards and scenario analysis tools that tell you which company levers are driving metrics you care about.
6. Kaggle –
Kaggle is the world’s largest data science community. Companies and researchers post their data and statisticians and data miners from all over the world compete to produce the best models.
Kaggle is a platform for data science competitions. It help you solve difficult problems, recruit strong teams, and amplify the power of your data science talent.
3 steps of working –
- Upload a prediction problem
- Submit
- Evaluate and Exchange
7. Weka –
WEKA is a very sophisticated best data mining tool. It shows you various relationships between the data sets, clusters, predictive modelling, visualization etc. There are a number of classifiers you can apply to get more insight into the data.
8. Rattle –

Rattle stands for the R Analytical Tool to Learn Easily. It presents statistical and visual summaries of data, transforms data into forms that can be readily modelled, builds both unsupervised and supervised models from the data, presents the performance of models graphically, and scores new datasets.
It is a free and open source best data mining toolkit written in the statistical language R using the Gnome graphical interface. It runs under GNU/Linux, Macintosh OS X, and MS/Windows.
9. KNIME –
Konstanz Information Miner is a user friendly, intelligible and comprehensive open-source data integration, processing, analysis and exploration platform. It has a graphical user interface which helps users to easily connect the nodes for data processing.
KNIME also integrates various components for machine learning and data mining through its modular data pipelining concept and has caught the eye of business intelligence and financial data analysis.
10. Python –
As a free and open source language, Python is most often compared to R for ease of use. Unlike R, Python’s learning curve tends to be so short it’s become legendary. Many users find that they can start building data sets and doing extremely complex affinity analysis in minutes. The most common business-use case-data visualizations are straightforward as long as you are comfortable with basic programming concepts like variables, data types, functions, conditionals and loops.
11. Orange –
Orange is a component based data mining and machine learning software suite written in Python Language. It is an Open Source data visualization and analysis for novice and experts. Data mining can be done through visual programming or Python scripting. It is also packed with features for data analytics, different visualizations, from scatterplots, bar charts, trees, to dendrograms, networks and heat maps.
12. SAS Data Mining –
Discover data set patterns using SAS Data Mining commercial software. Its descriptive and predictive modelling provides insights for better understanding of the data. They offer an easy to use GUI. They have automated tools from data processing, clustering to the end where you can find best results for taking right decisions. Being a commercial software it also includes advanced tools like Scalable processing, automation, intensive algorithms, modelling, data visualization and exploration etc.
13. Apache Mahout –
Apache Mahout is a project of the Apache Software Foundation to produce free implementations of distributed or otherwise scalable machine learning algorithms focused primarily in the areas of collaborative filtering, clustering and classification.
Apache Mahout supports mainly three use cases:Recommendation mining takes users’ behavior and from that tries to find items users might like. Clustering takes e.g. text documents and groups them into groups of topically related documents. Classification learns from existing categorized documents what documents of a specific category look like and is able to assign unlabeled documents to the (hopefully) correct category.
14. PSPP –
PSPP is a program for statistical analysis of sampled data. It has a graphical user interface and conventional command-line interface. It is written in C, uses GNU Scientific Library for its mathematical routines, and plot UTILS for generating graphs. It is a Free replacement for the proprietary program SPSS (from IBM) predict with confidence what will happen next so that you can make smarter decisions, solve problems and improve outcomes.
15. jHepWork –
jHepWork is a free and open-source data-analysis framework that is created as an attempt to make a data-analysis environment using open-source packages with a comprehensible user interface and to create a tool competitive to commercial programs.
JHepWork shows interactive 2D and 3D plots for data sets for better analysis. There are numerical scientific libraries and mathematical functions implemented in Java. jHepWork is based on a high-level programming language Jython, but Java coding can also be used to call jHepWork numerical and graphical libraries.
16. R programming Language–
There’s no mystery why R is the superstar of free data mining tools on this list. It’s free, open source and easy to pick up for people with little to no programming experience. There are literally thousands of libraries that can be incorporated into the R environment making it a powerful data mining environment. It’s a free software programming language and software environment for statistical computing and graphics.
The R language is widely used among data miners for developing statistical software and data analysis. Ease of use and extensibility has raised R’s popularity substantially in recent years.
17. Pentaho –
Pentaho provides a comprehensive platform for data integration, business analytics and big data. With this commercial tool you can easily blend data from any source. Get insights into your business data and make more accurate information driven decisions for future.
18. Tanagra –
TANAGRA is a data mining software for academic and research purposes. There are tools for exploratory data analysis, statistical learning, machine learning and databases area. Tanagra contains some supervised learning but also other paradigms such as clustering, factorial analysis, parametric and non-parametric statistics, association rule, feature selection and construction algorithms.
19. NLTK –
Natural Language Toolkit, is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for the python language. It provides a pool of language processing tools including data mining, machine learning, data scrapping, sentiment analysis and other various language processing tasks. Build python programs to deal with human language data.
We hope our list of best free data mining tools was helpful to you. We would love to know your opinion, please do share your views in the comments section below.