지금까지 빅 데이터에 대한 블로그에서 빅 데이터가 실제로 의미하는 것부터 사실과 해야 할 일과 하지 말아야 할 일에 이르기까지 빅 데이터의 다양한 측면에 대해 알려드렸습니다. 이전 블로그에서 몇 가지 빅 데이터 분석 기술을 살펴보았습니다. 이 블로그에서 목록을 자세히 살펴보세요.
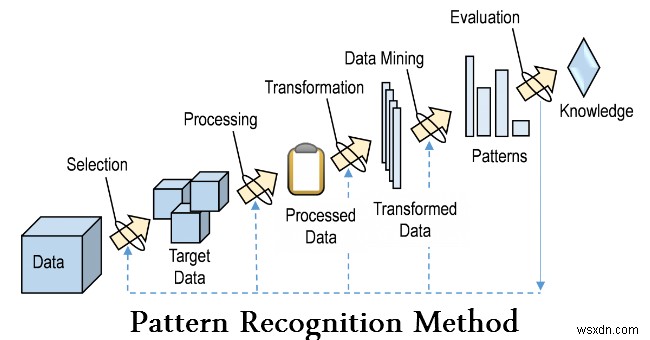
- 패턴 인식
패턴 인식은 데이터의 패턴과 규칙성을 인식하는 데 중점을 둔 기계 학습의 한 분야이지만 경우에 따라 기계 학습과 거의 동의어로 간주되기도 합니다. 패턴 인식 시스템은 많은 경우 레이블이 지정된 "훈련" 데이터(지도 학습)에서 훈련되지만 레이블이 지정된 데이터를 사용할 수 없는 경우 다른 알고리즘을 사용하여 이전에 알려지지 않은 패턴을 발견할 수 있습니다(비지도 학습).
- 예측 모델링
예측 분석은 과거 데이터와 현재 데이터를 기반으로 미래 결과를 예측하는 다양한 기술로 구성됩니다. 실제로 예측 분석은 수천 개의 센서에서 나오는 데이터 스트림을 기반으로 제트 엔진의 고장을 예측하는 것부터 고객이 무엇을 구매하는지, 언제 구매하는지, 심지어 무엇을 구매하는지에 따라 고객의 다음 행동을 예측하는 것까지 거의 모든 분야에 적용할 수 있습니다. 그들은 소셜 미디어에서 말합니다. 예측 분석 기술은 주로 통계적 방법을 기반으로 합니다.
- 회귀 분석
이것은 독립 변수를 사용하고 종속 변수에 미치는 영향을 파악하는 기술입니다. 이것은 인터넷 플랫폼에서 사랑을 찾을 확률과 같은 소셜 미디어 분석을 결정하는 데 매우 유용한 기술이 될 수 있습니다.
- 감정 분석
감정 분석은 연구원이 주제와 관련하여 화자 또는 작가의 감정을 파악하는 데 도움이 됩니다. 감정 분석은 다음을 돕기 위해 사용됩니다.
- 고객 의견을 분석하여 호텔 체인의 서비스를 개선합니다.
- 고객이 진정으로 원하는 것을 해결하기 위해 인센티브와 서비스를 맞춤화합니다.
- 소셜 미디어의 의견을 바탕으로 소비자가 실제로 생각하는 것을 판단합니다.
- 신호 처리
신호 처리는 광범위하게 지정되는 다양한 물리적, 기호 또는 추상 형식에 포함된 정보를 처리하거나 전송하는 기본 이론, 응용 프로그램, 알고리즘 및 구현을 포함하는 활성화 기술입니다. 신호 . 그것은 표현, 모델링, 분석, 합성, 발견, 복구, 감지, 수집, 추출, 학습, 보안 또는 법의학을 위해 수학적, 통계적, 계산적, 경험적, 언어적 표현, 형식 및 기술을 사용합니다. 샘플 응용 프로그램에는 시계열 분석을 위한 모델링 또는 덜 정확한 데이터 소스 집합에서 데이터를 결합하여(즉, 잡음에서 신호 추출) 보다 정확한 판독값을 결정하기 위한 데이터 융합 구현이 포함됩니다.
- 공간 분석
공간 분석은 원시 데이터를 유용한 정보로 바꾸는 프로세스입니다. It is the process of examining the locations, attributes, and relationships of features in spatial data through overlay and other analytical techniques in order to address a question or gain useful knowledge. Spatial analysis extracts or creates new information from spatial data.
- Statistics
In statistics, exploratory data analysis is an approach to analyzing data sets to summarize their main characteristics, often with visual methods. A statistical model can be used or not, but primarily EDA is for seeing what the data can tell us beyond the formal modelling or hypothesis testing task. Statistical techniques are also used to reduce the likelihood of Type I errors (“false positives”) and Type II errors (“false negatives”). An example of an application is A/B testing to determine what types of marketing material will most increase revenue.
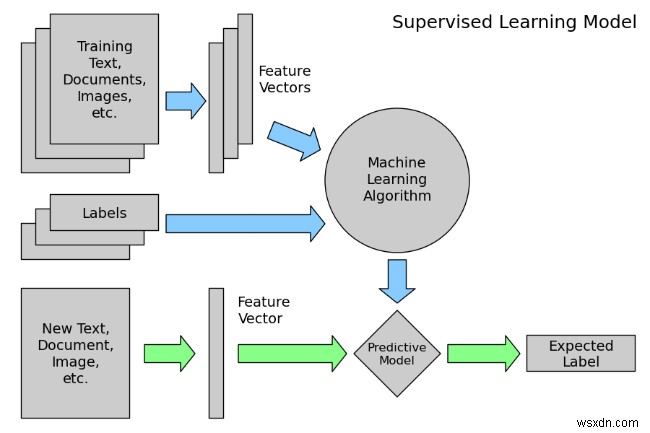
- Supervised learning
Supervised learning is the machine learning task of inferring a function from labeled training data. The training data consist of a set of training examples . In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal ). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples.
- Social Network Analysis
Social network analysis is a technique that was first used in the telecommunications industry, and then quickly adopted by sociologists to study interpersonal relationships. It is now being applied to analyze the relationships between people in many fields and commercial activities. Nodes represent individuals within a network, while ties represent the relationships between the individuals.
- Simulation
Modeling the behavior of complex systems, often used for forecasting, predicting and scenario planning. Monte Carlo simulations, for example, are a class of algorithms that rely on repeated random sampling, i.e., running thousands of simulations, each based on different assumptions. The result is a histogram that gives a probability distribution of outcomes. One application is assessing the likelihood of meeting financial targets given uncertainties about the success of various initiatives
- Time Series Analysis
Time series analysis comprises methods for analyzing time series data in order to extract meaningful statistics and other characteristics of the data. Time series data often arise when monitoring industrial processes or tracking corporate business metrics. Time series analysis accounts for the fact that data points taken over time may have an internal structure (such as autocorrelation, trend or seasonal variation) that should be accounted for. Examples of time series analysis include the hourly value of a stock market index or the number of patients diagnosed with a given condition every day.
- Unsupervised Learning
Unsupervised learning is the machine learning task of inferring a function to describe hidden structure from unlabeled data. Since the examples given to the learner are unlabeled, there is no error or reward signal to evaluate a potential solution – this distinguishes unsupervised learning from supervised learning and reinforcement learning.
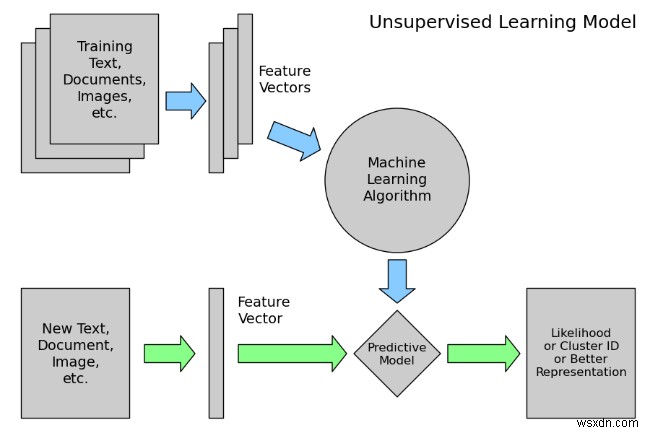
However, unsupervised learning also encompasses many other techniques that seek to summarize and explain key features of the data.
- Visualization
Data visualization is the preparation of data in a pictorial or graphical format. It enables decision makers to see analytics presented visually, so they can grasp difficult concepts or identify new patterns. With interactive visualization, you can take the concept a step further by using technology to drill down into charts and graphs for more detail, interactively changing what data you see and how it’s processed.
Conclusion
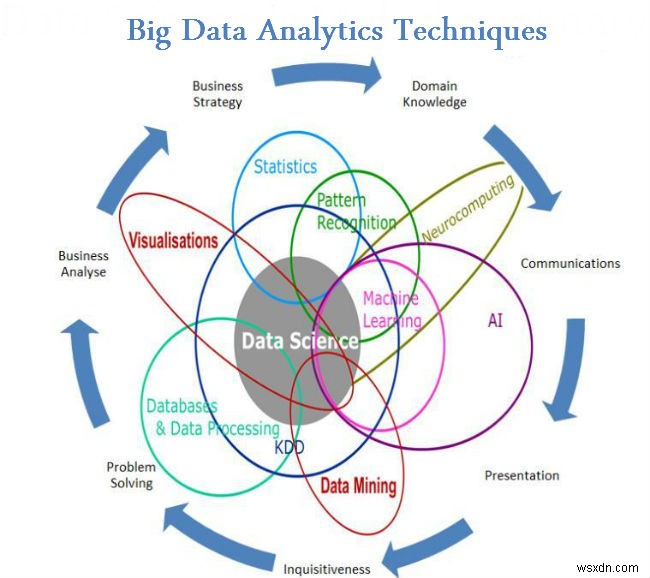
Big data analytics has been one of the most important breakthroughs in the information technology industry. In fact, Big Data has shown its importance and need almost in all sectors, and in all the departments of those industries. There is not a single aspect of life which has not been affected by Big Data, not even our personal lives. Hence we need Big Data Analytics to manage this huge amounts of Data efficiently.
As said before this list is not exhaustive. Researchers are still experimenting on new ways of Analyzing this huge amounts of Data which is present in a variety of forms whose speed of generation is increasing with time to derive values for our specific uses.