입력할 때 검색 상자에 단어가 어떻게 추천되는지 본 적이 있나요? 알고 보니 이러한 제안 중 대부분은 단순한 알파벳 순서로 표시되며 별로 도움이 되지 않습니다.
하지만 시간이 지남에 따라 검색창이 더 똑똑해질 수 있다면 어떨까요?
사람들이 실제로 무엇을 클릭하는지 알아보고 가장 인기 있는 결과를 먼저 표시하시겠습니까?
우리가 만들 항목은 다음과 같습니다.
Redis Sorted Set가 사용자 행동을 학습하여 시간이 지남에 따라 더욱 정확해지는(인기 결과를 먼저 표시하는) 지능형 자동 완성 시스템을 어떻게 강화할 수 있는지 살펴보겠습니다.
스마트 자동완성 시스템의 아이디어
기본 검색창에서는 접두어 일치라는 방법을 사용하여 먼저 표시할 결과를 결정합니다.
입력하면 A-Z 순서로 일치 항목이 표시됩니다. 사람들이 실제로 어떤 결과를 가장 많이 클릭하는지는 중요하지 않습니다.
우리는 이를 더욱 스마트하게 만들 예정입니다. Google 검색창은 사람들이 무엇을 선택하는지 학습합니다. . 사람들이 검색 결과를 클릭하면 다음번에는 해당 결과가 먼저 표시됩니다.
이는 가장 인기 있는 결과를 자동으로 상단에 표시함으로써 시간이 지남에 따라 검색 기능이 더욱 향상되고 유용해짐을 의미합니다.
이것이 검색 애플리케이션에 중요한 이유
영화 검색 애플리케이션을 생각해 보세요. 사용자가 "int"를 입력하는 경우입니다. 다음 내용을 볼 수 있습니다:
- "인터셉터"
- '고속도로 60번'
- '인터스텔라'
"전통적인" 시스템에서는 이러한 문자가 알파벳순으로 표시됩니다. 그러나 사용자가 지속적으로 "인터스텔라"를 클릭하는 경우 자동 완성 추천 항목의 상단에 표시하고 싶습니다.
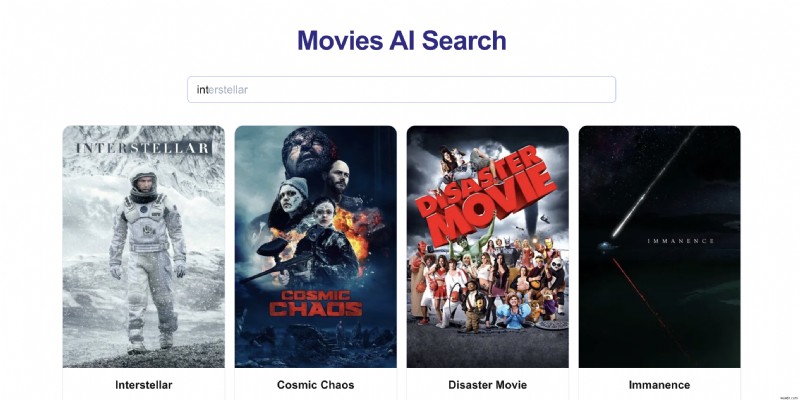
이 스마트 순위 시스템은 다음과 같은 경우에 매우 적합합니다:
- 스트리밍 서비스 Netflix나 YouTube와 같이 사람들이 가장 많이 시청하는 콘텐츠를 보여줍니다.
- 온라인 상점 검색 시 인기상품을 먼저 보여드리기 위해
- 고객센터 사람들이 묻는 가장 일반적인 질문을 보여줍니다.
- 검색 기능이 있는 모든 웹사이트 대부분의 사람들이 무엇을 먼저 클릭하는지 보여주기 위해
Redis 정렬 세트 이해
Redis Sorted Set이 자동 완성 시스템을 구축하는 데 왜 좋은지 알아보겠습니다.
Redis 정렬 세트는 다음과 같은 스마트 목록과 같습니다.
- 각 항목은 고유합니다(예:세트)
- 각 항목에는 점수가 있습니다(주문용)
- 점수에 따라 항목을 빠르게 정렬할 수 있습니다.
자동 완성 시스템에서는 두 가지 정렬 세트를 사용합니다:
- 텍스트 접두사와 일치하는 항목(예:"int"는 "interstellar"와 일치)
- 각 제안의 인기를 추적하기 위한 또 다른 방법
이 두 세트는 함께 작동하여 사용자가 입력할 때 가장 관련성이 높은 결과를 제안합니다.
재단:알파벳순
Redis 정렬 세트는 모든 구성원이 동일한 점수를 가질 때 알파벳 순서를 유지합니다. 이는 다음과 같은 기능을 제공하므로 검색 제안을 작성하는 데 적합합니다.
- 모든 접두사 저장 단일 데이터 구조에서 검색 가능한 용어
ZRANK사용 O(log N) 시간에 접두사의 시작 위치를 찾으려면ZSCAN사용 해당 위치에서 시작하는 모든 일치 항목을 효율적으로 검색합니다ZMSCORE사용 각 경기의 인기 점수를 얻으려면ZINCRBY사용 각 경기의 인기 점수를 높이려면
간단한 예를 살펴보겠습니다. 검색 시스템에 영화 "INTERSTELLAR"를 추가하면 다음과 같이 분류됩니다.
- 점수:0, 회원:"I"
- 점수:0, 회원:"IN"
- 점수:0, 회원:"INT"
- 점수:0, 회원:"INTE"
- 점수:0, 멤버:"INTER"
- 점수:0, 회원:"INTERSTELLAR$Interstellar"(표시 형식으로 전체 항목)
$를 어떻게 사용하는지 알아보세요. 검색 버전을 디스플레이 버전에서 분리하려면 어떻게 해야 하나요? 이렇게 하면 사용자가 대문자나 소문자에 대해 걱정하지 않고 검색할 수 있지만 영화 제목은 정확히 어떻게 표시되어야 하는지 표시됩니다.
데이터 저장 방법
자동 완성 작업을 수행하기 위해 두 개의 Redis 정렬 세트를 사용합니다:
1. 영화 제목 목록
movies라는 정렬된 집합을 추적해 보겠습니다. . 영화를 빨리 찾는 데 도움이 되는 사전이라고 생각하세요. 누군가 "int"를 입력하면 해당 문자로 시작하는 모든 영화를 즉시 찾을 수 있습니다.
"int"의 첫 번째 발생은 ZRANK에서 발견됩니다. 그런 다음 해당 위치에서 와일드카드 INT*$*를 사용하여 전체 영화 이름을 시작합니다. 가져오게 됩니다.
2. 인기 영화 목록
movie-popularity라는 정렬된 집합도 추적해 보겠습니다. . 이것이 "인기 영화" 목록입니다.
누군가 검색 결과에서 영화를 클릭할 때마다 ZINCRBY를 사용하여 점수를 올려 해당 영화의 인기가 높아집니다. . 가장 많이 클릭한 영화가 향후 검색에서 가장 먼저 표시됩니다.
이는 Netflix가 인기 영화를 보여주는 것과 같습니다. 더 많은 사람들이 시청할 수록 추천 항목에 더 많이 표시됩니다.
우리의 경우 INT*$*와 정확히 일치하는 항목을 찾은 후 , 우리는 movie-popularity에 가서 점수를 확인합니다. 가장 인기 있는 것을 얻으려면.
알고리즘 흐름
graph TD
A[User types 'int'] --> B[ZRANK: Find lexicographic position of 'INT']
B --> C[ZSCAN: Retrieve matches starting from position (movies set)]
C --> D[Filter: Extract complete terms containing '$']
D --> E[ZMSCORE: Get popularity scores for all matches (movie-popularity set)]
E --> F[Rank: Return highest-scored suggestion]
G[User selects suggestion] --> H[ZINCRBY: Increment popularity score]
H --> I[Future searches: Higher scored items rank first]
I --> A사용자가 추천 항목을 검색하고 클릭하면 시스템이 학습하고 개선됩니다. 더 많은 사람들이 사용할수록 가장 관련성이 높은 제안을 먼저 표시하는 것이 더 좋습니다.
자동완성 시스템을 구축해보자
이 자동 완성 시스템을 단계별로 구축하는 방법을 살펴보겠습니다. 아주 간단하게 설명하겠습니다!
1단계:Redis에 영화 제목 추가
먼저 나중에 검색할 수 있도록 영화 제목을 Redis에 추가해야 합니다. 데이터베이스나 텍스트 파일 등 어디서나 간단한 영화 목록으로 시작할 수 있습니다. 추가하는 방법은 다음과 같습니다.
import { Redis } from "@upstash/redis";
const redis = new Redis({
url: process.env.UPSTASH_REDIS_URL!,
token: process.env.UPSTASH_REDIS_TOKEN!,
});
// Example: your list of titles
const titles = [
"Interceptor",
"Interstate 60",
"Interstellar",
// ... more titles
];
async function populateAutocomplete() {
// Insert prefixes and full titles into the 'movies' sorted set
for (const title of titles) {
let term = title.toUpperCase();
let terms = [];
for (let i = 1; i < term.length; i++) {
terms.push({ score: 0, member: term.substring(0, i) });
}
terms.push({ score: 0, member: term });
terms.push({ score: 0, member: term + "$" + title });
await redis.zadd("movies", ...terms);
}
// Insert all titles into the 'movie-popularity' sorted set for popularity tracking
await redis.zadd(
"movie-popularity",
...titles.map((title) => ({
score: 0,
member: title.toUpperCase(),
})),
);
}
populateAutocomplete();위 코드의 기능을 분석해 보겠습니다.
-
각 영화 제목에 대해 다음을 저장합니다:
- 가능한 모든 부분 일치(예:"Interstellar"의 경우 "INT", "INTE", "INTER")
- 전체 제목 자체
- 표시용 형식의 버전
-
또한 조회수 0부터 시작하여 각 영화의 인기를 추적하는 별도의 목록을 만듭니다.
이는 사용자가 입력하고 클릭하는 내용을 통해 학습할 때 스마트한 제안을 표시하는 데 필요한 모든 것을 제공합니다.
2단계:가장 적합한 항목 찾기
다음으로, 이러한 영화 제목을 검색하여 일치하는 항목을 찾는 방법을 살펴보겠습니다. 우리 matchQuery 함수는 모든 어려운 작업을 수행합니다:
export const matchQuery = async (query: string): Promise<string | null> => {
const upperQuery = query.toUpperCase();
// Step 1: Find starting position using lexicographic ordering
let rank = await redis.zrank("movies", upperQuery);
if (rank === null) return null;
// Step 2: Efficiently scan for matches from that position
const scanResult = await redis.zscan("movies", rank, {
match: `${upperQuery}*$*`,
count: 1000,
});
// Step 3: Extract complete entries and get their popularity scores
const completeTitles = scanResult[1].filter(
(el, idx) => idx % 2 === 0 && el.includes("$"),
);
const baseNames = completeTitles.map((title) => title.split("$")[0]);
const scores = await redis.zmscore("movie-popularity", baseNames);
// Step 4: Return the highest-scored (most popular) match
const maxScore = Math.max(...scores);
const bestMatchIndex = scores.indexOf(maxScore);
return completeTitles[bestMatchIndex].split("$")[1];
};사용자 선택으로부터 배우기
누군가 영화 제목을 선택하면 점수에 1점을 추가합니다. 포인트가 더 많은 영화는 제안 목록에서 더 높은 곳에 표시됩니다. 정말 간단해요!
시스템은 사람들이 실제로 무엇을 선택하는지 추적하여 시간이 지남에 따라 더욱 똑똑해집니다.
const onSubmit = async (title: string) => {
// Handle submit logic here
await redis.zincrby("movie-popularity", 1, title.toUpperCase());
};얼마나 빠른가요?
각 작업에 소요되는 시간을 분석하여 이 솔루션이 얼마나 빠른지 살펴보겠습니다.
- Z랭크 :O(log N) - 로그 조회 시간
- ZSCAN :O(log N + M) - 여기서 M은 반환된 요소의 수입니다.
- ZMSCORE :O(N) - 여기서 N은 전체 데이터 세트 크기가 아니라 일치하는 결과의 수입니다.
- ZINCRBY :O(log N) - 로그 복잡도에 따른 원자 증가
더 많은 영화 제목을 추가해도 성능은 일관되게 유지됩니다.
결론:우리가 함께 이룬 것
AI 없이도 시간이 지나면서 더 좋아지는 스마트 검색창을 구축하는 방법을 배웠습니다!
자동완성은 사람들이 무엇을 선택하는지 학습하고 해당 정보를 사용하여 더 나은 제안을 표시합니다.
빠르고 간단하며 더 많은 사람들이 사용할수록 더욱 유용해집니다.
Redis 최적화 전략에 대해 이야기하고 싶거나 자신의 구현을 공유하고 싶으십니까? Discord에 참여하세요!