
IPv4(인터넷 프로토콜 버전 4)는 인터넷 및 기타 패킷 교환 네트워크에서 표준 기반 인터네트워킹 방법의 핵심 프로토콜 중 하나입니다. IPv4는 여전히 가장 널리 배포되는 인터넷 프로토콜입니다. Google의 IPv6 통계에 따르면 2025년 4월 24일 Google 서비스에 대한 트래픽의 44.29%가 IPv6를 통해 발생했으며, 이는 55.71%가 IPv4를 통해 발생함을 의미합니다.
이 핸드북은 IP 주소 이해부터 패킷 헤더 및 조각화 검사에 이르기까지 IPv4의 모든 측면을 안내합니다. 배우게 될 내용은 다음과 같습니다:
-
IP 주소의 작동 방식과 다양한 형식
-
고정 길이에서 CIDR까지의 네트워크 주소 지정 체계
-
특수 IPv4 주소 및 용도
-
IPv4 헤더에 있는 모든 필드의 구조와 목적
-
IPv4가 다양한 네트워크에서 패킷 조각화를 처리하는 방법
네트워크 엔지니어, 소프트웨어 개발자, IT 전문가 모두 최신 컴퓨터 네트워크를 사용하려면 IPv4를 이해하는 것이 중요합니다.
우리가 다룰 내용:
-
배경
-
IP 주소 이해
-
네트워크 ID 및 호스트 ID
-
네트워크와 호스트 부분을 결정하는 방법
-
고정 길이 접근 방식
-
여기서 단점은 무엇입니까? 🤔
-
-
클래스풀 주소 지정
-
IP 주소 할당
-
여기서 단점은 무엇입니까? 🤔
-
-
CIDR:클래스 없는 도메인 간 라우팅
- 실제 사례
-
서브넷 마스크
-
중간 요약 – IPv4 주소
-
자신을 테스트해 보세요
-
접두사 표기법과 서브넷 마스크 간 변환
-
서브넷 마스크를 이용한 역방향 작업
-
바이트 정렬되지 않은 접두사
-
네트워크 회원 결정
-
-
특수 IPv4 주소
-
"이 호스트" 주소:0.0.0.0
-
"이 네트워크" 주소
-
브로드캐스트 주소
-
루프백 주소:127.0.0.0/8
-
특수 IPv4 주소 요약
-
-
IPv4 헤더
-
헤더 구조
-
IPv4 헤더 – 중간 요약
-
-
IPv4 단편화
-
조각화가 필요한 이유
-
IP에서 조각화가 작동하는 방식
-
식별 필드
-
조각 오프셋
-
더 많은 조각 및 조각화 금지 플래그
-
조각화 예
-
IPv4 단편화 – 요약
-
-
요약 – IPv4
-
주소 지정 및 네트워크 구조
-
IPv4 헤더 구조
-
조각화
-
마지막 말씀
-
-
저자 소개
-
추가 참고자료
시작하기 전 간단한 메모
-
내 YouTube 채널인 컴퓨터 네트워크 재생 목록에서 컴퓨터 네트워크에 대한 더 많은 콘텐츠를 찾을 수 있습니다.
-
저는 컴퓨터 네트워크에 관한 책을 집필 중이에요! 초기 버전을 읽고 피드백을 제공하는 데 관심이 있으십니까? 나에게 이메일을 보내주세요:gitting.things@gmail.com
배경
IP는 "인터넷 프로토콜"을 의미하므로 IPv4는 인터넷 프로토콜 버전 4입니다. IPv4는 1981년 9월에 발행된 IETF의 RFC 791에 설명되어 있으며 1982년 처음으로 인터넷의 초기 부분을 형성한 초기 위성 네트워크인 SATNET(대서양 패킷 위성 네트워크)에서 생산을 위해 배포되었습니다.
IPv4는 연결이 없으며 최선의 전달 모델로 작동합니다. 이는 배달, 올바른 패킷 순서 또는 데이터 유효성을 보장하지 않는다는 것을 의미합니다. 빠르고 유연하게 설계되었습니다.
IP 주소 이해
IP 주소는 오늘날 대부분의 인터넷 연결을 지원하는 계층적 논리 주소입니다. 각각은 4으로 구성됩니다. 바이트 또는 255 비트. 일반적으로 점으로 구분된 십진수 표기법으로 작성됩니다. 예:

직접 테스트해보세요 – 다음 주소가 유효한 IP 주소를 나타냅니까?

아니요. 점은 서로 다른 바이트를 구분하므로 각 값은 0 사이여야 합니다. 및 255 . 숫자 392부터 255보다 큽니다. , 단일 바이트로 표현할 수 없습니다.

네트워크 ID 및 호스트 ID
IP 주소는 네트워크 식별자라는 두 부분으로 구성됩니다. (또는 네트워크 ID) 및 호스트 식별자 (또는 호스트 ID)는 이 네트워크의 특정 호스트를 식별합니다.
네트워크 식별자는 네트워크의 모든 호스트에 대해 동일하며 "접두사"라고도 합니다. 예를 들어 201.22.3라는 네트워크 식별자를 생각해 보세요. . 이것이 네트워크 접두사인 경우 다음 주소는 다음과 같습니다.
201.22.3.15
201.22.3.91
동일한 접두사를 공유하므로 동일한 네트워크에 속합니다. 첫 번째 주소는 호스트 번호 15에 속합니다. 이 네트워크에서 두 번째는 호스트 번호 91에 속합니다. .
이 주소는 다른 접두사 또는 다른 네트워크 식별자를 가지므로 다른 네트워크에 속합니다:
201.22.14.50
위의 예에는 3바이트(24비트)로 구성된 네트워크 식별자와 1바이트(8비트)로 구성된 호스트 식별자가 있습니다.

네트워크와 호스트 부분을 결정하는 방법
질문이 생깁니다. 어떤 비트가 네트워크 ID의 일부이고 어느 비트가 호스트 ID의 일부인지 어떻게 알 수 있습니까? 이 문제를 해결하기 위해 시간이 지남에 따라 여러 가지 접근 방식이 발전했습니다.
고정 길이 접근 방식
이 솔루션을 고려해 보겠습니다. 모든 IP 주소에 대해 첫 번째의 가장 중요한 바이트는 네트워크 ID를 나타내고 나머지 3개의 가장 중요한 바이트는 호스트 ID를 나타냅니다. 이렇게 하면 IP 주소를 읽는 것이 정말 쉽습니다. 예를 들어 이 주소는 다음과 같습니다:
20.12.1.92
20 네트워크를 설명한다는 것을 알고 계실 겁니다. , 호스트 12.1.92 그 네트워크 내부에서요. 20로 시작하지 않는 모든 IP 주소 (예:22.1.2.3) , 다른 네트워크에 상주하며 20으로 시작하는 모든 IP 주소 , 예:20.1.2.3 , 동일한 네트워크 내에 있을 것입니다.

여기서 단점은 무엇입니까? 🤔
네트워크 ID를 나타내는 데 1바이트(8비트)만 있으면 2^8, 즉 256만 있으면 됩니다. , 다른 네트워크. 물론 현실 세계에는 그보다 훨씬 더 많은 네트워크가 있습니다. 인터넷 초창기에도 대학과 대기업은 각각 고유한 네트워크 식별자가 필요했습니다.
일반적으로 네트워크 ID에 고정 길이를 사용하고 호스트 ID에 고정 길이를 사용하는 것은 충분히 유연하지 않습니다. 가장 중요한 두 바이트가 네트워크 ID를 나타내고 가장 중요하지 않은 두 바이트가 호스트 ID를 나타내기로 결정한 경우 최대 2^16 또는 65,536를 나타낼 수 있습니다. 네트워크도 충분하지 않습니다. 또한 대기업과 같은 일부 네트워크에는 65,536 이상이 필요할 수 있습니다. 호스트 ID.
클래스풀 주소 지정
해결책은 어느 정도 유연성을 제공하는 데 있습니다. "클래스풀 주소 지정"이라는 또 다른 접근 방식을 고려해보세요. 이 접근 방식에서는 네트워크 ID 전용 비트 수가 한 주소에서 다른 주소로 변경되며, 주소의 가장 중요한 첫 번째 바이트를 보면 네트워크 ID를 알 수 있습니다.
-
1사이의 숫자로 시작하는 모든 주소 및127"클래스 A"에 속합니다. 즉, 네트워크 ID가 1바이트로 구성되고 호스트 ID로 3바이트가 남습니다. -
128사이의 숫자로 시작하는 모든 주소 및191"클래스 B"에 속합니다. 즉, 네트워크 ID의 길이는 2바이트이고 호스트 ID의 길이도 2바이트입니다. -
192사이의 숫자로 시작하는 모든 주소 및223"Class C"에 속하므로 네트워크 ID는 3바이트, 호스트 ID는 1바이트입니다.
아래 표에서 이 접근 방식의 전체 설명을 볼 수 있습니다.
ClassFirst 바이트 범위네트워크 ID 크기호스트 ID 크기 A1 - 127 1바이트3바이트B128 - 191 2바이트2바이트C192 - 223 3바이트1바이트D224 - 239 (멀티캐스트)E240 - 255 (예약)

예를 들어, 이 주소는 어떤 클래스에 속합니까?
(1) 130.12.204.5
130로 시작하므로 , 128 사이 및 191 , "클래스 B"에 속합니다. 이는 네트워크 ID가 130.12임을 의미합니다. 이며 호스트 ID는 204.5입니다. . "주소번호 1"로 표시해 보겠습니다.
이 주소와 다음 주소(2)가 동일한 네트워크에 속해 있습니까?
(2) 130.90.2.40
아니요. 네트워크 식별자가 다르기 때문에 동일한 네트워크 내에 있지 않습니다.
다음 주소는 어떤 클래스에 속합니까?
(3) 200.1.1.9
첫 번째 바이트 값인 200로 C 클래스에 속합니다. , 192 사이입니다. 및 223 . 이는 네트워크 식별자가 200.1.1임을 의미합니다. , 이 접두사로 시작하는 모든 주소는 동일한 네트워크 내에 상주합니다. 이 특정 주소는 호스트 9를 설명합니다. 이 네트워크 내에서.
그림을 완성하려면 224 사이의 값으로 시작하는 주소를 입력하세요. 및 239 "클래스 D"에 속합니다. 즉, 멀티캐스트 주소는 여러 장치에 속하는 주소입니다. 240 사이의 값으로 시작하는 주소 및 255 나중에 사용하기 위해 예약되었습니다. 0로 시작하는 주소 특수 주소입니다.
IP 주소 할당
초기 인터넷에서는 IPv4 주소가 IANA(Internet Assigned Numbers Authority)에 의해 조직에 할당되었습니다. 인터넷이 성장함에 따라 이 책임은 다양한 지역에 대한 주소 할당을 처리하는 5개의 지역 인터넷 등록 기관(RIR)에 분산되었습니다. 대규모 조직은 필요에 따라 주소 블록을 받게 되며, 주소 클래스에 따라 이러한 블록의 크기가 결정됩니다.
여기서 단점은 무엇입니까? 🤔
클래스 기반 주소 지정은 고정 길이 접근 방식에 비해 더 많은 유연성을 허용하지만 이 접근 방식도 충분히 유연하지 않습니다.
다음 시나리오를 고려하십시오. 창립자가 두 명뿐인 소규모 스타트업 회사에는 네트워크 식별자가 필요합니다. 어떤 수업이 필요할까요?
클래스 A 또는 클래스 B를 얻는 것은 과도하므로 클래스 C를 얻을 수도 있습니다. 256을 허용합니다. 주소. 이는 현재 필요한 것보다 많지만 일부 확장이 가능합니다. 스타트업이 256 이상으로 성장하면 어떻게 되나요? 직원(및 장치)은 무엇입니까?
이 시점에서 그들은 65,536 이상의 클래스 B 주소를 얻어야 합니다. 주소, 필요한 것은 256를 약간 넘는 것뿐입니다. 주소. 이는 60,000보다 더 많은 것을 낭비한다는 의미입니다. 주소.
이는 1990년대 초 인터넷이 빠르게 성장하면서 실질적인 문제가 되었습니다. 더 많은 IP 주소에 대한 필요성이 명백해졌고 IPv4 주소 공간이 곧 고갈되었습니다. 60,000인 경우 주소가 낭비되는 것은 더 이상 용납될 수 없습니다.
CIDR:클래스 없는 도메인 간 라우팅
이러한 주소 부족을 해결하기 위한 조치 중 하나는 1993년에 클래스풀 주소 지정을 포기하고 CIDR(클래스 없는 도메인 간 라우팅)이라는 다른 접근 방식으로 전환하는 것이었습니다. 이 접근 방식은 오늘날에도 여전히 사용되고 있습니다.
CIDR은 네트워크 ID와 호스트 ID를 선택할 때 유연성을 허용합니다. 이를 통해 네트워크 관리자는 클래스 A, B 또는 C로 제한되지 않고 정확한 크기의 서브넷을 생성할 수 있습니다.
간단한 예부터 시작해 보겠습니다. CIDR 표기법에서는 네트워크 부분에 사용되는 비트 수를 나타내는 접미사를 추가합니다.
(4) 200.8.3.1/16
이 슬래시 표기법은 네트워크 ID를 설명하는 비트 수를 지정합니다. 위의 예 (4)에서 첫 번째 16 비트(또는 2 bytes)이 네트워크 ID로 사용됩니다. 따라서 이 경우 200.8 은 네트워크 식별자이고 3.1 호스트 식별자입니다. 200.8이라는 사실 네트워크 ID는 200.8.0.0의 모든 주소를 의미합니다. 200.8.255.255을 통해 이 네트워크에 있습니다.

다음 추가 주소를 고려하십시오:
(5) 200.2.13.5
(6) 200.8.21.6
이 주소 접두어가 16인 경우 비트 또는 2 바이트, 이 주소 중 어느 것이 예 (4)와 동일한 네트워크에 속하는지 (200.8.3.1/16 )?
첫 번째 주소(5)(200.2.13.5 )은 첫 번째 16이므로 이 네트워크에 속하지 않습니다. 비트 - 200.2 , 첫 번째 16과 다릅니다. 예시 주소의 비트입니다.
두 번째 주소(6)(200.8.21.6 )은 예시 주소와 동일한 네트워크에 속해 있습니다.

실제 사례
실제로 ISP는 104.16.0.0/12와 같은 큰 블록을 수신할 수 있습니다. RIR에서. 이를 통해 104.16.0.0의 모든 주소를 제어할 수 있습니다. 104.31.255.255으로 . 그런 다음 ISP는 소규모 기업에 /24를 제공하는 등 더 작은 서브넷을 고객에게 할당할 수 있습니다. 256가 포함된 서브넷 주소 또는 대규모 회사 /20 4,096가 포함된 서브넷 주소.
서브넷 마스크
네트워크 접두사를 표현하는 또 다른 방법은 다음과 같이 서브넷 마스크를 사용하는 것입니다.
255.255.0.0
바이너리로 변환하면 255 십진수로 8 1 s는 바이너리이므로 모든 비트가 켜져 있습니다. 따라서 이 마스크를 바이너리로 변환하면 다음과 같은 결과를 얻게 됩니다:
11111111 11111111 00000000 00000000
즉, 16 비트가 켜져 있습니다. 이는 16의 네트워크 접두사를 의미합니다. 비트. 두 가지 규칙(CIDR 표기법과 서브넷 마스크)이 매우 자주 사용됩니다.

CIDR을 사용하면 주소는 서로 다른 네트워크 접두사 또는 서브넷 마스크가 지정된 서로 다른 네트워크에 있을 수 있습니다. 다른 접두어를 가진 동일한 예시 주소를 고려한다면 8라고 말하세요. 비트 – 두 추가 주소는 모두 첫 번째 8를 공유하므로 동일한 네트워크에 속합니다. 비트 - 200 .
8의 네트워크 접두사를 어떻게 표시하시겠습니까? 비트를 서브넷 마스크로 사용합니까? 첫 번째 8가 필요합니다. 비트가 켜져 있어야 합니다. 이는 255을 의미합니다. 10진수로 표시되고 나머지 비트는 꺼져 있어 다음과 같은 서브넷 마스크가 됩니다.
255.0.0.0

24의 네트워크 접두사를 사용하면 어떻게 되나요? 비트? 먼저, 이를 서브넷 마스크로 어떻게 표현할까요? 24가 필요합니다 비트가 켜져 있으므로 8비트의 3배가 켜져 결과는 다음과 같습니다.
255.255.255.0

이제 추가 주소는 네트워크 ID 200.8.3를 공유하지 않으므로 예제 주소와 동일한 네트워크 내에 상주하지 않습니다. .

네트워크 접두사는 전체 바이트를 나타낼 필요가 없습니다. 예를 들어 12의 네트워크 접두사를 사용할 수 있습니다. 비트 또는 11 비트 또는 22 비트. 접두사 길이가 8의 배수가 아닌 경우 , 서브넷 마스크는 0 이외의 값을 갖습니다. 또는 255 그 위치 중 하나에 있습니다.
이는 스타트업 회사에 관한 문제를 해결합니다. 스타트업에 300이 있는 경우 직원이라면 23을 받아야 합니다. -비트 네트워크 ID(9 제외) 네트워크 내의 호스트에 대한 비트입니다. 이는 2^9 또는 512를 의미합니다. 주소이면 충분합니다.
중간 요약 – IPv4 주소
이 섹션에서는 IPv4 주소에 대해 배웠습니다. IP 주소는 4으로 구성된 계층적 논리 주소입니다. 바이트. IP 주소는 네트워크의 모든 호스트에 속하는 네트워크 식별자와 네트워크의 특정 호스트를 식별하는 호스트 식별자의 두 부분으로 구성됩니다.
네트워크 식별자와 호스트 식별자를 결정하기 위한 다양한 옵션을 살펴보았습니다.
-
고정 길이 접근 방식 – 너무 엄격하고 제한적임
-
클래스별 주소 지정 방식 – 더 좋지만 여전히 낭비적입니다
-
CIDR(클래스 없는 도메인 간 라우팅) - 유연하고 효율적입니다.
CIDR은 훨씬 더 많은 유연성을 제공하고 IPv4 주소 부족이라는 심각한 문제를 극복하는 데 도움이 됩니다. 그러나 CIDR은 NAT(Network Address Translation)와 궁극적으로 IPv6를 포함한 다른 솔루션을 통해 IPv4 주소 부족 문제를 해결하는 일부일 뿐입니다.
다음 섹션에서는 특수 IPv4 주소를 살펴본 다음 IPv4 패킷 헤더를 검사합니다.
스스로 테스트해 보세요
이제 배운 개념을 연습하고 익숙해지도록 하세요.
답변을 확인하기 전에 잠시 시간을 내어 다음 질문에 답변해 보세요.
접두사 표기와 서브넷 마스크 간 변환
16의 네트워크 접두사를 어떻게 표현하시겠습니까? 비트, 다음과 같이 작성됨 /16 , 서브넷 마스크로 사용하시겠습니까?
16이 필요합니다 켜져 있는 비트입니다. 8일 때 비트가 켜져 있으면 255을 얻습니다. 십진수로 다음을 사용합니다:
255.255.0.0

이 네트워크 접두어가 주어지면 이 주소는 동일한 네트워크에 속합니까?

예, 그렇습니다. 가장 중요한 동일한 16을 공유하기 때문입니다. 비트 또는 2바이트

이 주소는 이전 주소와 동일한 네트워크에 속해 있습니까?

네, 그렇습니다. 다시 말하지만, 동일한 가장 중요한 두 바이트를 공유합니다.

이건 어때요? 이전 주소와 동일한 네트워크에 속해 있나요?
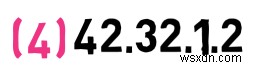
아니요, 처음 2바이트는 42.31가 아니기 때문입니다. – 이것은 다른 네트워크입니다. 따라서 이 주소는 호스트 1.2를 설명합니다. , 42.32 네트워크 내 .

서브넷 마스크를 사용한 역방향 작업
다른 방법을 시도해 봅시다. 다음 서브넷 마스크가 있습니다:
255.255.255.0
네트워크 접두어를 사용하면 어떻게 표현하나요?
255가 세 번 발생했습니다. , 이는 8의 세 번을 의미합니다. 비트가 켜져 있으므로 전체적으로 24이 됩니다. 켜져 있는 비트입니다. 따라서 /24를 쓸 수도 있습니다. . 이는 3를 의미합니다. 바이트.

이 서브넷 마스크가 주어지면 위의 주소 (1)과 (3)이 동일한 네트워크에 속합니까?

둘 다 동일한 가장 중요한 3바이트(network 42.31.93)를 갖고 있기 때문에 그렇습니다. .

주소 (1)과 (2)는 어떻습니까?

이 네트워크 접두사가 주어지면 동일한 네트워크에 속하지 않습니다. 첫 번째 주소는 42.31.93 네트워크에 속합니다. , 두 번째 주소는 42.31.1 네트워크에 속합니다. .

바이트 정렬되지 않은 접두사
네트워크 접두사는 8에 맞춰 정렬될 필요가 없습니다. 비트 또는 전체 바이트. 14라는 네트워크 접두사가 있다고 가정해 보겠습니다. 비트. 이를 서브넷 마스크로 어떻게 변환하시겠습니까?
음, 첫 번째 바이트는 명확합니다. 8이 있습니다. 비트가 켜져 있으므로 첫 번째 바이트는 255입니다. . 다음은 어떨까요?
바이너리에서는 6개의 추가 1과 2개의 0이 필요합니다. 따라서 바이너리에서는 다음과 같이 작성합니다:
11111100
십진수로 변환하면 이 이진수는 252을 나타냅니다. . 따라서 서브넷 마스크는 다음과 같습니다:
255.252.0.0
이 변환을 수행하는 또 다른 방법:이진수로 된 8개의 1이 255을 나타냄을 알고 있습니다. 십진수로. 11도 알고 계시죠? 바이너리는 3입니다. 이므로 간단히 3를 빼면 됩니다. 255에서 그리고 252을 얻으세요 .

다음에는 다른 방법을 시도해 보세요. 다음과 같은 서브넷 마스크가 있습니다:
255.255.224.0
네트워크 접두사를 나타내는 비트는 몇 개입니까?
처음 2바이트는 명확합니다. 16입니다. 비트. 세 번째 바이트를 바이너리로 변환:224 십진수는 11100000입니다. 바이너리로. 즉, 1이 3개 더 있으므로 위의 서브넷 마스크를 접두사 /19으로 쓸 수 있습니다. 비트 - 16 두 255에 대한 비트 바이트 및 3 224에 대한 추가 비트 바이트.

네트워크 회원 결정
다음 주소를 고려해 보겠습니다:

동일한 네트워크에 속해 있습니까? 🤔
서브넷 마스크에 따라 다릅니다.
네트워크 접두사가 /8인 경우 , 동일한 네트워크 ID를 공유하므로 동일한 네트워크에 속해 있습니다.

반면, 네트워크 접두사가 /16인 경우 , 서로 다른 네트워크 ID를 가지므로 동일한 네트워크에 속하지 않습니다. 하지만 그 사이에 접두사가 있으면 어떻게 되나요? /9 접두사에 대해 동일한 네트워크에 상주합니까? ? /14 ?
이 질문에 접근하는 방법은 이 주소의 두 번째 바이트를 바이너리로 변환하는 것입니다. 첫 번째 주소의 경우 이 바이트는 24입니다. , 바이너리 형식은 다음과 같습니다.
00011000
두 번째 주소의 경우 두 번째 바이트는 23입니다. , 바이너리 형식은 다음과 같습니다.
00010111
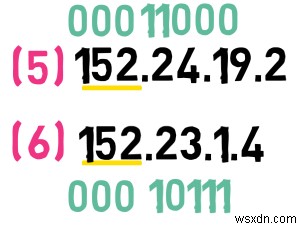
가장 중요한 4을 볼 수 있습니다. 두 번째 바이트 내의 비트는 동일합니다. 첫 번째 8를 추가하면 주소 비트 중 가장 중요한 12이 표시됩니다. 이 주소의 비트는 동일합니다.
따라서 네트워크 접두사가 /11인 경우 , 이 주소가 동일한 네트워크에 속해 있습니까?
예, 그렇습니다. 가장 중요한 11입니다. 비트는 동일합니다.
/13은 어떻습니까? ?
아니요, 이 네트워크 접두어를 사용하면 13와 동일한 네트워크 식별자를 공유하지 않습니다. 번째 비트가 다릅니다.
이렇게 하면 서브넷 마스크와 네트워크 접두사에 익숙해지는 데 도움이 됩니다. 다음 섹션에서는 특수 IP 주소에 대해 알아보고 IP 패킷 헤더를 검사합니다.
특수 IPv4 주소
이제 IP 주소와 서브넷 마스크에 익숙해졌으니 특별한 의미가 있는 몇 가지 IP 주소를 살펴보겠습니다.
"이 호스트" 주소:0.0.0.0
주소 0.0.0.0 "이 호스트"를 의미하며 두 가지 시나리오에 사용됩니다:
첫째, 머신이 부팅되었지만 아직 IP 주소가 없는 경우입니다. IP 주소는 머신에 할당되어야 하는 논리적 주소입니다. 이 할당 이전에는 장치에 IP 주소가 전혀 없었습니다. 장치가 이 단계에서 통신해야 하는 경우 이 특수 주소 0.0.0.0를 사용할 수 있습니다. .
둘째, 모든 네트워크 인터페이스에서 들어오는 연결을 수신해야 하는 네트워크 애플리케이션을 작성할 때입니다. 예를 들어, 컴퓨터에 두 개의 인터페이스가 있는 경우(하나는 IP 주소 1.1.1.1) , 주소가 2.2.2.2인 다른 하나 – 0.0.0.0 주소에서 청취 어떤 네트워크 인터페이스가 연결을 수신하는지에 관계없이 연결을 수락한다는 의미입니다.
"이 네트워크" 주소
특수 주소의 또 다른 클래스는 0으로 시작하는 주소입니다. 여기서 0은 "이 네트워크"를 의미합니다.
예를 들어 다음 주소의 컴퓨터가 있는 경우:
12.34.55.55
네트워크 접두사 16 비트를 사용하여 이 컴퓨터는 전체 주소(예:12.34.66.66)를 사용하여 네트워크의 다른 장치로 패킷을 보낼 수 있습니다. , 또는 특수 0 표기법을 사용하여 패킷을 다음 주소로 보냅니다.
0.0.66.66
이는 "호스트 66.66로 패킷을 보낸다"는 뜻입니다. 이 네트워크에서요." 물론, 이 주소를 올바르게 해석하려면 수신자가 관련 네트워크 접두사도 알아야 합니다.
방송 주소
주소 255.255.255.255 , 여기서 모든 비트는 1로 설정됩니다. 는 로컬 네트워크에 있는 모든 호스트의 주소, 즉 브로드캐스트 주소입니다. 이는 이더넷의 브로드캐스트 주소(FF:FF:FF:FF:FF:FF)와 유사합니다. ). 두 경우 모두 모든 비트가 1으로 설정됩니다. .
호스트 식별자가 모두 1로 설정된 적절한 네트워크 식별자를 사용하면 브로드캐스트 패킷을 원격 네트워크로 보내는 데 사용할 수 있습니다. 예를 들어 12.34.0.0/16 네트워크를 생각해 보세요. 네트워크 ID가 12.35.0.0/16인 다른 네트워크 . 12.34.55.55에 기계가 있는 경우 다른 네트워크의 모든 장치에 패킷을 보내려는 경우 대상 주소:12.35.255.255를 사용할 수 있습니다. .
IP 사양(RFC)에 따라 허용되는 기능이지만 실제로는 보안 취약점이 발생할 수 있으므로 비활성화되는 경우가 많습니다.
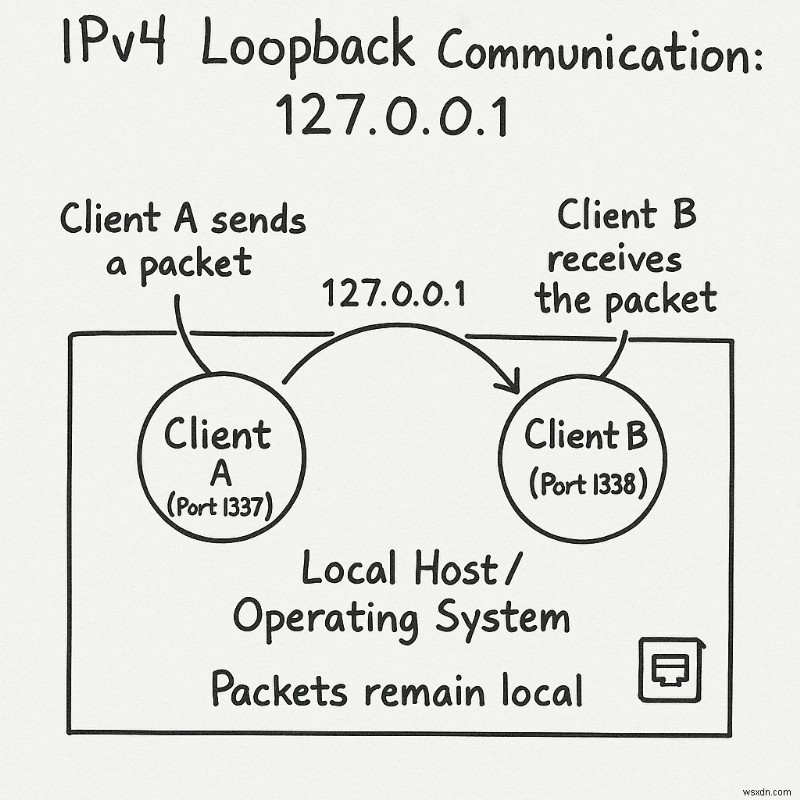
루프백 주소:127.0.0.0/8
네트워크 127.0.0.0/8의 모든 주소 (즉, 127으로 시작하는 모든 주소 )은 루프백 주소입니다. 이러한 주소로 전송된 패킷은 실제 네트워크에 배치되지 않고 운영 체제 내에서 로컬로 처리됩니다. 이는 개발 및 디버깅에 매우 유용합니다.
예를 들어 간단한 채팅 프로그램을 개발하려면 데이터를 교환하는 두 개의 클라이언트가 필요합니다. 한 가지 접근 방식은 서로 다른 두 대의 물리적 컴퓨터를 사용하는 것이지만 이는 지루한 작업입니다. 한 컴퓨터에 메시지를 쓰고 다른 컴퓨터에서 메시지가 수신되었는지 확인한 다음 두 번째 컴퓨터에 메시지를 쓰고 첫 번째 컴퓨터로 돌아가서 수신 여부를 확인해야 합니다.
훨씬 간단한 접근 방식은 루프백 주소를 사용하는 것입니다. 두 클라이언트 모두 동일한 시스템에서 실행되고 서로 연결할 수 있습니다. 동일한 물리적 컴퓨터에서 두 개의 서로 다른 클라이언트 프로그램을 실행하고 추가 컴퓨터 없이도 두 프로그램 간에 메시지를 교환할 수 있습니다.
예를 들어 127.0.0.1 주소를 사용할 수 있습니다. , 하나의 클라이언트가 포트 1337에서 수신 대기함 다른 하나는 포트 1338에 있습니다. . 클라이언트 A가 클라이언트 B에게 패킷을 보내면 이 패킷은 네트워크 카드를 떠나지 않고 운영 체제 내에 남아 있습니다. 클라이언트 B는 마치 물리적 네트워크에서 수신한 것처럼 루프백 인터페이스에서 패킷을 수신합니다.
디버깅이 완료된 후 클라이언트 코드를 변경할 필요가 없습니다. 유일한 차이점은 루프백 주소 대신 실제 IP 주소를 사용하여 통신한다는 것입니다.
특수 IPv4 주소 요약
지금까지 배운 특수 IPv4 주소를 요약하면:
특수 주소 의미사용0.0.0.0 "이 호스트"는 부팅 중에 사용되거나 0으로 시작하는 모든 인터페이스 주소를 수신하는 데 사용됩니다. "이 네트워크"는 로컬 네트워크255.255.255.255의 호스트로 전송 중입니다. 브로드캐스트로컬 네트워크의 모든 호스트로 전송호스트 부분이 모두 1인 네트워크 ID 특정 네트워크의 모든 호스트로 전송127.0.0.0/8 루프백물리적 네트워크를 사용하지 않고 테스트 및 디버깅 다음 섹션에서는 IPv4 헤더의 구조에 대해 알아보겠습니다.
이제 IP 주소, 서브넷, 특수 주소를 이해했으므로 IPv4 헤더 구조를 자세히 살펴보겠습니다.

위 다이어그램은 RFC 791에 정의된 IPv4 헤더를 보여줍니다. 각 필드를 살펴보겠습니다.
버전(4비트)
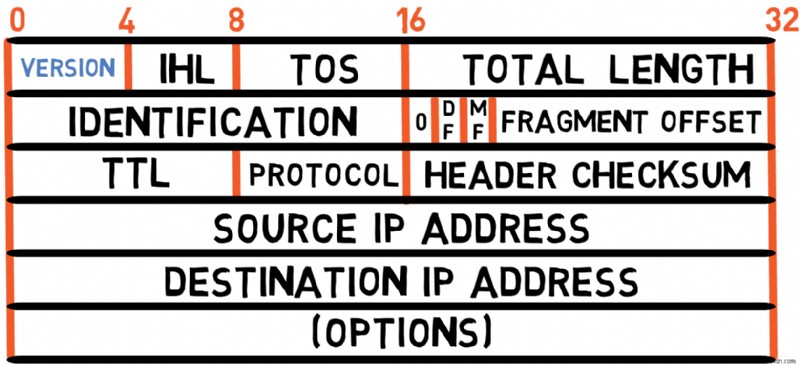
헤더는 4비트로 구성된 버전 필드로 시작됩니다. IPv4 패킷의 경우 버전은 4입니다. 이므로 이 필드는 항상 4 값을 전달합니다. (또는 0100 바이너리로).
❓ 헤더가 버전 필드로 시작하는 이유는 무엇인가요? 🤔
(참고 - ❓ 표시로 문장을 시작하면 이는 귀하에게 하는 질문이므로 읽기 전에 먼저 답변해 보시기 바랍니다.
그 이유는 버전에 따라 나머지 필드가 다를 수 있기 때문입니다. 네트워크 장치가 IP 패킷을 읽고 버전 필드에 4 값이 있는 경우 , 패킷의 나머지 부분이 IPv4 구조를 따를 것으로 예상합니다. 6와 같은 다른 값을 전달하는 경우 , 나머지 필드는 IPv6에서와 다릅니다.

이 필드는 헤더 자체의 길이를 나타냅니다.
❓ 길이를 지정해야 하는 이유는 무엇인가요? 🤔
헤더 크기가 고정되어 있는 이더넷과 달리 IPv4 헤더 길이는 선택적 필드로 인해 달라질 수 있습니다. 특별한 옵션이 없는 IP 패킷의 경우 헤더는 20로 구성됩니다. 바이트가 가장 일반적인 경우입니다.
IHL 필드에서는 길이를 바이트 단위로 직접 지정하지 않고 4바이트 단어 단위로 지정합니다. 따라서 20의 길이를 지정하려면 바이트이면 값은 5입니다. (5 × 4 =20). 이 인코딩을 사용하면 헤더 길이를 최대 60로 지정하면서 필드가 4비트만 사용할 수 있습니다. 바이트(IHL =15인 경우) ).
따라서 일반 IPv4 패킷은 0x45 바이트로 시작됩니다. 16진수로, 버전이 4임을 의미합니다. IP 프로토콜의 헤더는 20입니다. 바이트 길이입니다.
서비스 유형(TOS)(8비트)

이 필드의 기본 개념은 모든 패킷이 똑같이 중요하지는 않다는 것입니다. 일부 패킷에 다른 패킷보다 우선순위를 부여할 수 있습니다.
예를 들어 실시간 데이터(예:음성 또는 화상 회의)를 전달하는 패킷은 이메일이나 파일 다운로드를 전달하는 패킷보다 시간에 더 민감합니다. 라우터가 현재 높은 로드를 겪고 있는 경우 이상적으로는 시간에 민감한 패킷의 우선순위를 지정해야 합니다.
서비스 유형 필드를 통해 발신자는 패킷의 우선 순위를 나타낼 수 있습니다. 그러나 공용 인터넷에서는 모든 발신자가 우선순위 값을 설정할 수 있기 때문에 라우터에서 이 필드를 무시하는 경우가 많습니다. 대부분의 경우 이 필드는 0 값을 전달합니다. .
전체 길이(16비트)
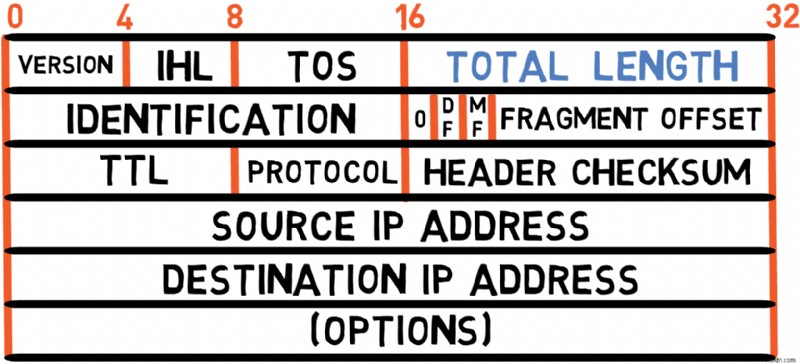
This field specifies the total length of the IP packet, including both the header and the payload (data).
❓ Why is this needed to specify the length? 🤔
Unfortunately, the IP layer doesn’t necessarily know if some of the bytes in the packet are actually a padding of the second layer. I described this in detail in a previous post, where I showed that in Ethernet protocol, in some cases, the receiving Ethernet entity cannot tell which bytes belong to the payload and which bytes are simply padding. The IP layer needs to know precisely which bytes belong to the actual packet, hence the Total Length field.
❓What is the maximum size of an IPv4 packet? 🤔
Since this field is 16 bits long, an IPv4 packet may contain a maximum of 2^16-1 bytes, or 65,535 bytes, including the header. The minimum size is 20 bytes, consisting of just the header without options or payload.
Fragmentation Fields (32 bits)
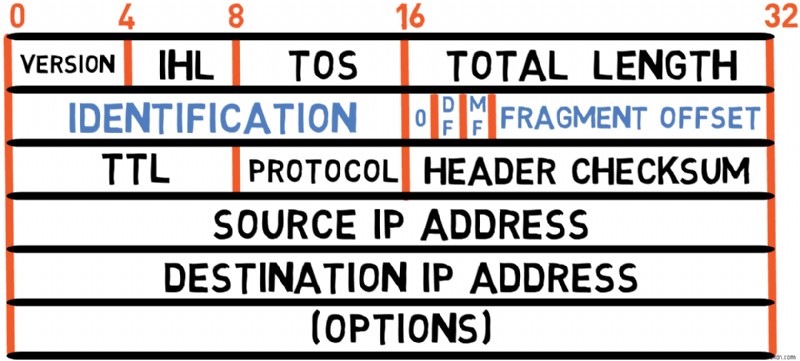
The next four bytes are dedicated to fragmentation control. I’ll cover these fields in a separate section, as they involve a complex topic deserving special attention.
Time to Live (8 bits)

Despite its name, this field doesn't actually measure time but rather the maximum number of routing hops a packet can traverse before being discarded.
To understand its purpose, consider this scenario:If Machine A sends a packet to Machine B through a series of routers, but there's a routing loop where Router 2 sends to Router 3, which sends to Router 4, which sends back to Router 2, the packet could circulate indefinitely, consuming bandwidth and never reaching its destination.
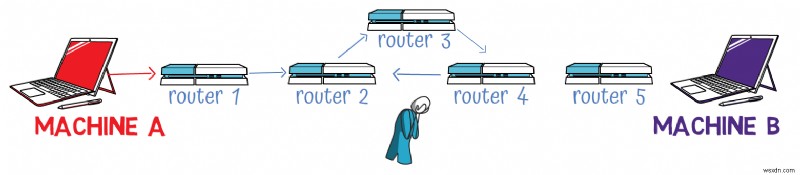
The TTL field prevents this by setting a limit on how many hops a packet can take:
-
The sender sets an initial TTL value (often
64or128) -
Each router that handles the packet decrements the TTL by
1 -
If a router receives a packet with TTL =
1, it decrements it to0and discards the packet -
The router then sends an ICMP "Time Exceeded" message back to the original sender
This doesn't solve the underlying problem of routing loops, but it prevents packets from circulating forever.
In IPv6, this field is renamed "Hop Limit," which more accurately describes its function.
Protocol (8 bits)

This field describes the payload of the IPv4 packet. 예:
-
A value of
6means the payload is TCP -
A value of
17means the payload is UDP
This helps the receiving system know which protocol handler should process the packet's contents. It's similar to the Type field in Ethernet, which specifies the protocol of the layer encapsulated within the Ethernet frame.
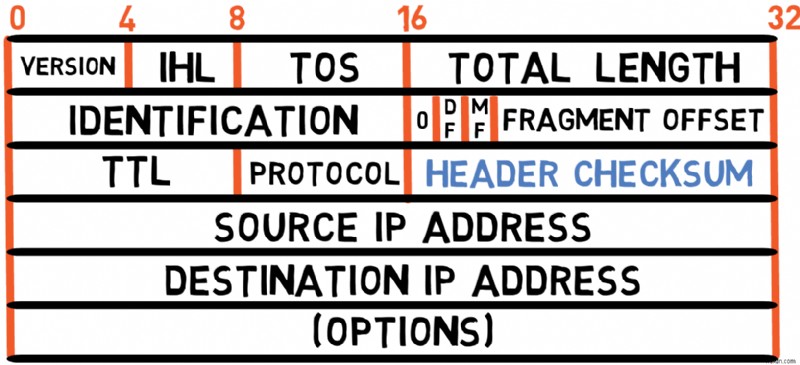
This is a 16-bit checksum used to verify the validity of the header only (that is, excluding the payload). The sender computes this value based on the fields of the header, and the receiver also computes it to validate that the header was received correctly.
❓The checksum must be recalculated by each router. 왜 그럴까요? 🤔
Because the TTL field changes at each hop. For example, if a packet starts with TTL =7 , each router will:
-
Verify the current checksum based on TTL =
7 -
Decrement TTL to
6 -
Calculate a new checksum based on TTL =
6 -
Forward the packet with the new checksum
If the checksum verification fails, the device drops the packet. This prevents packets with corrupted headers (which might have incorrect destination addresses, for instance) from being forwarded.
Source and Destination Addresses (32 bits each)
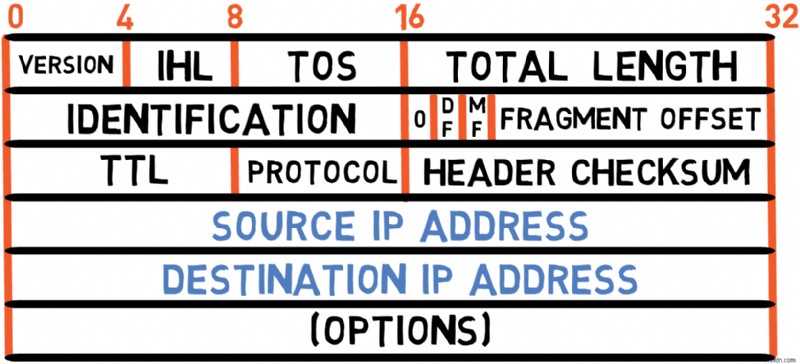
These fields contain the source and destination IPv4 addresses, respectively. Each is 4 bytes (32 bits) long, as you learned in the previous sections on IPv4 addressing.
Options (Variable Length)
Most IPv4 packets don't include options, but when present, they can provide additional functionality:
-
Record Route :Each router that handles the packet adds its own address to this option, creating a trace of the packet's path
-
Source Routing :Allows the sender to specify the route the packet should take:
-
Strict Source Routing:The entire route must be followed exactly
-
Loose Source Routing:Certain routers must be traversed, but the exact path between them is flexible
-
Padding
In some cases, the header ends with padding bytes (usually 0 s).
❓Why does the IPv4 header have padding?🤔
As explained before, the IHL field specifies the header length in 4-byte units, so the total header length must be a multiple of 4 bytes. If options make the header length not divisible by 4, padding bytes (usually 0 ) are added to reach the next multiple of 4.
For example, if you have 3 bytes of options, you would need 1 byte of padding to make the total header length a multiple of 4 bytes.
You've now learned about the structure of the IPv4 header, with the exception of the fragmentation fields which I’ll cover in the next section.
The IPv4 header efficiently packs all the necessary routing and control information into a compact structure, typically 20 bytes long (without options). This design allows for fast processing by routers while providing the flexibility needed for internet communication. It is amazing how prominent IPv4 is, even so many years after its publication.
In the next section, you'll learn about IPv4 fragmentation.
IPv4 Fragmentation
In the previous section, you learned about most of the IPv4 header structure, with the exception of 32 bits dedicated to fragmentation. This topic deserves special attention, as it reveals important aspects of how IP packets travel across different networks.
Why Fragmentation Is Needed
To understand what fragmentation is and why it's needed, consider the following network scenario:
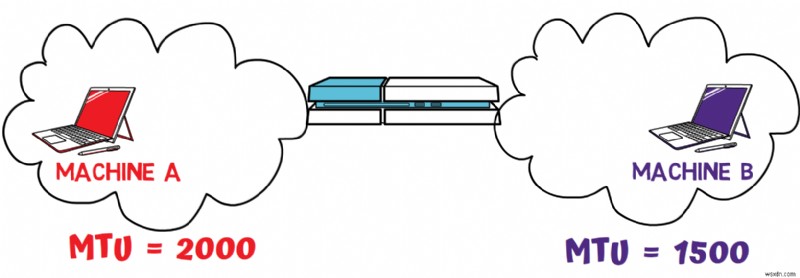
In this diagram, you have two different networks where Machine A resides in one network and Machine B resides in another. A router forwards packets between these two networks.
These two networks have different Maximum Transmission Units (MTUs). MTU refers to the maximum size of a frame that can be transmitted in a network. 예:
-
Machine B is connected to an Ethernet network with an MTU of
1500bytes -
Machine A is connected to a different network with an MTU of
2000bytes
Different MTUs stem from the different protocols and hardware that different networks have. Ethernet has an MTU of 1500 bytes. This maximum size was chosen because RAM was expensive back in the late 1970s when Ethernet was planned, and a receiver would need more RAM if a frame could be bigger. Other networks were devised at different times where RAM prices might have been lower, or just have other considerations that affect the MTU.
Now, consider this scenario:Machine A wants to send a packet to Machine B. This packet is 1800 bytes long. From A's perspective, there's no problem since its network supports packets of this size. Machine A transmits the packet.
When the router receives this packet, it faces a problem:it cannot simply forward the packet to B's network because the packet is too big for the network's MTU. The router must fragment the packet – splitting it into smaller chunks of up to 1500 bytes, which will then be reassembled by Machine B.
How Fragmentation Works in IP
Let's examine the scenario further. The router needs to take an IP packet of 1800 bytes and split it into two fragments, each consisting of up to 1500 bytes. If Machine A sends another packet of 1800 bytes to Machine B, the router will have to split that one too – resulting in four different fragments that will be reassembled into two separate packets.

When Machine B receives these fragments, it must ensure that it reassembles fragment #1 together with fragment #2 of packet A, and fragment #1 with fragment #2 of packet B – and not, for instance, fragment #1 of packet A with fragment #2 of packet B. It must also reassemble the fragments in the correct order – so structure a packet that consists of #1#2 and not #2#1.

Identification Field
First, focus on making sure Machine B reassembles fragments of the same packet (for example, fragment #1 and fragment #2 of packet A in the example above, rather than fragment #1 of packet A and fragment #2 of packet B). This is achieved using the identification field of IPv4. Fragments belonging to the same packet will have the same identification value. For example, both fragments of packet A might have identification set to 100 , and both fragments of packet B might have identification of 200 .

It's important to note that sharing identification values isn't sufficient for fragments to belong to the same packet. Fragments of the same packet must also share:
-
The same source IP address
-
The same destination IP address
-
The same protocol value (indicating whether the payload is TCP, UDP, and so on)
Fragment Offset
Since IP is a connectionless protocol, there's no guarantee that fragments will arrive at Machine B in the correct order. Fragment #2 of packet A may arrive before fragment #1. To handle this issue, each fragment carries an Offset field, which denotes the offset from the beginning of the original packet.
The Offset field consists of 13 bits, which means it can carry values from 0 to 8191 (2^13-1). This poses a potential problem, as the maximum size of an IP packet can be 65,535 bytes (since the Total Length field of the IP header consists of 16 bits).
To address this limitation, the value encoded in the Offset field is actually multiplied by 8 (2^3). This means the minimum size of a fragment is 8 bytes, with the exception of the last fragment.
❓Why do IP packets carry an offset in bytes divided by 8, instead of just a sequential fragment number?🤔
While using sequence numbers might seem simpler, it would create problems when packets need to be fragmented multiple times.
For example, if Computer A sends a packet to the first router, which fragments it into pieces of 1480 bytes and 320 bytes, and then these fragments are sent to another router that needs to fragment them again into even smaller pieces, how would you number them?
With byte offsets, the solution is straightforward – if the first fragment has an offset of 0 and the next one has an offset of 1480 , then if we need to split them into maximum 800 -byte fragments, we'd have:
-
First fragment:
800bytes with offset0 -
Second fragment:
680bytes with offset800 -
Third fragment:
320bytes with offset1480
More Fragments and Don't Fragment Flags
When Machine B receives a fragment, it needs to know whether this is an entire packet by itself or if it should expect additional fragments. For this purpose, each IP fragment carries a More Fragments (MF ) bit that is set to 1 for every fragment that is not the last fragment of the packet. For the last fragment, it's set to 0 .
In case the packet consists of a single fragment – the MF bit will be set to 0 , and the offset field will also hold the value 0 (that is, 13 bits of 0 s).
Another bit related to fragmentation is the Don't Fragment (DF ) bit. When this flag is turned on, intermediate devices should not fragment the original packet, even if it exceeds the MTU. Instead, they should drop it and typically send an ICMP "Fragmentation Needed" message back to the source.
In our example, if Machine A sets the Don't Fragment bit to 1 , the router would drop the packet, and notify Machine A about it.
Note that right after the identification field and before the DF flag, there is a reserved bit set to 0 . This bit was reserved in case it is needed in the future, for a reason unknown to the original authors of IPv4.
Fragmentation Example
Consider again our example above – with Machine A residing in a network where the MTU is 2000 , and Machine B residing in a network where the MTU is 1500 . Machine A sends a packet which is 1800 bytes long.
❓Can you fill the values in these tables?
First Fragment:
Total Length IdentificationDon’t FragmentMore FragmentsOffsetSecond Fragment:
Total Length IdentificationDon’t FragmentMore FragmentsOffsetFor our example above, the values of the relevant fragmentation fields in IP would be as follows:
First Fragment:
-
Total Length:
1500(including20bytes of IP header, so1480bytes of payload) -
Identification:
1337(arbitrary value) -
Don't Fragment bit:
0(off, to allow further fragmentation if needed) -
More Fragments bit:
1(on, as this is not the last fragment) -
Offset:
0(it's the first fragment)
Second Fragment:
-
Total Length:
340(including20bytes of IP header, so320bytes of payload – together with the first fragment, we get to1800bytes of payload) -
Identification:
1337(same as first fragment, indicating they belong together) -
Don't Fragment bit:
0(off, to allow further fragmentation if needed) -
More Fragments bit:
0(off, as this is the last fragment) -
Offset:
185(1480/8 =185, or0xB9in hexadecimal)
IPv4 Fragmentation – Summary
You've now learned about the final part of the IPv4 Header:fragmentation. Fragmentation is necessary to allow packets to travel across networks with different MTUs. The IPv4 header includes several fields specifically designed to support fragmentation:
-
Identification (16 bits):Identifies which fragments belong together
-
Flags (3 bits):Including the "More Fragments" and "Don't Fragment" flags
-
Fragment Offset (13 bits):Indicates where in the original packet this fragment belongs
With this knowledge, you now understand every bit and byte of the IPv4 header and how IP packets can traverse networks with different characteristics.
Summary – IPv4
In this comprehensive guide to IPv4, you've learned about the fundamental building blocks of Internet communications. Let's recap the key concepts we covered:
Addressing and Network Structure
-
IPv4 addresses are 32-bit numbers typically written in dotted decimal notation
-
Networks can be identified using various methods:
-
Fixed-length approach (historically)
-
Classful addressing (A, B, C, D, E classes)
-
CIDR (modern approach allowing flexible network sizes)
-
-
Special addresses serve specific purposes:
-
0.0.0.0for "this host" -
127.0.0.0/8for loopback -
255.255.255.255for broadcast
-
-
The header contains crucial fields for packet routing and processing:
-
Version and IHL for header interpretation
-
Type of Service for traffic prioritization
-
Total Length for packet size
-
Various fields for fragmentation control
-
TTL to prevent infinite routing loops
-
Protocol to identify the encapsulated protocol
-
Checksum for error detection
-
Source and destination addresses
-
Fragmentation
-
Allows IPv4 packets to traverse networks with different MTUs
-
Uses three key fields:
-
Identification to group fragments
-
Flags to control fragmentation
-
Fragment Offset to reassemble packets
-
마지막 한마디
While IPv4 has limitations, particularly its address space constraints, its elegant design and robust features have allowed it to remain the backbone of the Internet for over four decades. Understanding IPv4 provides essential context for working with modern networks and helps in transitioning to newer protocols like IPv6.
About the Author
Omer Rosenbaum is Swimm’s Chief Technology Officer. He's the author of the Brief YouTube Channel. He's also a cyber training expert and founder of Checkpoint Security Academy. He's the author of Gitting Things Done (in English) and Computer Networks (in Hebrew). You can find him on Twitter.
Additional References
- Computer Networks Playlist - on my Brief channel
무료로 코딩을 배우세요. freeCodeCamp의 오픈 소스 커리큘럼은 40,000명 이상의 사람들이 개발자로 취업하는 데 도움을 주었습니다. 시작하세요