

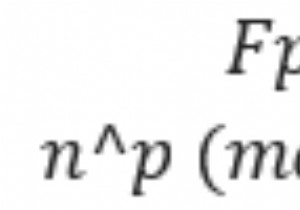
유향 그래프의 위상 정렬 또는 위상 순서는 정점 u에서 정점 v까지의 모든 유향 모서리 UV에 대해 u가 순서에서 v 앞에 오도록 정점의 선형 순서입니다. 이것은 유향 그래프에서만 의미가 있습니다. 토폴로지 정렬이 의미가 있는 곳이 많이 있습니다. 예를 들어 레시피를 따르고 있다고 가정해 보겠습니다. 여기에는 다음 단계로 이동하기 위해 반드시 거쳐야 하는 몇 가지 단계가 있습니다. 그러나 이들 중 일부는 병렬로 수행될 수 있습니다. 비슷한 방식으로 대학에서 과정을 선택할 때 추가 과정의 전제 조건이 될 수 있는 고급 과정에 대한
그래프 이론에서 최단 경로 문제는 그래프에서 구성 간선의 가중치 합이 최소화되도록 그래프에서 두 정점(또는 노드) 사이의 경로를 찾는 문제입니다. 여기서 우리는 가장자리 추가를 수정하고 가장자리에도 가중치를 추가할 수 있도록 지시된 방법을 추가해야 합니다. 이것을 추가하는 방법을 살펴보겠습니다 - 예시 /** * Adds 2 edges with the same weight in either direction * * &nbs
Dijkstra 알고리즘은 가중치 그래프에서 노드 간의 최단 경로를 찾는 알고리즘입니다. 새로운 addEdge 및 addDirectedEdge 메서드를 사용하여 그래프를 생성할 때 가장자리에 가중치를 추가합니다. 이 알고리즘이 어떻게 작동하는지 살펴보겠습니다 - 거리 컬렉션을 만들고 소스 노드를 제외한 모든 정점 거리를 무한대로 설정합니다. 거리가 0이므로 우선순위가 0인 최소 우선순위 대기열에 소스 노드를 추가합니다. 우선순위 대기열이 비어 있을 때까지 루프를 시작하고 최소 거리만큼 노드를 대기열에서 빼냅니다. 현재 노드 거리
Djikstra의 알고리즘은 한 노드에서 다른 모든 노드까지의 최단 경로 거리/경로를 찾는 데 사용됩니다. 모든 노드에서 다른 모든 노드까지의 최단 경로를 찾아야 하는 경우가 있습니다. 여기에서 모든 쌍 최단 경로 알고리즘이 유용합니다. 가장 많이 사용되는 모든 쌍 최단 경로 알고리즘은 Floyd Warshall 알고리즘입니다. Floyd Warshall 알고리즘은 다음과 같이 작동합니다 - N x N 거리 행렬을 Infinity로 초기화합니다. 그런 다음 각 모서리 u, v에 대해 이 행렬을 업데이트하여 이 모서리의 가중치를
트리 탐색은 트리 데이터 구조의 각 노드를 정확히 한 번 방문하는 프로세스를 말합니다. 이러한 순회는 노드를 방문한 순서에 따라 분류됩니다.
이 순회 방법에서는 왼쪽 하위 트리를 먼저 방문한 다음 루트를 방문한 다음 오른쪽 하위 트리를 방문합니다. 모든 노드가 하위 트리 자체를 나타낼 수 있음을 항상 기억해야 합니다. 이진 트리가 순서 순회되는 경우 , 출력은 오름차순으로 정렬된 키 값을 생성합니다. 우리는 A,에서 시작합니다. 그리고 in-order traversal에 이어 왼쪽 하위 트리 B로 이동합니다. 나 도 순서대로 순회합니다. 모든 노드를 방문할 때까지 프로세스가 계속됩니다. 이 트리의 중위 순회 출력은 다음과 같습니다. - D → B &rar
이 순회 방법에서는 루트 노드를 먼저 방문한 다음 왼쪽 하위 트리, 마지막으로 오른쪽 하위 트리를 방문합니다. 우리는 A, 에서 시작합니다. 그리고 선주문 순회 후에 우리는 먼저 A 를 방문합니다. 그 다음 왼쪽 하위 트리 B로 이동합니다. 나 선주문도 통과됩니다. 모든 노드를 방문할 때까지 프로세스가 계속됩니다. 이 트리의 선주문 순회 출력은 다음과 같습니다. - A → B → D → E → C → F → G 이것이 우리가 구현할 알고리즘입니다: 노드 데이터 인쇄
이 순회 방법에서는 루트 노드가 마지막으로 방문되므로 이름이 지정됩니다. 먼저 왼쪽 하위 트리, 오른쪽 하위 트리, 마지막으로 루트 노드를 순회합니다. 우리는 A,에서 시작합니다. Post-order traversal 다음에는 먼저 왼쪽 하위 트리B를 방문합니다. 나 또한 주문 후 순회됩니다. 모든 노드를 방문할 때까지 프로세스가 계속됩니다. 이 트리의 후위 순회 출력은 - D → E → B → F → G → C → A 이것이 우리가 구현할 알고리즘입니다 - 왼쪽 하위
트리에서 노드를 제거하는 것은 멀리서 보면 상당히 복잡합니다. 노드를 제거할 때 고려해야 할 3가지 경우가 있습니다. 이들은 다음 기능의 주석에 언급되어 있습니다. 이전에 했던 것처럼 클래스에 메서드를 만들고 재귀적으로 호출하는 도우미를 만듭니다. 클래스 메소드 deleteNode(key) { // If a node is successfully removed, a reference will be received. return !(deleteNodeHelper(this.root, key)
다음은 BinarySearchTree 클래스의 완전한 구현입니다 - 예시 class BinarySearchTree { constructor() { // Initialize a root element to null. this.root = null; } insertIter(data) { let node = new this.Node(data);
AVL 트리(발명자 Adelson-Velsky와 Landis의 이름을 따서 명명됨)는 자체 균형 이진 검색 트리입니다. 자체 균형 트리는 왼쪽과 오른쪽 모두에서 균형을 잡을 수 있도록 하위 트리 내에서 일부 회전을 수행하는 트리입니다. 이러한 나무는 삽입으로 인해 나무가 한쪽으로 무거워지는 경우에 특히 유용합니다. 균형 잡힌 트리는 O(n) 쪽으로 더 기울어지는 완전히 불균형한 트리와 달리 조회 시간을 O(log(n))에 가깝게 유지합니다.
AVL 트리는 왼쪽 및 오른쪽 하위 트리의 높이를 확인하고 차이가 1 이하인지 확인합니다. 이 차이를 균형 요소 예를 들어, 다음 트리에서 첫 번째 트리는 균형을 이루고 다음 두 트리는 균형이 맞지 않습니다 - 두 번째 트리에서 C의 왼쪽 서브트리는 높이가 2이고 오른쪽 서브트리는 높이가 0이므로 차이는 2입니다. 세 번째 트리에서 A의 오른쪽 서브트리는 높이가 2이고 왼쪽이 누락되어 있으므로 0입니다. , 그리고 그 차이는 다시 2입니다. AVL 트리는 차이(균형 계수)가 1일 수 있도록 허용합니다. BalanceFact
균형을 맞추기 위해 AVL 트리는 다음 네 가지 회전을 수행할 수 있습니다. - 왼쪽 회전 오른쪽 회전 왼쪽-오른쪽 회전 오른쪽-왼쪽 회전 처음 두 회전은 단일 회전이고 다음 두 회전은 이중 회전입니다. 불균형한 나무를 가지려면 최소한 높이 2의 나무가 필요합니다. 이 간단한 나무로 하나씩 이해해 봅시다. 왼쪽 회전 트리가 불균형 상태가 되면 오른쪽 하위 트리의 오른쪽 하위 트리에 노드가 삽입될 때 왼쪽으로 한 번 회전 - 이 예에서 노드 A A의 오른쪽 하위 트리의 오른쪽 하위 트리에 노드가 삽입되면서 불균형이 되었습
우리는 AVL 트리에 노드를 삽입하는 방법을 배울 수 있습니다. AVL 트리의 삽입은 BST와 동일하며, 트리 아래로 이동할 때마다 삽입 중에 밸런스 트리라는 추가 단계를 수행하면 됩니다. 이것은 우리가 이전에 이미 본 균형 계수를 계산해야 합니다. 그리고 구성에 따라 적절한 회전 방법을 호출해야 합니다. 위의 설명 덕분에 매우 직관적입니다. 재귀 호출을 위한 클래스 메서드와 도우미 함수를 다시 만듭니다. 예시 insert(data) { let node = new this.Node(data);
때로는 조인 기능을 사용하여 컨테이너를 결합하고 새 컨테이너를 가져와야 합니다. 2개의 HashTable을 가져와서 모든 값으로 새 HashTable을 만드는 정적 조인 메서드를 작성합니다. 간단하게 하기 위해 두 값 모두에 키가 있는 경우 두 번째 값이 첫 번째 값보다 우선 적용됩니다. 예시 combo.put(k, v)); 콤보 반환;} 다음을 사용하여 테스트할 수 있습니다. 예시 let ht1 =new HashTable();ht1.put(10, 94);ht1.put(20, 72);ht1.put(30, 1);let ht2
다음은 HashTable 클래스의 완전한 구현입니다. 이것은 물론 보다 효율적인 데이터 구조와 충돌 해결 알고리즘을 사용하여 향상될 수 있습니다. 예시 class HashTable { constructor() { this.container = []; // Populate the container with empty arrays // which can be used to add more elem
트리는 조직 계층 차트, 파일 시스템 등과 같은 계층 구조를 나타냅니다. 좀 더 공식적으로 설명하면 트리는 노드 모음으로 재귀적으로(로컬에서) 정의될 수 있습니다. 루트 노드), 여기서 각 노드는 노드에 대한 참조 목록(자식)과 함께 값으로 구성된 데이터 구조이며 참조가 중복되지 않는다는 제약 조건이 있습니다(즉, 각 자식에는 정확히 하나의 부모가 있음).
바이너리 트리는 데이터 저장 목적으로 사용되는 특수 데이터 구조입니다. 이진 트리에는 각 노드가 최대 두 개의 자식을 가질 수 있다는 특수한 조건이 있습니다. 이진 트리는 검색이 정렬된 배열만큼 빠르고 삽입 또는 삭제 작업이 연결 목록만큼 빠르기 때문에 정렬된 배열과 연결 목록의 이점이 있습니다. 다음은 아래에서 논의한 몇 가지 용어가 있는 이진 트리의 그림입니다. 중요 약관 다음은 나무와 관련된 중요한 용어입니다. 경로 − 경로는 트리의 가장자리를 따라 노드의 순서를 나타냅니다. 루트 − 트리의 맨 위에 있는
이진 검색 트리는 특별한 동작을 보입니다. 노드의 왼쪽 자식은 부모 값보다 작은 값을 가져야 하고 노드의 오른쪽 자식은 부모 값보다 큰 값을 가져야 합니다. 이 섹션에서는 나무에 대해 주로 이러한 나무에 중점을 둘 것입니다. 이진 검색 트리에 대한 연산 이진 검색 트리에서 다음 작업을 정의합니다. - 트리에 키 삽입 트리의 순서 순회 트리에서 선주문 순회 트리의 후위 순회 트리에서 값 검색 트리에서 최소값 검색 트리에서 최대값 찾기 트리에서 리프 노드 제거
트리의 각 요소는 노드입니다. 트리가 노드로 구성되어 있으므로 이진 트리를 정의하기 전에 노드를 정의해야 합니다. 3가지 속성, 즉 왼쪽, 오른쪽 및 데이터가 있는 매우 간단한 노드 정의를 만들 것입니다. 왼쪽 − 이것은 이 노드의 왼쪽 자식에 대한 참조를 보유합니다. 맞습니다 − 이것은 이 노드의 오른쪽 자식에 대한 참조를 보유합니다. 데이터 − 이 노드에 저장하려는 데이터에 대한 참조를 보유합니다. 이러한 구조의 코드 표현을 살펴보겠습니다. 예시 class Node { construc