2026년 4월 19일 오전 10시(EDT) 게시됨
기술 출판 분야에서 Afam의 경험은 Make Tech Easier에서 근무했던 2018년으로 거슬러 올라갑니다. 수년에 걸쳐 그는 Windows, Linux 및 오픈 소스 도구를 다루는 고품질 가이드, 리뷰, 팁 및 설명 기사를 게시하는 것으로 명성을 쌓아왔습니다. 그의 작업은 Technical Ustad, Windows Report, Guiding Tech, Alphr 및 Next of Windows를 포함한 최고의 웹사이트에 소개되었습니다.
그는 컴퓨터 공학 1학위를 보유하고 있으며 Fuzo Tech YouTube 채널에 게시된 주제에 대한 몇 가지 팁, 비디오 및 튜토리얼을 통해 데이터 개인 정보 보호 및 보안에 대한 강력한 옹호자입니다.
그는 일하지 않을 때 가족과 함께 시간을 보내거나 자전거를 타거나 정원을 가꾸는 것을 좋아합니다.
나는 안정성 때문에 Linux를 사용하는 것을 좋아했습니다. 그러나 연중무휴 24시간 운영되는 내 홈 서버는 한계에 도달한 것처럼 보이며 최악의 순간에도 서버가 중단되는 것을 보았습니다. 때때로 원격 장치가 다시 온라인 상태가 되도록 수동으로 재부팅해야 했습니다.
이것이 직면한 시나리오라면 Linux에는 이러한 상황에 완벽한 내장 시스템이 있습니다. 이를 systemd의 서비스 복구와 결합하면 물리적 개입이 필요하지 않은 효율적인 2계층 충돌 복구 메커니즘이 제공됩니다.
 관련
관련
Linux에는 이미 복구 메커니즘이 내장되어 있습니다.
시스템을 보호하는 감시 타이머
Linux에는 watchdog이라는 기능이 내장되어 있습니다. 이 기능은 시스템이 정기적으로 활성 상태임을 나타내는 신호를 보내는 원리에 따라 작동합니다. 시스템에서 신호를 수신하지 못하는 순간 워치독은 문제가 있다고 가정하고 재부팅을 시작합니다. 이 기능은 1990년대 중반부터 Linux에 존재했으며 서버 및 임베디드 시스템과 같이 가동 시간을 협상할 수 없는 시스템에서 주로 사용되었습니다.
일부 시스템에서는 Watchdog이 /dev/watchdog을 통해 노출됩니다. 장치 파일이고 다른 파일에서는 /dev/watchdog0일 수 있습니다. . 카운트다운 타이머를 재설정하려면 프로세스가 이 파일에 써야 합니다. 프로세스가 쓰기를 중지하면 일반적으로 시스템이 정지되었거나 런어웨이 프로세스에서 리소스를 소비했음을 의미합니다. 이러한 경우 타이머가 만료되고 재부팅이 시작됩니다.
워치독에는 하드웨어와 소프트웨어(소프트독)라는 두 종류가 있습니다. 첫 번째는 마더보드의 하드웨어 메커니즘일 수 있습니다. 커널이 완전히 잠겨 있는 경우에도 항상 시스템을 재설정할 수 있습니다. 다음은 커널 내부에서 실행되며 추가 하드웨어가 필요하지 않은 소프트웨어 버전입니다. 하지만 이 버전은 커널 충돌이 발생할 경우 사용자를 구해 주지 않습니다.
<머리> <일>유형
<일>전용 하드웨어 필요
<일>하드 커널 충돌에도 살아남음
<일>다음에 가장 적합합니다.
하드웨어 감시
예
예
서버, 항상 켜져 있는 중요한 시스템
소프트웨어(소프트도그)
아니요
아니요
홈 서버, VM, 범용 장비
소프트웨어 감시 기능은 로드 급증, 메모리 고갈, 프로세스 폭주 등 대부분의 설정에서 흔히 발생하는 작동 중지에 적합합니다. 그러나 이 기능은 기본적으로 비활성화되어 있으며 잘못 구성하면 불필요하고 반복되는 시스템 재부팅이 발생할 수 있습니다. 즉, 이는 제가 가장 좋아하는 숨겨진 Linux 기능 중 하나가 되었습니다.
몇 분 만에 자동 충돌 복구 설정
실제로 작동하는 실용적인 감시 설정
Softdog은 이미 거의 모든 Linux 배포판에서 작동하므로 새 하드웨어가 필요하지 않습니다. 시작점은 다음 명령을 사용하여 모듈을 로드하는 것입니다:
sudo modprobe softdog
재부팅 후에도 소프트독이 지속되도록 하려면 /etc/modules에서 파일을 엽니다. (Debian/Ubuntu), 자체 라인에 Softdog을 추가하고 저장합니다. 이제 워치독 데몬을 설치하고 아래 명령을 사용하여 활성화하세요:
sudo apt install watchdog
sudo systemctl enable --now watchdog
이 작업이 완료되면 /etc/watchdog.conf를 열 차례입니다. 몇 가지 중요한 설정에 집중하세요:
<머리> <일>설정
<일>제어 대상
<일>실용적인 출발점
간격
시스템이 체크인하는 빈도
10초
최대-로드-1
재부팅 전 평균 한도 로드
~6× CPU 코어 수
최소 메모리
재부팅 전 여유 메모리 공간
~512페이지(~2MB)
max-load-1의 평균 로드는 1분입니다. 이 값은 장치에서 CPU 시간을 두고 적극적으로 경쟁하는 프로세스 수를 나타냅니다. 이는 4코어 시스템의 로드가 4.0이면 모든 코어가 완전히 점유된다는 의미입니다. 시스템이 잠기기 전에 합법적일 수 있는 버스트에 대비한 여유 공간을 확보할 수 있도록 코어 수를 6배로 사용하는 것이 더 안전합니다.
또한 최소 메모리는 메가바이트가 아닌 메모리 페이지로 지정됩니다. x86_64 시스템에서 한 페이지는 일반적으로 4KiB입니다. 이렇게 하면 512페이지가 약 2MB의 여유 메모리가 됩니다.
이러한 구성을 완료한 후 systemctl status watchdog 명령을 실행합니다. 데몬이 실행 중인지 확인하려면 journalctl -u watchdog 명령을 실행하세요. 활동을 검토할 수 있습니다.
watchdog 서비스를 중지해도 재부팅이 실행되지 않습니다. 종료 시 데몬이 /dev/watchdog을 완전히 닫아 타이머를 안전하게 해제합니다. 워치독이 시스템을 재부팅하는지 실제로 테스트하려면 지속적인 로드 스파이크와 같은 실제 오류 조건을 시뮬레이션해야 합니다.
모든 충돌이 재부팅이 필요한 것은 아닙니다
시스템이 손상된 서비스를 몇 초 만에 수정하도록
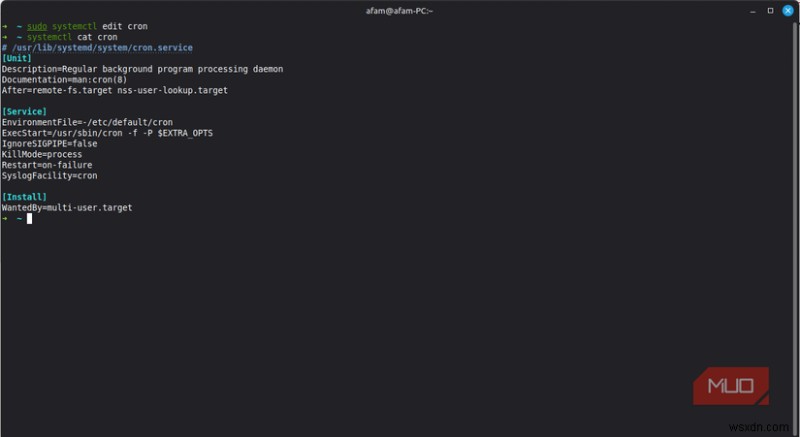
시스템을 재부팅할 필요 없이 몇 초 안에 systemd가 처리할 수 있는 몇 가지 오류가 있습니다. 충돌이 발생하거나 예기치 않게 종료되거나 응답이 중지되는 서비스를 예로 들 수 있습니다. 원래 장치를 건드리지 않고 모든 것이 재부팅을 트리거하지 않도록 검사를 적용할 수 있습니다. 아래 명령을 실행하여 서비스 이름을 추가하세요:
sudo systemctl edit
그런 다음 다음을 추가하세요:
[Service]
Restart=on-failure
RestartSec=5
Restart=on-failure는 오류 코드와 함께 서비스가 종료될 때만 다시 시작되도록 보장하고 RestartSec=5는 빠른 재시작 루프를 방지하기 위해 실제 다시 시작하기 전에 짧은 지연을 제공합니다.
StartLimitIntervalSec 결합 및 StartLimitBurst 중단된 서비스가 무기한으로 다시 시작되는 것을 방지합니다. 충돌 루프를 중지하는 데 필수적이지만 systemd 내에서 실행되는 서비스에서만 작동합니다.
거의 모든 오류를 처리하는 2단계 복구
워치독이나 시스템 서비스 관리는 그 자체로는 완전하지 않습니다. 그러나 함께 사용하면 거의 모든 것을 처리할 수 있습니다.
<머리> <일>실패 유형
<일>복구 레이어
<일>예상되는 결과
오류로 인해 서비스가 종료됩니다
systemd(재시작=실패 시)
몇 초 안에 서비스가 다시 시작됩니다
서비스는 깔끔하게 종료되지만 종료되어서는 안 됩니다
systemd (다시 시작=항상)
몇 초 안에 서비스가 다시 시작됩니다
전체 시스템 정지 또는 로드 나선형
감시 데몬
자동 재부팅, 수동 단계 없음
systemd는 개별 서비스 오류를 포착하고 다시 시작하는 데 매우 적합하며, 감시자는 그 위에 위치하여 전체 시스템을 관찰하고 systemd의 한계를 넘어서 문제가 발생할 때 다시 시작을 트리거합니다.
이 조합은 문제가 발생할 때마다 연락할 필요가 없으며 서버 관리 작업을 더욱 즐겁게 만들어줍니다. 또한 대부분의 시스템 문제를 해결하는 데 도움이 되는 특정 Linux 명령을 배우는 것도 고려해 보세요.