
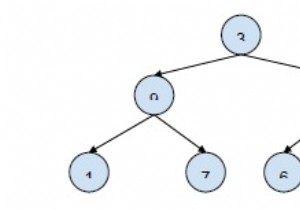

이 문제에서는 +, - , /, *와 같은 이진 연산으로 구성된 표현식 트리가 제공됩니다. 표현식 트리를 평가한 다음 결과를 반환해야 합니다. 표현식 트리 각 노드가 다음과 같이 배포되는 연산자 또는 피연산자로 구성되는 특수한 유형의 이진 트리입니다. 트리의 리프 노드는 작업을 수행할 값입니다. 리프가 아닌 노드는 이항 연산자로 구성됨 수행할 작업을 나타냅니다. 문제를 이해하기 위해 예를 들어 보겠습니다. 입력: 출력: 1 설명: 표현식 트리 디코딩, 경험치 =( (5+9) / (2*7) ) =
이 문제에서는 각각 투자 계획을 나타내는 두 개의 배열이 제공됩니다. 우리의 임무는 투자 위험 평가 를 수행하는 것입니다. 두 투자 중 어느 것이 더 유망한지 찾아보십시오. 투자 I1[][] 및 I2[][]에는 모두 일련의 결과와 해당 투자 결과의 확률이 있습니다. 이 값을 사용하여 각 투자의 위험을 찾은 다음 두 투자 중에서 더 나은 투자를 인쇄해야 합니다. 이를 위해 통계 수학을 사용하고 더 나은 투자로 결론을 내리는 데 도움이 되는 몇 가지 값을 찾을 것입니다. 이러한 값을 찾을 수 있습니다. 투자의 평균 또는 평균
프로그래밍에는 작업 수행 방법을 제어하는 몇 가지 규칙이 있습니다. 연산의 평가 순서와 연산의 연관성(왼쪽에서 오른쪽으로 정의됨) 다음은 피연산자의 평가 순서를 표시하는 프로그램입니다. 예시 #include <iostream> using namespace std; int x = 2; int changeVal() { x *= x; return x; } int main() { int p = changeVal() + cha
이 문제에서는 n/2개의 짝수 값과 n/2개의 홀수 값으로 구성된 n 크기의 배열 arr[]이 제공됩니다. 우리의 임무는 짝수 인덱스에 짝수를, 홀수 인덱스에 홀수를 배치하는 프로그램을 만드는 것입니다. 문제를 이해하기 위해 예를 들어 보겠습니다. 입력: arr[] ={5, 1, 6, 4, 3, 8} 출력: arr[] ={6, 1, 5, 4, 3, 8} 해결 방법 - 해결책은 배열을 순회한 다음 짝수 위치에 있지 않은 끝 번호를 찾아 다음 위치 값으로 바꾸는 것입니다. 이것은 유망한 솔루션이지만 짝수와 홀수에 각각 하나씩
이 문제에서는 n-ary 트리를 나타내는 인접 목록이 제공됩니다. 우리의 임무는 n-ary 트리에서 짝수 크기의 하위 트리의 수를 찾는 것입니다. N-ary 트리 은 일반적으로 다음과 같은 방식으로 계층적으로 표현되는 노드 모음으로 정의됩니다. 트리는 루트 노드에서 시작됩니다. 트리의 각 노드는 하위 노드에 대한 포인터 목록을 유지 관리합니다. 하위 노드의 수가 m보다 작거나 같습니다. 문제를 이해하기 위해 예를 들어 보겠습니다. 입력: 출력: 4 설명: 뿌리가 7인 나무는 크기가 짝수입니다.
이 문제에서는 세 개의 정수 값 A, B, T가 주어집니다. 우리의 임무는 두 개의 정수로 짝수 턴 게임을 하는 프로그램을 만드는 것입니다. 두 정수 값은 다음과 같습니다. T는 게임의 턴 수를 나타냅니다. A는 player1의 값을 나타냅니다. B는 player2의 값을 나타냅니다. T 값이 홀수이면 A 값에 2를 곱합니다. T의 값이 짝수이면 B의 값에 2를 곱합니다. max(A, B) / min(A, B) 값을 찾아서 반환해야 합니다. 마지막에. 문제를 이해하기 위해 예를 들어 보겠습니다. 입력: A =3,
이 문제에서 배열 숫자 N이 주어집니다. 우리의 임무는 숫자가 사악한 숫자인지 이상한 숫자인지 확인하는 것입니다. 악의 번호: 이진 확장에서 1의 개수가 짝수인 양수입니다. 예: 5, 17 이상한 숫자: 이진 확장에서 1이 홀수인 양수입니다. 예: 4, 6 문제를 이해하기 위해 예를 들어 보겠습니다. 입력: N =65 출력: 이블 넘버 설명: 65의 이진 확장:1000001 해결 방법: 문제에 대한 간단한 해결책은 숫자의 이진 확장을 찾은 다음 확장에서 1의 수를 계산하는 것입니다. 숫자가 짝수이면
이 문제에서는 홀수 N이 주어집니다. 우리의 임무는 소수의 합으로 홀수를 표현하는 것입니다. 숫자를 표현하는 동안 최대 3개의 소수가 있을 수 있습니다. 문제를 이해하기 위해 예를 들어 보겠습니다. 입력: N =55 출력: 53 + 2 해결 방법: 홀수는 소수의 합으로 나타낼 수 있습니다. 이 소수를 고려하면 세 가지 경우가 있습니다. 사례 1: n이 소수이면 하나의 소수 n의 합으로 표시됩니다. . 사례 2: (n - 2)가 소수이면 두 소수 n-2와 2의 합으로 표현됩니다. . 사례 3: ( n - 3 )은 G
표현식 트리는 트리의 각 노드가 연산자 또는 피연산자로 구성된 특수한 유형의 이진 트리입니다. 리프 노드 트리의 피연산자를 나타냅니다. . 리프가 아닌 노드 트리의 연산자는 . 예: 쉽게 풀 수 있는 중위 표현식을 얻으려면 중위 순회를 사용하여 트리를 순회해야 합니다.
Midy의 정리는 n/p로 표시되는 숫자의 소수 확장에 사용되는 문입니다. 여기서 n은 임의의 숫자이고 p는 소수이며 a/p는 마침표가 짝수인 반복 소수를 가집니다. Extended Midys Theorem에서 반복되는 부분을 m자리로 나누고 그 합은 10m - 1의 배수입니다. 확장 미디의 정리를 설명하는 프로그램: 예시 #include <bits/stdc++.h> using namespace std; string findDecimalValue(int num, int den) { &nb
관계형 데이터 모델은 데이터 저장 및 처리를 위해 전 세계적으로 널리 사용되는 기본 데이터 모델입니다. 이 모델은 단순하며 스토리지 효율성으로 데이터를 처리하는 데 필요한 모든 속성과 기능을 갖추고 있습니다. 그것들은 관계 대수학의 기본 연산자입니다. 여기서 우리는 몇 가지 확장 연산자에 대해 배울 것입니다. 주로 세 가지 유형이 있습니다. 교차로 가입 나누기 교차로 작업 는 관계 R1 및 R2에 대한 특수 유형의 연산으로, 여기서 요소가 있는 튜플이 두 관계, 즉 관계 R1 및 R2에 존재하는 관계입니다
외부 정렬 방대한 양의 데이터를 정렬할 수 있는 정렬 알고리즘의 범주입니다. 이 유형의 정렬은 주 메모리(RAM)에 저장할 수 없는 대용량 메모리를 획득하고 보조 메모리(하드 디스크)에 저장되는 데이터 세트에 적용됩니다. 외부 정렬에 사용되는 정렬 개념은 병합 정렬과 매우 유사합니다. 또한 병합 정렬과 같은 두 단계를 가지고 있습니다. 정렬 단계에서 작은 메모리 크기의 데이터 세트는 정렬된 다음 병합 단계에 있습니다. , 이들은 단일 데이터세트로 결합됩니다. 외부 정렬 한 번에 처리할 수 없는 거대한 데이터 세트의
이 문제에서는 두 개의 숫자 A와 B가 주어집니다. 우리의 임무는 나누지 않고 두 숫자의 빠른 평균을 계산하는 프로그램을 만드는 것입니다. 문제를 이해하기 위해 예를 들어 보겠습니다. 입력: A =34 B =54 출력: 44 해결 방법: 를 사용하여 수행할 수 있으며 나누기 연산자를 사용하는 대신 이진 확장을 시프트할 수 있습니다. 우리 솔루션의 작동을 설명하는 프로그램, 예 #include <iostream> #include <stdio.h> using namespace std; int calcA
이 문제에서는 정수 x가 주어집니다. 우리의 임무는 빠른 역제곱근( ) 32비트 부동 소수점 숫자. 숫자의 역제곱근을 찾는 알고리즘은 비디오 게임의 벡터 정규화 와 같은 프로그래밍에 매우 유용합니다. 3D 그래픽 등에서 알고리즘: 1단계: 알고리즘은 부동 소수점 값을 정수로 변환합니다. 2단계: 정수 값을 연산하고 역제곱근의 근사값을 반환합니다. 3단계: 1단계에서 사용한 것과 동일한 방법을 사용하여 정수 값을 다시 부동 소수점으로 변환합니다. 4단계: 뉴턴의 방법을 사용하여 정밀도를 향상시키기 위해 근
데이터베이스 관리 시스템 또는 DBMS는 적절한 보안 조치와 함께 최고의 효율성으로 사용자 데이터를 저장 및 검색하는 기술을 말합니다. 연합 데이터베이스 관리 시스템 하나 이상의 자율 데이터베이스를 연합 데이터베이스인 하나의 데이터베이스에 투명하게 매핑하는 특수한 유형의 DBMS입니다. 연합 데이터베이스 관리 시스템은 데이터베이스 연합을 사용하는 여러 애플리케이션으로 작업할 때 유용합니다. 연합 데이터베이스 관리 시스템에 몇 가지 문제가 있습니다. 그들은 - 데이터 모델의 차이 관리 연합 데이터베이스로 작업하는 동안 여러
정수론의 페르마의 마지막 정리는 페르메의 추측 으로도 알려져 있습니다. 는 거듭제곱 n이 2보다 크다는 것을 나타내는 정리입니다. a, b, c의 세 값은 −를 만족하지 않습니다. an + bn =cn 즉, n <=2인 경우 an + bn =cn 그렇지 않으면 an + bn !=cn n =2에 대한 값의 예 32 + 42 =9 + 16 =25 =52 . 25 + 49 =169 =132 . 이 문제에서는 L, R, 범위를 나타내는 pow [L, R] 및 거듭제곱의 세 가지 값이 제공됩니
페르마의 작은 정리 - 이 정리는 임의의 소수 p에 대해, 아p - 피 p의 배수입니다. 모듈식 산술 의 이 명령문 는 로 표시됩니다. ap ≡ a (mod p) p로 나누어 떨어지지 않으면 ap - 1 ≡ 1(모드 p) 이 문제에서는 두 개의 숫자와 p가 주어집니다. 우리의 임무는 페르마의 작은 정리 를 확인하는 것입니다. 이러한 가치에 대해. ap 인지 확인해야 합니다. ≡ a (mod p) 또는 a p - 1 ≡ 1(모드 p) 및 p의 주어진 값에 대해 참입니다. 문제를 이해하기 위해
이 문제에서 우리는 숫자 N이 주어집니다. 우리의 임무는 숫자의 다섯 번째 근의 바닥 값을 찾는 것입니다. 다섯째 루트 의 숫자는 자신에게 5번을 곱하면 숫자를 반환하는 숫자입니다. N1/5인 경우 =다음, a*a*a*a*a =N . 문제를 이해하기 위해 예를 들어 보겠습니다. 입력: N =325 출력: 3 설명: 325의 5번째 근은 3.179이고 하한값은 3입니다. 해결 방법: 문제에 대한 간단한 해결책은 1에서 n으로 순회하는 것입니다. 그리고 자신에게 5번을 곱했을 때 그 수를 구하면 그 수가 됩니다.
파일 글로빙은 경로 이름 확장이라고도 합니다. 와일드카드 를 인식하는 방법입니다. Linux에서 패턴을 찾은 다음 이러한 패턴을 기반으로 파일 경로 확장을 찾습니다. 와일드카드 패턴 패턴을 기반으로 여러 파일을 선택하는 데 사용되는 문자열입니다. ?와 같은 문자 패턴 , [ ] , *는 파일의 패턴 일치 및 다중 선택에 사용됩니다. 파일 글로빙을 사용하는 와일드카드 문자의 예: 별표(*): * 패턴은 파일 이름에서 문자열 뒤의 0개 이상의 문자를 일치시켜야 할 때 사용됩니다. 예: file*은 이름이 file,
프로그래밍 언어의 파일 처리는 파일에 액세스하고 그 안의 데이터를 가져오기 위해 메모리와 프로그래밍의 상호 작용에 매우 중요합니다. 프로그램을 사용하여 파일에서 데이터 읽기 뿐만 아니라 파일에 데이터를 쓰고 더 많은 기능을 수행합니다. 여기에서는 파일에서 데이터를 읽는 것을 볼 수 있습니다. 프로그래밍에서 작업을 수행하기 전에 파일을 열어야 합니다. 그리고 프로그래밍 언어로 파일을 여는 여러 모드가 있습니다. 파일에 대한 액세스는 파일을 여는 모드를 기반으로 합니다. 여기에서 파일을 여는 두 가지 모드의 차이점 에 대해 알