빠르게 반응하는 AI 기반 애플리케이션은 사용자가 즉각적으로 듣고 보는 듯한 느낌을 받도록 하여 사용자 경험을 향상시킵니다. 스트리밍을 사용하면 쿼리를 즉시 해결하거나 실시간으로 개인화된 추천을 제공하는 챗봇을 만들 수 있습니다. 이는 단지 속도의 문제가 아니라 사용자 요구 사항을 신속하게 충족하고 인지된 가치를 높이는 것입니다.
스트리밍에는 하나의 큰 블록이 아닌 작고 연속적인 청크로 데이터를 보내는 것이 포함됩니다. 챗봇이나 추천 시스템과 같은 AI 애플리케이션의 맥락에서 스트리밍이란 전체 응답을 한 번에 컴파일하고 전달하기를 기다리는 대신, 사용 가능한 즉시 부분 응답을 사용자에게 보내는 것을 의미합니다. 이러한 접근 방식을 통해 사용자는 즉각적인 피드백이나 정보를 받을 수 있어 더욱 역동적이고 반응이 빠른 사용자 경험을 만들 수 있습니다.
이 가이드에서는 SSE(서버 전송 이벤트)를 활용하여 LangChain 및 OpenAI의 언어 모델을 사용하여 Next.js 엔드포인트에서 스트리밍을 구현하는 방법을 알아봅니다. 또한 Upstash를 사용하여 스트리밍 응답을 캐시하는 방법을 배우게 됩니다.
전제조건
다음이 필요합니다:
- Node.js 18 이상
- OpenAI 계정
- Upstash 계정
- Vercel 계정
기술 스택
OpenAI 토큰 생성
OpenAI API를 사용하면 AI를 활용한 챗봇 응답을 생성할 수 있습니다. OpenAI API에 대한 요청에는 인증 토큰이 필요합니다. 토큰을 얻으려면 OpenAI 계정의 API 키로 이동하여 새 비밀 키 만들기를 클릭하세요. 버튼. 나중에 OPENAI_API_KEY로 사용할 수 있도록 이 토큰을 복사하여 안전하게 저장하세요. 환경변수입니다.
Upstash Redis 설정
Upstash 계정을 생성하고 로그인하면 Redis 탭으로 이동하여 데이터베이스를 생성하게 됩니다.
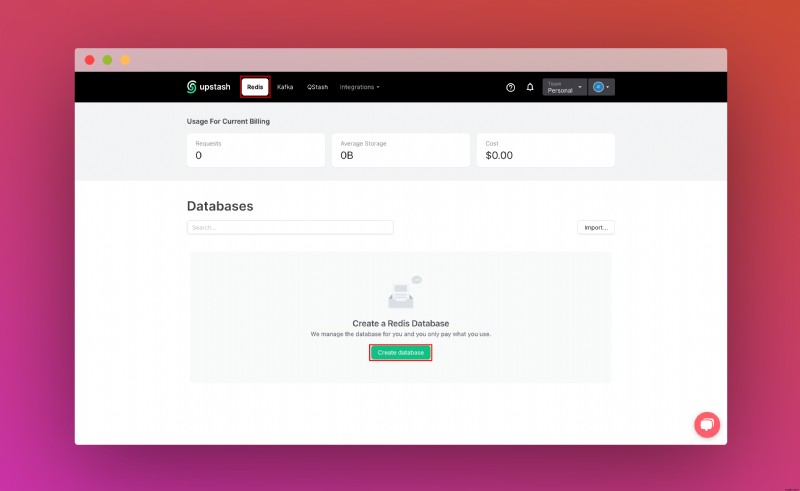
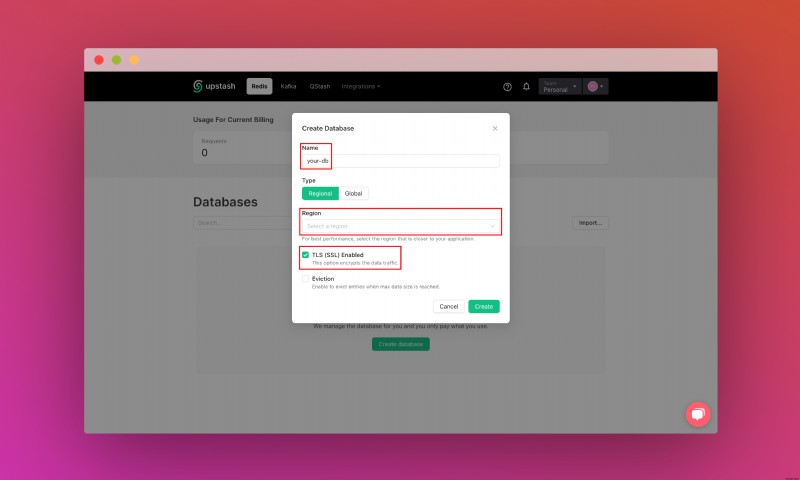
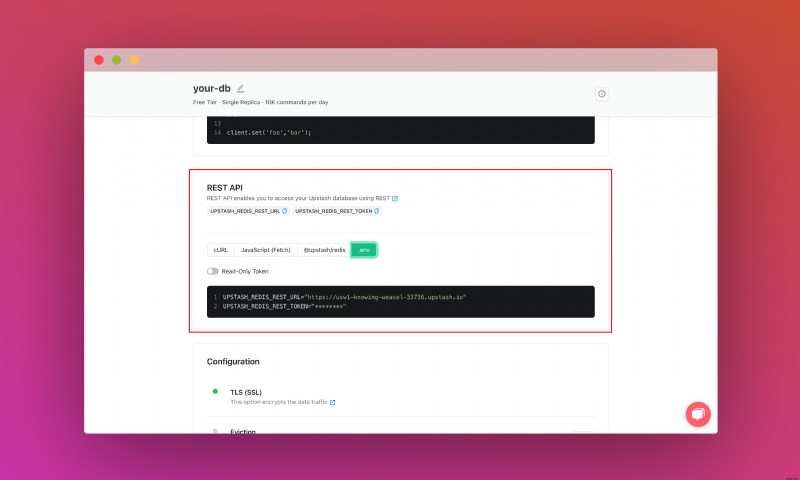
REST API 섹션을 찾을 때까지 아래로 스크롤하고 .env를 선택합니다. 버튼. 콘텐츠를 복사하여 안전한 곳에 저장하세요.
새 Next.js 애플리케이션 만들기
새로운 Next.js 프로젝트를 만들어 시작해 보겠습니다. 터미널을 열고 다음 명령을 실행하세요:
npx create-next-app@latest my-app메시지가 나타나면 다음을 선택하세요:
YesTypeScript를 사용하라는 메시지가 표시될 때.NoESLint를 사용하라는 메시지가 표시되면YesTailwind CSS를 사용하라는 메시지가 표시되면Nosrc/를 사용하라는 메시지가 표시되면 디렉토리.Yes앱 라우터를 사용하라는 메시지가 표시될 때.No기본 가져오기 별칭(@/*)을 사용자 정의하라는 메시지가 표시되면 ).
완료되면 프로젝트 디렉터리로 이동하고 다음 명령을 실행하여 개발 모드에서 앱을 시작하세요.
cd my-app
npm run dev앱은 localhost:3000에서 실행되어야 합니다. 다음 명령을 실행하여 응용 프로그램에 LangChain 종속성을 설치하기 위해 개발 서버를 중지하십시오:
npm install @langchain/openai @langchain/community이 명령은 다음 라이브러리를 설치했습니다:
@langchain/openai:OpenAI 시리즈 모델과 인터페이스하기 위한 LangChain 패키지입니다.@langchain/community:LangChain 코어와의 플러그 앤 플레이를 위한 제3자 통합 모음입니다.
이제 .env를 생성하세요. 프로젝트 루트에 있는 파일입니다. OPENAI_API_KEY을 추가하려고 합니다. 이전에 획득했습니다.
다음과 같아야 합니다:
# .env
# OpenAI Environment Variable
OPENAI_API_KEY="..."
# Upstash Redis Environment Variables
UPSTASH_REDIS_REST_URL="..."
UPSTASH_REDIS_REST_TOKEN="..."Next.js에서 API 엔드포인트를 생성하려면 웹 요청 및 응답 API를 통해 응답을 제공할 수 있는 Next.js 경로 처리기를 사용합니다. 사용자에게 응답을 스트리밍하는 Next.js에서 API 경로 생성을 시작하려면 다음 명령을 실행하세요:
mkdir -p app/api/stream/completion/chat
mkdir app/lib
-p 플래그는 chat에 대한 상위 디렉토리를 생성합니다. 디렉토리가 누락된 경우.
그러면 Next.js 프로젝트가 설정됩니다. 이제 Upstash를 사용하여 캐시 핸들러를 생성해 보겠습니다.
Upstash Redis Cache 클라이언트 인스턴스화
UpstashRedisCache 사용 클래스를 사용하면 몇 줄의 코드 내에서 OpenAI API 응답을 캐싱하기 위해 Redis 캐시 클라이언트를 초기화할 수 있습니다. upstashCache.tsx 파일 만들기 app/lib 내부 디렉토리:
캐시 핸들러를 사용하면 OpenAI API에서 생성된 대화 또는 완료 응답을 캐시하는 것이 매우 쉬워집니다. Next.js에서 Server-Sent Events를 사용하는 방법을 이해해 보겠습니다.
Next.js 앱 라우터에서 서버 전송 이벤트 API 생성
SSE(서버 전송 이벤트)를 사용하면 지속적인 폴링 없이 서버에서 클라이언트로 실시간 데이터 업데이트를 전달할 수 있습니다. SSE는 수명이 긴 단일 HTTP 연결을 통해 단방향 데이터 흐름을 가능하게 합니다.
route.ts라는 파일을 만듭니다. app/api/stream에 다음 코드를 사용하세요. 서버에서 보낸 이벤트를 사용하여 응답을 스트리밍하는 데 필요한 최소 설정을 이해하려면 디렉터리:
// File: app/api/stream/route.ts
// Prevents this route's response from being cached on Vercel
export const dynamic = "force-dynamic";
export async function POST(request: Request) {
const encoder = new TextEncoder()
// Create a streaming response
const customReadable = new ReadableStream({
start(controller) {
const message = "A sample message."
controller.enqueue(encoder.encode(`data: ${message}\n\n`))
},
})
// Return the stream response and keep the connection alive
return new Response(customReadable, {
// Set the headers for Server-Sent Events (SSE)
headers: {
Connection: "keep-alive",
"Content-Encoding": "none",
"Cache-Control": "no-cache, no-transform",
"Content-Type": "text/event-stream; charset=utf-8",
},
})
}위의 코드는 다음을 수행합니다:
- 동적 상수는
force-dynamic로 설정됩니다. , Vercel 플랫폼에서 응답 캐싱을 방지합니다. 이렇게 하면 SSE 스트림에 대한 각 요청이 최신 데이터를 가져오고 캐시에서 제공되지 않습니다. ReadableStream클라이언트에 보낼 데이터 스트림을 생성하기 위해 생성됩니다. 스트림의 시작 메소드에서 메시지가 인코딩되어 스트림 컨트롤러에 포함됩니다. 이 메시지는 SSE 스트림의 일부로 클라이언트에 전송됩니다.Response개체는 서버에서 보낸 이벤트와 관련된 헤더로 생성됩니다. 이러한 헤더에는 다음이 포함됩니다:Connection: keep-alive스트리밍을 위해 연결을 열어두기 위해.Cache-Control: no-cache, no-transform브라우저에서 캐싱을 방지합니다.Content-Type: text/event-stream; charset=utf-8콘텐츠 유형을 서버에서 보낸 이벤트로 지정합니다.
- 맞춤 ReadableStream이 포함된 응답 개체가 엔드포인트에서 반환됩니다. 이 응답은 SSE 스트림을 요청하는 클라이언트에게 전송됩니다.
이로써 응답을 스트리밍할 수 있는 엔드포인트가 생성되었습니다. 다음 섹션에서는 LangChain 콜백을 사용하여 OpenAI에서 Completion 및 Chat Completion API 응답을 스트리밍하는 방법을 이해하게 됩니다.
LangChain 콜백으로 OpenAI Completion API 응답 스트리밍
OpenAI Completion API는 주어진 프롬프트를 기반으로 텍스트를 생성하는 강력한 도구를 제공하며, 이는 콘텐츠 생성 및 언어 번역과 같은 다양한 실제 시나리오에 유용합니다. LangChain 콜백을 통합하면 응답의 실시간 스트리밍이 가능해지며 애플리케이션의 인지된 응답성이 높아집니다.
completionModel.tsx이라는 파일을 만듭니다. app/lib에서 스트리밍이 활성화된 OpenAI 인스턴스와 LangChain 콜백을 초기화하고 실시간으로 텍스트를 생성하는 함수를 정의하는 디렉터리입니다.
// File: app/lib/completionModel.tsx
import { OpenAI } from "@langchain/openai";
export const completionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new OpenAI({
streaming: true,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(`data: ${token}\n\n`));
},
async handleLLMEnd(output) {
controller.close();
},
},
],
});위의 코드는 다음을 수행합니다:
OpenAI를 가져옵니다.@langchain/openai의 클래스 패키지.completionModel라는 함수를 내보냅니다. 두 개의 매개변수를 사용합니다:- 컨트롤러:
ReadableStreamDefaultController메시지를 스트림의 대기열에 넣을 수 있는 개체입니다. - 인코더:
TextEncoder메시지를Uint8Array로 인코딩하는 객체 개체입니다.
- 컨트롤러:
OpenAI의 새 인스턴스를 만듭니다. 다음 구성 옵션이 있는 클래스:streaming:true로 설정하면 API가 스트리밍 응답을 반환해야 함을 나타냅니다.callbacks:각 단계에서 LLM에 의한 응답 생성을 가로채는 데 사용되는 두 개의 콜백 함수가 있는 단일 객체를 포함하는 배열입니다.
handleLLMNewToken:언어 모델에 의해 새 토큰이 생성될 때 호출되는 콜백입니다. 인코딩된 토큰을 컨트롤러의 대기열에 추가합니다.handleLLMEnd:언어 모델 생성이 완료되면 호출되는 비동기 콜백입니다. 컨트롤러를 닫습니다.
그런 다음 route.ts이라는 파일을 만듭니다. app/api/stream/completion에 다음 코드를 사용하세요. 디렉토리. 귀하가 생성한 초기 스트리밍 경로 핸들러의 변경 사항은 아래에 강조 표시되어 있습니다:
// File: app/api/stream/completion/route.ts
// Prevents this route's response from being cached on Vercel
export const dynamic = "force-dynamic";
+ import { completionModel } from "@/app/lib/completionModel";
export async function POST(request: Request) {
+ // Obtain the user message from request's body
+ const { message } = await request.json();
const encoder = new TextEncoder();
// Create a streaming response
const customReadable = new ReadableStream({
async start(controller) {
+ // Generate a streaming response from OpenAI with LangChain
+ await completionModel(controller, encoder).invoke(message);
},
});
// Return the stream response and keep the connection alive
return new Response(customReadable, {
// Set the headers for Server-Sent Events (SSE)
headers: {
Connection: "keep-alive",
"Content-Encoding": "none",
"Cache-Control": "no-cache, no-transform",
"Content-Type": "text/event-stream; charset=utf-8",
},
});
}이전에 Next.js에서 스트리밍 엔드포인트를 생성하기 위해 수행한 작업 외에도 위에 추가된 코드는 다음을 수행합니다.
completionModel를 가져옵니다. 기능.request.json()을 사용하여 요청 본문에서 사용자 메시지를 추출합니다. .start내부 ReadableStream의 메소드인completionModel함수는 요청에서 얻은 메시지와 비동기적으로 호출됩니다. 이 함수는 LangChain을 사용하여 OpenAI로부터 스트리밍 응답을 생성합니다.
Upstash를 사용하여 사용자 쿼리와 응답을 캐시하려면 Upstash Redis 캐시 클라이언트를 completionModel로 가져옵니다. 기능은 다음과 같습니다:
import { OpenAI } from "@langchain/openai";
+ import cache from '@/app/lib/upstashCache';
export const completionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new OpenAI({
+ cache,
streaming: true,
temperature: 0.9,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(token));
},
async handleLLMEnd(output) {
console.log(output.generations[0][0].text);
controller.close();
},
},
],
});최소한의 변경으로 Upstash를 사용하여 OpenAI Completion API 응답 캐싱을 활성화했습니다.
이제 Next.js 엔드포인트에서 OpenAI Chat Completion API 응답을 스트리밍하는 방법을 알아보겠습니다.
LangChain 콜백으로 OpenAI Chat Completion API 응답 스트리밍
OpenAI Chat Completion API는 제공된 메시지를 기반으로 실시간 대화 응답을 생성하는 강력한 도구를 제공합니다. 애플리케이션은 자연스러운 대화에 참여할 수 있는 챗봇 구축부터 AI 기반 상호 작용 기능을 갖춘 고객 지원 시스템 강화까지 다양합니다. 이를 통해 개발자는 동적이고 반응이 빠른 대화 인터페이스를 만들 수 있습니다.
chatCompletionModel.tsx이라는 파일을 만듭니다. app/lib에서 디렉토리, chatCompletionModel 정의 LangChain 콜백을 사용하여 OpenAI의 Chat Completion API용 스트리밍 인터페이스를 생성하여 제공된 메시지를 기반으로 실시간 대화 생성을 촉진하는 기능입니다.
// File: app/lib/chatCompletionModel.tsx
import { ChatOpenAI } from "@langchain/openai";
export type ConversationMessage = {
role: string;
content: string;
};
export type ConversationMessages = ConversationMessage[];
export const chatCompletionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new ChatOpenAI({
streaming: true,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(`data: ${token}\n\n`));
},
async handleLLMEnd(output) {
controller.close();
},
},
],
});위의 코드는 다음을 수행합니다:
ChatOpenAI을 가져옵니다.@langchain/openai의 클래스 패키지.- 다음 유형 정의를 생성합니다:
ConversationMessage:대화에서 단일 메시지의 유형을 정의합니다. 여기에는 역할이라는 두 가지 속성이 포함되어 있습니다. (발신자의 역할 표시) 및 콘텐츠 (메시지 내용).ConversationMessages:대화 메시지 배열의 유형을 정의합니다.
chatCompletionModel라는 함수를 내보냅니다. 두 개의 매개변수를 사용합니다:- 컨트롤러:
ReadableStreamDefaultController메시지를 스트림의 대기열에 넣을 수 있는 개체입니다. - 인코더:
TextEncoder메시지를Uint8Array으로 인코딩하는 객체 개체입니다.
- 컨트롤러:
ChatOpenAI의 새 인스턴스를 만듭니다. 다음 구성 옵션이 있는 클래스:streaming:true로 설정하면 API가 스트리밍 응답을 반환해야 함을 나타냅니다.callbacks:각 단계에서 LLM에 의한 응답 생성을 가로채는 데 사용되는 두 개의 콜백 함수가 있는 단일 객체를 포함하는 배열입니다.
handleLLMNewToken:언어 모델에 의해 새 토큰이 생성될 때 호출되는 콜백입니다. 인코딩된 토큰을 컨트롤러의 대기열에 추가합니다.handleLLMEnd:언어 모델 생성이 완료되면 호출되는 비동기 콜백입니다. 컨트롤러를 닫습니다.
그리고 route.ts라는 파일을 생성하세요. app/api/stream/completion/chat에 다음 코드를 사용하세요. 디렉토리. 귀하가 생성한 초기 스트리밍 경로 핸들러의 변경 사항은 아래에 강조 표시되어 있습니다:
// File: app/api/stream/completion/chat/route.ts
// Prevents this route's response from being cached on Vercel
export const dynamic = "force-dynamic";
+ import {
+ type ConversationMessage,
+ chatCompletionModel,
+ } from "@/app/lib/chatCompletionModel";
export async function POST(request: Request) {
+ // Obtain the conversation messages from request's body
+ const { messages = [] } = await request.json();
const encoder = new TextEncoder();
// Create a streaming response
const customReadable = new ReadableStream({
async start(controller) {
+ // Generate a streaming response from OpenAI with LangChain
+ await chatCompletionModel(controller, encoder).invoke(
+ messages.map((i: ConversationMessage) => [i["role"], i["content"]])
+ );
},
});
// Return the stream response and keep the connection alive
return new Response(customReadable, {
// Set the headers for Server-Sent Events (SSE)
headers: {
Connection: "keep-alive",
"Content-Encoding": "none",
"Cache-Control": "no-cache, no-transform",
"Content-Type": "text/event-stream; charset=utf-8",
},
});
}이전에 Next.js에서 스트리밍 엔드포인트를 생성하기 위해 수행한 작업 외에도 위에 추가된 코드는 다음을 수행합니다.
chatCompletionModel를 가져옵니다. 함수 및ConversationMessage유형 정의.request.json()를 사용하여 요청 본문에서 대화 중인 메시지를 추출합니다. .start내부 ReadableStream의 메소드인chatCompletionModel함수는 변환된 메시지 배열 후에 비동기적으로 호출됩니다. 각 메시지는 메시지의 역할과 내용을 포함하는 배열로 변환됩니다. 이 함수는 LangChain을 사용하여 OpenAI로부터 스트리밍 응답을 생성합니다.
Upstash로 채팅 기록을 캐시하려면 Upstash Redis 캐시 클라이언트를 chatCompletionModel로 가져옵니다. 기능은 다음과 같습니다:
+ import cache from '@/app/lib/upstashCache';
import { ChatOpenAI } from "@langchain/openai";
export type ConversationMessage = {
role: string;
content: string;
};
export type ConversationMessages = ConversationMessage[];
export const chatCompletionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new ChatOpenAI({
+ cache,
streaming: true,
temperature: 0.9,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(token));
},
async handleLLMEnd(output) {
console.log(output.generations[0][0].text);
controller.close();
},
},
],
});최소한의 변경만으로 Upstash를 통해 전체 채팅 기록을 캐싱할 수 있게 되었습니다.
이제 스트리밍 엔드포인트를 사용하기 위한 클라이언트 측 React 구성 요소를 생성해 보겠습니다.
서버에서 보낸 이벤트를 수신하도록 Next.js 프런트엔드 설정
이 섹션에서는 서버 전송 이벤트 API 메시지에 대한 최소 리스너를 설정하는 방법과 사용자와 AI 간에 교환되는 메시지 상태를 관리하는 접근 방식을 알아봅니다.
React에서 서버 전송 이벤트 API 수신
React의 클라이언트 측 구성 요소에서 SSE API를 수신하기 위해 지정된 API 경로에 대한 POST 요청을 시작합니다. 응답을 받으면 TextDecoderStream를 사용하여 수신 데이터를 문자열로 디코딩합니다. 방법을 사용하고 스트림에서 데이터를 지속적으로 읽습니다.
"use client";
export default function () {
const obtainAPIResponse = async (apiRoute: string, apiData: any) => {
// Initiate the first call to connect to SSE API
const apiResponse = await fetch(apiRoute, {
method: "POST",
headers: {
"Content-Type": "text/event-stream",
},
body: JSON.stringify(apiData),
});
if (!apiResponse.body) return;
// To decode incoming data as a string
const reader = apiResponse.body
.pipeThrough(new TextDecoderStream())
.getReader();
while (true) {
const { value, done } = await reader.read();
if (done) {
break;
}
if (value) {
// Do something
}
}
};
return <></>
}React에서 대화 상태 관리
사용자와 챗봇 간의 대화 상태를 관리하려면 상태 변수를 사용할 수 있습니다. 상태 변수 messages를 업데이트합니다. 및 latestMessage 대화 기록과 최신 메시지를 각각 저장합니다. SSE API에서 들어오는 데이터를 처리하는 루프 내에서 이러한 상태 변수를 업데이트하면 대화 표시가 실시간으로 업데이트될 수 있습니다. 이를 달성하기 위한 코드 추가는 다음과 같습니다:
"use client";
+ import { useEffect, useState } from "react";
+ import { ConversationMessages } from "@/app/lib/chatCompletionModel";
export default function () {
+ const [latestMessage, setLatestMessage] = useState<string>("");
+ const [messages, setMessages] = useState<ConversationMessages>([]);
const obtainAPIResponse = async (apiRoute: string, apiData: any) => {
// Initiate the first call to connect to SSE API
const apiResponse = await fetch(apiRoute, {
method: "POST",
headers: {
"Content-Type": "text/event-stream",
},
body: JSON.stringify(apiData),
});
if (!apiResponse.body) return;
// To decode incoming data as a string
const reader = apiResponse.body
.pipeThrough(new TextDecoderStream())
.getReader();
+ let incomingMessage = "";
while (true) {
const { value, done } = await reader.read();
if (done) {
+ // Insert the response received into the messages state
+ setMessages((messages) => [
+ ...messages,
+ { role: "assistant", content: incomingMessage },
+ ]);
+ // Reset the latest message's state received
+ setLatestMessage("");
break;
}
if (value) {
+ // Append the incoming data to latest message's value
+ incomingMessage += value;
+ setLatestMessage(incomingMessage);
}
}
};
return <></>
}위의 코드 추가는 다음을 수행합니다:
- SSE API로부터 수신된 수신 데이터 스트림을 저장하기 위해 상태 변수가 선언됩니다.
- 완전한 메시지를 받은 경우(
done로 표시됨) true인 경우) 가장 최근에 수신된 메시지가messages에 추가됩니다. 상태 배열. 이 메시지는 도우미 역할로 형식화되었습니다. 사용자 메시지와 구별하기 위해. 또한 다음 수신 메시지를 준비하기 위해 최신 메시지 상태가 빈 문자열로 재설정됩니다. - 데이터가 점진적으로 수신되면(아직 완전한 메시지를 형성하지 않음)
incomingMessage에 추가됩니다. 변수입니다. - 최신 메시지 상태는 연결된 수신 데이터로 업데이트되므로 새 데이터가 도착할 때마다 실시간 업데이트가 보장됩니다.
좋아요! 반응형 latestMessage 사용 그리고 messages 변수를 사용하여 이제 대화에서 교환된 메시지와 최신 AI 생성 응답을 나타내는 동적 사용자 인터페이스를 생성할 수 있습니다.
정말 많이 배웠습니다! 이제 모든 작업이 완료되었습니다 ✨
Vercel에 배포
이제 저장소를 Vercel에 배포할 준비가 되었습니다. 배포하려면 다음 단계를 따르세요.
- 앱 코드가 포함된 GitHub 저장소를 만드는 것부터 시작하세요.
- 그런 다음 Vercel 대시보드로 이동하여 새 프로젝트를 만듭니다. .
- 새 프로젝트를 방금 생성한 GitHub 저장소에 연결하세요.
- 설정 , 환경 변수를 업데이트하세요. 귀하의 지역
.env에 있는 것과 일치시키려면 파일. - 배치하세요! 🚀
추가 정보
더 자세한 통찰력을 얻으려면 이 게시물에 인용된 참고 자료를 살펴보세요.
- GitHub 저장소
- 서버 전송 이벤트
- Next.js 스트리밍
- LLM용 캐싱 계층