당신은 이것에 대해 들었을 것입니다. Google은 사람들이 웹사이트와 상호 작용하는 방식을 바꾸는 아이디어를 고려하고 있습니다. 보다 구체적으로 사람들이 URL, 즉 우리가 방문하는 웹 사이트를 주로 식별하고 기억하는 사람이 읽을 수 있는 웹 주소와 상호 작용하는 방식입니다. 이 제안에 대한 파급 효과는 적어도 매우 흥미로웠습니다. 그리고 생각이 났습니다.
하나, 변화 자체보다 변화에 대한 실제 반발이 더 적나라하게 드러난다. 둘째, URL을 현재 형식보다 더 의미 있고 유용하게 만들려고 노력하는 데 실제로 어떤 장점이 있습니까? 이를 위해 이 기사를 읽고 있습니다.
URL 개요
인간은 숫자보다는 단어로 기억을 연관시킵니다. 일련의 숫자보다 전체 문장이나 단락을 기억하는 것이 훨씬 쉽습니다. 우리의 언어는 대부분 단어로 구성되어 있기 때문입니다. 우리는 8자리 또는 9자리보다 긴 일련의 숫자로 어려움을 겪습니다. 단순한 이유는 문자의 경우 정보의 고유성이 상대적으로 작기 때문입니다. 1001과 1002는 말하자면 한 문자만 떨어져 있지만 차이에 의미를 부여하는 마지막 부분일 뿐입니다. 단어의 경우 문자 및/또는 소리의 짧은 시퀀스 이상으로 모호한 조합이 상대적으로 적습니다.
따라서 웹이 등장하면서 웹 사이트를 식별하기 위해 기계 해석보다 단어(문자열)를 사용하는 것이 더 논리적이 되었습니다. 재미있는 사이클입니다. 우리는 단어(코드)를 기계 언어로 변환한 다음 사람들이 의미 있는 방식으로 컴퓨터와 상호 작용할 수 있도록 그 반대 작업을 수행합니다. 숫자를 사용하여 웹에 대해 이동하는 것은 기계 방식입니다. 문자열은 인간의 방식입니다.문제는 - URL은 인간과 기계 언어의 하이브리드 형식입니다. 한편으로는 사람의 요소, 주소 자체(예:dedoimedo.com)가 있지만 나머지는 모두 원격 서버가 정보를 찾고, 검색하고, 사용자에게 다시 제공하기 위한 거의 지침입니다. 이것은 사람들이 일반 인간의 두뇌에 항상 이해되지 않는 방식으로 웹 사이트와 상호 작용한다는 점에서 문제를 나타냅니다.
또 다른 문제는 URL에 내장된 정보 충실도가 없다는 것입니다. 실제 세계의 물리적 주소와 매우 유사합니다. 17 Orchard Drive에 가면 그 주소가 무엇인지 알려주지 않습니다. 사무실이 될 수도 있고 개인 주택이 될 수도 있고 댄스홀이 될 수도 있습니다. CONTENT에 대한 정보도 없습니다. 사람, 돌무더기, 제단 등에서 찾을 수 있습니다.
마찬가지로 URL은 대상(연결하려는 사이트)을 반영하지 않습니다. 경우에 따라 약간의 상관관계가 있을 수 있지만 전반적으로 사이트가 무엇에 관한 것인지, 무엇을 하려는지 모르면 의미가 없습니다. 소규모 사이트와 대기업 모두 마찬가지입니다.
예를 들어 Google은 검색 엔진이라는 사실을 실제로 알려주지 않습니다. Yahoo는 그것이 검색 엔진이라고 말하지 않습니다. 빙은 무슨 뜻인가요? 아마존은 강인가, 숲인가, 거대한 온라인 시장인가? URL 정보에 프로토 값이 있어서가 아니라 사용 및 일반적인 평판을 통해 이러한 사이트를 신뢰하게 되었습니다. 그러나 상황은 좋아지거나 나빠집니다.
- 사이트 문자열과 사이트 목적 사이에 상관관계가 없습니다.
- 사이트 문자열과 사이트 이름(또는 그 뒤의 비즈니스) 사이에 상관관계가 없습니다.
- 웹사이트 페이지 제목과 사이트 이름 간에 상관관계가 없습니다.
- 사이트 목적에 대한 정보가 없습니다.
또한 특정 페이지에 방문하면 페이지 제목, URL 및 콘텐츠 간에 상관 관계가 없을 수 있습니다. 어떤 사이트, cats.html이라는 페이지로 이동할 수 있지만 자동차용 고양이 모양의 데칼에 관한 것일 수도 있고 작은 털복숭이에 관한 것일 수도 있습니다. 또는 완전히 다른 것. 사이트 이름은 실제로 Dany's shop이고 URL은 mysitenstuff.org와 같을 수 있습니다.
그리고 그것은 여전히 악화됩니다. 지금은 방정식의 인적 요소에 대해서만 논의했습니다. 그런 다음 기계 부품이 있습니다. 하위 도메인. m, www, www3 같은 것. http, https, ftp와 같은 프로토콜. 구분 기호, 하위 디렉터리. 날짜, 임의의 숫자, 문자열 등 사이트가 페이지를 표시하는 비균일 방식. 그런 다음 지침도 있습니다. 페이지의 URL 문자열 끝에 &uid=1234567&ref=true와 같은 내용이 추가될 수 있습니다. 이는 사용자에게는 아무 의미가 없지만 콘텐츠를 제공하거나 구문 분석하는 웹 서버 및/또는 응용 프로그램에 특정 정보를 알려줍니다. .
이러한 모든 URL 옵션은 동일한 콘텐츠로 확인되지만 모두 다르게 보이고 렌더링됩니다.
마지막으로 신뢰의 척도가 없습니다. 웹사이트는 어떤 방식으로든 검증되기 전까지는 그 가치가 동일합니다. 초기에 온라인 쇼핑이 대중화되면서 신뢰할 수 있는 기관이 암호화 및 변조 방지 배지 뒤에 신뢰성과 보안을 모두 보증하는 디지털 인증서의 개념이 등장했습니다. 커뮤니티 활동 및 페이지 순위(때로는 독점)는 도메인(사이트) 및 해당 콘텐츠와 관련된 가치의 두 번째 척도가 되었지만 기본적으로 URL 자체에는 반영되지 않습니다.
그래서 질문은 우리에게 변화가 필요한가 입니다. 아마도. 아마. 인터넷이 잘 작동하고 확장됩니다.
답은 솔루션에 있습니다. 하지만 먼저 철학이 조금 더 있습니다.제안을 들었을 때 어떻게 반응했나요?
내가 본 바로는 여기에 두 개의 주요 캠프가 있습니다. 변화를 환영하는 사람들은 이것이 웹을 더 좋게 만들 것이라고 생각합니다. 그리고 변화에 반대하는 사람들. 두 번째 그룹은 세 가지로 나눌 수 있습니다. 변화를 위한 변화에 저항하는 사람들, 기술적 장점과 예상되는 이점에 반대하는 사람들, 세 번째 그룹은 이러한 변화를 제안하거나 주도하는 영리 기업을 신뢰하지 않습니다.
실제로 이것은 훨씬 더 큰 철학적 질문을 제기합니다. Google이 이를 주도하도록 허용해야 합니까?
결국, 수년에 걸쳐 수많은 영리 기업들이 오늘날 우리가 그것에 대해 생각하지 않고 사용하는 멋진 제품을 만들었습니다. 초기의 분노와 논쟁은 오랫동안 잊혀졌습니다. 하지만 관련된 돈이 있었고, 그것은 강력한 동기부여 요인이었고, 회사의 순익을 강화하기 위한 일들이 행해졌습니다. 이름이 무엇이든 간에 주주에 대한 책임이 있는 회사라면 필연적으로 같은 일이 일어날 것입니다. Google은 모바일 세계와 검색 영역에서 막대한 영향력을 발휘하기 때문에 선두 위치에 있습니다. 그러나 이것은 어떤 회사든지 될 수 있으며 궁극적으로 근본적인 요소는 동일합니다. 어떤 사람들에게는 이것이 중요한 전부입니다. 영리를 목적으로 한다면 인류에게 이익이 되는 공정한 해결책이 될 수 없습니다. 부작용일 수도 있지만 주요 목표는 아닙니다.
그리고 이것은 정말 흥미로운 것입니다. 저항은 기술 자체와 관련된 것이 아니라 수년 동안 Google을 반영한 것입니다. Do-no-Evil(회사 매니페스트에서 사라짐)에서 평범한 또 다른 빅보이 슈트 회사로 변모한 것 같습니다.
사례를 강화하는 또 다른 예는 일반 HTML을 특별한 AMP 지시문으로 래핑하는 자체 모바일 최적화 프로젝트인 AMP에 대한 Google의 주장입니다. 페이지 로딩 등과 관련하여 약간의 장점이 있지만 전반적으로 이것은 정말 나쁩니다. 이것은 Microsoft가 웹 표준을 따르지 않는 모든 범위의 새로운 지침을 제시하여 최근에야 부분적으로 해결된 브라우저별 HTML/CSS 혼돈을 야기하는 Internet Explorer 6에서 우리가 본 문제의 반복입니다.
2006년에 Dedoimedo를 시작했을 때 이것이 큰 문제였습니다. 그 당시에는 거의 모든 사이트가 HTML에서 IE6/7/8을 재정의했습니다. 공통적이고 표준화된 방식으로 디자인을 할 수 있는 유일한 방법은 전설적인 Tim Berners-Lee가 구상한 방식이기 때문에 방문자에게 발생할 수 있는 불이익이나 기타 등등에 관계없이 그것들을 구현하지 않고 W3C 사양을 고수하기로 결정했습니다. 역사는 내가 옳았다는 것을 증명했습니다. 지금도 저는 모든 페이지에 유효한 HTML과 CSS가 있는지 확인합니다. 이는 요즘 시장에서 거의 볼 수 없는 것입니다. 그리고 이 브라우저 또는 해당 브라우저에 대해 특수 재정의를 사용하면 인터넷을 덜 좋게 만드는 데 도움이 됩니다.
유효한 HTML, 멸종 위기종.
이제 Google은 AMP로 HTML/CSS 규정 준수 차이 문제를 재현하고 있습니다. 웹은 중립적이어야 하며 공정한 국제 표준을 준수해야 합니다. 어느 회사가 원하는 대로 형성되어서는 절대 안 됩니다.
따라서 URL은 대기업, 특히 개인 데이터 사업에 종사하는 대기업에 대한 불신을 높이는 촉매제에 불과합니다. 감정과 기술을 분리하기 위해 먼저 해결해야 할 문제입니다. 그렇지 않으면 기술적인 요구 사항보다는 감정적인 요구 사항을 해결하려고 하기 때문에 향후의 모든 제안에 결함이 있을 것입니다.
이에 대한 솔루션이 없습니다. Google만이 Google을 변경할 수 있습니다. 물론 그들이 원한다면.
변화
우리는 이것을 잊지 말아야 합니다. 자비로운 생각은 삶의 추진력에 휩쓸려 초기 개념의 왜곡된 버전이 됩니다. 이는 의도적인 설계를 통해 발생하기도 하고, 사전에 보거나 계획할 수 없었던 백만 가지의 작은 결정과 제약을 통해 우연히 발생하기도 합니다. 당신이 사용하고 있는 거의 모든 제품에 대해 생각해보세요. 5년이나 10년 전에는 어땠는지 보세요. 그렇게 오래 전에도 존재했다면요. 변화가 보이시나요? 당신은 그것을 좋아합니까? 그리고 당신도 한 인간으로서 변했고 오늘날 당신이 세상을 인식하는 방식은 몇 년 전 당신이 느꼈던 것과 같지 않다는 것을 기억하세요.
Google의 솔루션 또는 해당 문제에 대한 모든 사람의 솔루션이 세계 최고일 수 있습니다. 지금부터 17년 또는 20년 후에는 최선의 의도와 세상의 모든 딥 러닝에도 불구하고 예측할 수 없는 방식으로 변할 수 있습니다. 거기에 악의가 있을 필요는 없습니다. 일이 진행되는 방식이 서서히 변하면서 사람들은 새로운 규범을 오래된 전통으로 받아들이고 익숙해져 원래의 것을 잊을 때까지 계속 나아갑니다.
거기에 큰 문제가 있습니다. 오늘 합의된 제안이 무엇이든 간에 Google의 솔루션이 완벽하더라도 Google 자체를 포함하여 어떤 회사도 비공개, 독점 구현을 만드는 것을 막을 수 없습니다. 또는 어떤 경쟁자도 마찬가지입니다.
인터넷의 민영화는 실제로 이미 일어나고 있다. 인터넷은 점점 작아지고 있습니다. 첫째, 검색 엔진, 뉴스 포털과 같은 브로커를 통해 대부분의 정보를 소비하고 있습니다. 인기있는 검색 사이트에 나열되지 않는 한 새로운 콘텐츠를 거의 찾을 수 없으며 심지어 목록의 상위에 있습니다. 모바일에서는 더욱 심각합니다. 사람들은 더 이상 검색을 거의 하지 않습니다. 그들은 하나의 중앙 집중식 스토어에서 제공하는 앱을 사용합니다.
선별되고 필터링된 콘텐츠가 포함된 엄격하게 통제되는 플랫폼인 일반적인 스마트폰이나 스마트 TV가 무엇인지 살펴보세요. 전화 앱을 실행하면 백그라운드에서 무엇을 하고 있는지 또는 어떤 URL에 연결되어 있는지 알 수 없습니다. 플랫폼이 약속한 대로 할 것이라고 신뢰하거나 사용하지 않거나 둘 중 하나입니다. 일상 생활에 필요한 기술이 얼마나 거슬리고 필요한지 감안할 때 이는 점점 더 어려워지고 있습니다. 그리고 이것은 인터넷이 실제로 붐을 일으킨 지 불과 10년 또는 15년 만에 일어났습니까? 20년 또는 50년 후에 어떤 일이 일어날지 상상해 보십시오.
인권으로서의 인터넷
말하자면 인터넷은 이미 세계 인권 선언에 추가되었습니다. 그러나 그것은 충분하지 않습니다.
이미 인터넷 전담반이 있습니다. 우리에게는 기준이 있습니다. 우리는 또한 개인 정보 보호법을 가지고 있으며 대부분 국가입니다. 그러나 디지털 자유와 웹의 중립성에 대한 개인의 비간섭을 개인 수준까지 보장하는 초정부 기구는 없습니다. 파이가 너무 크고 즙이 많아서 놓을 수 없기 때문에 이런 일이 절대 일어나지 않을 수도 있습니다.
저에게 묻는다면, 웹의 특정 부분이 진정으로 건드릴 수 없는지 확인하는 유일한 방법은 디지털 제네바와 같은 컨벤션에 그것들을 안치하는 것입니다. 이것은 순진하고 이상적으로 들릴 수 있지만, 오늘날 귀하는 귀하의 인터넷을 제어하는 사람과 그들이 귀하에게 인터넷을 제공하기로 결정한 자비입니다.
나의 제안
자, 마지막으로 기술적인 부분입니다.
어쨌든 URL 구조는 크게 다음과 같습니다. machine | 인간 | 기계입니다.
추진 요소는 중립성, 보안, 무결성, 사용 용이성입니다. 보안과 무결성은 디지털 인증서로 이미 비교적 잘 해결되었지만 개선될 수 있습니다. URL 문자열의 사람 부분에는 중립성이 포함되어 있고 사용 편의성은 첫 부분과 마지막 부분에 있습니다.
기계 부품 1
아시다시피 최신 브라우저는 주소의 https:// 및/또는 www 부분을 표시하지 않음으로써 이미 웹 주소 문자열의 기계 부분과 사람 부분을 분리하려고 시도하고 있습니다. http 또는 https. 이것은 나쁘지 않습니다. 그러나 Secure-Not Secure 개념은 충분히 명확하지 않습니다. 놀랍고 위안이 되지만 올바른 이유가 아닙니다. 이에 대해서는 인적 부분 섹션에서 이야기하겠습니다.
HTTP:// 또는 HTTPS://는 99%의 사람들에게 아무 의미가 없습니다. 다른 응용 프로그램에 URL 문자열을 전달하면 연결에 올바른 프로토콜을 사용할 수 있으므로 유용합니다. 게다가 여기에 중복이 있습니다. 인증서는 이미 연결 보안을 확인하는 작업을 수행하고 있습니다.
답은 접두사(기계 부분 1)를 완전히 제거하고 인증서만 사용하거나, 상징적인 이유로 접두사를 실제 구분 기호와 별도의 조사가 없는 웹과 같은 것으로 바꾸는 것입니다. 이것은 잠재적으로 가상 현실, 순수 미디어 스트리밍, 채팅 등과 같은 웹이 아닌 다른 프로토콜의 향후 구현을 위한 장소를 열 수 있습니다. 또한 구성, 크롬 등과 같은 브라우저별 내부 페이지와 일치하도록 유지합니다.
인체 부분
인간적인 부분은 침해되지 않아야 합니다. 사이트 페이지 주소가 무엇이든 간에 그대로 유지되어야 하며 난독화 없이 항상 사용자에게 표시되어야 합니다. 도메인 이름, 목적, 논리, 날짜 및 제목을 일치시키는 것을 포함하여 애플리케이션이 따를 수 있는 좋은 URL 관행에 대한 지침이 있어야 합니다. 일부 서버에서는 그렇게 합니다. 그러나 이것은 물리적 주소와 같습니다. We don't get to choose how streets are named, or how the home address is formed, and there are so many options worldwide. Same here.
This is part of what we are - and changing this language also breaks communication. There is no universal piece of objective information in a domain name, page title or similar. It's all down to what we want to write, and so, trying to tame this into submission is the wrong way forward.
But what about trust, integrity, spoofing?
If you mistype a site name, you could land on a wrong page. Or people ignore security warnings and give their credentials out on fake domains. Are there ways to work around these without breaking the human communication?
Well, certificates help - but they won't stop you going to a digitally signed site that is serving bogus content. Nor can they stop you from giving out your personal data. But on its own, technology CANNOT stop human stupidity or ignorance. It can be mitigated, but the unholy obsession with security degrades the user experience and breaks the Internet. So what to do?
I believe it is better to compromise on security than on user experience. The benefits outweigh the costs. There is crime out there, but largely, there's no breakdown of society and no anarchy. Because if we compromise on freedom for the sake of security, well, you know where this leads.
All that said, if the question is how to guarantee human users can differentiate between legitimate and fake sources supposedly serving identical content, beyond what we already have, then the answer lies in another question. If you give out two seemingly identical pages to a user, what is the one piece that separates them? The immediate answer is:URL. But if the user is not paying attention to the URL, what then?
The answer to that question could be a whitelist mechanism. In other words, if a user tries to input information on a page that is not recognized (in some way) as a known (read good) source, the browser could prompt the user with something like:You're currently on a page XYZ and about to fill in personal information, is this what you expect?
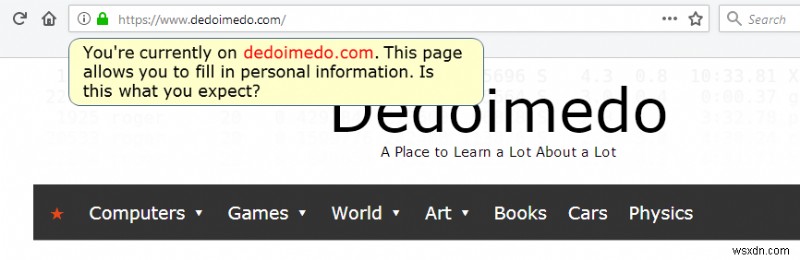
Crude illustration/mockup of what could be used to warn users when they are about to provide personal information on websites that are not "whitelisted" in some way.
People might still proceed and give away their data, but hey, nothing stops people from electrocuting themselves with toaster ovens in a bath tub, either. It is NOT about changing the URL - it's about helping people understand they are at the RIGHT address. In a way that does not break the user experience.
Now, let's talk about the machine string some more, shall we.
Machine part 2
The second part needs to be standardized. Today, servers and applications parse, mangle and structure URLs any which way they want. You can add all sorts of qualifies and key pair values, and end up with things like video autoplay, shopping cart contents, pre-filled forms, and more. In a way, this is lazy, convenient coding.
The standardization needs to be neutral - not dependent on how the browser or the site wants to present its information, because it's part of the problem today (including phishing and whatnot). I think that websites need to be forced to present a simple URL structure to the user that responds in a valid way.
The answer is:URL language. The same way browsers parse HTML and CSS, there could be a URL standard for the machine part. This could be a relatively small dictionary, and it would include somewhat STILL human-readable keys like (just a small subset of possible examples):
- unique-user-identifier - this would be a value that maps to an individual browser/user.
- javascript-status - if the client supports or runs Javascript.
- media-autoplay - whether media should play.
- media-timestamp - playback position for media.
- page - navigation element.
- Other similar keys.
And the rest would be ignored by the browser - provided all browsers adhere to the international standards and offer the same behavior and responses. Yes, the same way if you invent a new CSS class or HTML directive, and it does not exist and/or hasn't been properly declared, it gets ignored. The same way the remote application should ignore non-existent standard keys.
There must be special keys (flags), like dev=1 or debug=1 that would force the browser to interpret all provided machine parts and forward them to the server, which would also allow site devs/owners to troubleshoot their applications and offer full backward compatibility to everything we have on the market today. But then, the user could be prompted if such a combo is spotted in the URL address:
This site wants to run in dev mode. Do you want to allow it?
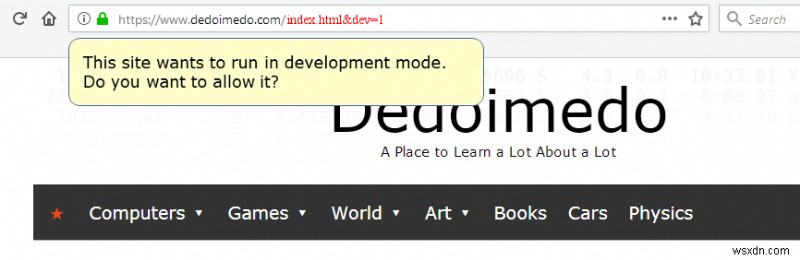
Crude illustration/mockup of what a standardized URL construct might be, with dev/debug flags.
This might enhance security too. Theoretically, the browsers could allow the user to block tracking via URL and not just on loaded pages. For instance, lots of email invitations and such come with a whole load of tracking, embedded in the URL. Privacy-conscious browsers could strip those away - or ask the user.
The URL is convenient for passing information to the application - but there's no real reason for this. When you click Buy on Amazon or PayPal, you don't see what happens. When you read Gmail, you don't see what happens. Buttons hide functionality, and it is not reflected in the URL.
To sum it up:the machine-part of the URL would contain a limited dictionary of standardized keys that would allow the information to be passed this way, but the rest would be ignored unless special flags like dev or debug are used, with the option to prompt the user. Enhanced security, enhanced privacy.
If ever defined, standardized and adopted, this will take time - an industry-wide effort. Now, is there a way to ignore forty years of legacy and existing implementations? The answer is, no bloody way. A change to the URL structure is something that will take decades. If you think IPv4 to IPv6 is complex, the URL journey will be even longer.
Finally, Quis custodiet ipsos custodes? Back to square one.
결론
The URL change is not important on its own - it is, but the technical part is relatively easy. The bigger issue is that, at the moment, people still have a fairly unrestricted access to the Web, largely due to the nerdy nature of the human-readable Web addresses. The URL is one of the old pieces of the Internet, and as such, it is mostly unfiltered and without abstractions. Once that goes away, we truly lose control of information. The world becomes a walled garden.
Google's general call to action makes sense, from the technical perspective, but the change could accidentally lead to something far bigger. Something sinister. Something sad. The death of the Internet as we know it. The ugly, cumbersome URL was invented in an age of innocence and exploration. As confusing as it is, it's the one piece that does not really belong to anyone. Any future change must preserve that neutrality.
If I were Google, I wouldn't worry about the URL. I would focus on why people don't want Google to be the arbiter of their Internet. Understand why people oppose you, regardless of the technical detail. Because, in the end, it's not about the URL. 그것은 자유에 관한 것입니다. Once that piece clicks into place, the technical solution will be trivial.
Food for thought.
건배.