Rails 프레임워크의 장점 중 하나는 모델에서 Ruby on Rails 연결을 활용하는 기능입니다. 이러한 연결을 사용하면 편리한 구문으로 코드의 레코드 컬렉션에 액세스할 수 있으므로 기본 SQL 쿼리를 작성할 필요가 없습니다. 이러한 추상화는 모든 데이터가 한 곳에 있는 한 유지됩니다. 테이블이 별도의 데이터베이스 클러스터에 분산되는 순간 특정 연결 유형이 작동을 멈춥니다.
이 기사에서는 해당 경계가 정확히 어디에 있는지, 그리고 Rails가 그 경계 내에서 작동하기 위해 무엇을 제공하는지 설명합니다. 문제가 발생하는 이유와 Rails의 어떤 연결이 영향을 받는지부터 시작하여 다중 클러스터와 다대다 관계를 지원하는 데이터베이스 구성 및 모델 계층 구조로 이동합니다. 여기에서 우리는 서로 다른 데이터 액세스 패턴이 각각 해당 분해와 어떻게 상호 작용하는지 다룰 것입니다.
특히 다중 데이터베이스 설정을 다루는 Rails 연관 튜토리얼을 찾고 있다면 이것이 바로 그것입니다. 그 밖에도 많은 사항에 대해 논의할 예정이니 잠시만 기다려주세요.
데이터베이스가 다른 클러스터에 있는 이유
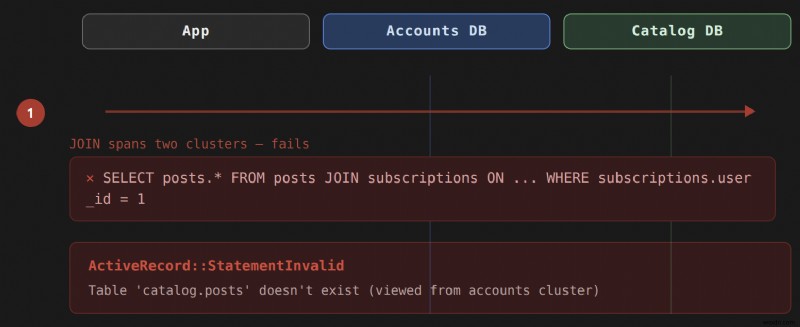
Rails 애플리케이션이 모든 데이터를 단일 데이터베이스에 저장하면 Active Record 연결이 투명하게 처리되므로 기본 SQL에 대해서는 전혀 고려하지 않아도 됩니다. 데이터가 여러 데이터베이스 클러스터에 존재하는 순간 투명성이 무너집니다. JOIN 두 테이블이 모두 동일한 데이터베이스 서버에 있어야 합니다. 클러스터 전체에 걸쳐 하나를 시도하면 ActiveRecord::StatementInvalid이 생성됩니다. 다음과 같은 오류:
ActiveRecord::StatementInvalid (Table 'people_cluster.humans' doesn't exist)
이는 구성 실수가 아닙니다. 이는 물리적으로 어려운 제약입니다. 데이터베이스 서버는 JOIN할 수 없습니다. 그들이 호스팅하지 않는 테이블에 대해. has_many :through에 이 문제가 있습니다. 및 has_one :through 연관. 이는 중간 JOIN를 생성하는 연관 유형이기 때문입니다. 쿼리. 직접 has_many 또는 belongs_to 관계는 조인이 필요하지 않으므로 수정 없이 클러스터 전체에서 작동합니다.
언제 이해하기 이 경계에 도달하는 것이 첫 번째 단계입니다. User인 경우 accounts에 거주 데이터베이스 및 Post content에 거주 데이터베이스, User has_many :posts 잘 작동합니다. 하지만 중간 Subscription를 추가하면 billing의 모델 데이터베이스를 만들고 User has_many :posts, through: :subscriptions를 정의합니다. , Rails는 subscriptions에 참여하려고 시도합니다. 및 posts 단일 쿼리로. 바로 여기서 클러스터 경계가 문제가 됩니다.
3계층 데이터베이스 구성
모델 코드를 작성하기 전에 데이터베이스 구성에 다중 클러스터 레이아웃이 반영되어야 합니다. Rails는 config/database.yml에서 3계층 구조를 사용합니다. 이 목적을 위해. 각 최상위 환경 키에는 중첩된 데이터베이스 이름이 포함되어 있으며 각 키에는 해당 클러스터에 대한 연결 세부 정보가 포함되어 있습니다.
# config/database.yml
default: &default
adapter: postgresql
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
development:
primary:
<<: *default
database: myapp_primary_dev
accounts:
<<: *default
database: myapp_accounts_dev
migrations_paths: db/accounts_migrate
content:
<<: *default
database: myapp_content_dev
migrations_paths: db/content_migrate
production:
primary:
<<: *default
database: myapp_primary_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
accounts:
<<: *default
database: myapp_accounts_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
content:
<<: *default
database: myapp_content_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
migrations_paths Rails 생성기와 db:migrate를 원하는 경우 키는 선택 사항이 아닙니다. 마이그레이션을 올바른 디렉터리로 라우팅합니다. 이것이 없으면 모든 마이그레이션의 기본값은 db/migrate입니다. 기본 데이터베이스에 적용됩니다. 각 보조 데이터베이스에는 Rails 모델이 상속하는 해당 추상 레코드 클래스도 있어야 합니다. --database을 전달하면 생성기가 이를 자동으로 처리합니다. 플래그:
rails generate model Subscription plan:string --database accounts
그러면 AccountsRecord이 생성됩니다. 클래스가 아직 존재하지 않는 경우 생성된 Subscription 모델은 이를 상속받습니다.
추상 레코드 클래스 및 연결 라우팅
추상 레코드 클래스는 Rails가 쿼리를 올바른 클러스터로 라우팅하는 데 사용하는 메커니즘입니다. 각각 connects_to을 호출합니다. 쓰기 및 읽기 작업을 위해 매핑되는 데이터베이스를 선언합니다. 귀하의 애플리케이션은 일반적으로 이 계층 구조에 3개의 레이어를 갖습니다.
# app/models/application_record.rb
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to database: { writing: :primary, reading: :primary }
end
# app/models/accounts_record.rb
class AccountsRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :accounts, reading: :accounts }
end
# app/models/content_record.rb
class ContentRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :content, reading: :content }
end
사용자 모델은 이 계층 구조를 이해하는 데 좋은 기준이 됩니다. accounts에 살아요 클러스터 및 AccountsRecord에서 상속됨 . content의 모델 클러스터는 ContentRecord에서 상속됩니다. . 다른 모든 항목은 ApplicationRecord에서 상속됩니다. 기본 데이터베이스에 도달합니다. 이 상속 체인은 Active Record가 쿼리를 실행할 때 사용할 연결 풀을 결정하는 방법입니다. connects_to을 호출한 클래스를 찾을 때까지 클래스 계층 구조를 탐색합니다. . 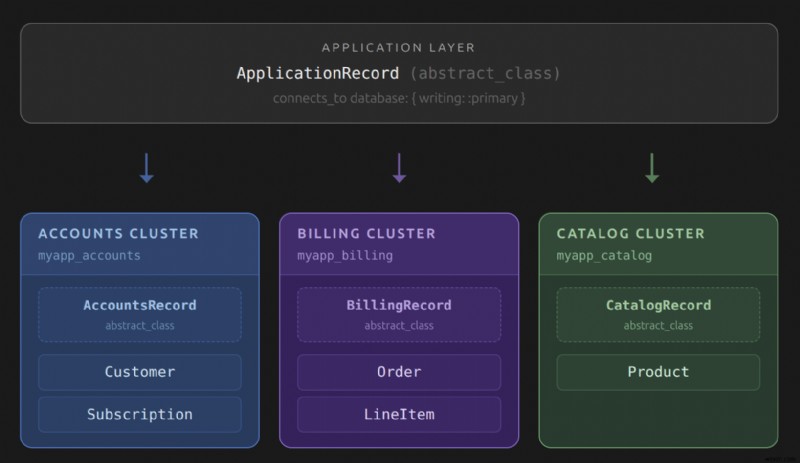
일반적인 실수는 establish_connection를 호출하는 것입니다. 추상 클래스를 사용하는 대신 개별 모델에서. 각 establish_connection 호출은 별도의 연결 풀을 엽니다. accounts에 50개의 모델이 있는 경우 데이터베이스, 각각 establish_connection 호출 , 동일한 서버를 가리키는 50개의 연결 풀이 생성됩니다. 추상 클래스는 이를 상속받은 모든 모델에서 단일 풀을 공유하여 이 문제를 해결합니다.
Rails의 클러스터 간 연결이 실제로 작동하는 방식
disable_joins: true 옵션은 through을 만드는 직접적인 메커니즘입니다. 연관은 관련 테이블이 다른 클러스터에 있을 때 작동합니다. 레일스 has_many 가장 일반적으로 사용되는 연관 유형이며 클러스터 경계의 영향을 가장 직접적으로 받는 유형입니다. Rails가 연관에서 이 옵션을 발견하면 단일 JOIN를 포기합니다. 쿼리 전략을 사용하고 대신 두 개 이상의 순차 SELECT를 발행합니다. 문, 첫 번째 쿼리의 ID를 WHERE ... IN (...)로 파이프 두 번째 절.
다음은 세 개의 클러스터에 걸쳐 있는 구체적인 모델 설정입니다. 아래 모델 설정은 다대다 관계이며, 사용자는 구독을 통해 게시물에 연결하며, 이는 클러스터 간 문제를 가장 직접적으로 노출시키는 패턴입니다.
# app/models/user.rb - lives in the accounts database
class User < AccountsRecord
has_many :subscriptions
has_many :posts, through: :subscriptions, disable_joins: true
end
# app/models/subscription.rb - lives in the accounts database
class Subscription < AccountsRecord
belongs_to :user
has_many :posts
end
# app/models/post.rb - lives in the content database
class Post < ContentRecord
belongs_to :subscription
end
user.posts에 전화하면 , Rails는 단일 JOIN 대신 이 쿼리 쌍을 생성합니다. :
-- Query 1: fetch subscription IDs from the accounts cluster
SELECT "subscriptions"."id"
FROM "subscriptions"
WHERE "subscriptions"."user_id" = 1
-- Query 2: fetch posts from the content cluster using those IDs
SELECT "posts".*
FROM "posts"
WHERE "posts"."subscription_id" IN (4, 7, 12)
첫 번째 쿼리는 accounts에 대해 실행됩니다. 기본 키를 수집하는 데이터베이스입니다. 두 번째는 content에 대해 실행됩니다. . Rails는 외래 키 user_id를 따라 관계를 해결합니다. 구독 및 subscription_id 두 클러스터에 걸쳐 게시물에. 첫 번째 쿼리는 구독에서 기본 키 값을 수집한 다음 이를 IN에 전달합니다. 두 번째 쿼리의 절입니다. 두 쿼리 모두 클러스터 간 조인을 시도하지 않습니다. Rails는 애플리케이션 메모리에 최종 결과 세트를 조합합니다. 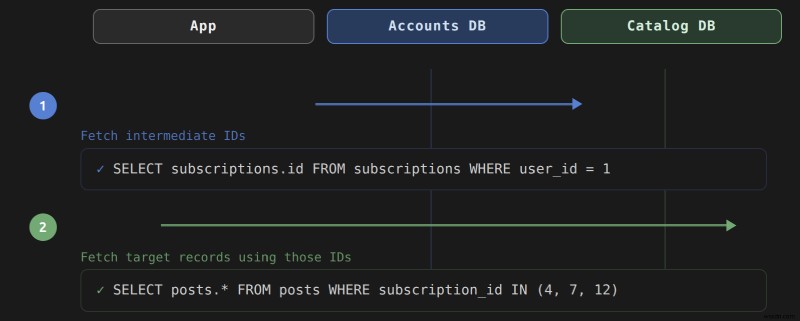
 동일한 옵션이
동일한 옵션이 has_one :through에서도 동일하게 작동합니다. :
# app/models/user.rb
class User < AccountsRecord
has_one :profile
has_one :avatar, through: :profile, disable_joins: true
end
# app/models/profile.rb - accounts database
class Profile < AccountsRecord
belongs_to :user
has_one :avatar
end
# app/models/avatar.rb - content database
class Avatar < ContentRecord
belongs_to :profile
end
user.avatar 두 개의 쿼리를 실행합니다. 하나는 profile_id을 가져오는 것입니다. , 또 다른 하나는 콘텐츠 클러스터에서 아바타 기록을 가져오는 것입니다.
disable_joins일 때 명시적으로 설정해야 합니다
Rails는 클러스터 경계를 자동으로 감지하고 disable_joins를 삽입하지 않습니다. 당신을 위해. Active Record의 연관 로딩이 지연됩니다. 연결에 대한 SQL은 연결이 실제로 트리거될 때가 아니라 모델에 정의된 지점에서 결정됩니다. user.posts까지 실행되면 Rails는 이미 JOIN 사용 여부를 결정했습니다. 또는 연결 선언에 따라 별도의 쿼리를 수행할 수도 있습니다.
이는 through마다 클러스터 경계를 넘는 연결에는 disable_joins: true이 필요합니다. 선언문에.
모델을 감사하는 실용적인 방법은 through:을 찾는 것입니다. 소스 모델과 대상 모델이 서로 다른 추상 레코드 클래스에서 상속되는 연관입니다. User < AccountsRecord인 경우 및 Post < ContentRecord , has_many :posts, through: :subscriptions disable_joins: true가 필요합니다. Subscription 위치에 상관없이 살아있습니다.
클러스터 간 즉시 로드
disable_joins 옵션은 연결이 로드되는 방식에 영향을 주지만 즉시 로드 전략이 클러스터 간 데이터와 상호 작용하는 방식은 변경하지 않습니다. 다중 데이터베이스 설정에서 N+1 쿼리를 피하려면 이러한 구별을 이해하는 것이 중요합니다.
eager_load 클러스터 간 연결에서는 제외됩니다. LEFT OUTER JOIN을 생성합니다. , 일반 JOIN와 동일한 물리적 제한이 있습니다. , 두 테이블 모두 동일한 서버에 있어야 합니다. User.eager_load(:posts)을 시도하면 게시물이 다른 클러스터에 있는 경우 동일한 StatementInvalid을 얻게 됩니다. 오류가 발생했습니다.
preload 올바른 전략이다. 각 연관에 대해 별도의 쿼리를 발행하고 Ruby에서 관계를 조합합니다. 이는 disable_joins와 구조적으로 동일합니다. 단일 레코드에 적용됩니다. 차이점은 규모입니다:preload 로드된 모든 상위 레코드에 대해 두 번째 쿼리를 일괄 처리합니다.
# This works across clusters.
# Query 1: SELECT "users".* FROM "users"
# Query 2: SELECT "posts".* FROM "posts" WHERE "posts"."subscription_id" IN (...)
users = User.preload(:posts).all
users.each do |user|
user.posts.each { |post| puts post.title } # No additional queries fired
end
includes preload에 위임하는 경우에 작동합니다. 내부적으로는 관련 테이블을 참조하는 조건이 없을 때 기본적으로 수행됩니다. .where를 추가하면 연관된 테이블의 열과 접촉하는 절, includes eager_load로 전환 동작하며 클러스터 전체에서 실패합니다. 어떤 전략 includes인지 확실하지 않은 경우 preload를 선택하고 명시적으로 사용합니다. 직접.
# includes delegates to preload here, works across clusters
User.includes(:posts).all
# includes switches to eager_load because of the where clause, fails across clusters
User.includes(:posts).where("posts.published = ?", true)
# Use preload + a separate where for cross-cluster filtering
User.preload(:posts).all.select { |u| u.posts.any?(&:published?) }
# Or filter in application code after loading
범위가 지정된 연결 및 클러스터 간 필터링
다중 데이터베이스 설정에서 보다 미묘한 상호 작용 중 하나는 범위 지정 연결입니다. has_many에서 범위를 정의하는 경우 클러스터를 교차하는 경우 범위의 SQL은 소스가 아닌 대상 데이터베이스에 대해 실행됩니다.
class User < AccountsRecord
has_many :subscriptions
has_many :published_posts,
-> { where(published: true) },
through: :subscriptions,
source: :posts,
class_name: "Post",
disable_joins: true
end
where(published: true) 절은 content에 대해 실행되는 두 번째 쿼리에 추가됩니다. 데이터베이스. 이는 올바른 동작이며 범위가 문제 없이 대상 테이블의 열을 참조할 수 있음을 의미합니다. 범위가 지정된 쿼리가 실행될 때 중간 쿼리가 이미 완료되었기 때문에 수행할 수 없는 작업은 해당 범위에 있는 중간 테이블의 열을 참조하는 것입니다.
# This will fail because subscriptions.active is not a column in the content database
has_many :active_posts,
-> { where("subscriptions.active = ?", true) },
through: :subscriptions,
source: :posts,
disable_joins: true
대신 중간 연관에 범위를 추가하여 중간 레코드를 필터링하십시오:
class User < AccountsRecord
has_many :active_subscriptions, -> { where(active: true) }, class_name: "Subscription"
has_many :active_posts, through: :active_subscriptions, source: :posts, disable_joins: true
end
이제 subscriptions.active에 대한 필터링이 이루어졌습니다. accounts에 대한 첫 번째 쿼리에서 발생합니다. 데이터베이스이며 활성 구독의 ID만 두 번째 쿼리로 전달됩니다.
수평 샤딩 및 교차 샤드 연결
tenant_id와 같은 파티션 키를 기반으로 하나의 논리적 데이터베이스를 여러 서버로 분할 클러스터 간 문제에 두 번째 차원을 도입합니다. disable_joins 메커니즘은 여전히 적용되지만 연결 라우팅이 더욱 복잡해집니다.
레일스는 connected_to을 제공합니다 요청 내에서 샤드 간 전환:
ActiveRecord::Base.connected_to(role: :writing, shard: :shard_one) do
User.find(1) # Hits shard_one
end
연결이 클러스터와 샤드 모두에 걸쳐 있는 경우 샤드 컨텍스트와 disable_joins를 모두 확인해야 합니다. 옵션이 마련되어 있습니다. User shard_one에서 별도의 content에 있는 게시물에 액세스 데이터베이스에는 여전히 동일한 두 쿼리 분해가 필요합니다.
Rails 8에는 런타임 시 샤드 토폴로지를 더 쉽게 추론할 수 있는 자체 검사 방법이 추가되었습니다.
class ShardedBase < ActiveRecord::Base
self.abstract_class = true
connects_to shards: {
shard_one: { writing: :shard_one },
shard_two: { writing: :shard_two }
}
end
class User < ShardedBase; end
User.shard_keys # => [:shard_one, :shard_two]
User.sharded? # => true
ShardedBase.connected_to_all_shards do
User.current_shard # Yields :shard_one, then :shard_two
end
connected_to_all_shards 모든 샤드에서 레코드를 처리해야 하는 백그라운드 작업에 특히 유용합니다. 각 샤드를 순차적으로 반복하여 각 블록 실행에 대한 연결 컨텍스트를 전환합니다.
테넌트 기반 샤딩의 경우 lock: true 샤드 전환의 기본값은 요청 중에 실수로 테넌트가 호핑하는 것을 방지합니다. 이는 안전 메커니즘입니다. 요청이 테넌트의 샤드로 라우팅되면 애플리케이션 코드는 lock: false를 명시적으로 전달하지 않고는 다른 테넌트의 샤드로 전환할 수 없습니다. . 단일 테넌트 샤드 내의 클러스터 간 연결에서는 여전히 disable_joins를 사용합니다. 다른 데이터베이스 클러스터와 접촉하는 연결의 경우.
클러스터 간 연결 테스트
다중 데이터베이스 설정을 테스트하려면 테스트 환경이 프로덕션 데이터베이스 토폴로지를 미러링해야 합니다. Rails의 테스트 프레임워크는 이를 지원하지만 구성은 명시적이어야 합니다.
database.yml의 각 데이터베이스 test이 필요합니다 환경 블록. 설비 및 공장 기반 테스트 데이터는 올바른 데이터베이스를 대상으로 해야 합니다. User인 경우 공장에서는 accounts에 레코드를 생성합니다. 데이터베이스 및 Post 공장에서는 content에 하나를 생성합니다. , 둘 사이의 연결은 두 레코드가 동일한 테스트 트랜잭션 내의 해당 데이터베이스에 존재하는 경우에만 작동합니다.
Rails는 기본적으로 각 테스트를 트랜잭션으로 래핑하지만 해당 트랜잭션은 연결별로 이루어집니다. 여러 데이터베이스를 사용하면 각 연결마다 자체 트랜잭션이 발생합니다. 이는 테스트 정리(각 테스트 종료 시 자동 롤백)가 각 데이터베이스에서 독립적으로 발생함을 의미합니다. 테스트에서 User을 쓰는 경우 accounts로 그리고 Post content로 , 둘 다 롤백되지만 테스트 프레임워크가 두 연결을 모두 알고 있는 경우에만 가능합니다.
fixtures 선언은 모델이 올바른 추상 클래스에서 상속될 때 이를 자동으로 처리합니다. 공장 기반 설정(FactoryBot, Fabricator)의 경우 각 공장의 create을 확인하세요. 전략은 모델 자체의 connects_to를 허용하여 올바른 데이터베이스에 도달합니다. 라우팅이 작업을 수행합니다.
# spec/factories/users.rb
FactoryBot.define do
factory :user do
# User inherits from AccountsRecord and writes to accounts DB automatically
name { Faker::Name.name }
end
end
# spec/factories/posts.rb
FactoryBot.define do
factory :post do
# Post inherits from ContentRecord and writes to content DB automatically
association :subscription
title { Faker::Lorem.sentence }
end
end
클러스터 간 연결이 예상한 쿼리 수를 실행하는지 확인하려면 sql.active_record를 구독하세요. 알림:
# spec/support/query_counter.rb
module QueryCounter
def assert_query_count(expected, &block)
count = 0
callback = ->(_name, _start, _finish, _id, payload) do
count += 1 unless payload[:name] == "SCHEMA" || payload[:sql].start_with?("EXPLAIN")
end
ActiveSupport::Notifications.subscribed(callback, "sql.active_record", &block)
assert_equal expected, count, "Expected #{expected} queries, got #{count}"
end
end
has_many :through disable_joins: true 사용 단일 레코드에서는 정확히 2개의 쿼리를 생성해야 합니다. 1이 표시되면 조인이 아직 시도 중인 것입니다. 별도의 서버에 대한 프로덕션에서는 실패합니다. N+1이 표시되면 즉시 로딩이 예상대로 작동하지 않는 것입니다.
몇 가지 주의사항
disable_joins 연관 로딩 문제를 해결하지만 쿼리 체인으로 확장되지는 않습니다. .where을 연결할 수 없습니다. , .order 또는 .group 단일 액티브 레코드 관계의 클러스터 전체에 걸쳐 열을 참조하는 절:
# This does not work, you cannot filter products by order columns across clusters
customer.purchased_products.where("orders.total > ?", 100)
여러 클러스터의 데이터를 기반으로 필터링하거나 정렬해야 하는 쿼리의 경우 수동으로 분해하세요. 한 클러스터에서 필요한 ID 또는 값을 가져온 다음 이를 다른 클러스터에 대한 쿼리의 입력으로 사용합니다.
high_value_order_ids = Order.where(customer_id: customer.id)
.where("total > ?", 100)
.pluck(:id)
line_item_product_ids = LineItem.where(order_id: high_value_order_ids).pluck(:product_id)
products = Product.where(id: line_item_product_ids)
이는 disable_joins와 동일한 분해입니다. 내부적으로 수행되지만 각 단계에서 필터링을 적용할 수 있도록 명시적으로 수행됩니다. 더 장황하지만 Rails 구문의 연결 뒤에 클러스터 경계를 숨기는 대신 코드에 클러스터 경계를 표시합니다.
편집자 주:이 게시물은 원래 2023년 1월에 게시되었으며 정확성을 위해 업데이트되었습니다.