이 게시물에서는 Upstash, Next.js, LangChain 및 Fly.io를 사용하여 오픈 소스 맞춤형 콘텐츠 AI Chatbot을 구축한 방법에 대해 설명합니다. Upstash는 모델 훈련 일정을 잡는 데 도움이 되었고, OpenAI API 응답을 관대하게 제한하고 캐싱하는 방법을 제공했습니다.
사용할 제품
- Next.js(프런트엔드 및 백엔드)
- LangChain(언어 모델을 기반으로 하는 애플리케이션 개발을 위한 프레임워크)
- Upstash(QStash를 통한 훈련 모델 예약, 속도 제한 및 OpenAI 응답 캐싱)
- Tailwind CSS(스타일링)
- Fly.io(배포)
필요한 것
- Node.js 18
- Upstash 계정
- OpenAI 계정(OpenAI API 키용)
Upstash Redis 설정
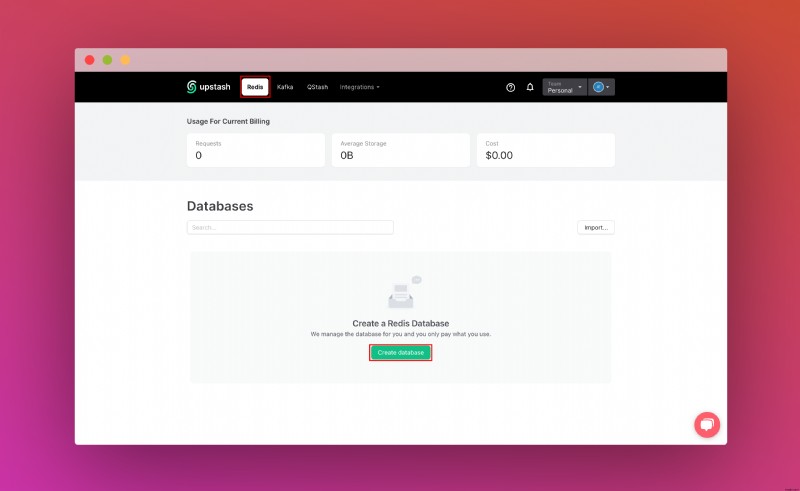
Upstash 계정을 생성하고 로그인하면 Redis 탭으로 이동하여 데이터베이스를 생성하게 됩니다.
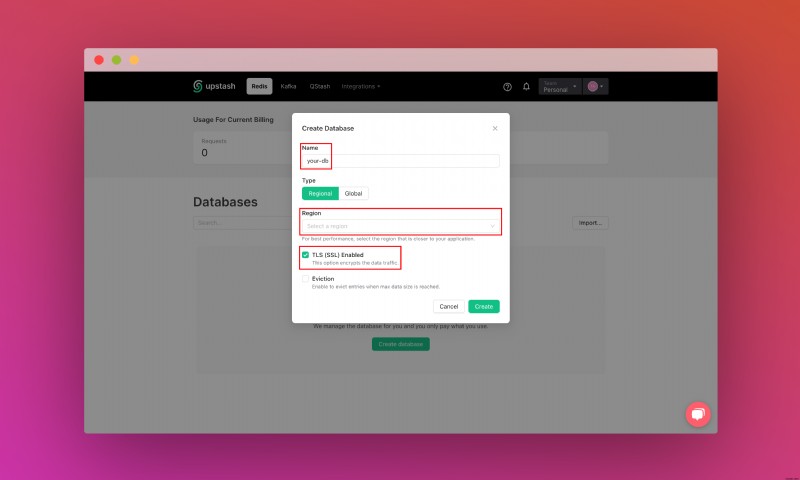
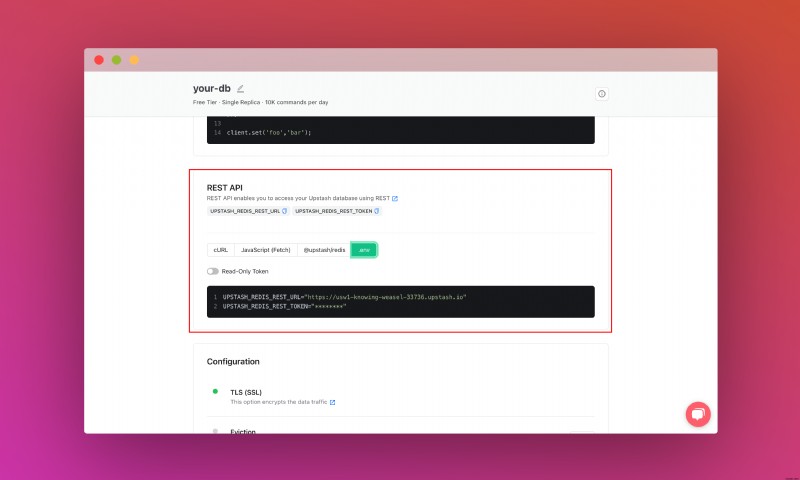
데이터베이스를 생성한 후 세부정보 탭으로 이동합니다. 데이터베이스 연결 섹션을 찾을 때까지 아래로 스크롤합니다. 콘텐츠를 복사하여 안전한 곳에 저장하세요.
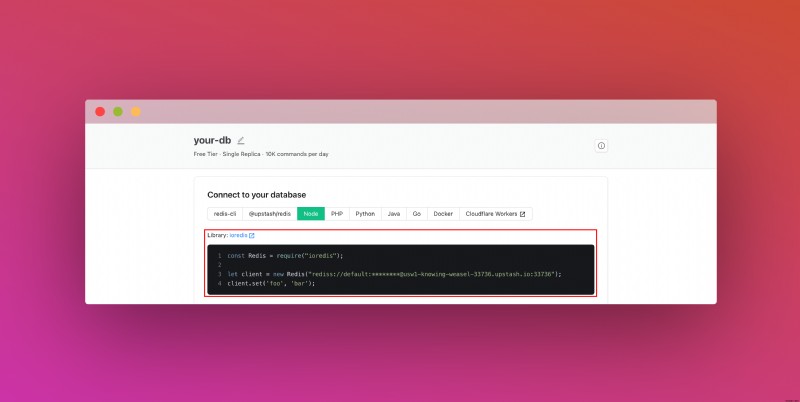
또한 REST API 섹션을 찾을 때까지 아래로 스크롤하고 .env 버튼을 선택합니다. 콘텐츠를 복사하여 안전한 곳에 저장하세요.
Upstash 설정 QStash
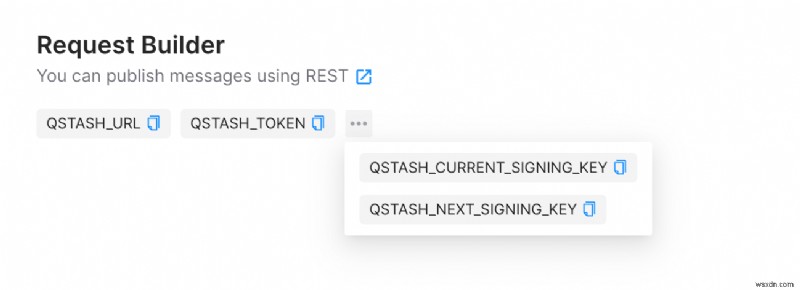
로그인하면 QStash 탭으로 이동하여 QSTASH_URL를 얻을 수 있습니다. , QSTASH_TOKEN , QSTASH_CURRENT_SIGNING_KEY 및 QSTASH_NEXT_SIGNING_KEY . 콘텐츠를 복사하여 안전한 곳에 저장하세요.
프로젝트 설정
설정하려면 앱 저장소를 복제하고 이 튜토리얼에 따라 그 안에 있는 모든 내용을 알아보세요. 프로젝트를 포크하려면 다음을 실행하세요:
git clone https://github.com/rishi-raj-jain/custom-content-ai-chatbot
cd custom-content-ai-chatbot
npm install저장소를 복제한 후에는 .env 파일을 생성하게 됩니다. 위 섹션에서 저장한 항목을 추가하게 됩니다.
다음과 같아야 합니다:
# .env
# Obtained from the steps as above
# Upstash Redis Secrets
UPSTASH_REDIS_REST_URL="https://....upstash.io"
UPSTASH_REDIS_REST_TOKEN="..."
# Upstash QStash Secrets
QSTASH_URL="https://qstash.upstash.io/v1/publish/"
QSTASH_TOKEN="..."
QSTASH_CURRENT_SIGNING_KEY="sig_..."
QSTASH_NEXT_SIGNING_KEY="sig_..."
# OpenAI Key
OPENAI_API_KEY="sk-..."
# Admin Access Key
# Used to verify a training request as to be done only by an admin
ADMIN_KEY="..."이 단계 후에는 다음 명령을 사용하여 로컬 환경을 시작할 수 있습니다:
npm run dev저장소 구조
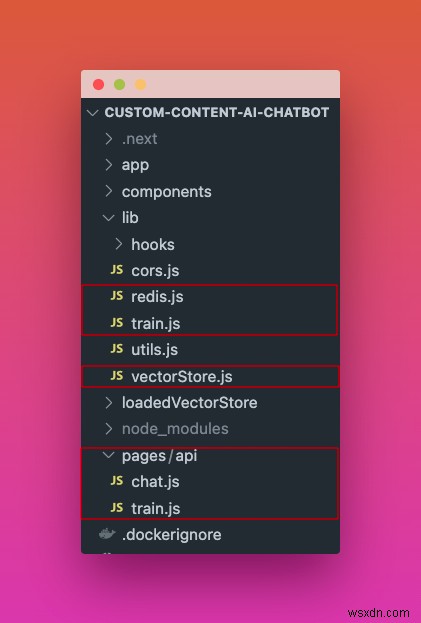
이는 프로젝트의 기본 폴더 구조입니다. 벡터 저장소 관리, 사용자 지정 콘텐츠에 대해 훈련된 AI와 채팅하기 위한 API 경로 생성(응답 캐싱 포함), 모델 훈련 프로세스 예약 등을 다루는 이 게시물에서 추가로 논의될 파일을 빨간색으로 표시했습니다.
상위 수준의 데이터 흐름 및 운영
이는 데이터 흐름과 발생하는 작업에 대한 상위 수준 다이어그램입니다 👇🏻
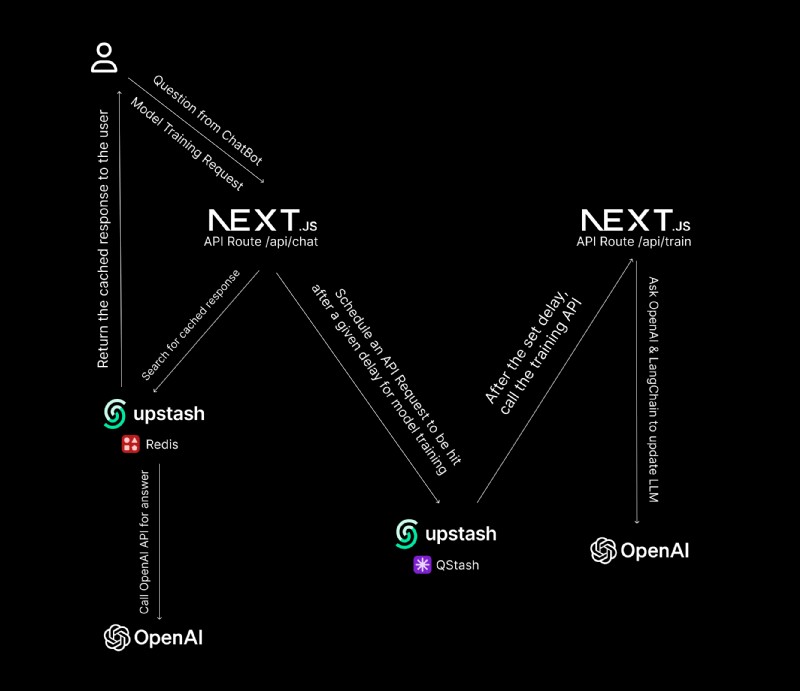
- 사용자가 챗봇을 통해 질문하면 속도 제한을 기준으로 사용자의 IP를 확인하고 Upstash Redis를 통해 캐시되지 않은 경우 OpenAI API에서 응답을 찾은 다음 캐시하여 사용자에게 스트리밍합니다.
- 관리자가 특정 URL 세트에 대한 기존 모델 교육을 요청하면 Upstash의 QStash를 사용하여 지정된 URL의 콘텐츠를 가져오고 (백그라운드에서) 모델을 업데이트하기 위해 지정된 지연 후 서버리스에서 POST 요청이 수행됩니다.
Next.js에서 채팅 설정 및 API 경로 학습
이 섹션에서는 pages/api/chat.js 경로를 설정하는 방법에 대해 설명합니다. Cross Origin 요청을 활성화하고, Chat API 호출 속도를 제한하고, 사용자에 대한 캐시 및 스트림 응답을 제공하고, 특정 URL에 대한 콘텐츠 교육을 예약하는 방법을 공개합니다. pages/api/train.js 지정된 URL에 대해서만 백그라운드에서 훈련을 수행합니다.
1. CORS 활성화
cors 사용 패키지에서는 웹사이트의 봇과 같은 여러 위치에서 챗봇을 사용할 수 있도록 애플리케이션에서 CORS를 활성화했습니다. API Route가 초기화되자마자 아래와 같이 cors 설정을 실행합니다👇🏻
// File: pages/api/chat.js
// Reference Function to cors
import { runMiddleware } from '@/lib/cors'
export default async function (req, res) {
try {
// Run the middleware
await runMiddleware(req, res)
// ...
catch (e) {
console.log(e.message || e.toString())
}
return res.end()
}
// Cors Function
// File: lib/cors.js
import Cors from 'cors'
// Initializing the cors middleware
// You can read more about the available options here: https://github.com/expressjs/cors#configuration-options
const cors = Cors({
methods: ['POST', 'OPTIONS', 'HEAD'],
})
// Helper method to wait for a middleware to execute before continuing
// And to throw an error when an error happens in a middleware
export function runMiddleware(req, res, fn = cors) {
return new Promise((resolve, reject) => {
fn(req, res, (result) => {
if (result instanceof Error) return reject(result)
return resolve(result)
})
})
}2. 특정 URL에 대한 콘텐츠 교육 요청 예약
Upstash QStash를 사용하면 실행 후 잊어버리는 것과 같은 API를 만들 수 있습니다. 응답을 받기 위해 기본 기능이 완료될 때까지 적극적으로 기다릴 필요는 없으며 오히려 백그라운드에서 수행합니다(선택적으로 약간의 지연 후에). 크론 작업과 비슷하지만 예약된 간격에 따라 정기적으로 실행되지 않고 각 요청에 따라 실행됩니다.
동일한 채팅 API 경로에서 admin-key이 있는 요청을 수락합니다. 헤더 및 서버 측 비밀 번호(ADMIN_KEY)와 일치하는지 여부 ), 약간의 지연 후 요청 본문에 전달된 URL 세트에 대한 콘텐츠 교육을 예약합니다(여기서는 10s ). 설정된 지연 후 콘텐츠 학습 요청이 지정된 엔드포인트(여기:https://custom-content-ai-chatbot.fly.dev/api/train)에 이루어집니다. )
// File: pages/api/chat.js
// If the headers contain an `admin-key` header
if (req.headers['admin-key'] === process.env.ADMIN_KEY) {
// If `urls` is not in body, return with `Bad Request`
if (!req.body.urls) return res.status(400).send('No urls to train on.')
// Hit QStash API to train on this set of URLs after 10 seconds from now
await qstashClient.publishJSON({
delay: 10,
body: { urls: req.body.urls },
url: 'https://custom-content-ai-chatbot.fly.dev/api/train'
})
return res.status(200).end()
}
이제 train API 경로(pages/api/train.js)에 무엇이 있는지 살펴보겠습니다. ) 👇🏻
// File: pages/api/train.js
import train from '@/lib/train'
import * as dotenv from 'dotenv'
import { redis } from '@/lib/redis'
import { runMiddleware } from '@/lib/cors'
import { verifySignature } from '@upstash/qstash/nextjs'
dotenv.config()
// Disabling converting request body to JSON directly
// More on https://nextjs.org/docs/pages/building-your-application/routing/api-routes#custom-config
export const config = {
api: {
bodyParser: false,
},
}
async function handler(req, res) {
try {
// Run the middleware
await runMiddleware(req, res)
// If method is not POST, return with `Forbidden Access`
if (req.method !== 'POST') return res.status(403).send('No other methods allowed.')
// If `urls` is not in body, return with `Bad Request`
if (!req.body.urls) return res.status(400).send('No urls to train on.')
// Train on the particular URLs
await train(req.body.urls)
// Once saved, clear all the responses in Upstash
let allKeys = await redis.keys('*')
if (allKeys) {
// Filter out the keys to not have the ratelimiter ones
allKeys = allKeys.filter((i) => !i.includes('@upstash/ratelimit:'))
const p = redis.pipeline()
// Create a pipeline to clear out all the keys
allKeys.forEach((i) => p.del(i))
// Execute the pipeline commands in a transaction
await p.exec()
console.log('Cleaned cached responses in Upstash.')
}
return res.status(200).end()
} catch (e) {
console.log(e.message || e.toString())
}
return res.end()
}
// Verify the incoming request to be a valid
// QStash Scheduled POST request with Upstash-Signature
export default verifySignature(handler)위 코드에서는 세 가지 중요한 작업을 수행합니다:
- QStash의
verifySignature를 사용하여 수신 요청 확인을 수행합니다. 방법. 아래에서Upstash-Signature을 찾습니다. 헤더를 확인하고 수신된 원시 본문으로 이를 확인합니다. train에 전화하세요. URL 콘텐츠를 가져와 기존 벡터 저장소에 추가(및 저장)하는 함수입니다.- Redis 트랜잭션을 통한 속도 제한 구현과 관련된 키를 필터링한 후 Upstash Redis에서 캐시된 응답을 지웁니다.
3. 속도 제한
속도 제한을 구현하기 위해 Upstash Redis 데이터베이스 클라이언트와 @upstash/ratelimit라는 속도 제한기 라이브러리를 사용합니다. .
// File: lib/redis.js
// Reference Function to ratelimiting
import * as dotenv from 'dotenv'
import { Redis } from '@upstash/redis'
import { Ratelimit } from '@upstash/ratelimit'
// Load environment variables
dotenv.config()
// Initialize Upstash Redis
export const redis = new Redis({
url: process.env.UPSTASH_REDIS_REST_URL,
token: process.env.UPSTASH_REDIS_REST_TOKEN,
})
// Initialize Upstash Rate Limiter
export const ratelimit = {
chat: new Ratelimit({
redis,
// Limit requests to 30 questions per day per IP Address
limiter: Ratelimit.slidingWindow(30, '86400s'),
}),
}
Rate Limiting을 사용하여 완전히 무료이며 공개적인 서비스를 사용할 수 있었습니다! 이를 통해 시스템의 이점, 즉 채팅 응답을 선보일 수 있었습니다. 말 그대로 누구나 웹사이트를 통해 하루에 30개의 질문을 할 수 있습니다. IP address을 기준으로 하루에 30개의 질문으로 비율 제한을 적용할 수 있습니다. 열쇠로.
// File: pages/api/chat.js
import requestIp from 'request-ip'
import { ratelimit } from '@/lib/redis'
// ...
// Get the client IP
const detectedIp = requestIp.getClientIp(req)
// If no IP detected, return with a `Bad Request`
if (!detectedIp) return res.status(400).send('Bad request.')
// Check the Rate Limit
const result = await ratelimit.chat.limit(detectedIp)
// If rate limited, return with the same
if (!result.success) return res.status(400).send('Rate limit exceeded.')
// Continue with serving the chat responses4. 저장된 인덱스 벡터 저장소를 로드하고 OpenAI에 응답 요청
모든 확인이 완료되었으므로 이제 주요 작업인 사용자 정의 콘텐츠로 OpenAI API를 호출하고 사용자에게 응답을 보내는 작업으로 이동합니다. 단순화를 위해 다음과 같은 부분으로 나누어 보겠습니다.
- 3.1:저장된 벡터 저장소 검색
// File: pages/api/chat.js
// Reference Function to loadVectorStore
import { loadVectorStore } from '@/lib/vectorStore'
// Load the trained model
const vectorStore = await loadVectorStore()
// ...
// Vectore Store Function
// File: lib/vectorStore.js
import { join } from 'path'
import { existsSync } from 'fs'
import { Document } from 'langchain/document'
import { FaissStore } from 'langchain/vectorstores/faiss'
import { OpenAIEmbeddings } from 'langchain/embeddings/openai'
export async function loadVectorStore() {
const directory = join(process.cwd(), 'loadedVectorStore')
const docStoreJSON = join(process.cwd(), 'loadedVectorStore', 'docstore.json')
if (existsSync(docStoreJSON)) {
// If the directory is found, load the vector store saved by Faiss integration
return await FaissStore.load(directory, new OpenAIEmbeddings())
} else {
// If no content is there, load the vector store with just `Hey` for starters
return await FaissStore.fromDocuments([new Document({ pageContent: 'Hey' })], new OpenAIEmbeddings())
}
}- 3.2:사용자 쿼리에 프롬프트 지침 추가
LangChain의 PromptTemplate을 사용하여 사용자 쿼리와 함께 AI가 질문에 대답하는 방법과 방식에 대한 지침을 전달합니다.
// File: pages/api/chat.js
import { z } from 'zod'
import { PromptTemplate } from 'langchain/prompts'
import { RetrievalQAChain } from 'langchain/chains'
import { OutputFixingParser, StructuredOutputParser } from 'langchain/output_parsers'
// Load the trained model
// ...
// Create a prompt specifying for OpenAI what to write
const outputParser = StructuredOutputParser.fromZodSchema(
z.object({
answer: z.string().describe('answer to question in HTML friendly format, use all of the tags wherever possible and including reference links'),
}),
)
// ...
// Create an instance of output parser class to help refine the response of OpenAI
const outputFixingParser = OutputFixingParser.fromLLM(model, outputParser)
// Create a prompt specifying for OpenAI how to process on the input
const prompt = new PromptTemplate({
template: `Answer the user's question as best and be as detailed as possible:\n{format_instructions}\n{query}`,
inputVariables: ['query'],
partialVariables: {
format_instructions: outputFixingParser.getFormatInstructions(),
},
})
// Pass the prompt to the query with the model to OpenAI API
const chain = RetrievalQAChain.fromLLM(model, vectorStore.asRetriever(), prompt)- 3.3:스트림 및 캐시 응답
Upstash Redis로 응답을 캐시하기 위해 UpstashRedisCache을 사용합니다. LangChain의 캐시 라이브러리. 기존 Redis 인스턴스를 클라이언트로 전달하고 캐싱 핸들러를 ChatOpenAI에 전달합니다. 응답이 전달되면 이를 캐시하는 데 사용하는 래퍼:
// File: pages/api/chat.js
import { redis } from '@/lib/redis'
import { ChatOpenAI } from 'langchain/chat_models/openai'
import { UpstashRedisCache } from 'langchain/cache/upstash_redis'
// Load the trained model
// ...
// Create Upstash caching
const upstashRedisCache = new UpstashRedisCache({ client: redis })
// A flag to detect if response was not cached
let doesToken = false
const model = new ChatOpenAI({
// Enable streaming to return responses to user as quickly possible
streaming: true,
// Cache responses using Upstash Redis cache client
cache: upstashRedisCache,
callbacks: [
{
handleLLMNewToken(token) {
// Set the flag to true if we receive stream from OpenAI
doesToken = true
// Stream the token to the user
res.write(token)
},
},
],
})
// Create a LLM QA Chain
// ...
// Store the output to refer to in case cached
const chainOutput = await chain.call({ query: req.body.input })
// If no tokens received implies that the content is cached
// Return the cached response as is
if (!doesToken) return res.status(200).send(chainOutput.text)정말 많이 배웠습니다! 이제 모든 작업이 완료되었습니다.
Fly.io에 배포
저장소에는 특히 다음과 관련된 Fly.io용 기본 설정이 함께 제공됩니다.
- 도커파일
- fly.toml
- .dockerignore
배포하려면 Fly.io에 계정이 필요합니다. 계정이 있으면 프로젝트의 루트 폴더에서 다음 명령을 실행하여 Fly.io에서 앱을 생성할 수 있습니다:
# Create an app based on the baked-in configuration in your account
# This will result only in the change of app name in existing fly.toml
fly launch👇🏻
를 통해 배포하세요.# Deploy the app based on the configuration created above
fly deploy이제 배포가 완료되었습니다! 네, 그게 전부였습니다.
결론
결론적으로, 이 프로젝트는 필요에 따라 확장되는 서비스(예:Upstash)를 사용하면서 OpenAI 응답 캐싱, 속도 제한 및 모델 교육을 위한 예약된 API 요청을 구현하는 귀중한 경험을 제공했습니다.
Next.js , Redis , TailwindCSS , LangChain , Serverless Scheduling