우리가 만들고 있는 것
이 기사에서는 쉽게 살아남을 수 있는 매우 내구성이 뛰어난 LLM 스트림을 구축하고 있습니다.
- 네트워크 중단
- 페이지 새로고침
- 웹사이트 폐쇄
- 노트북 덮개 닫기
보너스:동시에 여러 기기(예:휴대폰 및 노트북)에서 동일한 스트림을 볼 수 있습니다. .
아무리 열심히 스트림을 끊으려고 해도 연결이 끊어진 동안에는 백그라운드에서 계속되고 다시 돌아오면 원활하게 계속됩니다. 이건 놀랍습니다 사용자 경험.
튼튼한 LLM 스트림 데모 👇
영감
AI로 구축할 때는 AI 응답을 실시간으로 스트리밍하는 것이 모범 사례입니다.
사용자는 전체 응답을 기다리는 대신 생성된 콘텐츠를 실시간으로 볼 수 있습니다. 이는 UX에 있어서 놀라운 일입니다. Vercel의 AI SDK와 같은 도구를 사용하면 이 작업이 매우 쉬워졌습니다.
import { openai } from "@ai-sdk/openai";
import { streamText } from "ai";
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt: "Invent a new holiday and describe its traditions.",
});실시간 LLM 스트림이 기술 수준에서 작동하도록 하려면 클라이언트를 API에 연결하고 서버 전송 이벤트(SSE)와 같은 프로토콜을 사용하여 데이터를 다시 스트리밍합니다.
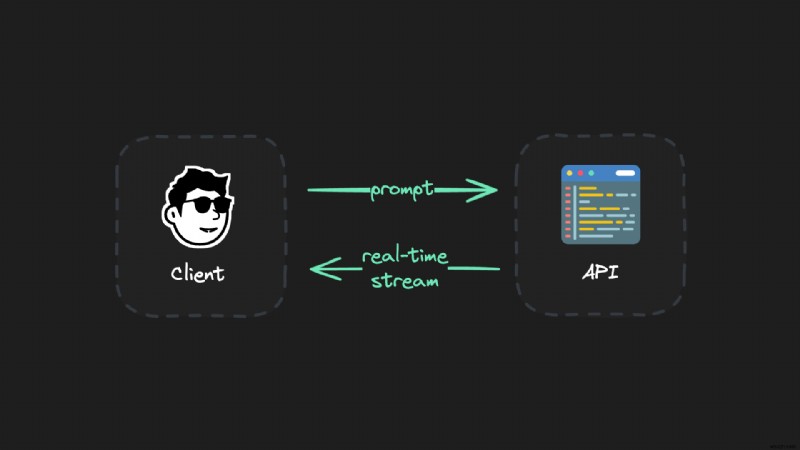
하지만 이 설정에는 문제가 있습니다.
스트리밍 중에 인터넷 연결이 끊기거나 노트북 덮개가 닫히거나 네트워크 문제가 발생하는 등의 문제가 발생하면 전체 세대가 손실됩니다. 다시 시작하고 전체 세대를 다시 기다려야 합니다. 이는 특히 더 긴 세대(예:O1과 같이 실행 비용이 많이 드는 모델)의 경우 짜증나는 일입니다.
분명히 이 문제는 사람들의 레이더에 있습니다. 안정적인 실시간 LLM 스트리밍에 대한 실질적인 수요가 있으며 더 많은 개발자가 이를 작동시키는 방법을 실험하고 있습니다.
고내구성 LLM 스트림 구축
진정으로 내구성이 있고 재개 가능한 LLM 스트림을 생성하는 비결은 클라이언트를 생성 환경에서 분리하는 것입니다. 클라이언트 연결이 불안정하며 노트북 닫기, 네트워크 문제, 페이지 새로 고침 등 여러 가지 이유로 연결이 끊어질 수 있습니다.
클라이언트 프로세스와 생성 프로세스를 분리하여 유지함으로써 생성은 항상 중단 없이 계속됩니다. 클라이언트는 진행 중인 생성을 중단하지 않고 언제든지 다시 연결할 수 있습니다.
나쁜 생각:지속적이고 직접적인 연결:
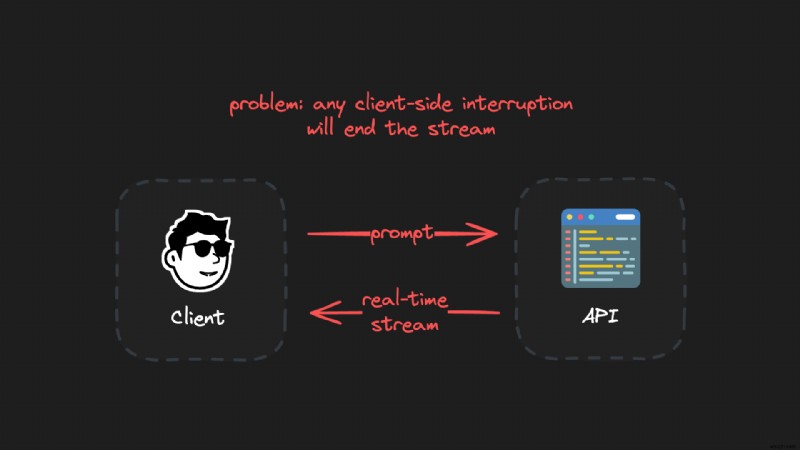
좋은 아이디어:교체 가능하고 중단 가능한 스트림 연결:
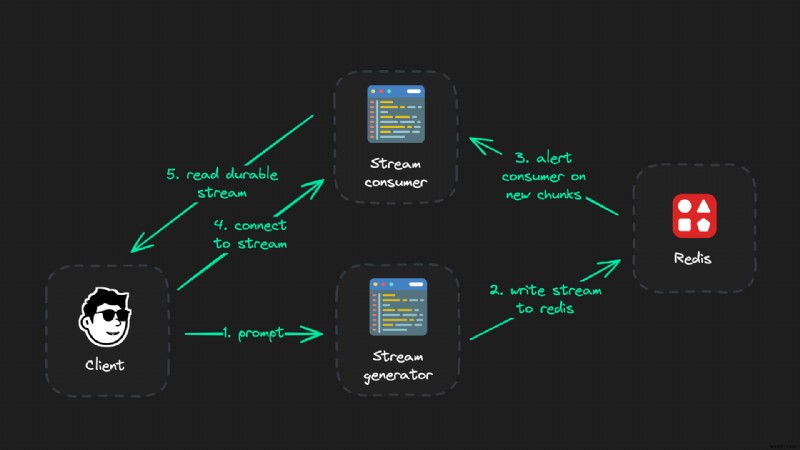
그리고 그렇습니다. 이 아키텍처는 단순한 AI 스트림의 경우 꽤 복잡해 보일 수 있습니다. 하지만 지금 코드에서 볼 수 있듯이 이는 코드 몇 줄에 불과하며 구현하는 데 몇 분 정도 걸립니다.
지속적인 스트림 설정
매우 안정적인 LLM 스트림 설정은 세 부분으로 구성됩니다:
- 클라이언트 (프런트엔드)
- 스트림 생성기 (API 경로)
- 스트림 소비자 (API 경로이기도 함)
클라이언트에 대한 모든 직접 연결은 언제든지 중단되거나 일시 중지될 수 있습니다. 따라서 LLM 출력 스트림 생성을 담당하는 로직(스트림 생성기)은 클라이언트에 대한 활성 연결이 없는 독립적인 API여야 합니다.
대신 소비자를 통해 클라이언트에 연결합니다. 소비자는 Redis에서 데이터를 읽기만 하고 그렇지 않으면 꽤 "어리석은" 일입니다. 유일한 목적은 생성기의 출력을 읽고 클라이언트가 연결할 때마다 클라이언트가 아직 보지 못한 모든 LLM 청크를 제공하는 것입니다. 그게 다야.
간략한 요약 - 각 부분의 역할:
- 클라이언트: 스트림 생성기를 트리거하고(그러나 열린 연결은 유지하지 않음) 실시간 스트림을 렌더링합니다
- 스트림 생성기: 실시간으로 LLM 출력을 생성하고 Redis에 게시합니다.
- 스트림 소비자: 생성기의 스트림을 읽고 청크를 클라이언트에 푸시합니다.
생성기는 LLM 스트림을 읽고 실시간으로 Redis에 게시하는 역할만 담당합니다. 클라이언트에서 종료, 재연결 등이 가능한 스트림 소비자로의 교체 가능한 연결을 얻습니다. 스트림 생성기에 아무 영향도 미치지 않습니다.
코드 예시
이번 섹션에서는 코드를 살펴보겠습니다. 원칙을 더욱 명확하게 하기 위해 마지막에는 실제적이고 완전한 프로덕션 코드 구현을 살펴보겠습니다.
지금은 전체 코드 파일 대신 핵심 스니펫과 그 목적을 살펴보는 것이 코드를 이해하는 것이 훨씬 쉽습니다.
1. 클라이언트
고객에게는 3가지 책임만 있습니다:
- 세션 ID 생성
- 생성기 트리거
- 세대 스트림 렌더링
각각을 살펴보겠습니다:
클라이언트:세션 ID 생성
클라이언트가 스트림에 연결하거나 다시 연결할 때 클라이언트가 아직 확인하지 못한 모든 메시지를 보내려고 합니다. 즉, 활성 스트림 중에 각 메시지에는 전체 스트림이 아닌 클라이언트가 확인해야 하는 정확한 델타만 포함됩니다.
다시 연결하면 현재 생성 지점까지의 전체 스트림이 전송되고 향후 모든 이벤트에 대한 구독이 누락된 청크 없이 완벽하게 원활하게 이루어집니다.
어떻게?
실시간 데이터를 효율적으로 저장하고 검색하는 방법인 Redis Streams에는 소비자 그룹이라는 기능을 통해 아직 볼 수 없는 기능이 내장되어 있습니다. 우리가 해야 할 유일한 일은 각 클라이언트가 고유한 세션을 가지고 있는지 확인하는 것입니다. 즉, 각 세대에 고유한 ID를 할당한다는 의미입니다.
스트림 소비자를 살펴보면 소비자 그룹에 대해 더 자세히 알아볼 것입니다. 다음과 같습니다:
await redis.xgroup("redis-key", {
type: "CREATE",
group: "my-group-name",
id: "0",
});클라이언트가 어느 지점까지 어느 스트림까지 확인했는지, 어느 부분이 누락되었는지 확인하는 전체 논리는 전적으로 Redis 스트림에 의해 처리됩니다 정확성이 보장됩니다. 우리는 누락된 LLM 청크를 가져오는 일이 없으며 항상 고객이 필요로 하는 데이터를 정확하게 보냅니다.
현재 클라이언트가 해야 할 유일한 일은 각 세대에 ID를 할당하는 것입니다. 우리는 단순히 nanoid를 사용합니다. :
import { customAlphabet } from "nanoid"
const nanoid = customAlphabet("0123456789", 6);클라이언트:세대 스트림 트리거
클라이언트가 생성 엔진에 대해 갖는 유일한 상호 작용은 이를 트리거하는 것입니다. 하지만 기술적으로는 다른 곳(예:CRON 작업, 자동화된 파이프라인)에서 생성을 트리거할 수 있습니다.
가장 간단한 형태로 이는 생성 API 경로에 대한 가져오기 호출입니다.
// 👇 trigger stream generator
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId }),
});클라이언트:세대 스트림 읽기
생성을 트리거한 후 생성기는 LLM 출력을 클라이언트에서 완전히 분리된 중앙 Redis 저장소로 스트리밍하기 시작합니다. 생성 스트림을 읽기 위해 스트림 소비자에 연결해 보겠습니다.
// 👇 connect to stream consumer
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
});그게 다야!
이것이 고객의 세 가지 책임입니다. 물론 ID 생성을 위한 사용자 정의 후크, 추가 안정성을 위한 반응 쿼리 등을 사용하면 훨씬 더 멋진 기능을 얻을 수 있습니다. 이에 대해서는 나중에 전체 코드 예제에서 살펴보겠습니다.
2. 스트림 생성기
스트림 생성기는 LLM 스트림을 열고 각 청크를 Redis 스트림에 씁니다. 실시간 업데이트를 위한 새로운 데이터에 대해 스트림 소비자에게 알리기 위해 작성된 모든 청크에 대해 메시지를 게시합니다.
참고:다시 말하지만 이는 의도적으로 전체 코드 예제가 아닙니다. 마지막에 전체 코드를 살펴보겠습니다. 이는 개념을 이해하기 위한 것입니다.
import { streamText } from "ai"
import { redis } from "@/utils"
const result = await new Promise(
async (resolve, reject) => {
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
// ...
}),
})
for await (const chunk of textStream) {
if (chunk) {
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
}
// 👇 write chunk to redis stream
await redis.xadd(streamKey, "*", chunkMessage)
// 👇 alert consumer that there's a new chunk
await redis.publish(streamKey, { type: MessageType.CHUNK })
}
}
}
)3. 스트림 소비자
스트림 소비자는 Redis에 연결하고 Redis pub/sub를 통해 새로운 청크 경고를 수신합니다. 각 클라이언트는 자신의 소비자 그룹을 통해 본 메시지와 본 메시지를 추적합니다.
참고:게시는 실제 청크를 전송하지 않으며 스트림에서 새 청크를 사용할 수 있다는 알림만 제공합니다.
새 청크를 사용할 수 있게 되면 스트림 소비자 API는 이를 스트림에서 읽어 연결된 모든 클라이언트에 전달합니다. Redis 소비자 그룹은 각 클라이언트가 본 내용을 추적하여 중복되거나 누락된 청크가 전송되지 않도록 보장합니다.
핵심 스트림 소비자는 다음과 같습니다:
const streamKey = `llm:stream:${sessionId}`;
const groupName = `sse-group-${nanoid()}`;
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
});
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
// 👇 built-in Redis stream functionality: only send unseen messages
">",
)) as StreamData[];
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0];
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields);
const validatedMessage = validateMessage(rawObj);
if (validatedMessage) {
controller.enqueue(json(validatedMessage));
}
}
}
};
// 👇 initial read
await readStreamMessages();
const subscription = redis.subscribe(streamKey);
subscription.on("message", async () => {
// 👇 read every time a new chunk is written to stream
await readStreamMessages();
});참고:우리는 모든 연결에 소비자 그룹을 생성하고 있습니다. Redis가 이 작업을 멱등적으로 처리하기 때문에 이는 매우 잘 작동합니다. 그룹이 이미 존재하면 아무 일도 일어나지 않습니다.
전체 코드
세션ID 생성
지금까지 우리는 클라이언트의 작업, 스트림 생성기 및 스트림 소비자를 개별적으로 이해하기 위해 개별 코드 조각을 살펴보았습니다. 이제 전체 구현을 보면서 이러한 부분들이 어떻게 조화를 이루는지 살펴보겠습니다.
시작하려면 nanoid()를 사용하는 것보다 sessionId를 생성하는 것이 더 탄력적이어야 합니다. . 결국 웹사이트가 새로 고쳐지거나 닫히면 어떻게 될까요? 다시 연결하면 생성된 sessionId를 어딘가에 저장하지 않으면 잃게 됩니다. 생성이 실행되는 동안 지속되어야 합니다.
다행히 localStorage 이 작업에 딱 맞습니다:
import { customAlphabet } from "nanoid";
import { useRouter } from "next/navigation";
import { useCallback, useEffect, useState } from "react";
export const useLLMSession = () => {
const [sessionId, setSessionId] = useState<string>("");
const router = useRouter();
const nanoid = customAlphabet("0123456789", 6);
const updateUrlWithSessionId = useCallback(
(id: string) => {
const url = new URL(window.location.href);
url.searchParams.set("sessionId", id);
router.replace(url.toString(), { scroll: false });
},
[router],
);
useEffect(() => {
const urlParams = new URLSearchParams(window.location.search);
const urlSessionId = urlParams.get("sessionId");
const storedSessionId = localStorage.getItem("llm-session-id");
if (urlSessionId) {
localStorage.setItem("llm-session-id", urlSessionId);
setSessionId(urlSessionId);
} else if (storedSessionId) {
setSessionId(storedSessionId);
updateUrlWithSessionId(storedSessionId);
} else {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
}
// eslint-disable-next-line react-hooks/exhaustive-deps
}, []);
const clearSessionId = useCallback(() => {
localStorage.removeItem("llm-session-id");
setSessionId("");
const url = new URL(window.location.href);
url.searchParams.delete("sessionId");
router.replace(url.toString(), { scroll: false });
}, [router]);
const regenerateSessionId = () => {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
return newSessionId;
};
return {
sessionId,
regenerateSessionId,
clearSessionId,
};
};클라이언트
우리는 이미 클라이언트의 가장 중요한 두 부분, 즉 스트림 시작과 스트림에 연결을 살펴보았습니다. API에서 생성기가 실행 중이라는 확인을 받으면 반응 쿼리 refetch를 사용하여 스트림에 연결합니다. 연결 쿼리를 호출하는 유틸리티입니다.
모든 조각이 서로 어울리는 방법은 다음과 같습니다.
app/page.tsx"use client"
import { useLLMSession } from "@/use-llm-session"
import { useMutation, useQuery } from "@tanstack/react-query"
import { FormEvent, useRef, useState, useEffect } from "react"
import {
MessageType,
validateMessage,
type ChunkMessage,
type MetadataMessage,
StreamStatus,
} from "@/lib/message-schema"
// precondition = stream is ready to read
class PreconditionFailedError extends Error {
constructor(message: string) {
super(message)
this.name = "PreconditionFailedError"
}
}
export default function Home() {
const { sessionId, regenerateSessionId, clearSessionId } = useLLMSession()
const [prompt, setPrompt] = useState("")
const [status, setStatus] = useState<
"idle" | "loading" | "streaming" | "completed" | "error"
>("idle")
const [response, setResponse] = useState("")
const [chunkCount, setChunkCount] = useState(0)
const controller = useRef<AbortController | null>(null)
const responseRef = useRef<HTMLDivElement>(null)
const isInitialRequest = useRef(true)
// keep generation in viewport
useEffect(() => {
if (responseRef.current) {
responseRef.current.scrollTop = responseRef.current.scrollHeight
}
}, [response])
// start generator
const { mutate, error, isIdle } = useMutation({
mutationFn: async (newSessionId: string) => {
controller.current?.abort()
isInitialRequest.current = false
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId: newSessionId }),
})
},
onSuccess: () => {
setStatus("streaming")
refetch()
},
})
// connect to running stream
const { refetch } = useQuery({
queryKey: ["stream", sessionId],
queryFn: async () => {
if (!sessionId) return null
setResponse("")
setChunkCount(0)
const abortController = new AbortController()
controller.current = abortController
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
signal: controller.current.signal,
})
if (res.status === 412) {
// stream is not yet ready, retry connection
throw new PreconditionFailedError("Stream not ready yet")
}
if (!res.body) return null
const reader = res.body.pipeThrough(new TextDecoderStream()).getReader()
let streamContent = ""
while (true) {
const { value, done } = await reader.read()
if (done) break
if (value) {
const messages = value.split("\n\n").filter(Boolean)
for (const message of messages) {
if (message.startsWith("data: ")) {
const data = message.slice(6)
try {
const parsedData = JSON.parse(data)
const validatedMessage = validateMessage(parsedData)
if (!validatedMessage) continue
switch (validatedMessage.type) {
case MessageType.CHUNK:
const chunkMessage = validatedMessage as ChunkMessage
streamContent += chunkMessage.content
setResponse((prev) => prev + chunkMessage.content)
setChunkCount((prev) => prev + 1)
break
case MessageType.METADATA:
const metadataMessage = validatedMessage as MetadataMessage
if (metadataMessage.status === StreamStatus.COMPLETED) {
setStatus("completed")
}
break
case MessageType.ERROR:
setStatus("error")
break
}
} catch (e) {
console.error("Failed to parse message:", e)
}
}
}
}
}
return streamContent
},
refetchOnWindowFocus: false,
refetchOnMount: false,
retry(failureCount, error) {
if (isInitialRequest.current === true) return false
if (error instanceof PreconditionFailedError) {
return failureCount < 10
}
return false
},
})
const handleSubmit = async (e: FormEvent) => {
e.preventDefault()
setStatus("loading")
const newSessionId = regenerateSessionId()
mutate(newSessionId)
}
const handleReset = () => {
controller.current?.abort()
clearSessionId()
setPrompt("")
setResponse("")
setChunkCount(0)
setStatus("idle")
}
return (
<main className="flex min-h-screen flex-col items-center justify-between p-12 sm:p-24">
<div className="z-10 max-w-5xl w-full items-center justify-between font-mono text-sm">
<h1 className="text-4xl tracking-tight font-bold mb-8 text-center">
Resumable LLM Stream
</h1>
<form onSubmit={handleSubmit} className="mb-8">
<div className="mb-4">
<label htmlFor="prompt" className="block text-sm font-medium mb-2">
Enter your prompt:
</label>
<textarea
autoFocus
id="prompt"
value={prompt}
onChange={(e) => setPrompt(e.target.value)}
className="w-full p-2 border border-zinc-700 rounded-md min-h-[100px] focus:outline-none focus:ring-2 focus:ring-blue-500 focus:border-transparent transition-all duration-200"
placeholder="Ask the AI something..."
disabled={status === "loading" || status === "streaming"}
/>
</div>
<div className="flex gap-4">
<button
type="submit"
disabled={status === "loading" || status === "streaming"}
className="px-4 py-2 bg-blue-600 text-white rounded-md hover:bg-blue-700 disabled:bg-gray-400"
>
{status === "loading"
? "Starting..."
: status === "streaming"
? "Streaming..."
: "Generate Response"}
</button>
<button
type="button"
onClick={handleReset}
className="px-4 py-2 bg-zinc-600 text-white rounded-md hover:bg-zinc-700"
>
Reset
</button>
</div>
</form>
<div className="mt-8">
<h2 className="text-xl tracking-tight font-semibold mb-2">
Response:
</h2>
{status === "error" ? (
<div className="p-4 bg-red-100 border border-red-300 rounded-md text-red-800">
<p className="font-bold">Error:</p>
<p>{error?.message}</p>
</div>
) : status === "idle" && !response ? (
<p className="text-gray-500">
Enter a prompt and click "Generate Response" to see the AI's
response.
</p>
) : (
<div
ref={responseRef}
className="flex flex-col h-96 overflow-y-auto p-4 bg-zinc-900 text-zinc-200 border border-zinc-800 rounded-md whitespace-pre-wrap [&::-webkit-scrollbar]:w-2 [&::-webkit-scrollbar-thumb]:bg-zinc-700 [&::-webkit-scrollbar-track]:bg-zinc-800"
>
<div>{response || "Loading..."}</div>
</div>
)}
{(status === "streaming" || status === "completed") && (
<div className="mt-2 text-sm text-gray-500">
<p>Session ID: {sessionId}</p>
<p>Status: {status}</p>
<p>Chunks received: {chunkCount}</p>
<p>
Connection: {status === "streaming" ? "Active SSE" : "Closed"}
</p>
</div>
)}
</div>
</div>
</main>
)
}스트림 생성기
스트림 생성기의 전체 코드는 다음과 같습니다. 어느 시점에서든 LLM 생성이 실패하면 최대 안정성을 위해 Upstash Workflow를 사용하여 자동으로 재시도됩니다.
api/llm-stream/route.tsimport {
MessageType,
StreamStatus,
type ChunkMessage,
type MetadataMessage,
} from "@/lib/message-schema";
import { redis } from "@/utils";
import { openai } from "@ai-sdk/openai";
import { serve } from "@upstash/workflow/nextjs";
import { streamText } from "ai";
interface LLMStreamResponse {
success: boolean;
sessionId: string;
totalChunks: number;
fullContent: string;
}
export const { POST } = serve(async (context) => {
const { prompt, sessionId } = context.requestPayload as {
prompt?: string;
sessionId?: string;
};
if (!prompt || !sessionId) {
throw new Error("Prompt and sessionId are required");
}
const streamKey = `llm:stream:${sessionId}`;
await context.run("mark-stream-start", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.STARTED,
completedAt: new Date().toISOString(),
totalChunks: 0,
fullContent: "",
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
const res = await context.run("generate-llm-response", async () => {
const result = await new Promise<LLMStreamResponse>(
async (resolve, reject) => {
let fullContent = "";
let chunkIndex = 0;
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
success: true,
sessionId,
totalChunks: chunkIndex,
fullContent,
});
},
});
for await (const chunk of textStream) {
if (chunk) {
fullContent += chunk;
chunkIndex++;
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
};
await redis.xadd(streamKey, "*", chunkMessage);
await redis.publish(streamKey, { type: MessageType.CHUNK });
}
}
},
);
return result;
});
await context.run("mark-stream-end", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.COMPLETED,
completedAt: new Date().toISOString(),
totalChunks: res.totalChunks,
fullContent: res.fullContent,
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
});완전한 유형 안전성을 위해 모든 메시지 스키마도 zod로 작성했습니다:
메시지-스키마.tsimport { z } from "zod";
export const MessageType = {
CHUNK: "chunk",
METADATA: "metadata",
EVENT: "event",
ERROR: "error",
} as const;
export const StreamStatus = {
STARTED: "started",
STREAMING: "streaming",
COMPLETED: "completed",
ERROR: "error",
} as const;
export const baseMessageSchema = z.object({
type: z.enum([
MessageType.CHUNK,
MessageType.METADATA,
MessageType.EVENT,
MessageType.ERROR,
]),
});
export const chunkMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.CHUNK),
content: z.string(),
});
export const metadataMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.METADATA),
status: z.enum([
StreamStatus.STARTED,
StreamStatus.STREAMING,
StreamStatus.COMPLETED,
StreamStatus.ERROR,
]),
completedAt: z.string().optional(),
totalChunks: z.number().optional(),
fullContent: z.string().optional(),
error: z.string().optional(),
});
export const eventMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.EVENT),
});
export const errorMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.ERROR),
error: z.string(),
});
export const messageSchema = z.discriminatedUnion("type", [
chunkMessageSchema,
metadataMessageSchema,
eventMessageSchema,
errorMessageSchema,
]);
export type Message = z.infer<typeof messageSchema>;
export type ChunkMessage = z.infer<typeof chunkMessageSchema>;
export type MetadataMessage = z.infer<typeof metadataMessageSchema>;
export type EventMessage = z.infer<typeof eventMessageSchema>;
export type ErrorMessage = z.infer<typeof errorMessageSchema>;
export const validateMessage = (data: unknown): Message | null => {
const result = messageSchema.safeParse(data);
return result.success ? result.data : null;
};스트림 소비자
마지막으로 전체 스트림 소비자 구현을 살펴보겠습니다. 이는 클라이언트가 연결될 때 보이지 않는 모든 청크를 자동으로 보내는 교체 가능한 연결입니다:
api/check-stream/route.tsimport { redis } from "@/utils"
import { nanoid } from "nanoid"
import { NextRequest, NextResponse } from "next/server"
import {
validateMessage,
MessageType,
type ErrorMessage,
} from "@/lib/message-schema"
export const dynamic = "force-dynamic"
export const maxDuration = 60
export const runtime = "nodejs"
type StreamField = string
type StreamMessage = [string, StreamField[]]
type StreamData = [string, StreamMessage[]]
const arrToObj = (arr: StreamField[]) => {
const obj: Record<string, string> = {}
for (let i = 0; i < arr.length; i += 2) {
obj[arr[i]] = arr[i + 1]
}
return obj
}
const json = (data: Record<string, unknown>) => {
return new TextEncoder().encode(`data: ${JSON.stringify(data)}\n\n`)
}
export async function GET(req: NextRequest) {
const { searchParams } = new URL(req.url)
const sessionId = searchParams.get("sessionId")
if (!sessionId) {
return NextResponse.json(
{ error: "Stream key is required" },
{ status: 400 }
)
}
const streamKey = `llm:stream:${sessionId}`
const groupName = `sse-group-${nanoid()}`
const keyExists = await redis.exists(streamKey)
if (!keyExists) {
return NextResponse.json(
{ error: "Stream does not (yet) exist" },
{ status: 412 }
)
}
try {
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
})
} catch (_err) {}
const response = new Response(
new ReadableStream({
async start(controller) {
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
">"
)) as StreamData[]
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0]
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields)
const validatedMessage = validateMessage(rawObj)
if (validatedMessage) {
controller.enqueue(json(validatedMessage))
}
}
}
}
await readStreamMessages()
const subscription = redis.subscribe(streamKey)
subscription.on("message", async () => {
await readStreamMessages()
})
subscription.on("error", (error) => {
console.error(`SSE subscription error on ${streamKey}:`, error)
const errorMessage: ErrorMessage = {
type: MessageType.ERROR,
error: error.message,
}
controller.enqueue(json(errorMessage))
controller.close()
})
req.signal.addEventListener("abort", () => {
console.log("Client disconnected, cleaning up subscription")
subscription.unsubscribe()
controller.close()
})
},
}),
{
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
},
}
)
return response
}간단한 요약 및 최종 단어
우리는 네트워크 중단, 페이지 새로 고침, 심지어 완전한 연결 끊김까지 처리할 수 있는 매우 강력한 LLM 스트림을 구축했습니다. 우리가 한 일은 다음과 같습니다:
-
전달과 세대 분리: 클라이언트 연결에서 LLM 생성을 분리함으로써 클라이언트 문제에 관계없이 콘텐츠 생성이 계속됩니다.
-
Redis 스트림을 사용한 영구 저장소: 우리는 생성된 LLM 응답의 각 청크를 저장하기 위해 Redis 스트림을 영구 메시지 브로커로 사용하고 있습니다.
-
Redis Pub/Sub를 통한 실시간 업데이트: 우리는 새로운 청크가 사용 가능할 때 스트림 소비자에게 알리기 위해 Redis Pub/Sub를 사용하여 알림 시스템을 구축했습니다.
-
자동 재연결: 클라이언트는 언제든지 다시 연결할 수 있으며 중복되거나 누락된 청크 없이 모든 콘텐츠를 자동으로 수신할 수 있습니다. 여기에는 연결이 끊어진 동안 생성된 콘텐츠가 포함됩니다.
-
세션 관리: 우리는 사용자가 동시에 여러 기기에서 스트림을 볼 수 있는 세션 시스템을 만들었습니다.
결론적으로 우리는 이제 사용자에게 탁월한 사용자 경험(UX)을 제공하고 있습니다. 특히 LLM 채팅 서비스와 같은 것을 구축하는 경우 이 접근 방식을 적극 권장합니다.
읽어주셔서 감사합니다! 피드백이 있거나 Upstash의 게스트 작성자가 되고 싶다면 josh@upstash.com로 문의하세요. 🙌