오늘은 Ruby on Rails 애플리케이션을 대규모 사용자 기반으로 확장하는 데 사용할 수 있는 몇 가지 전략에 대해 알아보겠습니다.
애플리케이션을 확장하는 한 가지 확실한 방법은 애플리케이션에 더 많은 돈을 투자하는 것입니다. 그리고 놀라울 정도로 잘 작동합니다. 서버를 몇 개 더 추가하고, 데이터베이스 서버를 업그레이드하면, 짜잔, 많은 성능 문제가 그냥 폭발됩니다. !
그러나 서버를 추가하지 않고도 애플리케이션을 확장할 수 있는 경우도 많습니다. 오늘 우리가 논의할 내용은 바로 이것입니다.
가자!
Rails 애플리케이션에 AppSignal 사용
확장 및 성능 최적화에 대해 알아보기 전에 먼저 다음 사항을 확인해야 합니다. 이를 수행하려면 애플리케이션의 병목 현상이 무엇인지, 어떤 리소스를 확장할 수 있는지 알아보세요.
이를 수행하는 쉬운 방법 중 하나는 AppSignal의 Ruby용 성능 모니터링 및 지표를 사용하는 것입니다.
성능 대시보드는 평균적으로 느린 컨트롤러 작업과 백그라운드 작업을 정확히 찾아내는 데 도움이 됩니다.
예를 들어 성능 대시보드에서 ActiveRecord를 찾는 방법은 다음과 같습니다.
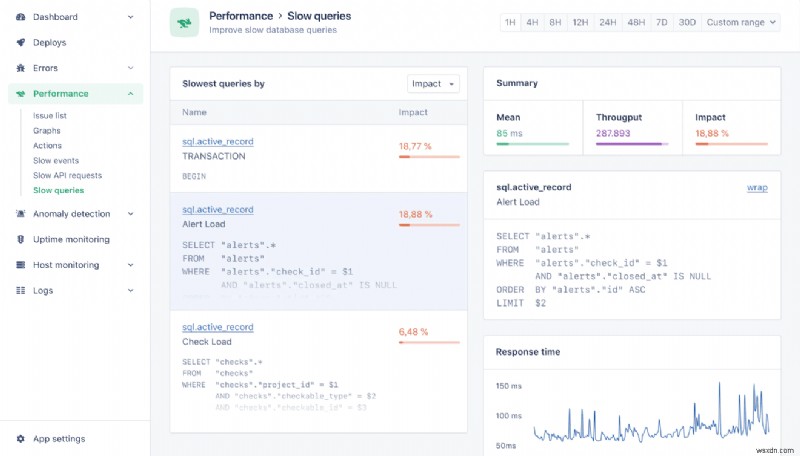
이는 서버를 더 추가하거나 코드를 통해 성능을 최적화하기로 결정하는 등 모든 확장 여정의 좋은 출발점이 됩니다.
이제 Rails 앱을 확장하는 데 사용할 수 있는 가장 간단한 기술 중 하나인 캐싱을 살펴보겠습니다.
Ruby on Rails의 캐싱
캐싱을 사용하면 동일한 작업을 반복해서 계산하는 것을 중단할 수 있습니다.
예를 들어, 소셜 미디어 플랫폼을 운영하고 있는데 매우 인기 있는 게시물이 있다고 가정해 보겠습니다. 캐싱을 사용하면 모든 사용자에 대해 해당 게시물을 렌더링하는 데 소비한 모든 CPU 주기를 즉시 회복하는 데 도움이 될 수 있습니다. 이는 캐싱이 도움이 될 수 있는 작업의 일부일 뿐입니다.
캐시할 수 있는 모든 리소스를 살펴보겠습니다.
뷰 캐싱
렌더링 뷰는 때로는 비용이 많이 드는 작업이 될 수 있으며, 특히 해당 뷰에 렌더링할 데이터가 많은 경우 더욱 그렇습니다. 작업 비용이 많이 들지 않더라도 사전 렌더링된 뷰를 사용하면 동일한 뷰를 백만 번 렌더링하는 것보다 많은 성능을 얻을 수 있습니다.
Rails는 cache를 사용하여 이를 즉시 지원합니다. 도우미 보기. 예를 들어, 목록을 렌더링할 때 각 게시물을 캐시하는 방법은 다음과 같습니다:
이를 위해 Rails는 템플릿의 HTML 콘텐츠, 게시물 ID 및 업데이트 타임스탬프에 따라 특정 키 아래에 각 게시물을 자동으로 캐시합니다.
이 기술에 대해 자세히 알아보려면 Rails 및 Rails 컬렉션 캐싱의 조각 캐싱 게시물을 확인하세요.
하지만 한 가지 명심해야 할 점은 캐시 키에 중첩된 템플릿 콘텐츠가 포함되지 않는다는 것입니다. 따라서 캐시 호출을 한 수준보다 깊게 중첩하는 경우 오래된 결과가 발생할 수 있습니다. Rails의 러시아 인형 캐싱에 대해 자세히 알아보세요.
응답 캐싱
뷰/조각을 캐싱하는 것 외에도 GET의 전체 응답을 캐시하도록 선택할 수도 있습니다. 요청. 이는 If-None-Match를 통해 지원됩니다. 및 If-Modified-Since 브라우저에서 보낸 헤더입니다.
If-None-Match일 때 요청에 헤더가 있으면 서버는 304 Not Modified를 반환할 수 있습니다. 응답에 변경 사항이 없으면 내용이 없는 응답입니다. 서버에서 계산된 Etag 해당 헤더 내부의 값과 비교됩니다.
마찬가지로, If-Modified-Since 헤더가 If-None-Match 없이 존재합니다. , 서버는 304 Not Modified를 반환할 수 있습니다. 내용이 없는 응답(해당 날짜 이후 응답이 변경되지 않은 경우)
Rails는 컨트롤러 작업 내에서 이를 수행하는 쉬운 방법을 제공합니다. 간단히 다음과 같이 작성할 수 있습니다:
Rails는 캐싱을 지원하고, 들어오는 헤더를 처리하고, 데이터가 변경되지 않은 경우 304로 응답하기 위해 필요한 모든 헤더를 보냅니다. 상황이 바뀌지 않는 한 서버는 전체 보기 렌더링을 다시 건너뛸 수 있습니다. Rails의 클라이언트측 캐싱:조건부 GET 요청에서 이 전략의 고급 구성에 대해 자세히 알아볼 수 있습니다.
값 캐싱
마지막으로 원시 값(캐시 저장소에 직렬화할 수 있는 모든 것)을 캐시하는 것도 가능합니다. 이는 일반적으로 리소스 집약적이거나 느린 작업의 결과를 캐시하고 해당 작업을 다시 수행하지 않으려는 데 유용합니다.
이 캐싱으로 이점을 얻을 수 있는 값을 식별하는 것은 애플리케이션에 따라 크게 다르지만 일반적으로 가장 느린 이벤트를 살펴보면 올바른 방향을 찾는 데 도움이 될 수 있습니다.
마지막으로 무엇을 캐시할지 식별할 때 Rails가 제공하는 API를 사용하면 매우 간단합니다.
위 코드는 perform_the_slow_computation입니다. 한 번만 cache_key_with_version 아래에 값을 캐시합니다. 열쇠. 다음에 동일한 코드가 호출되면 Rails는 먼저 캐시된 값이 이미 있는지 확인하고 perform_the_slow_computation를 트리거하는 대신 이를 사용합니다. 또.
이 캐싱 전략의 가장 중요한 부분은 값 계산에 사용된 모든 입력에 따라 좋은 캐시 키를 계산하는 것입니다. 이는 오래된 값을 계속 사용하지 않도록 하기 위한 것입니다.
캐시 저장소
이제 우리는 무엇을 캐시해야 하는지와 Rails가 캐시에 항목을 저장하기 위해 제공하는 기술을 알았으므로 다음 논리적 질문은 이 데이터를 어디에 캐시합니까?입니다. Rails에는 여러 내장 캐시 저장소 어댑터가 함께 제공됩니다. 프로덕션 사용 사례에 가장 널리 사용되는 캐시 저장소는 Redis와 Memcached입니다. 파일 저장소와 메모리 저장소 등 몇 가지 다른 옵션도 있습니다. 이러한 저장소에 대한 전체 논의는 post Rails의 내장 캐시 저장소:개요에서 찾을 수 있습니다.
파일 및 메모리 저장소는 작업을 신속하게 시작하고 실행하기 위한 개발 용도로 유용할 수 있습니다. 그러나 일반적으로 프로덕션에는 적합하지 않습니다. 특히 여러 서버가 있는 분산 설정에서 작업하는 경우 더욱 그렇습니다. Redis와 memcached는 모두 프로덕션 용도에 적합합니다. 일반적으로 어떤 것을 사용하는지는 애플리케이션에 따라 다릅니다.
Ruby on Rails의 백그라운드 워커
대부분의 애플리케이션에는 메일러, 정기적인 정리 또는 사용자가 없어도 시간이 많이 소요되는 기타 작업을 위한 백그라운드 작업이 필요합니다. 이미 백그라운드 작업자가 설정되어 있을 가능성이 높습니다.
컨트롤러 작업 내에서 수행하는 데 1초 이상 걸리는 작업을 수행하는 경우 대신 백그라운드 작업자로 이동할 수 있는지 확인하세요. 이는 큰 테이블 내 데이터 검색과 같은 사용자 대상 작업부터 대량의 데이터를 수집하는 API 메서드까지 다양할 수 있습니다.
구현예
사용자 정의 작업을 실행하기 위해 Rails는 Active Job 프레임워크를 제공합니다. 이를 사용하여 매우 복잡한 필터링 논리를 백그라운드 작업으로 이동하는 방법을 살펴보겠습니다. 먼저, 백그라운드 작업을 생성해 보겠습니다:
다음과 같이 컨트롤러에서 이 작업을 실행할 수 있습니다:
작업이 데이터를 계산하고 결과를 제공할 때까지 기다리는 동안 템플릿에 로딩 표시기를 렌더링해야 합니다.
하지만 작업 결과를 뷰로 어떻게 얻을 수 있습니까? 터보는 이것을 정말 쉽게 만듭니다. 예를 들어 뷰 내에서 turbo_stream_from를 사용하여 특정 알림 채널의 터보 스트림 이벤트를 구독할 수 있습니다. .
이를 사용하여 템플릿을 작성해 보겠습니다.
초기 컨트롤러 작업에서는 데이터가 정의되지 않았으므로 로딩 표시기만 렌더링합니다. 이제 우리 작업의 결과를 전달해 보겠습니다:
여기서 중요한 부분은 notify_completed입니다. 방법. Turbo::StreamsChannel을 사용하여 교체 이벤트를 [user, :huge_datasets]에 브로드캐스팅합니다. 우리가 구독한 알림 스트림입니다.
이것이 컨트롤러에서 백그라운드 작업으로 복잡한 작업을 이동하는 데 필요한 모든 것입니다. 작업을 백그라운드로 이동하는 것의 주요 이점은 백그라운드 작업자를 웹 서버와 독립적으로 확장할 수 있다는 것입니다. 이렇게 하면 웹 서버 측의 리소스가 상당히 확보됩니다. 사용자 입장에서는 이러한 인터페이스가 신속하게 반응하고 점진적으로 결과를 제공할 수 있기 때문에 반응성이 훨씬 더 높다고 느낄 수도 있습니다.
참고 :백그라운드 작업자 중에서 결정하는 데 도움이 필요하면 지연된 작업과 Sidekiq:어느 것이 더 나은가요?를 읽어보세요.
Ruby on Rails 애플리케이션에서 데이터베이스 확장
이 게시물에서 마지막으로 논의할 확장 가능한 리소스는 데이터베이스입니다. 데이터베이스는 대부분의 애플리케이션의 핵심을 형성합니다. 데이터와 해당 데이터에 액세스하는 서버 수가 증가함에 따라 데이터베이스에 부담이 느껴지기 시작합니다.
데이터베이스를 확장하는 가장 쉬운 방법은 데이터베이스 서버에 더 많은 처리 능력과 메모리를 추가하는 것입니다. 웹 서버를 확장하는 것과 달리 데이터베이스를 사용하여 이 작업을 수행하는 것은 일반적으로 매우 느린 작업이며, 특히 저장 용량이 큰 경우에는 더욱 그렇습니다.
데이터베이스를 확장하는 두 번째 옵션은 여러 데이터베이스를 사용하거나 데이터베이스를 분할하여 수평으로 확장하는 것입니다. 이에 대한 자세한 내용은 활성 레코드가 있는 다중 데이터베이스를 확인하세요.
대신 PostgreSQL을 살펴보고 데이터베이스 성능을 최적화하는 데 중점을 둘 것입니다.
PostgreSQL에서 시간이 많이 걸리는 쿼리 찾기
먼저, 가장 시간이 많이 걸리는 쿼리를 식별해야 합니다. 이를 수행할 수 있는 방법은 pg_stat_statements를 쿼리하는 것입니다. 서버에서 실행되는 모든 SQL 문에 대한 통계를 포함하는 테이블입니다. 실행 시간이 가장 높은 상위 100개 쿼리를 찾는 방법을 살펴보겠습니다.
그러면 쿼리, 호출 수 및 이러한 쿼리의 평균 실행 시간이 반환됩니다. 더 빠를 수 있다고 생각되는 것을 찾아 왜 느렸는지 분석해 보세요.
EXPLAIN을 실행할 수도 있습니다. 또는 EXPLAIN ANALYZE 쿼리 계획과 실제 실행 세부 정보를 각각 확인하세요.
결과에서 주목해야 할 가장 중요한 사항 중 하나는 Seq Scan입니다. 이는 Postgres가 쿼리를 실행하기 위해 모든 레코드를 순차적으로 통과해야 함을 나타냅니다. 이런 일이 발생하면 필터링한 열에 인덱스를 추가하여 순차 검색을 우회해 보세요.
가장 순차적인 스캔이 이루어진 테이블
제가 실행하고 싶은 또 다른 유용한 쿼리는 테이블에 대해 실행된 순차 스캔의 총 개수를 찾는 것입니다:
이 결과에서 매우 큰 테이블(행 수가 많음)과 높은 개수 값이 표시되면 문제가 있는 것입니다. 해당 테이블에 대해 모든 쿼리를 확인하고 순차 스캔을 실행할 수 있는 쿼리를 찾은 다음 인덱스를 추가하여 요약해 보세요.
색인 사용
다음 쿼리를 실행하여 인덱스 사용에 대한 통계를 찾을 수도 있습니다:
이는 각 테이블의 인덱스 사용량 비율을 반환합니다. 숫자가 낮다는 것은 해당 테이블의 일부 인덱스가 누락되었음을 의미합니다.
마무리
이 게시물에서는 캐싱 및 백그라운드 작업자를 포함하여 Ruby on Rails 애플리케이션을 확장하기 위한 몇 가지 전략을 살펴보았습니다. 또한 PostgreSQL 데이터베이스 성능 최적화에 대해서도 살펴보았습니다.
Rails를 사용하면 애플리케이션에 여러 계층의 성능 최적화를 쉽게 추가할 수 있습니다.
확장성과 관련하여 가장 중요한 고려 사항은 조치를 취하기 전에 애플리케이션의 병목 현상을 식별하는 것입니다. 좋은 성능 모니터링 도구가 도움이 될 수 있습니다. 필요한 경우 Ruby용 AppSignal을 확인해 보세요.
즐거운 코딩 되세요!
추신 Ruby Magic 게시물이 보도되는 즉시 읽으려면 Ruby Magic 뉴스레터를 구독하고 단 하나의 게시물도 놓치지 마세요!