인공 지능은 수년에 걸쳐 성장했으며 Facebook은 AI 개발 및 개념을 카메라 및 뉴스 피드 분석을 포함한 다양한 기능에 통합했습니다. 인공 지능은 자원 활용을 최적화하고 경험을 단순화하여 사람들의 삶을 더 쉽게 만들어줍니다. 소셜 미디어에서 AI는 사용자에게 차세대 통신 및 상호 작용 매체를 소개하는 데 사용되어 사용자가 사랑하는 사람과 스마트하게 연결할 수 있도록 도와줍니다. 그러나 다시 한 번 페이스북의 AI는 뉴스피드 필터링, 사용자 개인정보 보호에 비참하게 실패했으며 세계에서 가장 큰 소셜 미디어 플랫폼에서 증오심 표현이 자유롭게 퍼지도록 함으로써 윤리를 위반했습니다. Facebook의 F8 기조 연설 2일 차에는 Facebook CTO Mike Schroepfer가 이끄는 AI 및 AI 보안이 행사의 대부분을 다루었습니다. Facebook이 향후 AI로 무엇을 할 계획인지 살펴보겠습니다.
Facebook의 인공 지능

Facebook의 인공 지능의 핵심 용도는 뉴스 피드를 검사하는 것입니다. AI 기술은 증오심 표현, 폭력, 인종 차별, 정치 정보 및 Facebook 가치와 전 세계 법률을 위반하는 모든 콘텐츠를 확인하는 데 사용됩니다. AI는 또한 사용자 검색, 기본 설정 및 업데이트를 읽는 데 사용되므로 Facebook은 사용자에게 올바른 종류의 광고를 제공하고 친구 제안과 후원 게시물을 필터링하여 피드에 추가할 수 있습니다. 이것이 바로 Facebook의 비즈니스 모델을 지원하는 것입니다.
페이스북이 AI를 사용하는 방법

Facebook은 고급 자연어 처리(NLP)를 사용하여 AI를 훈련하고 모든 종류의 형식으로 된 다양한 유형의 콘텐츠 간의 차이를 이해하도록 돕고 있습니다. NLP는 AI가 다양한 언어로 된 콘텐츠를 이해하고 전 세계 뉴스피드에서 유해한 콘텐츠를 제거할 수 있도록 하는 다국어 임베딩을 사용합니다.
어려움

다국어 임베딩이 있음에도 불구하고 Facebook AI가 모든 콘텐츠를 캡처하는 것은 매우 어렵습니다. 전 세계에는 거의 같은 수의 민족적 배경을 가진 사람들이 쓰고 말하는 언어가 6,000개 이상 있습니다. 언어 이해에 대한 방대한 지식으로 AI를 훈련시키는 것은 매우 어렵습니다. 페이스북이 사용하는 AI는 시스템에 업로드된 레이블이 지정된 데이터에서 학습하고 학습합니다. 데이터는 방대한 양이며 AI의 효과적인 훈련을 위해 데이터에 레이블을 지정하는 것은 개발자에게 어려운 작업입니다. 그리고 데이터 양이 많을수록 사람이 실수할 가능성이 커집니다.
데이터의 사진 및 비디오 형식 학습은 또 다른 골칫거리입니다.

Facebook은 특히 Instagram을 인수한 후 사진을 이해하는 데 있어서 폭이 넓어졌습니다. Facebook은 이미지의 모든 측면의 아키텍처를 이해하기 위해 Computer Vision 및 Panoptic FPN(Panoptic Feature Pyramid Network) 개념을 내장했습니다. Panoptic FPN은 심지어 이미지 배경과 함께 모든 이미지 구조를 이해할 수 있도록 성장했으며, 이는 Facebook의 AI가 이미지 형태로 웹에서 사용할 수 있는 유해한 콘텐츠를 필터링할 수 있는 능력을 더욱 강화했습니다.
그러나 동영상 콘텐츠를 이해하는 것은 Facebook AI의 주요 단점이었으며 Facebook에 업로드 및 공유된 동영상을 통해 혐오 발언과 폭력을 피하는 것과 관련하여 기계 학습은 여러 수준에서 실패했습니다. 페이스북은 AI가 비디오 콘텐츠에서 학습하도록 돕기 위해 해시태그를 데이터 레이블로 사용하려고 시도했거나 적어도 해시태그가 제공하는 정보에서 데이터의 관련성을 판단하려고 시도했다고 주장하지만; 그러나 목표에 도달하지 못했습니다.
Facebook AI는 어디에서 실패합니까?

Facebook AI는 지도 학습에서 실행됩니다. 프레임워크를 통해 AI는 인간 개발자가 레이블을 지정한 데이터 세트에서 학습합니다. 지난 몇 년 동안 Facebook의 인구는 지구상 전체 인구의 거의 3분의 1에 달했습니다. 이것은 서면, 오디오 및 비디오 형식의 잉여 데이터가 몇 초 만에 Facebook에 업로드됨을 의미합니다. 한편 AI는 이 콘텐츠를 실시간으로 평가하는 역할을 한다. 인간의 개입이 있기 때문에 철저한 조사는 AI가 읽은 데이터 세트의 데이터 라벨링 또는 결함의 지연으로 이어질 수도 있습니다. 이로 인해 콘텐츠 감지 오류가 발생할 수 있으며 뉴스피드에 업로드된 모든 사용자 콘텐츠에 대해 AI가 동일한 방식으로 작동하지 않을 수 있습니다.
자기 감독 AI:유해한 콘텐츠를 제거하기 위한 Facebook의 백업 계획
F8 2019 2일 차에 CTO인 Mike Schroepfer는 Facebook이 연구원과 개발자가 자기 지도 학습을 지원하는 시스템을 설계하도록 이끌고 있다고 발표했습니다. 이러한 AI 시스템은 데이터 세트 및 레이블 지정 없이 정보를 이해할 수 있으므로 자체적으로 의존하고 자각할 수 있습니다. 자체 감독 AI는 엄청난 양의 데이터를 공급받을 수 있습니다. 그러나 전체 데이터가 원시 상태이고 그대로 공급될 필요는 없습니다. AI 머신용 교육 모듈을 설계하려면 사용자가 콘텐츠나 데이터에서 일부 정보를 제거한 다음 머신이 누락된 비트를 스스로 인식하도록 해야 합니다. 이러한 유형의 교육을 통해 기계는 Facebook에 게시되는 콘텐츠의 관련성을 높이고 더 나은 방식으로 정책 및 법률에 따라 콘텐츠를 면밀히 조사할 수 있습니다.
AI를 위한 포괄적인 교육:Facebook의 AR 비즈니스를 보다 윤리적이고 안전하게 만들기
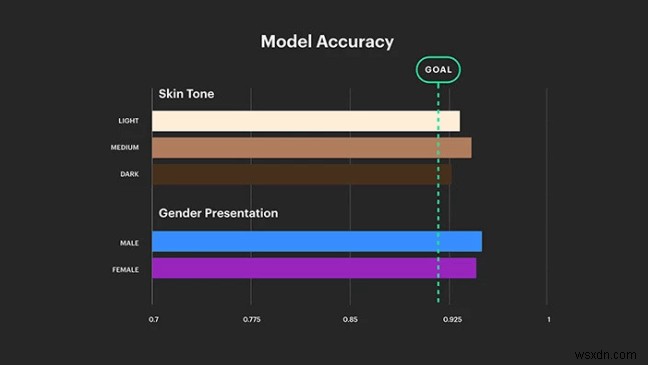
Portal 및 Spark AR을 통해 Facebook은 AR 및 VR 기술 비즈니스에서 대규모 벤처를 계획하고 있습니다. 그러나 스마트 기술은 번영하는 사용자 경험을 제공하기 위해 스마트 AI가 필요합니다. 포털 카메라는 증강 현실 개념으로 설계되었으며 차세대 안면 인식 및 스마트 화상 채팅 플랫폼을 도입하는 데 핵심이 될 것입니다. 그러나 이러한 카메라와 AR/VR 헤드셋은 사람의 명령을 이해하는 데 편향되어 있음이 밝혀졌습니다. 렌즈는 피부색과 성별을 구분하는 반면 모든 사용자에게 유사한 사용자 경험을 제공하지 못하는 것으로 밝혀졌습니다. 또한 이것은 인종 및 성 차별을 조장합니다. 전 세계에 걸친 모든 비판 이후, 이것이 Facebook이 원하는 마지막 것입니다.

그래서 페이스북은 이 문제를 근절하기 위해 포괄적인 AI를 구축하겠다고 발표했습니다. 이를 위해 나이지리아계 미국인 Lade Obamehinti가 Facebook의 AR/VR 섹션 전략 부서를 이끌고 있습니다. 연구자들은 AI가 오류나 변동 없이 학습 모듈에 포함된 포용성을 보장하기 위해 서로 다른 피부 톤을 가진 사람들과 함께 다양한 조명 설정에서 AI 카메라를 테스트할 것입니다.
Facebook이 AI에 대해 작업해야 하는 이유

페이스북은 사람들의 데이터가 남용되도록 내버려 두었고 그 데이터는 공무원의 코앞에서 마케터와 광고주에게 판매되었습니다. 그런 다음 Facebook은 전력 급증을 겪었고 수백만 명의 사용자 암호가 일반 텍스트로 노출되었습니다. 그런 다음 뉴질랜드 크라이스트처치의 한 남성이 모스크에서 사람들을 여러 번 총으로 쏴 죽이는 동영상을 페이스북에 라이브 스트리밍하면서 AI 무능력과 개발자의 무지 수준을 넘어섰습니다. 동영상이 스트리밍되었고 사람들이 다운로드할 수 있도록 충분한 시간 동안 FB 뉴스 피드에 남아 있었습니다.
페이스북은 이미 많은 반발을 겪었고 그 과정에서 수십억 달러를 잃었다. 이것이 마크 저커버그가 올해 F8 이벤트 첫날에 "프라이버시"라는 단어를 백만 번 사용한 이유입니다. Facebook은 레버리지를 잃었고 전 세계 사용자와 정책 입안자 모두의 인내심 한계를 우회했습니다. Facebook이 AI가 콘텐츠를 이해하지 못하면 향후 몇 년 안에 폐쇄될 수 있습니다.
아마도 페이스북이 하루 종일 CTO를 무대에 올려 놓고 페이스북이 사용자를 보호하기 위해 무엇을 하려는지 알려줌으로써 사용자를 안심시킨 유일한 이유였을 것입니다.
이 움직임이 성공할까요?

Zuckerberg는 이러한 변화가 하룻밤 사이에 일어나지 않을 것이라는 점을 받아들였습니다. Facebook은 AI의 결함을 완전히 근절하고 Facebook에서 증오 콘텐츠를 영원히 제거하기 위해 비즈니스 모델을 변경해야 할 수도 있습니다. 연구가 진행 중이며 이러한 교육 모듈의 개발은 초기 단계에 있습니다. 그러나 한 가지 말할 수 있는 것은 페이스북이 그러한 문제를 심각하게 받아들이기 시작했다는 것입니다. 그리고 그것이 우선 순위에 있다면 회사는 올해 F8에서 관계자들이 한 약속을 이행할 수 있을지도 모릅니다.
페이스북이 FB의 콘텐츠를 이해하기 위해 새로운 기술과 더 나은 AI 교육 모듈을 내놓는 것은 좋은 시간입니다. 특히 Facebook 및 기타 완전 소유 플랫폼 및 제품의 사용자가 날마다 증가하는 경향이 있다는 점을 감안할 때. 페이스북이 채팅 및 커뮤니케이션 서비스와 함께 광고 및 영향력 있는 포털로 변모한 이후 서버의 데이터는 분류 및 데이터 레이블 제한을 넘어섰습니다. Facebook Inc.의 이러한 움직임이 회사에 도움이 될까요? 이에 대한 답은 그리 간단하지 않을 수 있습니다. 그때까지 우리가 할 수 있는 일은 Zuckerberg 씨가 그의 말을 어떻게 실천하는지 지켜보는 것입니다.