RedisTimeSeries는 네이티브 시계열 데이터 구조를 Redis로 가져오는 Redis 모듈입니다. 이전에 Sorted Sets(또는 Redis Streams)를 기반으로 구축된 시계열 솔루션은 대용량 삽입, 짧은 대기 시간 읽기, 유연한 쿼리 언어, 다운 샘플링 등과 같은 RedisTimeSeries 기능의 이점을 누릴 수 있습니다.
일반적으로 시계열 데이터는 (상대적으로) 간단합니다. 하지만 다음과 같은 다른 특성도 고려해야 합니다.
- 데이터 속도:예. 초당 수천 개의 기기에서 수백 개의 측정항목을 생각합니다.
- 볼륨(빅 데이터):몇 개월(심지어 몇 년) 동안의 데이터 축적을 생각하십시오.
따라서 RedisTimeSeries와 같은 데이터베이스는 전체 솔루션의 일부일 뿐입니다. 또한 수집하는 방법도 생각해야 합니다. (수집), 프로세스, 보내기 모든 데이터를 RedisTimeSeries에 저장합니다. 정말 필요한 것은 생산자와 소비자를 분리하는 버퍼 역할을 할 수 있는 확장 가능한 데이터 파이프라인입니다.
Apache Kafka가 등장하는 곳입니다! 핵심 브로커 외에도 Kafka Connect(이 블로그 게시물에서 제공하는 솔루션 아키텍처의 일부), 여러 언어로 된 클라이언트 라이브러리, Kafka Streams, Mirror Maker 등을 포함한 풍부한 구성 요소 에코시스템이 있습니다. 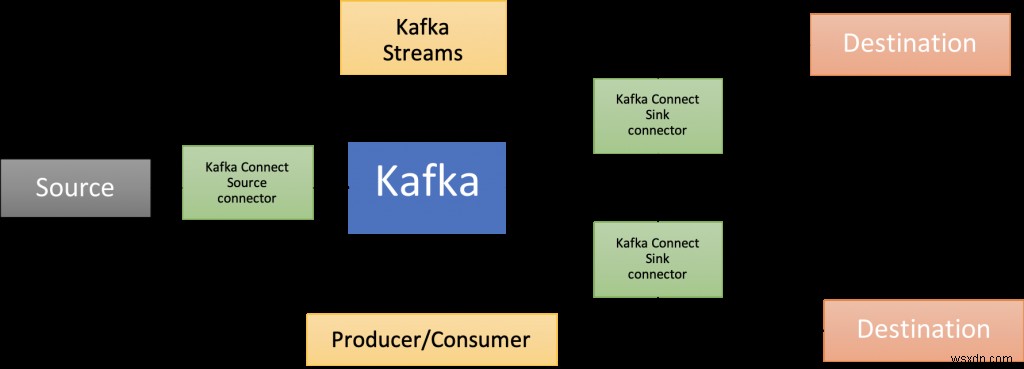
이 블로그 게시물은 시계열 데이터를 분석하기 위해 Apache Kafka와 함께 RedisTimeSeries를 사용하는 방법에 대한 실용적인 예를 제공합니다.
이 GitHub 리포지토리에서 코드를 사용할 수 있습니다. https://github.com/abhirockzz/redis-timeseries-kafka
먼저 사용 사례를 탐색하여 시작하겠습니다. 블로그 게시물의 목적을 위해 간단하게 유지한 다음 다음 섹션에서 자세히 설명합니다.
시나리오:기기 모니터링
많은 위치가 있고 각각에 여러 장치가 있고 장치 메트릭을 모니터링하는 책임이 있다고 상상해보십시오. 지금은 온도와 압력을 고려할 것입니다. 이러한 메트릭은 RedisTimeSeries에 저장되며(물론!) 키에 대해 다음 명명 규칙(
다음은 TS.ADD 명령을 사용하여 데이터 포인트를 추가하는 방법에 대한 아이디어를 제공하는 몇 가지 예입니다.
라벨과 함께 위치 3에 있는 기기 2의 온도 #:
TS.ADD temp:3:2 * 20 LABELS metric temp location 3 device 2
위치 3의 장치 2에 대한 # 압력:
TS.ADD pressure:3:2 * 60 LABELS metric pressure location 3 device 2
솔루션 아키텍처
다음은 높은 수준에서 솔루션의 모습입니다.
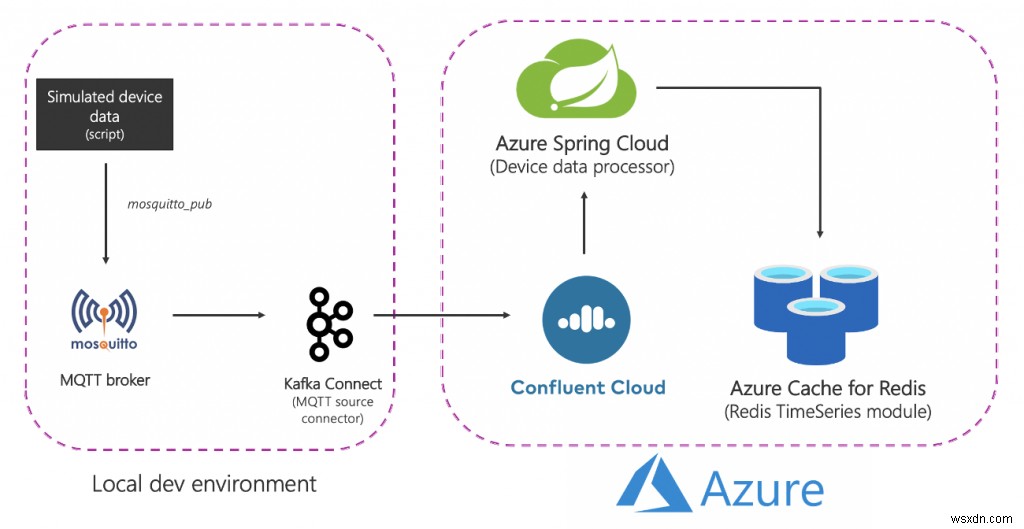
분해해 봅시다:
소스(로컬) 구성요소
- MQTT 브로커(모스키토): MQTT는 IoT 사용 사례를 위한 사실상의 프로토콜입니다. 우리가 사용할 시나리오는 IoT와 시계열의 조합입니다. 이에 대해서는 나중에 자세히 설명합니다.
- Kafka Connect:MQTT 소스 커넥터는 MQTT 브로커에서 Kafka 클러스터로 데이터를 전송하는 데 사용됩니다.
Azure 서비스
- Azure Cache for Redis Enterprise 계층:Enterprise 계층은 Redis의 Redis 상용 변형인 Redis Enterprise를 기반으로 합니다. RedisTimeSeries 외에도 Enterprise 계층은 RediSearch 및 RedisBloom도 지원합니다. 고객은 엔터프라이즈 계층에 대한 라이선스 취득에 대해 걱정할 필요가 없습니다. Azure Cache for Redis는 고객이 Azure Marketplace 제안을 통해 이 소프트웨어에 대한 라이선스를 얻고 비용을 지불할 수 있는 이 프로세스를 용이하게 합니다.
- Confluent Cloud on Azure:Azure에서 Confluent Cloud로의 통합 프로비저닝 계층 덕분에 Apache Kafka를 서비스로 제공하는 완전 관리형 제품입니다. 플랫폼 간 관리 부담을 줄이고 Azure 인프라에서 Confluent Cloud를 사용하기 위한 통합 환경을 제공하므로 Confluent Cloud를 Azure 애플리케이션과 쉽게 통합할 수 있습니다.
- Azure Spring Cloud:Azure Spring Cloud 덕분에 Azure에 Spring Boot 마이크로서비스를 더 쉽게 배포할 수 있습니다. Azure Spring Cloud는 인프라 문제를 완화하고 구성 관리, 서비스 검색, CI/CD 통합, 블루-그린 배포 등을 제공합니다. 이 서비스는 개발자가 코드에 집중할 수 있도록 모든 어려운 작업을 수행합니다.
일부 서비스는 단순하게 유지하기 위해 로컬에서 호스팅되었습니다. 프로덕션 등급 배포에서는 Azure에서도 실행하려고 합니다. 예를 들어 Azure Kubernetes Service에서 MQTT 커넥터와 함께 Kafka Connect 클러스터를 운영할 수 있습니다.
요약하자면 다음은 종단 간 흐름입니다.
- 스크립트는 로컬 MQTT 브로커로 전송되는 시뮬레이션된 기기 데이터를 생성합니다.
- 이 데이터는 MQTT Kafka Connect 소스 커넥터에서 선택되어 Azure에서 실행되는 Confluent Cloud Kafka 클러스터의 주제로 전송됩니다.
- Azure Spring Cloud에서 호스팅되는 Spring Boot 애플리케이션에 의해 추가로 처리된 다음 Azure Cache for Redis 인스턴스에 유지됩니다.
실용적인 것부터 시작할 때입니다! 그 전에 다음이 있는지 확인하십시오.
필수 조건:
- Azure 계정 — 여기에서 무료로 얻을 수 있습니다.
- Azure CLI 설치
- 예:JDK 11 OpenJDK
- Maven 및 Git의 최신 버전
인프라 구성요소 설정
설명서에 따라 RedisTimeSeries 모듈과 함께 제공되는 Azure Cache for Redis(Enterprise Tier)를 프로비저닝하세요.
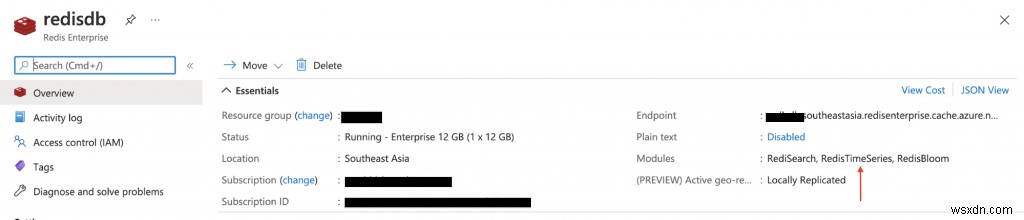
Azure Marketplace에서 Confluent Cloud 클러스터를 프로비저닝합니다. 또한 Kafka 주제(mqtt.device-stats) and create credentials (API key and secret) that you will use later on to connect to your cluster securely.

Azure Portal을 사용하거나 Azure CLI를 사용하여 Azure Spring Cloud 인스턴스를 프로비저닝할 수 있습니다.
az spring-cloud create -n <name of Azure Spring Cloud service> -g <resource group name> -l <enter location e.g southeastasia>
계속 진행하기 전에 GitHub 리포지토리를 복제해야 합니다.
git clone https://github.com/abhirockzz/redis-timeseries-kafka
cd redis-timeseries-kafka로컬 서비스 설정
구성 요소는 다음과 같습니다.
- 모스키토 MQTT 브로커
- MQTT 소스 커넥터를 사용한 Kafka Connect
- 대시보드에서 시계열 데이터를 추적하기 위한 Grafana
MQTT 브로커
Mac에서 로컬로 모기 브로커를 설치하고 시작했습니다.
brew install mosquitto
brew services start mosquittoOS에 해당하는 단계를 따르거나 이 Docker 이미지를 자유롭게 사용할 수 있습니다.
그라파나
Mac에서 로컬로 Grafana를 설치하고 시작했습니다.
brew install grafana
brew services start grafanaOS에 대해 동일한 작업을 수행하거나 이 Docker 이미지를 자유롭게 사용할 수 있습니다.
docker run -d -p 3000:3000 --name=grafana -e "GF_INSTALL_PLUGINS=redis-datasource" grafana/grafana카프카 커넥트
방금 복제한 저장소에서 connect-distributed.properties 파일을 찾을 수 있어야 합니다. bootstrap.servers, sasl.jaas.config 등과 같은 속성 값을 바꾸십시오.
먼저 Apache Kafka를 로컬에서 다운로드하고 압축을 풉니다.
로컬 Kafka Connect 클러스터 시작:
export KAFKA_INSTALL_DIR=<kafka installation directory e.g. /home/foo/kafka_2.12-2.5.0>
$KAFKA_INSTALL_DIR/bin/connect-distributed.sh connect-distributed.propertiesMQTT 소스 커넥터를 수동으로 설치하려면:
- 이 링크에서 커넥터/플러그인 ZIP 파일을 다운로드하고,
- Connect 작업자의 plugin.path 구성 속성에 나열된 디렉토리 중 하나로 압축을 풉니다.
로컬에서 Confluent Platform을 사용하는 경우 Confluent Hub CLI를 사용하기만 하면 됩니다. confluent-hub install confluentinc/kafka-connect-mqtt:latest
MQTT 소스 커넥터 인스턴스 만들기
mqtt-source-config.json 파일을 확인하십시오. kafka.topic에 대한 올바른 주제 이름을 입력하고 mqtt.topics를 변경하지 않은 상태로 두십시오.
curl -X POST -H 'Content-Type: application/json'
https://localhost:8083/connectors -d @mqtt-source-config.json
# wait for a minute before checking the connector status
curl https://localhost:8083/connectors/mqtt-source/status기기 데이터 프로세서 애플리케이션 배포
방금 복제한 GitHub 리포지토리에서 consumer/src/resources folder and replace the values for:
- Azure Cache for Redis 호스트, 포트 및 기본 액세스 키
- Confluent Cloud on Azure API 키 및 비밀
애플리케이션 JAR 파일 빌드:
cd consumer
export JAVA_HOME=<enter absolute path e.g. /Library/Java/JavaVirtualMachines/zulu-11.jdk/Contents/Home>
mvn clean packageAzure Spring Cloud 애플리케이션을 만들고 여기에 JAR 파일을 배포합니다.
az spring-cloud app create -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --runtime-version Java_11
az spring-cloud app deploy -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --jar-path target/device-data-processor-0.0.1-SNAPSHOT.jar시뮬레이트된 기기 데이터 생성기 시작
방금 복제한 GitHub 리포지토리에서 스크립트를 사용할 수 있습니다.
./gen-timeseries-data.sh참고 - mosquitto_pub CLI 명령을 사용하여 데이터를 전송하기만 하면 됩니다.
데이터는 device-stats MQTT 주제로 전송됩니다(이것은 아닙니다. 카프카 주제). CLI 구독자를 사용하여 다시 확인할 수 있습니다.
mosquitto_sub -h localhost -t device-statsConfluent Cloud 포털에서 Kafka 주제를 확인하세요. Azure Spring Cloud에서 장치 데이터 프로세서 앱에 대한 로그도 확인해야 합니다.
az spring-cloud app logs -f -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group>Grafana 대시보드를 즐기세요!
localhost:3000에서 Grafana UI로 이동합니다.
Grafana용 Redis 데이터 소스 플러그인은 Azure Cache for Redis를 비롯한 모든 Redis 데이터베이스에서 작동합니다. 이 블로그 게시물의 지침에 따라 데이터 소스를 구성하세요.
복제한 GitHub 리포지토리의 grafana_dashboards 폴더에서 대시보드를 가져옵니다(대시보드 가져오기 방법에 대한 도움이 필요한 경우 Grafana 설명서 참조).
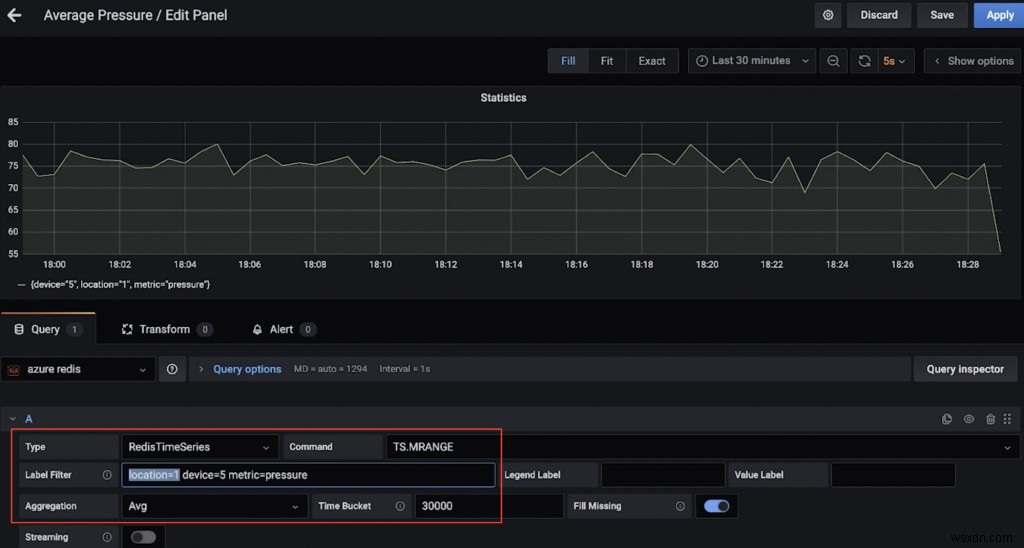
예를 들어, 다음은 위치 1(TS.MRANGE 사용)의 장치 5에 대한 평균 압력(30초 이상)을 보여주는 대시보드입니다.
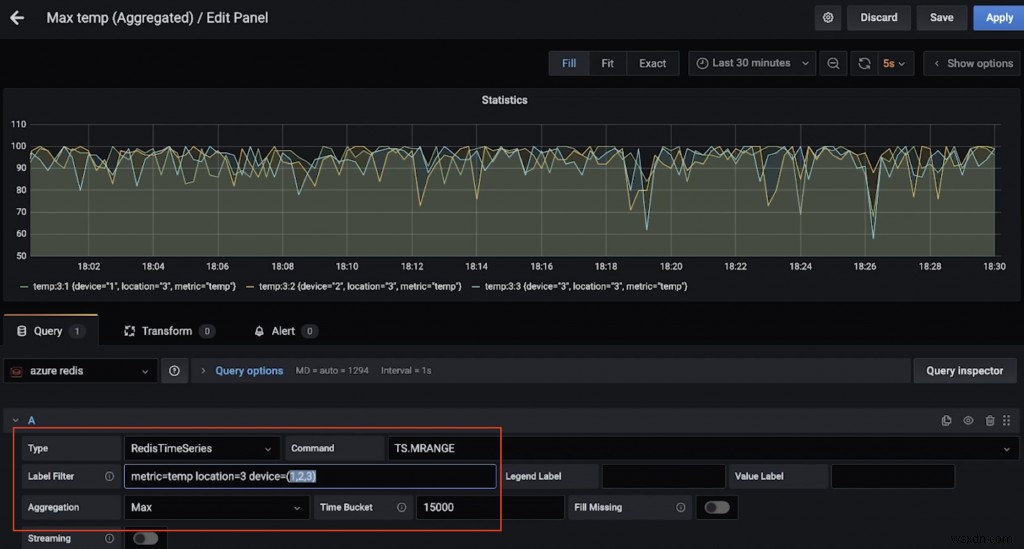
다음은 위치 3에 있는 여러 장치의 최대 온도(15초 이상)를 보여주는 또 다른 대시보드입니다(다시 TS.MRANGE 덕분).
그래서 RedisTimeSeries 명령을 실행하시겠습니까?
redis-cli를 크랭크업하고 Azure Cache for Redis 인스턴스에 연결합니다.
redis-cli -h <azure redis hostname e.g. myredis.southeastasia.redisenterprise.cache.azure.net> -p 10000 -a <azure redis access key> --tls간단한 쿼리로 시작:
# pressure in device 5 for location 1
TS.GET pressure:1:5
# temperature in device 5 for location 4
TS.GET temp:4:5위치별로 필터링하고 모든 에 대한 온도 및 기압 확인 기기:
TS.MGET WITHLABELS FILTER location=3특정 시간 범위 내에서 하나 이상의 위치에 있는 모든 장치의 온도 및 압력 추출:
TS.MRANGE - + WITHLABELS FILTER location=3
TS.MRANGE - + WITHLABELS FILTER location=(3,5)– +는 처음부터 최신 타임스탬프까지 모든 것을 나타내지만 더 구체적일 수 있습니다.
MRANGE is what we needed! We can also filter by a specific device in a location and further drill down by either temperature or pressure:
TS.MRANGE - + WITHLABELS FILTER location=3 device=2
TS.MRANGE - + WITHLABELS FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS FILTER location=3 device=2 metric=temp이 모든 것을 집계와 결합할 수 있습니다.
# all the temp data points are not useful. how about an average (or max) instead of every temp data points?
TS.MRANGE - + WITHLABELS AGGREGATION avg 10000 FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS AGGREGATION max 10000 FILTER location=3 metric=temp이 집계를 수행하고 다른 시계열에 저장하는 규칙을 만드는 것도 가능합니다.
완료되면 불필요한 비용을 피하기 위해 리소스를 삭제하는 것을 잊지 마십시오.
리소스 삭제
- 문서의 단계에 따라 Confluent Cloud 클러스터를 삭제합니다. Confluent 조직을 삭제하기만 하면 됩니다.
- 마찬가지로 Azure Cache for Redis 인스턴스도 삭제해야 합니다.
로컬 컴퓨터에서:
- Kafka Connect 클러스터 중지
- 모기 브로커 중지(예:양조 서비스에서 모기 중지)
- Grafana 서비스 중지(예:양조 서비스 중지 grafana)
Redis 및 Kafka를 사용하여 시계열 데이터를 수집, 처리 및 쿼리하는 데이터 파이프라인을 탐색했습니다. 다음 단계를 생각하고 프로덕션 등급 솔루션으로 이동할 때 몇 가지를 더 고려해야 합니다.
추가 고려사항
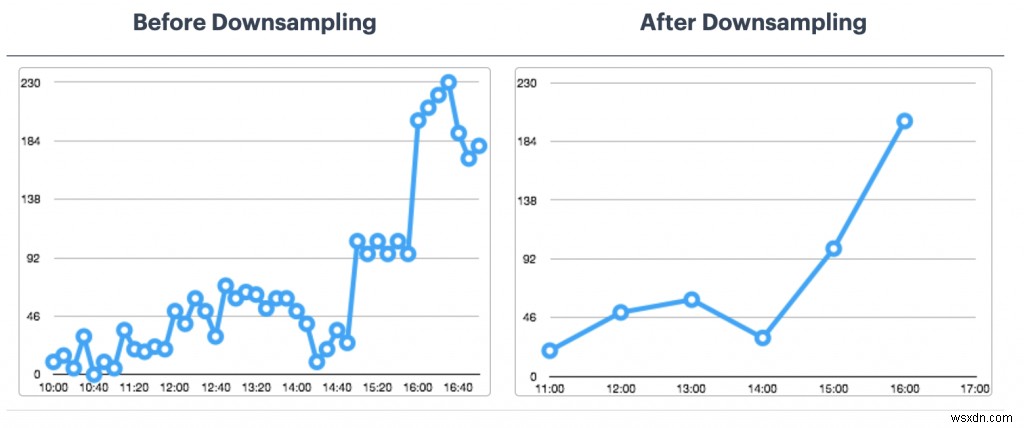
RedisTimeSeries 최적화
- 보존 정책:시계열 데이터 포인트는 그렇지 않으므로 이에 대해 생각해 보십시오. 기본적으로 잘리거나 삭제됩니다.
- 다운샘플링 및 집계 규칙:데이터를 영원히 저장하고 싶지 않죠? 이를 처리하기 위해 적절한 규칙을 구성해야 합니다(예:TS.CREATERULE temp:1:2 temp:avg:30 AGGREGATION avg 30000).
- 중복 데이터 정책:중복 샘플을 어떻게 처리하시겠습니까? 기본 정책(BLOCK)이 실제로 필요한지 확인하십시오. 그렇지 않다면 다른 옵션을 고려하십시오.
이것은 완전한 목록이 아닙니다. 다른 구성 옵션은 RedisTimeSeries 문서를 참조하십시오.
장기 데이터 보존은 어떻습니까?
시계열을 포함한 데이터는 소중합니다! 추가 처리를 원할 수 있습니다(예:통찰력 추출을 위한 기계 학습 실행, 예측 유지 관리 등). 이것이 가능하려면 이 데이터를 더 오랜 기간 동안 유지해야 하며, 이것이 비용 효율적이고 효율적이려면 Azure Data Lake Storage Gen2(ADLS Gen2)와 같은 확장 가능한 개체 스토리지 서비스를 사용하고 싶을 것입니다. .
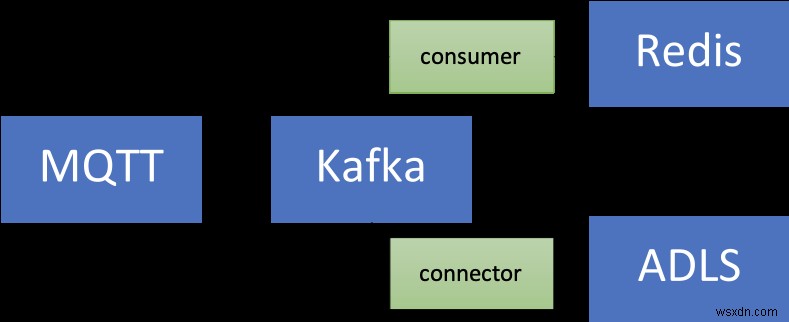
이를 위한 커넥터가 있습니다! 완전 관리형 Azure Data Lake Storage Gen2 싱크 커넥터 for Confluent Cloud를 사용하여 ADLS에서 데이터를 처리 및 저장한 다음 Azure Synapse Analytics 또는 Azure Databricks를 사용하여 기계 학습을 실행하여 기존 데이터 파이프라인을 향상할 수 있습니다.
확장성
시계열 데이터 볼륨은 한 방향으로만 이동할 수 있습니다. 솔루션의 확장성은 매우 중요합니다.
- 핵심 인프라:관리 서비스를 사용하면 특히 Redis 및 Kafka와 같은 스트리밍 플랫폼 및 데이터베이스와 같은 복잡한 분산 시스템과 관련하여 팀이 인프라를 설정 및 유지 관리하는 대신 솔루션에 집중할 수 있습니다.
- Kafka Connect:데이터 파이프라인에 관한 한 Kafka Connect 플랫폼은 본질적으로 상태 비저장이고 수평 확장이 가능하기 때문에 손에 꼽을 수 있습니다. Kafka Connect 작업자 클러스터를 설계하고 크기를 조정하는 방법과 관련하여 많은 옵션이 있습니다.
- 맞춤형 애플리케이션:이 솔루션의 경우와 마찬가지로 Kafka 주제의 데이터를 처리하는 맞춤식 애플리케이션을 구축했습니다. 다행히도 동일한 확장성 특성이 적용됩니다. 수평적 규모의 관점에서 보면 보유하고 있는 Kafka 주제 파티션의 수에 의해서만 제한됩니다.
통합 :그라파나 뿐만이 아닙니다! RedisTimeSeries는 Prometheus 및 Telegraf와도 통합됩니다. 그러나 이 블로그 게시물을 작성할 당시에는 Kafka 커넥터가 없었습니다. 이것은 훌륭한 추가 기능이 될 것입니다!
결론

물론, 시계열 워크로드를 포함하여 (거의) 모든 것에 Redis를 사용할 수 있습니다! 데이터 파이프라인 및 시계열 데이터 소스에서 Redis 및 그 이상까지의 통합을 위한 종단 간 아키텍처에 대해 생각해 보십시오.