블로그에서 빅 데이터에 대해 우리는 빅 데이터의 기능 계층에 대해 논의했으며 지난 블로그에서 상위 11개 클라우드 데이터 스토리지 도구를 나열했습니다. 저장 후 다음 단계는 데이터 정리 프로세스입니다.
빅 데이터에 대해 이야기할 때 비즈니스 데이터든 개인 데이터든 데이터가 놀라운 속도로 증가하고 있다는 것은 자명합니다. 사실에 따르면 매일 250경 바이트의 데이터가 전 세계에서 생성됩니다. 또한 이 데이터에는 통찰력을 얻기 위해 마이닝하기 전에 제거해야 하는 반복적이고 잘못된 레코드가 있습니다. 부정확한 데이터는 잘못된 가정과 분석으로 이어져 궁극적으로 프로젝트 실패로 이어집니다.
데이터 정리는 특정 데이터베이스에서 부정확한 레코드를 수정하고 제거(필요한 경우)하는 프로세스의 이름입니다. 데이터 정리의 목적은 주어진 데이터 세트가 정확하고 시스템의 다른 세트와 일관성이 있도록 소위 더티 데이터(Dirty Data)를 감지하여 이를 수정하거나 삭제하는 것입니다.
다양한 데이터 정리 도구가 있습니다. 좋은 데이터 정리 도구는 데이터베이스에서 중복 데이터, 잘못된 항목 및 잘못된 정보를 정리하는 데 도움이 됩니다. 이러한 도구는 사용 환경에 따라 아래 범주로 나눌 수 있습니다.
- 오프라인 데이터 정리 도구
- 클라우드 기반 데이터 정리 도구
- Salesforce 데이터용 데이터 정리 도구
이 블로그는 유용한 오프라인 데이터 정리 도구를 소개합니다.
1. 드레이크
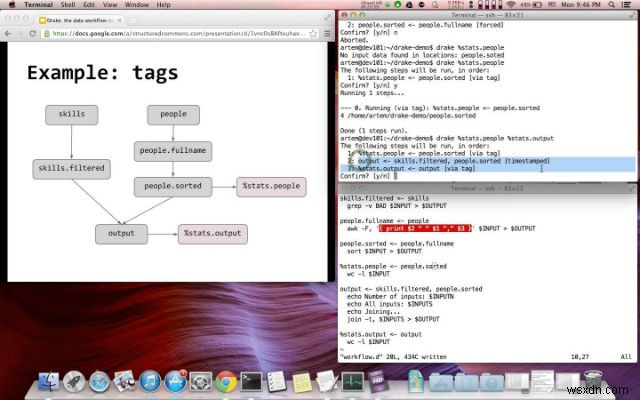
Drake는 사용이 간편하고 확장 가능한 텍스트 기반 데이터 워크플로 도구로서 데이터 및 해당 종속성을 중심으로 명령 실행을 구성합니다. 데이터 처리 단계는 입력 및 출력과 함께 정의됩니다. 종속성을 자동으로 해결하고 워크플로우 제어를 위한 다양한 옵션 세트를 제공합니다. 여러 입력 및 출력을 지원하며 HDFS 지원 기능이 내장되어 있습니다.
2. OpenRefine
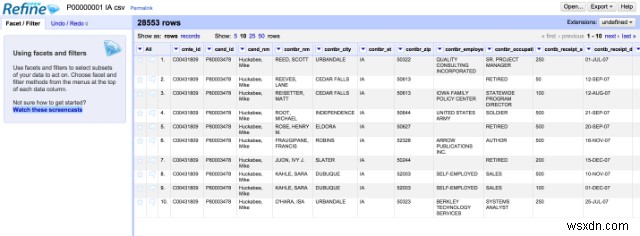
이전에는 Google Refine이라고 불렸던 OpenRefine은 지저분한 데이터로 작업할 수 있는 독립 실행형 오픈 소스 강력한 데스크톱 애플리케이션입니다. 데이터 랭글링 기능, 즉 데이터 정리 및 한 형식에서 다른 형식으로의 데이터 변환을 제공합니다. 스프레드시트 애플리케이션과 유사하지만 데이터베이스처럼 작동합니다.
관계 데이터베이스 테이블과 유사한 데이터에서 작동합니다. 즉, 열 아래에 셀이 있는 데이터 행에서 작동합니다. 하나의 OpenRefine 프로젝트는 하나의 테이블입니다. 사용자는 다양한 필터링 기준을 사용하여 행 표시를 변경할 수 있습니다. 데이터세트에서 수행된 모든 작업은 프로젝트에 저장되며 다른 데이터세트에서 재생할 수 있습니다.
3. Trifacta 랭글러
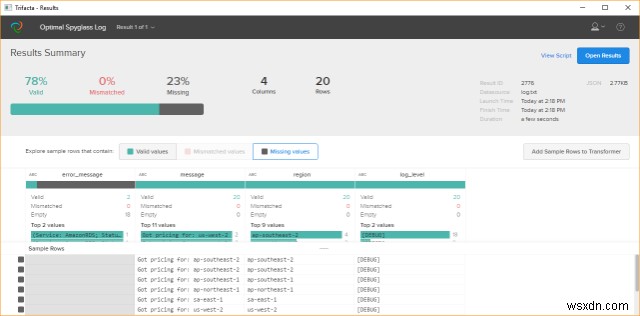
이 도구는 데이터 랭글링 프로세스에 도움이 됩니다. 데이터 랭글링은 반자동 도구를 사용하여 데이터를 보다 편리하게 사용할 수 있도록 하나의 원시 형식에서 다른 형식으로 데이터를 수동으로 변환하거나 매핑하는 프로세스로 느슨하게 정의됩니다.
Wrangler는 조직이 다양한 데이터에서 가치를 도출하는 방식을 획기적으로 개선합니다. trifecta wrangler를 통해 분석가가 데이터 시각화, 기계 학습, 인간-컴퓨터 상호 작용 및 데이터 처리의 최신 기술을 활용하여 데이터를 유용하게 만드는 방법에 새로운 접근 방식이 적용되었습니다. 서식 지정 시간을 줄이고 데이터 분석에 더 많은 시간을 할애한다는 단순한 목표를 가지고 있습니다. 복잡한 실제 데이터를 분석 도구용 데이터 테이블로 대화식으로 변환할 수 있습니다.
4. 데이터클리너
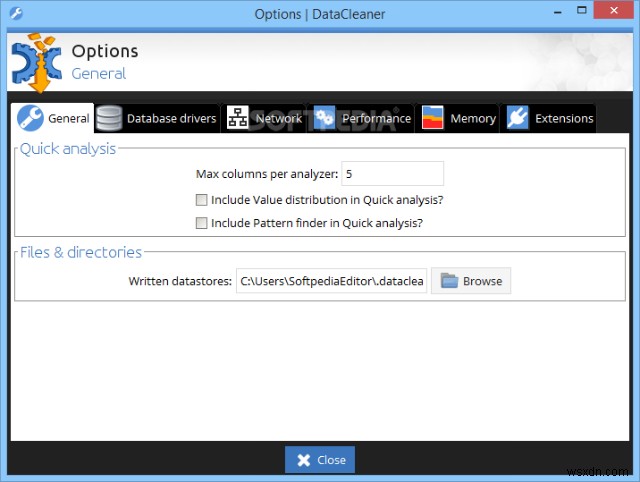
데이터 클리너는 데이터 품질 분석 애플리케이션이자 데이터 품질 솔루션을 위한 솔루션 플랫폼입니다. 핵심은 확장 가능한 강력한 프로파일링 엔진으로 데이터 정리, 변환, 보강, DE 복제, 일치 및 병합을 추가합니다. 일부 기능은 다음과 같습니다.
- 데이터 값의 패턴, 누락된 값, 문자 집합 및 기타 특성을 찾습니다.
- 이름 및 주소 확인으로 연락처 세부 정보를 정리합니다.
- 퍼지 논리와 구성 가능한 가중치 및 임계값을 사용하여 중복을 감지합니다. 그리고 마지막으로 단일 버전을 만듭니다.
- 자신만의 정리 규칙을 만들고 이를 여러 사용 시나리오와 대상 데이터베이스로 구성합니다.
5. Winpure 클린 앤 매치
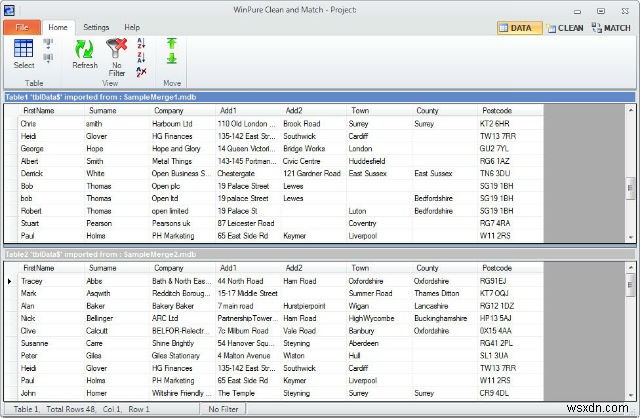
데이터 품질 관리는 프로젝트 또는 캠페인의 전반적인 성공 뒤에 있는 가장 중요한 요소입니다. 비즈니스 또는 소비자 데이터의 정확성을 높이기 위해 특별히 설계된 데이터 정리 및 일치 제품군입니다. 수상 경력에 빛나는 소프트웨어 제품군으로 메일링 리스트, 데이터베이스, 스프레드시트 및 CRM을 정리, 수정 및 중복 제거하는 데 이상적입니다. Access, Dbase, SQL Server, Excel 테이블 및 Txt 파일과 같은 데이터베이스에 사용할 수 있습니다.
6. TIBCO 명확성
TIBCO Clarity는 SaaS(Software-as-a-Service) 형식으로 웹에서 주문형 소프트웨어 서비스를 제공하는 데이터 준비 도구입니다. 서로 다른 소스에서 수집한 원시 데이터를 검색, 프로파일링, 정리 및 표준화하고 정확한 분석 및 지능적인 의사 결정을 위한 양질의 데이터를 제공하는 데 사용할 수 있습니다. 원시 데이터를 관리하는 TIBCO Clarity의 기능:
- 원활한 통합
- 데이터 검색 및 프로파일링
- 중복 제거
- 주소 표준화
- 데이터 변환
7. 데이터 사다리
Data Ladder Company는 비즈니스 사용자가 데이터 일치, 프로파일링, 중복 제거 및 강화 도구를 통해 데이터를 최대한 활용할 수 있도록 지원하는 데이터 품질 소프트웨어 회사입니다. . Data Match Enterprise 제품군은 고객 및 연락처 데이터 품질 문제를 해결하도록 특별히 설계된 매우 시각적인 데스크톱 데이터 정리 응용 프로그램입니다. Data Match Enterprise에는 음성, 퍼지, 키 오류 및 축약 변형을 감지하기 위한 여러 독점 및 표준 알고리즘이 포함되어 있습니다.
데이터 중복 제거 소프트웨어는 사용하기 쉬운 하나의 소프트웨어 제품군에서 데이터 품질, 정리, 일치 및 중복 제거 소프트웨어를 위한 완벽한 솔루션을 제공합니다.
8. 스타DQ 프로
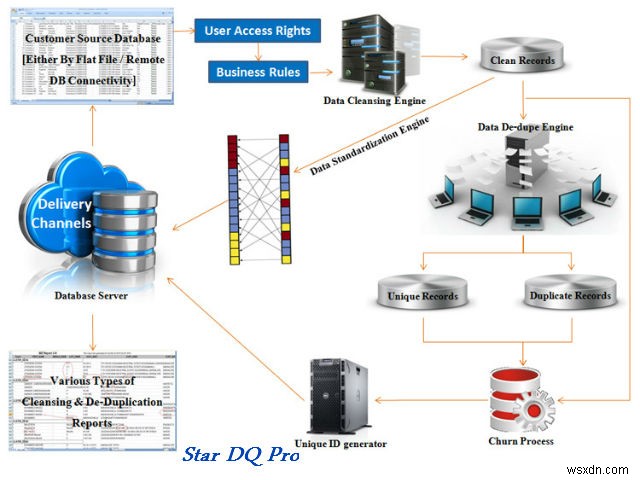
데이터가 정확하고 진실하며 최신인지 확인하세요. 정확성, 완전성, 일관성, 일정, 고유성 및 유효성과 같은 데이터 품질의 주요 요구 사항을 해결합니다. 제공되는 기능은 다음과 같습니다.
- 정리 – 결함 유형을 한정하고 설명이 포함된 부정확한 데이터의 로그를 생성합니다.
- 중복 제거 – 그룹화 및 클러스터링, 허위 진술 식별, 지속적인 증분 중복 제거.
- 모니터링 – 트랜잭션 로그, 메일/SMS를 통한 프로세스 상태 알림, 사용자 인증.
데이터 정리는 특히 많은 양의 데이터가 저장되어 있을 때 매우 중요합니다. 더티 데이터에 대한 시정 조치의 목표는 오류를 가능한 한 사소하게 만드는 것입니다. 정기적으로 데이터 정리를 하지 않으면 실수가 누적되어 업무 효율성이 저하될 수 있습니다. 빅 데이터에 관한 다음 블로그에서는 클라우드 기반 데이터 정리 도구와 Salesforce 데이터베이스용 도구를 나열하겠습니다.