원래 Tricore에서 발행:2017년 8월 2일
MongoDB를 시작하는 것은 쉽지만 애플리케이션을 구축할 때 더 복잡한 문제가 발생합니다. 다음과 같은 사항이 궁금할 수 있습니다.
- 복제 세트의 복제본 구성원을 어떻게 다시 동기화합니까?
- 충돌 후 MongoDB를 복구하려면 어떻게 해야 하나요?
- 파일을 저장하고 검색하기 위해 언제 MongoDB의 GridFS 사양을 사용해야 하나요?
- 손상된 데이터는 어떻게 수정합니까?
이 블로그 게시물은 MongoDB를 사용할 때 이러한 상황을 처리하기 위한 몇 가지 팁을 공유합니다.
팁 1:데이터 복구를 위해 복구 명령에 의존하지 마세요
데이터베이스가 충돌하고 –journal로 실행되지 않는 경우 플래그, 해당 서버의 데이터를 사용하지 마십시오.
MongoDB의 repair 명령은 찾을 수 있는 모든 문서를 살펴보고 깨끗한 복사본을 만듭니다. 그러나 이 프로세스는 시간이 많이 걸리고 많은 디스크 공간(현재 사용 중인 공간과 동일한 양)을 사용하며 손상된 레코드를 건너뜁니다. MongoDB의 복제 프로세스는 손상된 데이터를 수정할 수 없으므로 다시 동기화하기 전에 손상되었을 가능성이 있는 데이터를 지워야 합니다.
팁 2:복제 세트의 구성원 재동기화
복제 세트의 구성원을 재동기화하려면 하나 이상의 보조 구성원과 하나의 기본 구성원이 실행 중인지 확인하십시오. 그런 다음 Oracle이라는 사용자로 로그인했는지 확인하고 MongoDB 서비스를 중지합니다.
MongoDB라는 사용자로 로그인하고 문제가 발생할 경우 복원할 수 있도록 백업 폴더의 모든 데이터 파일을 이동합니다. 기존 파일이 백업 폴더에 있으면 제거할 수 있습니다. 데이터 파일을 어디에서 찾을 수 있는지 잘 모르겠다면 /etc/mongod.conf를 살펴보세요. .Oracle이라는 사용자로 MongoDB 서비스를 시작합니다.
유효성을 검사하려면 데이터베이스에 로그인하십시오. 복제본 세트에서 구성원이 동기화될 때까지 데이터베이스에 액세스하기 위해 인증할 필요가 없습니다.
복제 프로세스가 완료되면 상태가 STARTUP2에서 변경됩니다. SECONDARY로 .
팁 3:작은 바이너리 데이터에는 GridFS를 사용하지 마세요
MongoDB는 GridFS 사양을 사용하여 대용량 파일을 저장하고 검색합니다. 본질적으로 GridFS는 큰 바이너리 개체를 데이터베이스에 저장하기 전에 분해합니다. GridFS에는 파일의 메타데이터를 가져오는 쿼리와 내용을 가져오는 쿼리의 두 가지 쿼리가 필요합니다. 따라서 GridFS를 사용하여 작은 파일을 저장하면 애플리케이션에서 수행해야 하는 쿼리 수가 두 배로 늘어납니다.
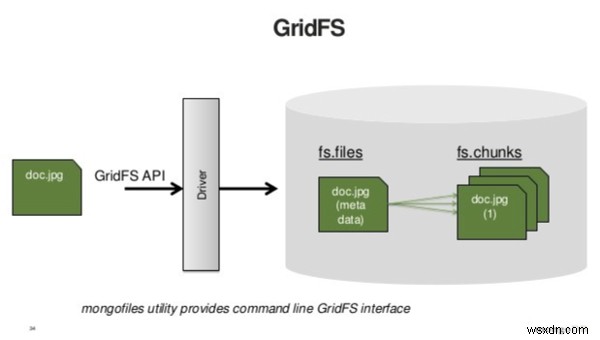
출처:https://www.slideshare.net
GridFS는 단일 문서에 담기에는 너무 큰 데이터를 의미하는 빅 데이터를 저장하도록 설계되었습니다. 일반적으로 클라이언트에 로드하기에는 너무 큰 것은 서버에 한 번에 로드하려는 것이 아닐 수 있습니다. 대안은 스트리밍입니다. 클라이언트로 스트리밍하려는 모든 것이 GridFS의 좋은 후보입니다.
팁 4:디스크 액세스 최소화
개발자는 RAM에서 데이터에 액세스하는 것이 빠르고 디스크에서 데이터에 액세스하는 것이 느리다는 것을 알고 있습니다.
디스크 액세스 수를 최소화하는 것이 훌륭한 최적화 기술이라는 것을 알고 있을 수 있지만 이 작업을 수행하는 방법을 모를 수도 있습니다.
한 가지 방법은 솔리드 스테이트 드라이브(SSD)를 사용하는 것입니다. SSD는 기존의 HDD(하드 디스크 드라이브)보다 훨씬 빠르게 많은 작업을 수행합니다. 또한 MongoDB와도 매우 잘 작동합니다. 반면에 더 작고 더 비쌉니다.
다음 이미지는 SSD와 HDD를 비교한 것입니다.

출처:https://www.serverintellect.com
디스크 액세스 수를 줄이는 또 다른 방법은 RAM을 추가하는 것입니다. 그러나 이 방법은 시간이 오래 걸리므로 결국 RAM이 데이터 크기를 수용할 수 없게 됩니다.
문제는 어떻게 테라바이트 또는 페타바이트의 데이터를 디스크에 저장하고, 자주 요청되는 데이터 메모리에 주로 액세스하는 애플리케이션을 프로그래밍하고, 디스크에서 메모리로 데이터를 가능한 한 자주 이동하지 않는 것입니다.
실시간으로 모든 데이터에 무작위로 액세스하는 경우 대답은 많은 RAM이 필요하다는 것입니다. 그러나 대부분의 응용 프로그램은 이러한 방식으로 작동하지 않습니다. 최근 데이터는 이전 데이터보다 더 자주 액세스하고 특정 사용자는 다른 사용자보다 더 활동적이며 특정 지역에는 다른 지역보다 더 많은 고객이 있습니다. 이 설명에 맞는 응용 프로그램은 특정 문서를 메모리에 유지하도록 설계할 수 있습니다. 매우 드물게 디스크에 액세스합니다.
팁 5:데이터베이스 충돌 후 정상적으로 MongoDB 시작
저널링을 실행하고 시스템이 복구 가능한 방식으로 충돌하는 경우 데이터베이스를 정상적으로 다시 시작할 수 있습니다. 모든 일반 옵션, 특히 -- dbpath를 사용하고 있는지 확인하십시오. (저널 파일을 찾을 수 있도록) 및 --journal .
MongoDB는 연결 수락을 시작하기 전에 데이터를 자동으로 수정합니다. 이 프로세스는 대용량 데이터 세트의 경우 몇 분 정도 걸릴 수 있지만 일반적으로 대용량 데이터 세트를 복구하는 데 걸리는 시간보다 훨씬 적습니다.
저널 파일은 journal에 저장됩니다. 예배 규칙서. 이 파일을 삭제하지 마십시오.
팁 6:복구 명령을 사용하여 데이터베이스 압축
수리 명령은 기본적으로 mongodump를 수행합니다. 그런 다음 mongorestore , 데이터의 깨끗한 복사본 만들기. 이 과정에서 데이터 파일의 빈 "구멍"도 제거됩니다.
복구 명령은 작업을 차단하고 데이터베이스가 현재 실행 중인 디스크 공간의 두 배를 필요로 합니다. 그러나 다른 시스템이 있는 경우 mongodump를 사용하여 수동으로 동일한 프로세스를 수행할 수 있습니다. 및 mongorestore .
프로세스를 수동으로 완료하려면 다음 단계를 따르세요.
-
Hyd1 시스템을 중단하고
fsync및lock:rs.stepDown() db.runCommand({fsync : 1, lock : 1}) -
파일을 Hyd2에 덤프:
Hyd2$ mongodump --host Hyd1 -
Hyd1에서 데이터 파일의 복사본을 만들어 여전히 백업용으로 가지고 있습니다. 그런 다음 원본 데이터 파일을 삭제하고 빈 데이터로 Hyd1을 다시 시작합니다.
-
Hyd2에서 복원합니다. 데이터 파일을 복원하려면 다음 명령을 입력하십시오.
Hyd2$ mongorestore --host Hyd1 --port 10000 # specify port if it's not 27017
결론
이러한 변경으로 인해 MongoDB 성능이 크게 향상되었습니다. MongoDB를 사용할 계획이라면 이 기사를 북마크에 추가한 다음 다시 돌아와서 다음에 새 프로젝트를 시작할 때 각 팁을 확인하는 것이 좋습니다.
2부로 구성된 이 시리즈의 2부에서는 대기업이 유용한 MongoDB 기능을 적절하게 설계, 최적화 및 구현하는 데 도움이 되는 몇 가지 팁을 공유합니다.
피드백 탭을 사용하여 의견을 남기거나 질문하십시오.