SQL Server 2017은 2017년 10월에 공식 출시되었습니다. SQL Server 2017의 첫 번째 부분은 2016년 말부터 출시되었으며 2017년 말 현재 10개의 릴리스가 있습니다.
SQL Server 2017 버전은 주로 Linux에 연결되어 SQL의 성능을 Linux에 제공합니다. 간단히 말해서 Linux 기반 도커 컨테이너에서 SQL Server 2017을 사용하여 Linux에 SQL Server 2017을 설치할 수 있습니다. SQL Server 2017을 사용하면 개발 언어를 선택하고 온프레미스 또는 클라우드 기반으로 개발할 수도 있습니다.
이 버전에서 SQL Server 2017은 또한 데이터베이스 엔진, 통합 서비스, 마스터 데이터 서비스, 분석 서비스 등과 같은 각 부분의 성능, 확장성 및 기능을 향상시킵니다. 이 문서에서 부분별로 살펴보겠습니다.
SQL Server 2017의 새로운 기능
- 데이터베이스 엔진의 새로운 기능
- identity_cache
- 향상된 적응형 쿼리 처리
- 자동 조정
- 그래프 DB의 새로운 기능
- 그래프 DB란 무엇입니까?
- 항상 사용 가능(교차 데이터 액세스)
- DTA 개선
- 새 문자열 함수
- 번역
- CONCATE_WS
- 트림
- STRING_AGG
- SQL 2017의 SSRS(보고 서비스)의 새로운 기능
- SQL 2017 SSIS(통합 서비스)의 새로운 기능
- SQL 2017의 Analysis Services(SSAS)의 새로운 기능은 무엇입니까?
- 머신 러닝
- 리눅스 지원
데이터베이스 엔진의 새로운 기능
identity_cache

이 옵션은 서버가 갑자기 종료되거나 장애 조치를 수행하거나 보조 서버로 전환하는 경우 ID 열 값의 편차를 방지하는 데 도움이 됩니다. ALTER DATABASE SCOPED CONFIGURATION 명령과 함께 사용하여 데이터베이스 구성 설정을 활성화합니다. 구문은 다음과 같습니다.
ALTER DATABASE SCOPED CONFIGURATION { { [ FOR SECONDARY] SET } } | CLEAR PROCEDURE_CACHE | SET < set_options > [;] < set_options > ::= { MAXDOP = { | PRIMARY } | LEGACY_CARDINALITY_ESTIMATION = { ON | OFF | PRIMARY } | PARAMETER_SNIFFING = { ON | OFF | PRIMARY } | QUERY_OPTIMIZER_HOTFIXES = { ON | OFF | PRIMARY } | IDENTITY_CACHE = { ON | OFF } } 향상된 적응형 쿼리 처리
쿼리 성능을 향상시키려면 이 새로운 기능이 큰 도움이 될 것입니다. SQL Server 및 Azure SQL Database에서 지원됩니다.
SQL 쿼리를 실행할 때 일반적인 최적화 프로세스입니다.
- 먼저 쿼리 최적화 프로그램은 방금 생성된 쿼리에 대해 가능한 모든 쿼리 실행 계획을 계산합니다.
- 다음으로 최고의/가장 빠른 계획을 보여줍니다.
- 마지막으로 쿼리를 실행하기 위해 예상되는 최상의 계획이 선택되고 실행 프로세스가 시작됩니다.
위 프로세스에는 다음과 같은 단점이 있습니다.
- 잘못된 계획의 추정치가 최선이면 성능에 영향을 미칩니다.
- 최적의 계획을 실행하기 위해 할당된 메모리가 부족하면 메모리 오버플로 오류가 발생합니다.
다음은 이러한 단점을 극복하기 위해 SQL Server 2017에 포함된 기능입니다.
배치 모드 메모리 부여 피드백(배치 모드에 대한 메모리 할당에 대한 피드백):이 피드백은 계획을 실행하는 데 필요한 메모리를 다시 계산하고 캐시에서 메모리를 할당합니다.
배치 모드 적응형 조인(배치 모드에 적응하는 조인):조인에는 해시 및 중첩 루프의 2가지 유형이 있습니다. 실행 계획 항목을 처음 입력하고 스캔할 때 최적의 속도로 출력을 얻기 위해 적용할 조인 유형을 결정합니다.
인터리브 실행:최적의 계획을 실행하는 동안 이 기능은 완벽한 요소만 계산하기 위해 다단계 테이블 값 함수를 만나면 "일시 중지"합니다. 이 표의 요소를 확인한 다음 계속해서 최적화합니다.
자동 조정
이 기능은 쿼리 성능의 문제를 검사하고 문제를 식별하고 제안된 솔루션으로 수정합니다. 이 기능에서 사용할 수 있는 자동 조정 기술은 다음과 같습니다.
자동 수정(계획):이 기술은 SQL 2017 데이터베이스에서 사용할 수 있으며 주어진 쿼리 계획에서 성능 문제를 찾은 다음 제안된 솔루션으로 수정합니다.
자동 관리(색인):이 기술은 SQL 2017 Azure DB에 포함되어 있으며 비표준 인덱스를 삭제하고 올바른 인덱스를 추가하여 인덱스의 순서를 식별하고 수정합니다. 색인.
그래프 DB의 새로운 기능
그래프 DB란 무엇입니까?
기본적으로 Graph DB는 노드와 에지의 집합이며, 에지는 노드 간의 관계를 나타내고, 노드는 엔티티이며, 에지는 여러 노드에 연결될 수 있습니다. 그래프 DB는 관계형 데이터베이스처럼 작동하며 다음과 같은 경우에 사용할 수 있습니다.
- 계층적 형식의 데이터베이스가 있고 노드에 대해 여러 부모를 저장하려는 경우
- 링크와 데이터 관계를 확인하고 분석해야 할 때
- 관계(관계)가 많을 때.
여기서 MATCH 키워드는 Graph 테이블을 쿼리하고 데이터를 정렬하는 데 사용되며 단일 쿼리의 도움으로 사용자는 그래프 및 관계형 데이터를 쿼리할 수 있습니다.
항상 사용 가능(교차 데이터 액세스)
이 기능의 도움으로 이제 서로 다른 SQL 인스턴스(다른 인스턴스 인스턴스에 연결할 수 있는 SQL 인스턴스) 간에 데이터베이스를 교차 교환할 수 있습니다. 또한 분산 데이터베이스 교환.[SQL 2016은 데이터베이스 간 액세스도 지원하지만 동일한 SQL Server 내의 인스턴스 간에만 가능합니다.]
DTA 개선
SQL 2017에서는 DTA(Database Tuning Advisor)의 성능이 향상되었습니다. 특히 DTA에 대한 옵션이 추가되었습니다.
DTA가 무엇인지 모르는 경우:
DTA는 쿼리 처리(처리)를 수행한 다음 데이터베이스 구조를 변경하여 성능을 향상시키는 데 도움이 되는 방법을 제공하는 데이터베이스 도구입니다. 데이터(예:인덱스, 잠금).DTA는 다음 두 가지 방법으로 사용할 수 있습니다.
- GUI(인터페이스) 사용
- 명령 유틸리티 사용
새 문자열 기능
SQL 2017은 사용자에게 TRANSLATE, CONCAT_WS, STRING_AGG, TRIM과 같은 몇 가지 새로운 문자열 기능을 제공합니다. . 각 기능을 하나씩 살펴보겠습니다.
번역
기본적으로 이 함수는 문자열 문자를 사용합니다. 입력 데이터로 입력한 다음 이러한 문자를 일부 새 문자로 변환합니다. 아래 구문을 참조하세요.
TRANSLATE (inputString, characters, translations)
위 구문에서 '문자'의 길이는 '번역'과 같아야 합니다. 그렇지 않으면 함수가 오류 값을 반환합니다. 예:
TRANSLATE ( '6 * {10 + 10} / [6-4]' , '[] {}' , '() ()' ) 위의 예에서 반환된 결과는 6 * (10 + 10) / (6-4)입니다. 중괄호와 대괄호가 둥근 대괄호로 변환된 것을 볼 수 있습니다.
이 함수는 REPLACE 함수와 동일한 메커니즘을 가지고 있지만 더 간단한 사용법은 REPLACE 함수를 대체하는 것입니다. 예를 들어 위와 같은 결과를 반환하고 싶지만 다음을 사용하는 경우 REPLACE 함수를 사용하면 다음 함수를 작성해야 합니다. 언뜻 보기에는 쉽지 않을 것입니다.
SELECT REPLACE (REPLACE (REPLACE (REPLACE ( '6 * {10 + 10} / [6-4]' , '{' , '(' ), '}' , ')' ), '[' , '(' ), ']' , ')' ); CONCATE_WS
이 함수의 기능은 단순히 모든 입력 인수를 지정된 구분 기호로 연결하는 것입니다. 아래 구문을 참조하십시오.
CONCAT_WS (separator, argument1, argument1 [, argumentN] .)
이 함수는 구분 기호를 사용하여 모든 인수를 연결하여 단일 문자열을 생성하므로 출력을 생성하려면 최소 2개의 인수가 필요합니다. 그렇지 않으면 결과가 대략 will 오류를 반환합니다. 예:
SELECTCONCAT_WS(',','카운트 숫자','하나','둘','셋','넷')AScounter;
위 명령에 의해 반환되는 결과는 다음과 같습니다.하나, 둘, 셋, 넷
암호화된 문자열 대신 데이터베이스 열 이름을 사용할 수도 있습니다.
트림
마지막으로 이 함수는 SQL 2017에도 등장했습니다. 기본적으로 C #의 trim 함수처럼 작동합니다. 즉, 문자열의 시작과 끝에 있는 모든 여분의 공백을 제거합니다.The 구문은 다음과 같습니다.
SELECT TRIM ( 'trim me' ) AS result;
위 명령에 의해 반환된 결과는 다음과 같습니다.trim me
이 함수는 문자열 중간에 있는 공백을 제거하지 않습니다.
STRING_AGG
이 함수는 문자열 끝에 구분 기호를 추가하지 않고 구분 기호를 사용하여 문자열의 값을 연결합니다. 입력 데이터는 VARCHAR, NVARCHAR일 수 있으며 선택적으로 WITHIN GROUP 절을 사용하여 결과의 표시 순서를 지정합니다.
아래 구문 참조:
STRING_AGG (expression, separator) []
:: =
WITHIN GROUP ( ORDER BY [ ASC | DESC ])
다음 예를 참조하십시오.
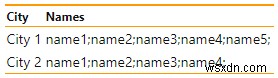
SELECT city,
STRING_AGG (name, ';' ) WITHIN GROUP ( ORDER BY name ASC ) AS names
FROM Students GROUP BY city;
위의 예에서 모든 이름은 쌍을 이루고 세미콜론(;)으로 구분되었습니다. WITHIN GROUP 절을 사용하면 순서대로 정렬할 수 있습니다. 반환된 결과는 다음과 같이 표시됩니다. 다음:
SQL 2017의 SSRS(보고 서비스)의 새로운 기능
- 이제부터 SSRS 설정은 SQL Server 설정에서 더 이상 사용할 수 없으므로 [여기] 다운로드 스토어에서 다운로드해야 합니다.
- 이제부터 쿼리 디자이너는 DAX를 지원합니다. SSAS(분석 서비스)를 방지하기 위해 네이티브 DAX 쿼리를 만들 수 있습니다. 이 기능은 SQL 도구 및 보고서 작성기의 최신 업데이트에 나타납니다.
- OpenAPI 명령은 RESTful API에서 지원되며 이제 RESTful API는 SSRS에서 지원됩니다.
- 이제부터 댓글에 더 많은 파일을 첨부할 수 있습니다.
- 보고서에 댓글을 추가할 수도 있습니다.
- 보고 서비스 포털이 크게 업그레이드되었습니다(이 기능은 SQL 2016에서 사용 가능).
SQL 2017 SSIS(통합 서비스)의 새로운 기능
이제부터 Linux에서 SSIS를 수행하고 볼륨을 늘리고 Linux에서 직접 데이터를 추출 및 변환할 수 있습니다.
크기 조정 기능을 사용하면 많은 고성능 시스템이 있는 복잡한 통합 시스템을 사용할 수 있습니다. 크기 조정 기능은 Scale Out 마스터 및 Scale Out 작업자의 도움으로 모든 작업을 수행할 수 있습니다.
SQL 2017의 Analysis Services(SSAS)의 새로운 기능
- Get Data의 새로운 인터페이스는 MS Excel, power BI와 유사한 SQL 2017에 출시되었습니다. 데이터 변환 및 데이터 매시업 기능도 등장했으며 쿼리 생성기와 M 표현식을 사용하여 이를 수행할 수 있습니다.
- SQL 2012에 도입된 제국인 SSAS의 테이블 형식 모드가 이제 SQL 2017에서 크게 업그레이드되었습니다.
- SQL 2017은 대용량 메모리에서 테이블 데이터를 최적화하는 데 사용되는 새로운 인코딩 힌트를 제공합니다.
- PIVOT의 성능을 개선합니다.
기계 학습
우리는 모두 SQL 2016이 현재 R 서비스를 지원한다는 것을 알고 있으며 앞으로 이 서비스의 이름은 SQL Server Machine Learning Services로 변경됩니다. 이 변경으로 얻을 수 있는 이점은 다음과 같습니다. SQL Server에서 R 또는 Python 명령 시스템을 쉽게 사용할 수 있습니다.
이 새로운 기능으로 Python은 저장 프로시저에서 실행할 수 있습니다. SQL Server를 통해 원격으로 명령을 실행할 수도 있습니다. 이는 Python 개발자에게 정말 유용합니다.그러나 이 기능은 현재 Linux에서는 아직 지원되지 않습니다. 다음 업그레이드를 기다려 주십시오.
더 효율적이고 최적의 방식으로 기계 학습을 사용하기 위해 SQL은 다음 솔루션을 사용합니다.
- revoscalepy 고성능 알고리즘, 계산 및 원격 상황을 위한 기초 역할을 하는 새로운 유형의 라이브러리입니다. 기본적으로 revoscalepy는 RevoScaleR 플랫폼(R 서비스 팩)을 기반으로 합니다.
- microsoftml Microsoft R입니다. 기계어 알고리즘을 지원하는 서버 클러스터를 위해 Microsoft는 내부적으로 기계 학습을 위한 이 라이브러리를 개발했습니다. 그러나 수년에 걸쳐 개선되어 이제 microsoftml은 대용량 문서 등의 변환은 물론 빠른 데이터 전송도 지원합니다.
Linux 지원
기본적으로 "SQL 2017 on Linux and Windows"라는 이름에서 바로 이 업그레이드의 주요 목적이 Linux 플랫폼에서 제품 릴리스를 지원하는 것임을 알 수 있습니다.다음은 "Linux의 SQL"의 몇 가지 주요 기능:
- 핵심 데이터베이스 저장 기능
- IPV6 지원
- NFS 지원
- Linux에서 AD 확인
- 암호화 지원
- Linux에 SSIS를 설치할 수 있음
- MSSQL-conf 명령 도구 사용 가능
- 원활한 설치 프로세스 및 자유화
- Visual Studio 코어용 SQL(VS 코어는 Linux에서 사용 가능)
- 교차 플랫폼 스크립트 생성기
요약
SQL Server에 대해 더 말하고 배울 것이 많으며 다음 섹션에서 이 여정을 계속할 것입니다. 주저하지 말고 의견과 질문을 요청하십시오!
자세히 보기:
- Windows에서 Linux 소프트웨어를 실행하는 7가지 방법
- Windows와 Linux의 8가지 주요 차이점
- MS SQL Server에서 데이터베이스에 로그인하는 방법
- MS SQL Server에서 서비스를 시작 및 중지하는 방법