AI 연구 에이전트 소개
학술 연구는 빠르게 진행됩니다. arXiv 및 기타 사전 인쇄 서버에 매일 새로운 논문이 게재됩니다. 수동으로 유지하는 것은 부담스러울 수 있습니다. 이 가이드에서는 AI 연구 보조자를 구축하겠습니다. 그:
- 연구원의 자연어 질문을 이해합니다
- arXiv 초록의 벡터 데이터베이스에서 가장 관련성이 높은 논문을 찾습니다.
- 주요 통찰력을 요약하고 질문에 대한 답을 설명합니다.
- 자세한 내용을 읽을 수 있도록 직접 PDF 링크 제공
우리는 Mastra를 통해 이를 달성할 것입니다. , AI 에이전트 구축을 위한 오픈소스 TypeScript 프레임워크 및 Upstash 서버리스 Redis 및 Vector 스토리지용. 다음은 AI 연구에 초점을 맞춘 기사 에이전트의 라이브 데모입니다. 사용해 볼 수 있도록 Vercel에 배포되었습니다.
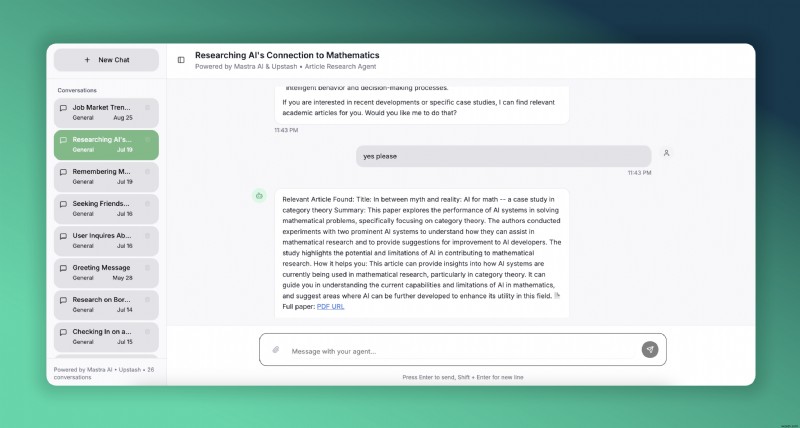
마스트라란 무엇인가요?
Mastra는 프로덕션급 AI 에이전트를 간단하게 생성할 수 있게 해주는 배터리 포함 프레임워크입니다.
- 에이전트 및 워크플로 — 에이전트, 도구 및 다단계 워크플로 구성
- 검색 증강 생성(RAG) - 내장 메모리 및 벡터 저장소
- 다중 LLM - OpenAI, Claude 등과 함께 작동합니다.
Upstash Redis를 메모리로 사용하는 에이전트를 생성하겠습니다. 또한 이전에 Upstash Vector 데이터베이스에 포함시켰던 관련 연구 기사를 찾는 도구도 갖게 됩니다.
더 자세한 내용은 Mastra 문서를 확인하세요.
프로젝트의 기술 스택
- Mastra 프레임워크 AI 에이전트 및 도구 생성
- Upstash Redis 상담원에게 대화 기억을 주기 위해
- 업스태시 벡터 연구 논문 초록의 임베딩을 저장하기 위해
- Next.js 및 Vercel 웹 애플리케이션 구축 및 배포
또한 Upstash Ratelimit를 사용하여 데모 애플리케이션에 대한 요청을 제한할 것입니다.
구현 연습
이 애플리케이션을 구축하려면 Mastra 서버와 웹 애플리케이션이라는 두 가지 주요 구성 요소를 생성해야 합니다. 동일한 프로젝트에 있을 수 있지만 별도로 유지하는 것이 더 깔끔합니다. Mastra 서버부터 시작해 보겠습니다.
Mastra 프로젝트 생성
새로운 Mastra 프로젝트를 생성하려면 터미널에서 다음 명령을 실행하세요.
npm create mastra@latest몇 가지 질문이 있을 것입니다. 이 프로젝트에서는 기본 설정이 괜찮습니다.
에이전트 및 도구 생성
에이전트 구성의 첫 번째 단계는 이름, 목적 및 도구를 정의하는 것입니다. 주어진 작업을 잘 수행할 수 있는 언어 모델을 선택하는 것도 중요합니다. 이 프로젝트에는 하나의 에이전트와 하나의 도구가 있습니다.
export const articleAgent = new Agent({
name: "articleAgent",
instructions: instruction,
model: openai('gpt-4o'),
tools: { articleQueryTool },
memory: memory
});
에이전트 구성은 위에 표시된 것처럼 간단합니다. articleAgent를 정의합니다. instruction 포함 (시스템 프롬프트 역할을 함) 전용 tools , model , 또 다른 중요한 구성요소:memory .
요원의 기억
Mastra는 상담원에게 채팅 기록과 의미 회상 기능을 모두 제공합니다. 저장 공간에 메모리를 유지함으로써 상담원은 보다 개인화되고 정확한 답변을 제공할 수 있습니다. 에이전트의 메모리 구성을 살펴보겠습니다.
export const memory = new Memory({
storage: myUpstashStore,
options: {
lastMessages: 10,
semanticRecall: false,
threads: {
generateTitle: true
}
}
});
채팅 기록을 활성화하기 위해 Upstash Redis를 스토리지 옵션으로 사용합니다. UpstashStore로 초기화합니다. MastraStorage을 확장하는 객체 , Mastra 에이전트와 원활하게 작동하도록 보장합니다.
export const myUpstashStore = new UpstashStore({
url: process.env.UPSTASH_REDIS_REST_URL!,
token: process.env.UPSTASH_REDIS_REST_TOKEN!,
});우리는 이전에 에이전트에 의미론적 회상 기능을 추가하여 현재 컨텍스트와 관련된 이전 메시지를 고려할 수 있다고 언급했습니다. 이를 위해 에이전트에는 메시지를 처리하기 위한 벡터 데이터베이스와 임베더가 필요합니다. 공개 데모는 개인적인 용도가 아니며 여러 스레드에 걸쳐 메시지를 기억할 필요가 없으므로 이 기능을 사용하지 않지만 다음과 같이 구현할 수 있습니다.
export const myUpstashVector = new UpstashVector({
url: process.env.UPSTASH_VECTOR_REST_URL!,
token: process.env.UPSTASH_VECTOR_REST_TOKEN!,
});
export const memory = new Memory({
storage: myUpstashStore,
vector: myUpstashVector,
embedder: openai.embedding("text-embedding-3-small"),
options: {
lastMessages: 10,
semanticRecall: {
topK: 3,
messageRange: 2,
scope: 'resource'
},
threads: {
generateTitle: true
}
}
});의미적 회상 구성에서 topK 검색할 유사한 메시지 수, messageRange를 지정합니다. 각 일치 항목에 포함할 주변 컨텍스트의 양을 정의하고 범위를 설정합니다. 'resource'로 지정하면 에이전트가 'resource'라는 사용자와 연결된 모든 스레드에서 검색하게 됩니다. 이 크로스 스레드 메모리는 Upstash에서 사용할 수 있는 강력한 기능입니다.
도구
도구를 만드는 것은 에이전트를 만드는 것만큼 간단합니다. 에이전트에 도구 기능이 필요할 때 실행할 이름, 설명, 입력 및 출력 스키마, 함수를 제공합니다.
export const articleQueryTool = createTool({
id: 'get-relevant-article',
description: 'Get relevant article information',
inputSchema: z.object({
question: z.string().describe('the question about the field'),
}),
outputSchema: z.object({
bestOption: z.object({
abstract: z.string().describe('the abstract of the article'),
title: z.string().describe('the title of the article'),
pdfUrl: z.string().describe('the PDF URL of the article')
})
}),
execute: async ({ context }) => {
return await querySimilar(context.question);
},
});우리는 Zod를 사용하여 입력 및 출력 스키마의 유효성을 검사합니다. 이는 일관된 응답을 유지하고 LLM의 잠재적 오류를 최소화하는 데 도움이 됩니다. 또한 도구가 사용할 기능을 정의합니다. 우리 도구는 arXiv API를 통해 정기적으로 업데이트되고 Upstash Vector 데이터베이스에 포함된 대규모 연구 기사 모음을 쿼리합니다.
const querySimilar = async (query: string) => {
const { embedding } = await embed({
value: query,
model: openai.embedding("text-embedding-3-small"),
});
const results = await myMastraUpstashVector.query({
indexName: "arxiv",
queryVector: embedding,
topK: 3,
});
if (results && results.length > 0) {
const bestMatch = results[0];
const metadata = bestMatch.metadata as ArxivPaper;
return {
bestOption: {
abstract: metadata.abstract,
title: metadata.title,
pdfUrl: metadata.pdfUrl
}
};
}
throw new Error("No relevant information found");
}
UpstashVector를 통해 벡터 데이터베이스에서 간단한 작업을 수행할 수 있습니다. MastraVector을 확장하는 인스턴스 . 위에서는 사전에 삽입한 유사한 기사 초록을 쿼리하고 최상의 결과를 도구에 반환합니다. 기사에서와 마찬가지로 쿼리에도 동일한 임베딩 모델을 사용한다는 점에 유의하세요. 기사 삽입에 대해서는 나중에 자세히 설명하겠습니다.
마스트라 인스턴스
export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
deployer: new VercelDeployer()
});
사용할 에이전트를 지정하고 Mastra 개체가 준비되었습니다. 또한 인메모리 스토리지 이상의 데이터를 유지하기 위한 스토리지도 제공합니다. 사용 가능한 배포 구성 중에서 선택할 수도 있습니다. Vercel을 사용하여 배포하겠습니다.
create-mastra-app의 기본 옵션 사용 , 필요한 파일 구조가 이미 있습니다:
.
└── mastra
├── agents
│ └── index.ts
├── tools
│ └── index.ts
└── index.ts
배포하기 전에 환경 변수라는 한 단계만 남았습니다.
OPENAI_API_KEY=
UPSTASH_VECTOR_REST_URL=
UPSTASH_VECTOR_REST_TOKEN=
UPSTASH_REDIS_REST_URL=
UPSTASH_REDIS_REST_TOKEN=
이것을 .env.local에 넣으세요 로컬 개발용 파일을 다운로드하여 배포 환경에 추가하세요.
이제 Mastra 서버를 구축하고 배포할 준비가 되었습니다.
npm run build && vercel --prodVercel 문서를 확인하여 배포 방법을 확인할 수 있습니다.
개발하는 동안 Mastra Playground를 사용하여 서버의 출력을 볼 수 있습니다. 다음 명령을 실행하세요:
npm run dev그러면 에이전트와 채팅하고, 명시적으로 도구를 실행하고, 서버 기능을 탐색할 수 있는 웹 인터페이스에 대한 링크가 제공됩니다.
이제 애플리케이션의 다른 부분에 대해 이야기할 차례입니다.
Next.js 서버
Mastra 서버가 설정되면 UI, Mastra 서버와의 통신, arXiv API와 통신하고 Upstash Vector에 요약을 포함하는 기사 서비스라는 세 가지를 처리해야 합니다. Mastra에는 서버 기능을 노출하는 클라이언트 SDK가 있습니다. 이를 통해 에이전트, 도구, 메모리 등에 액세스할 수 있습니다. 사용법은 간단하지만 몇 가지 예를 공유하겠습니다. 자세한 내용은 여기에서 설명서를 확인하세요. Next.js 프로젝트에서는 간단히 클라이언트 SDK를 설치하여 사용할 수 있습니다.
npm install @mastra/client-js@latest
코드에서 MastraClient의 인스턴스를 만듭니다. 프로젝트에 사용하세요.
import { MastraClient } from "@mastra/client-js";
export const mastra_sdk = new MastraClient({
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API!,
retries: 3,
});
NEXT_PUBLIC_MASTRA_API을 설정해야 합니다. Mastra 서버 주소로. 로컬에서 개발하는 경우 localhost이 됩니다. 주소. 3000에서 포트 충돌이 발생할 수 있으므로 , 다음과 같이 로컬로 실행할 때 Mastra 서버의 구성을 변경할 수 있습니다:
export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
server: {
port: 4111,
timeout: 10000,
}
});
이제 npm run dev를 사용하여 로컬에서 Mastra 서버를 실행하면 , 포트 4111에서 제공됩니다. . NEXT_PUBLIC_MASTRA_API를 설정할 수 있습니다 http://localhost:4111로 Next.js 프로젝트를 로컬에서 실행할 때
Mastra의 클라이언트 SDK를 어떻게 사용할 수 있는지 살펴보겠습니다.
export const MASTRA_CONFIG = {
resourceId: process.env.NEXT_PUBLIC_RESOURCE_ID || "articleAgent",
agentId: "articleAgent",
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API || "http://localhost:4111",
retries: 3,
}; // this is exported in another file so that we can use it anywhere in the codebase.
// Get your agent and simply stream your response through your agent object.
const agent = mastra_sdk.getAgent(MASTRA_CONFIG.agentId);
const response = await agent.stream({
messages: [message],
resourceId: MASTRA_CONFIG.resourceId,
threadId: threadId
});도구와 에이전트를 얻을 수 있으며 일단 확보하고 나면 클라이언트 SDK를 통해 실제 개체로 할 수 있는 거의 모든 작업을 수행할 수 있습니다.
이 데모 프로젝트를 공개적으로 게시할 예정이므로 에이전트에 과도한 부하를 주지 않는 것이 중요합니다. 이것이 Upstash Ratelimit가 들어오는 곳입니다. 모든 스트림 요청 전에 우리는 사용자가 속도 제한이 있는지 확인합니다. 속도 제한기를 구성하려면 Upstash Redis가 필요합니다. Mastra 에이전트에 대해 가지고 있는 것과 동일한 Redis 데이터베이스를 사용할 수 있습니다.
import { Ratelimit } from '@upstash/ratelimit';
import { Redis } from '@upstash/redis';
// Using the same Redis DB across the project
export const rateLimit = new Ratelimit({
redis: new Redis({
url: process.env.UPSTASH_REDIS_MEMORY_URL!,
token: process.env.UPSTASH_REDIS_MEMORY_TOKEN!
}),
limiter: Ratelimit.slidingWindow(10, '10s'),
prefix: 'upstash-ratelimit',
});
// Fetch the below function before every stream.
export async function isRateLimited(id: string): Promise<boolean> {
const { success } = await rateLimit.limit(id);
return !success;
}이렇게 하면 엔드포인트에 과부하가 걸리지 않게 됩니다.
Mastra로 채팅 에이전트를 생성할 때 Mastra 스레드 생성의 일부 기능을 아는 것이 도움이 될 수 있습니다. 에이전트의 메모리를 구성할 때 generateTitle를 설정했다는 점을 기억하세요. true으로 threads에서 개체. 이를 통해 Mastra는 새로 생성된 스레드에 대해 자동으로 제목을 생성합니다. 그러나 여기에 문제가 있습니다. 스레드를 명시적으로 생성하는 것이 가능하지만 자동 제목 생성은 그런 식으로 실행되지 않습니다. 일반적으로 새로운 스레드를 생성하는 방법은 다음과 같습니다.
const thread = await mastraClient.createMemoryThread({
title: "New Conversation",
metadata: { category: "support" },
resourceId: "resource-1",
agentId: "agent-1",
});
그러나 수동으로 설정하기 때문에 제목을 자동으로 생성하는 에이전트의 기능이 사라집니다. title에서 나가기 필드 비어도 작동하지 않습니다. 이 경우 Playground가 수행하는 작업을 확인할 수 있습니다. 개발 중에 서버의 기능을 경험하기 위해 Mastra에서 제공하는 Playground를 기억하시나요? 브라우저 개발자 도구의 네트워크 탭을 살펴보면 새 스레드가 생성될 때 실제로 스레드를 생성하기 위한 API 요청을 보내지 않는다는 것을 알 수 있습니다. 대신 첫 번째 메시지를 제출할 때까지 기다립니다. 그런 다음 새로 생성된 스레드 ID로 스트림 요청을 보냅니다. 이는 Mastra에게 이 ID를 가진 스레드가 존재하지 않음을 알려주므로 스레드를 생성해야 하며, generateTitle인 경우 true이면 첫 번째 메시지를 기반으로 제목을 생성합니다.
우리 프로젝트의 마지막 구성 요소인 arXiv 기사를 계속 진행하겠습니다.
arXiv 기사
arXiv는 다양한 분야의 약 240만 개에 달하는 연구 논문을 모아 놓은 오픈 액세스 아카이브입니다. articleQueryTool arXiv API를 통해 가져온 기사가 제공되는 Upstash 벡터 데이터베이스를 쿼리합니다. API는 사용이 간단합니다. 자세한 내용은 여기에서 확인하실 수 있습니다.
우리 프로젝트에서는 매일 기사를 가져오고 저장합니다. 서버가 처음 실행되면 지정된 카테고리에서 약 30,000개의 기사를 가져옵니다. 그 후에는 전날 게시된 새 기사를 가져옵니다. 기사 카테고리를 지정하고 초기 대규모 배치를 가져올지 여부를 지정하기 위해 해당 환경 변수를 설정합니다. arXiv의 분류 체계를 사용하여 원하는 기사 카테고리를 쉼표로 구분하여 제공해야 합니다. 여기에서 카테고리를 찾아보실 수 있습니다.
CATEGORIES=cs.AI
RUN_BEGINNING_STACK=false보다 포괄적인 데이터베이스를 원한다면 arXiv의 대량 데이터 액세스를 사용할 수 있습니다. 이것이 없으면 API 쿼리당 기사가 30,000개로 제한되며 이는 우리 목적에 충분합니다.
arXiv에 대한 간단한 쿼리는 다음과 같습니다:
const categories = process.env.CATEGORIES?.split(',') || []; // Get the desired categories and split them for the query.
const searchQuery = categories.length === 1 ? `cat:${categories[0]}` : `(${categories.map(c => `cat:${c}`).join(" OR ")})`;
const query = `search_query=${searchQuery}&sortBy=submittedDate&sortOrder=descending`;
const url = `http://export.arxiv.org/api/query?${query}`;
const response = await axios.get(url); // Make the API call with the constructed URL.우리는 매일 최신 기사를 가져오고 초기 스택을 가져오기 위해 비슷한 호출을 합니다.
기사를 가져온 후 이를 정규화하고 Upstash Vector에 저장하기 위해 삽입합니다. 이는 Mastra 도구가 사용하는 것과 동일한 벡터 데이터베이스여야 합니다. "정규화"란 가져온 기사를 표준 ArxivPaper으로 구문 분석하는 것을 의미합니다. 코드베이스 전체에서 사용할 유형입니다.
export interface ArxivPaper {
id: string;
title: string;
abstract: string;
authors: string[];
published: string;
pdfUrl: string;
category: string;
}// The type for our articles, across our codebase.
async function storeAbstracts(papers: ArxivPaper[]) {
const embeddingModel = openai.embedding("text-embedding-3-small"); // The same model used to query on the Mastra side.
const embeddings = await embedArticles(papers, embeddingModel)
// Put the embeddings into the required form with their metadata.
const vectorsToUpsert = getVectorsToUpsert(embeddings, papers)
for (let j = 0; j < vectorsToUpsert.length; j++) {
await vectorStore.upsert(vectorsToUpsert[j], { namespace: "arxiv" }); // Upsert the embeddings with their metadata to Upstash Vector.
}
}최신 연구를 통해 데이터베이스를 최신 상태로 유지하기 위해 예약된 작업 실행을 위해 Upstash QStash를 구현합니다. Vercel에 배포한 경우 처리 간격이 길어질 때 발생할 수 있는 기능 시간 초과를 방지해야 합니다. 우리는 서버에 공개 API 엔드포인트를 노출하여 QStash 인스턴스가 일일 데이터베이스 업데이트 기능을 안정적으로 트리거할 수 있도록 함으로써 이 문제를 해결합니다.
// src/app/api/arxiv_reneval/route.ts
import { verifySignatureAppRouter } from "@upstash/qstash/nextjs"
import { fetchAndUpsertYesterday} from "@/services/arxiv"
async function handler(request: Request) {
console.log("Fetching and upserting yesterday's papers...")
await fetchAndUpsertYesterday()
console.log("Fetching and upserting yesterday's papers completed")
return Response.json({ success: true })
}
export const POST = verifySignatureAppRouter(handler)Upstash 콘솔을 통해 매일 오전 6시(UTC)에 이 엔드포인트에 대한 요청을 자동으로 트리거하도록 스케줄러를 구성할 수 있습니다.
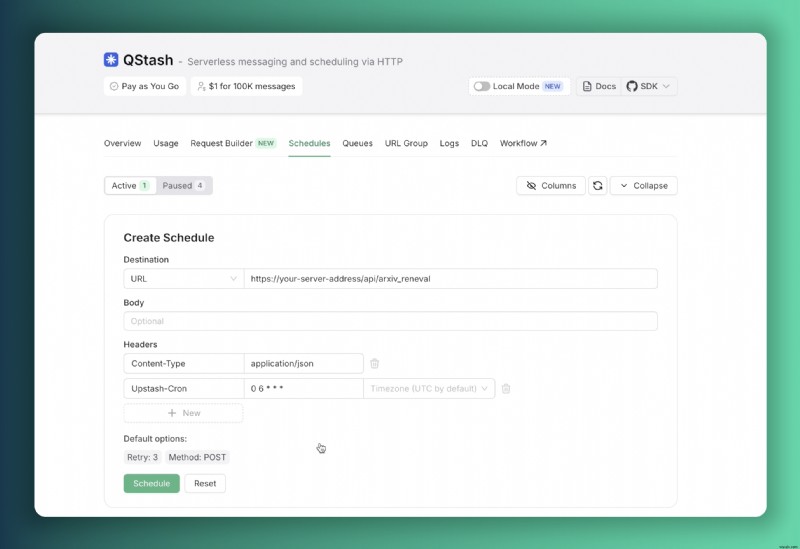
이러한 스케줄러 구성을 통해 당사 서버는 매일 아침 자동화된 데이터베이스 업데이트를 수행하여 지속적인 데이터 업데이트를 보장합니다.
또한 QStash 인스턴스에 대한 자격 증명을 제공해야 하며 모든 필수 env 변수는 예제 env 파일에 제공됩니다.
거의 그 정도입니다. 원한다면 코드를 가지고 시험해 볼 수 있습니다. 리포지토리를 포크하고 개발을 시작하세요. 여기에서 Mastra 부분의 저장소로 이동하고 여기에서 다른 저장소로 이동할 수 있습니다. 포크한 후:
- 로컬 컴퓨터에 복제하세요.
- 환경 변수를 입력합니다(예:
.env) 파일이 제공됩니다). - 별도의 터미널에서 두 프로젝트의 루트 디렉터리로 이동합니다.
- 다음 명령을 실행하세요:
npm install
npm run dev이제 http://localhost:3000에서 애플리케이션을 볼 수 있습니다.
Mastra를 사용하면 RAG, 워크플로우 및 네트워크와 같은 다른 템플릿을 활용하여 더 복잡한 것을 구축할 수 있습니다. 이 모든 목적에서 기억과 저장이 중요한 역할을 하는 것 같습니다. 업스태쉬가 빛을 발하는 곳이 바로 여기입니다.