이 게시물에서는 Upstash Vector, Upstash Redis, Hugging Face Inference API, Replicate LLAMA-2-70B Chat 모델 및 Vercel을 사용하여 오픈 소스 사용자 정의 콘텐츠 RAG Chatbot을 구축한 방법에 대해 설명합니다. Upstash Vector는 벡터를 삽입하고 쿼리하여 각 사용자 메시지에 대한 관련 컨텍스트를 동적으로 생성 또는 업데이트하는 데 도움이 되었으며 Upstash Redis는 챗봇 대화를 저장하는 데 도움이 되었습니다.
전제조건
다음이 필요합니다:
- Node.js 18 이상
- Upstash 계정
- Hugging Face 계정
- 복제 계정
- Vercel 계정
기술 스택
Upstash Redis 설정
Upstash 계정을 생성하고 로그인하면 Redis 탭으로 이동하여 데이터베이스를 생성하게 됩니다.
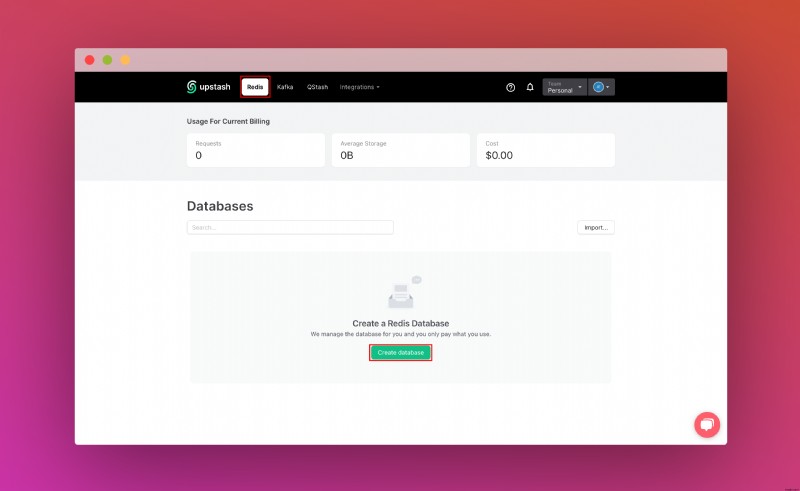
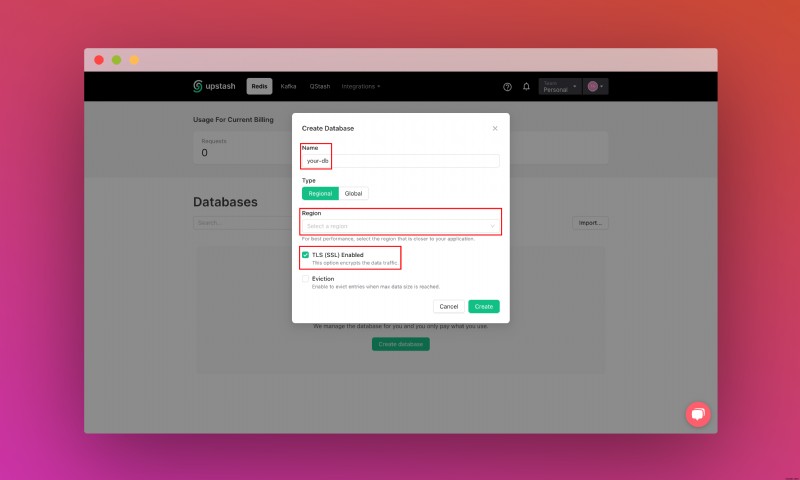
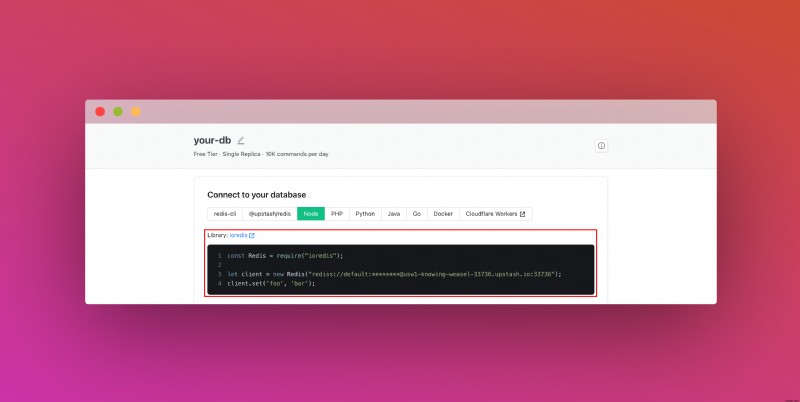
데이터베이스를 생성한 후 세부정보 탭으로 이동합니다. 데이터베이스 연결 섹션을 찾을 때까지 아래로 스크롤합니다. 콘텐츠를 복사하여 안전한 곳에 저장하세요.
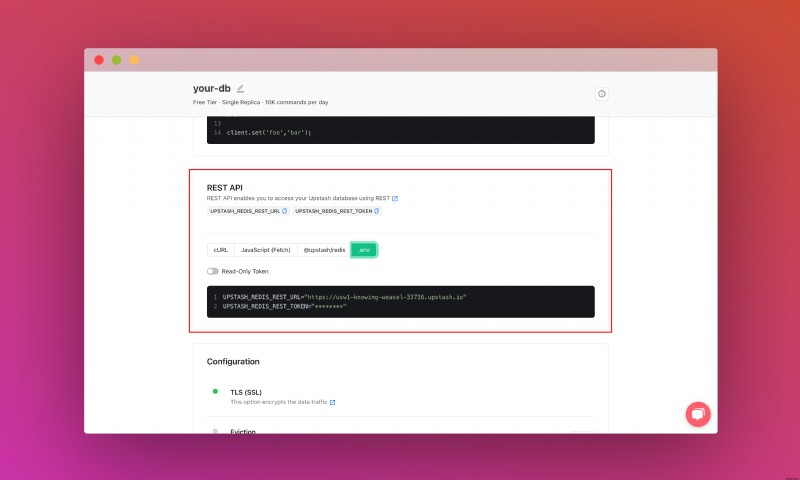
또한 REST API 섹션을 찾을 때까지 아래로 스크롤하고 .env 버튼을 선택합니다. 콘텐츠를 복사하여 안전한 곳에 저장하세요.
Upstash 벡터 설정
Upstash 계정을 생성하고 로그인하면 벡터 탭으로 이동하여 인덱스를 생성하게 됩니다.
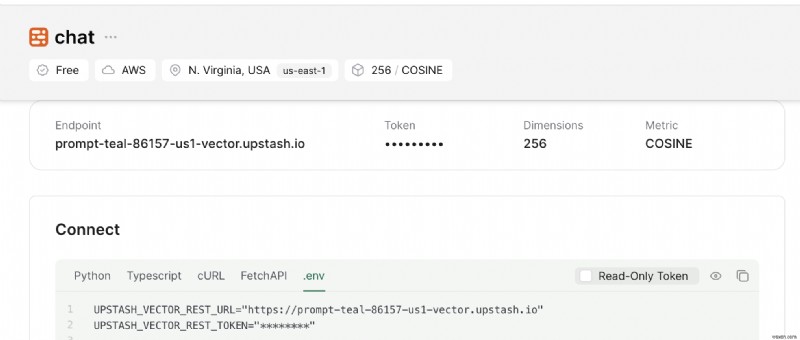
또한 연결을 찾을 때까지 아래로 스크롤하세요. 섹션을 클릭하고 .env를 선택하세요. 버튼. 콘텐츠를 복사하여 안전한 곳에 저장하세요.
프로젝트 설정
설정하려면 앱 저장소를 복제하고 이 튜토리얼에 따라 그 안에 있는 모든 내용을 알아보세요. 프로젝트를 포크하려면 다음을 실행하세요:
git clone https://github.com/rishi-raj-jain/custom-rag-chatbot-upstash-vector
cd custom-rag-chatbot-upstash-vector
pnpm install
저장소를 복제한 후에는 .env를 생성하게 됩니다. 파일. 위 섹션에서 저장한 항목을 추가하게 됩니다.
다음과 같아야 합니다:
# .env
# Obtained from the steps as above
# Upstash Redis URL and Token
UPSTASH_REDIS_REST_URL="https://....upstash.io"
UPSTASH_REDIS_REST_TOKEN="..."
# Upstash Vector URL and Token
UPSTASH_VECTOR_REST_URL="https://...-vector.upstash.io"
UPSTASH_VECTOR_REST_TOKEN="..."
# Replicate API Key
REPLICATE_API_TOKEN="r8_..."
# Hugging Face Inference API Key
HUGGINGFACEHUB_API_KEY="hf_..."이 단계 후에는 다음 명령을 사용하여 로컬 환경을 시작할 수 있습니다:
pnpm dev저장소 구조
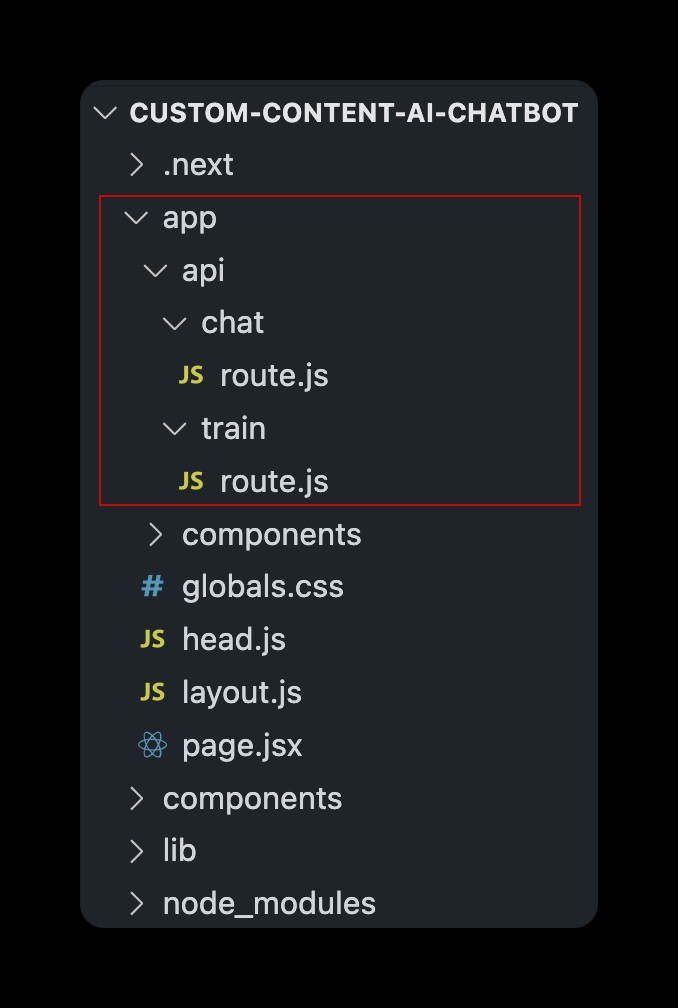
이는 프로젝트의 기본 폴더 구조입니다. 사용자 정의 컨텍스트에서 학습된 AI와 채팅하기 위한 API 경로를 생성하고 upsert로 컨텍스트를 업데이트하는 작업을 다루는 이 게시물에서 추가로 논의될 파일을 빨간색으로 표시했습니다. -기존 인덱스에 벡터를 넣습니다.
Next.js 앱 라우터에서 채팅 경로 설정
이 섹션에서는 app/api/chat/route.js 경로를 설정한 방법에 대해 설명합니다. 서버리스 데이터베이스에서 대화를 동기화하고, 문자열 임베딩을 동적으로 생성하고, 주어진 인덱스에서 관련 벡터를 쿼리하여 컨텍스트를 생성하고, LLAMA-2-70B 채팅 모델을 사용하여 관련 예측을 요청합니다. 단순화를 위해 다음과 같은 부분으로 나누어 보겠습니다.
대화 저장
Upstash Redis에서 진행되는 대화를 캐시하기 위해 Redis 목록을 사용하겠습니다. 사용자로부터 응답하라는 메시지가 들어오면 조건에 따라 챗봇(이전)의 응답을 목록에 푸시합니다. 그런 다음 사용자가 보낸 최신 메시지를 목록에 푸시하여 저장하고 이에 대한 응답을 진행합니다.
// File: app/api/chat/route.js
import { Redis } from '@upstash/redis'
// Instantiate the Upstash Redis
const upstashRedis = new Redis({
url: process.env.UPSTASH_REDIS_REST_URL,
token: process.env.UPSTASH_REDIS_REST_TOKEN,
})
export async function POST(req) {
try {
// the whole chat as array of messages
const { messages } = await req.json()
// assuming user - assistant chat
// add assitant's response to the chat history
if (messages.length > 1) {
await upstashRedis.lpush('unique_conversation_id', JSON.stringify(messages[messages.length - 2]))
}
// add user's request to the chat history
await upstashRedis.lpush('unique_conversation_id', JSON.stringify(messages[messages.length - 1]))
// Proceed to create a response
}최신 메시지 삽입 만들기
주어진 모든 컨텍스트(예:사용자가 제공한 사용자 정의 콘텐츠)에서 사용자의 최신 메시지에 효과적으로 응답하기 위해 기존 인덱스에서 관련 컨텍스트(유사 벡터라고도 함)를 검색하는 데 도움이 되는 임베딩을 생성할 것입니다. LangChain과 함께 Hugging Face Inference API를 사용하여 가장자리에서 API 호출만으로 임베딩을 생성하고 Upstash 벡터 인덱스(여기서는 256)를 회전시키면서 구성한 길이로 얻은 벡터를 잘라낼 것입니다. ).
// File: app/api/chat/route.js
import { HuggingFaceInferenceEmbeddings } from '@langchain/community/embeddings/hf'
// Instantiate the Hugging Face Inference API
const embeddings = new HuggingFaceInferenceEmbeddings()
export async function POST(req) {
try {
// ...
// get the latest question stored in the last message of the chat array
const userMessages = messages.filter((i) => i.role === 'user')
const lastMessage = userMessages[userMessages.length - 1].content
// generate embeddings of the latest question
const queryVector = (await embeddings.embedQuery(lastMessage)).slice(0, 256)
// Proceed to create a response
}최신 메시지를 기반으로 관련 컨텍스트 벡터 검색
메시지당 사용자가 제공한 모든 컨텍스트를 동적으로 가져오는 것은 비용이 많이 드는 작업입니다. 우리는 사용자의 최신 메시지와 관련된 컨텍스트만 사용하고 이를 시스템 프롬프트로 LLAMA-2-70B 채팅 모델에 전달하려고 합니다. 관련 컨텍스트만 가져오기 위해 기존 벡터 세트를 쿼리하여 메타데이터를 포함하여 가장 관련성이 높은 2개의 벡터를 얻고 신뢰도 점수가 70%보다 큰 결과를 필터링합니다.
// File: app/api/chat/route.js
import { Index } from '@upstash/vector'
// Instantiate the Upstash Vector Index
const upstashVectorIndex = new Index()
export async function POST(req) {
try {
// ...
// query the relevant vectors from the embedding vector
const queryResult = await upstashVectorIndex.query({
vector: queryVector,
// get the top 2 relevant results
topK: 2,
// do not include the whole set of embeddings in the response
includeVectors: false,
// include the meta data so that can get the description out of the index
includeMetadata: true,
})
// console.log('The query result came in', queryResult.length)
// using the resulting set of relevant vectors
// filter the one that have score of greater than 70% match
// and get the description we stored while training
const queryPrompt = queryResult
.filter((match) => match.score && match.score > 0.7)
.map((match) => match.metadata.description)
.join('\n')
// console.log('The query prompt is', queryPrompt)
// Proceed to create a response
}예측 컨텍스트가 포함된 프롬프트 LLAMA-2-70B 채팅 모델
이제 관련 컨텍스트를 문자열로 얻었으므로 마지막 단계는 llama-2-70B 채팅 모델이 사용자의 최신 메시지에 응답하도록 하는 것입니다. 우리는 Vercel AI SDK의 experimental_buildLlama2Prompt을 사용합니다. llama-2-70B 채팅 모델에 적합한 프롬프트 형식을 생성하는 방법입니다.
// File: app/api/chat/route.js
import Replicate from 'replicate'
import { experimental_buildLlama2Prompt } from 'ai/prompts'
import { ReplicateStream, StreamingTextResponse } from 'ai'
// Instantiate the Replicate API
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
})
export async function POST(req) {
try {
// ...
const response = await replicate.predictions.create({
// You must enable streaming.
stream: true,
// The model must support streaming. See https://replicate.com/docs/streaming
// This is the model ID for Llama 2 70b Chat
version: '2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1',
// Format the message list into the format expected by Llama 2
// @see https://github.com/vercel/ai/blob/99cf16edf0a09405d15d3867f997c96a8da869c6/packages/core/prompts/huggingface.ts#L53C1-L78C2
input: {
prompt: experimental_buildLlama2Prompt([
{
// create a system content message to be added as
// the llama2prompt generator will supply it as the context with the API
role: 'system',
content: queryPrompt.substring(0, Math.min(queryPrompt.length, 2000)),
},
// also, pass the whole conversation!
...messages,
]),
},
})
// stream the result to the frontend
const stream = await ReplicateStream(response)
return new StreamingTextResponse(stream)
}Next.js 앱 라우터에서 기차 경로 설정
이 섹션에서는 app/api/train/route.js 경로를 설정하는 방법에 대해 설명합니다. 요청 객체에 전달된 문자열의 임베딩을 동적으로 생성하고 이를 Upstash 벡터 인덱스에 추가합니다. 단순화를 위해 다음과 같은 부분으로 나누어 보겠습니다.
문자열 임베딩 생성
기존 인덱스를 설정하거나 업데이트하는 데 도움이 되는 문자열 임베딩을 생성하겠습니다. 그렇게 하면 챗봇의 향후 응답에 대한 컨텍스트를 최신 상태로 유지할 수 있습니다. 우리는 LangChain과 함께 Hugging Face Inference API를 사용하여 에지에서 API 호출만으로 임베딩을 생성할 것입니다.
// File: app/api/train/route.js
import { HuggingFaceInferenceEmbeddings } from '@langchain/community/embeddings/hf'
// Instantiate the Hugging Face Inference API
const embeddings = new HuggingFaceInferenceEmbeddings()
export async function POST(req) {
try {
// a default set of messages to create vector embeddings on
let messagesToVectorize = [
'Rishi is pretty much active on Twitter nowadays.',
'Rishi loves writing for Upstash',
"Rishi's recent article on building chatbot using Upstash went viral",
'Rishi is enjoying building launchfa.st.',
]
// if the POST request is of type application/json
if (req.headers.get('Content-Type') === 'application/json') {
// and if the request contains array of messages to train on
const { messages } = await req.json()
if (typeof messages !== 'string' && messages.length > 0) {
messagesToVectorize = messages
}
}
// Call the Hugging Face Inference API to get emebeddings on the messages
const generatedEmbeddings = await Promise.all(messagesToVectorize.map((i) => embeddings.embedQuery(i)))
// ...
}관련성 검색을 위한 벡터 저장
생성된 임베딩을 벡터 인덱스에 추가하기 위해 Upstash 벡터 인덱스(여기서는 256)를 회전하면서 구성한 길이로 얻은 벡터를 분할합니다. ) upsert를 사용하세요. 메타데이터, 즉 문자열 자체와 함께 임베딩을 삽입하는 방법입니다. 이를 통해 유사한 벡터가 검색될 때 문자열을 검색할 수 있으므로 LLAMA-2-70B 채팅 모델을 호출하여 응답을 생성하는 동안 대화의 지식 기반을 설정할 수 있습니다.
// File: app/api/train/route.js
import { Index } from '@upstash/vector'
// Instantiate the Upstash Vector Index
const upstashVectorIndex = new Index()
export async function POST(req) {
try {
// ...
// Slice the vector into lengths of upto 256
await Promise.all(
generatedEmbeddings
.map((i) => i.slice(0, 256))
.map((vector, index) =>
// Upsert the vector with description to be further as the context to upcoming questions
upstashVectorIndex.upsert({
vector,
id: index.toString(),
metadata: { description: messagesToVectorize[index] },
}),
),
)
// Once done, return with a successful 200 response
return new Response(JSON.stringify({ code: 1 }), { status: 200, headers: { 'Content-Type': 'application/json' } })
}정말 많이 배웠습니다! 이제 모든 작업이 완료되었습니다 ✨
Vercel에 배포
이제 저장소를 Vercel에 배포할 준비가 되었습니다. 배포하려면 다음 단계를 따르세요 👇🏻
- 앱 코드가 포함된 GitHub 저장소를 만드는 것부터 시작하세요.
- 그런 다음 Vercel 대시보드로 이동하여 새 프로젝트를 만듭니다. .
- 새 프로젝트를 방금 생성한 GitHub 저장소에 연결하세요.
- 설정 ,
Environment Variables을 업데이트하세요. 지역.env의 항목과 일치시키려면 파일. - 배치하세요! 🚀
추가 정보
더 자세한 통찰력을 얻으려면 이 게시물에 인용된 참고 자료를 살펴보세요.
결론
결론적으로, 이 프로젝트는 필요에 따라 확장되는 서비스(예:Upstash)를 사용하면서 임베딩을 생성하고, 기존 벡터 세트에서 쿼리하고, 컨텍스트를 사용하여 LLAMA-2-70B 채팅 모델을 사용하여 관련 예측을 생성하는 방법을 배우는 귀중한 경험을 제공했습니다.