웹 스크레이퍼 구축에 대한 이 시리즈에 다시 오신 것을 환영합니다. 이 튜토리얼에서는 내 팟캐스트 사이트에서 데이터를 스크랩하는 예를 살펴보겠습니다. 데이터를 추출한 방법, 도우미 및 유틸리티 메서드가 작업을 수행하는 방법, 모든 퍼즐 조각이 함께 모이는 방법에 대해 자세히 설명합니다.
주제
- 내 팟캐스트 스크랩
- 프라이
- 스크레이퍼
- 도우미 방법
- 게시물 작성
내 팟캐스트 스크랩
지금까지 배운 것을 실천해 봅시다. 여러 가지 이유로 내 팟캐스트의 재설계 Between | 화면이 오랫동안 지연되었습니다. 아침에 눈을 떴을 때 비명을 지르게 한 문제가 있었습니다. 그래서 Middleman으로 구축하고 GitHub Pages에서 호스팅하는 완전히 새로운 정적 사이트를 설정하기로 결정했습니다.
나는 Middleman 블로그를 필요에 맞게 조정한 후 새로운 디자인에 상당한 시간을 투자했습니다. 데이터베이스 지원 Sinatra 앱에서 콘텐츠를 가져오는 일만 남았으므로 기존 콘텐츠를 스크랩하여 새로운 정적 사이트로 전송해야 했습니다.
내 친구인 Nokogiri와 Mechanize에게 의지할 수 있었기 때문에 이 작업을 schmuck 방식으로 손으로 하는 것은 테이블 위에 있지 않았습니다. 심지어 질문도 없었습니다. 당신 앞에 있는 것은 너무 복잡하지 않지만 웹 스크래핑 초보자에게 교육적이어야 하는 몇 가지 흥미로운 비틀기를 제공하는 합리적으로 작은 스크래핑 작업입니다.
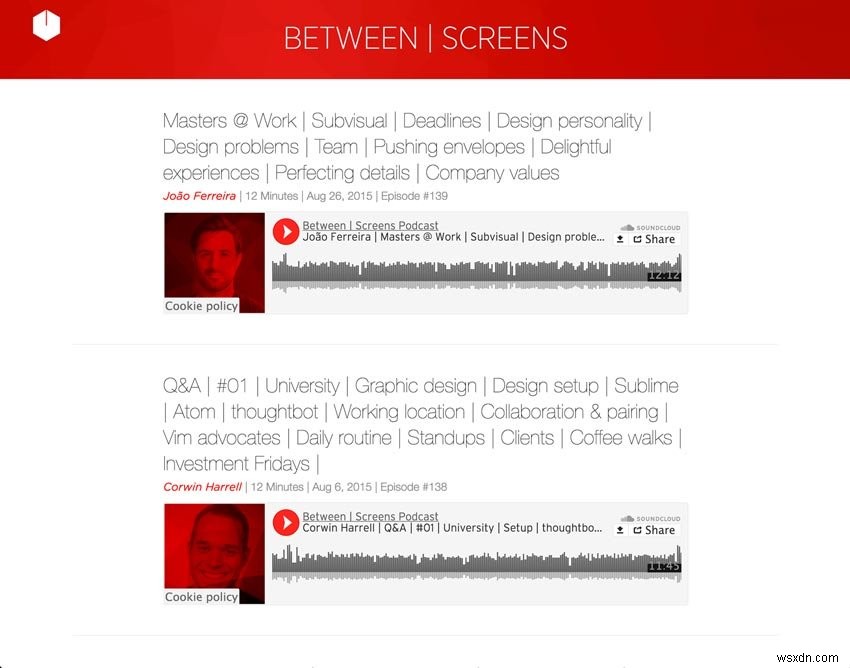
아래는 제 팟캐스트의 두 스크린샷입니다.
오래된 팟캐스트 스크린샷
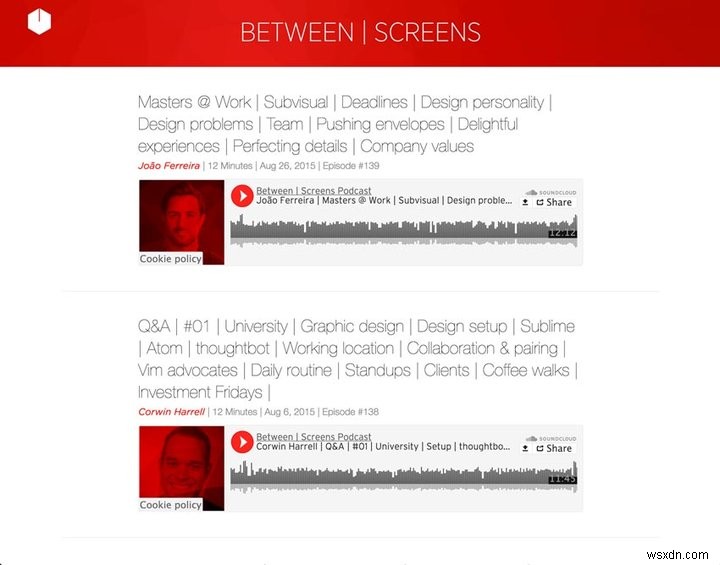
새 팟캐스트 스크린샷
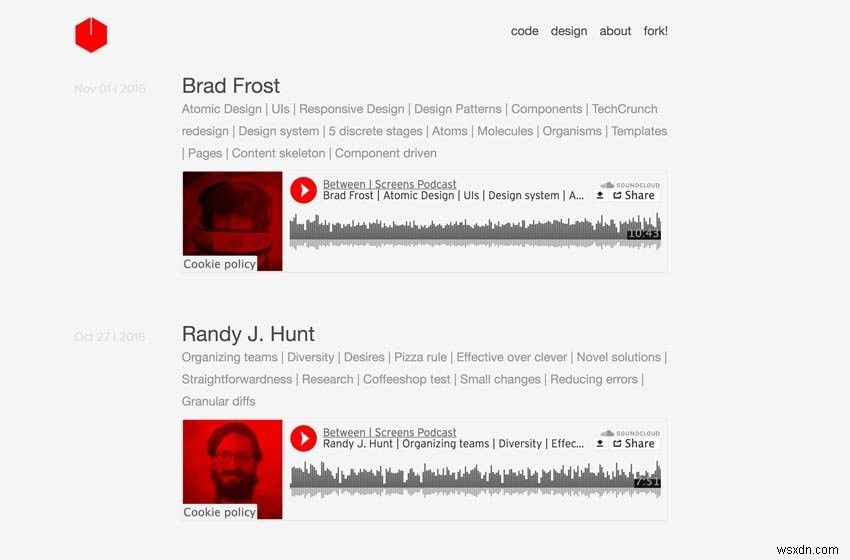
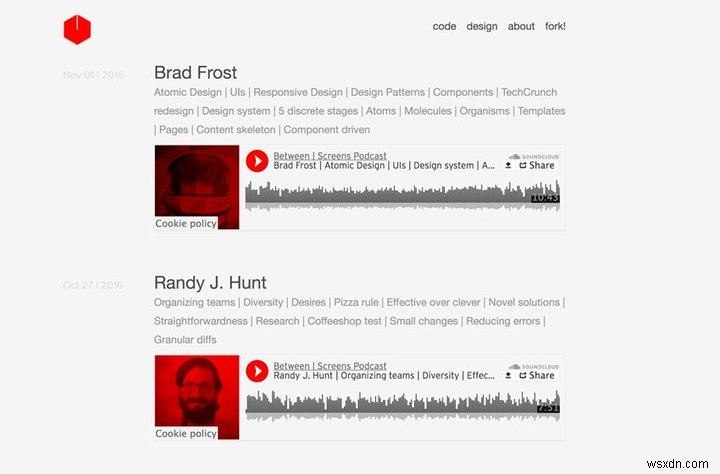
우리가 성취하고자 하는 것을 분해해 봅시다. 페이지가 매겨진 21개의 인덱스 사이트에 걸쳐 있는 139개의 에피소드에서 다음 데이터를 추출하고자 합니다.
- 제목
- 인터뷰 대상자
- 주제 목록이 있는 하위 헤더
- 각 에피소드의 SoundCloud 트랙 번호
- 날짜
- 에피소드 번호
- 쇼 노트의 텍스트
- 쇼 노트의 링크
페이지 매김을 반복하고 Mechanize가 에피소드의 모든 링크를 클릭하도록 합니다. 다음 세부 정보 페이지에서 위에서 필요한 모든 정보를 찾을 수 있습니다. 스크랩한 데이터를 사용하여 각 에피소드에 대한 마크다운 파일의 머리말과 '본문'을 채우고자 합니다.
아래에서 추출한 콘텐츠로 새 마크다운 파일을 구성하는 방법에 대한 미리보기를 볼 수 있습니다. 이것이 우리 앞에 놓인 범위에 대한 좋은 아이디어를 줄 것이라고 생각합니다. 이것은 우리의 작은 스크립트의 마지막 단계를 나타냅니다. 걱정하지 마세요. 자세히 살펴보겠습니다.
def compose_markdown
def compose_markdown(options={})<<-HEREDOC--- title:#{options[:interviewee]}인터뷰 대상:#{options[:interviewee]}topic_list:#{options[:title]}태그:#{options[:tags]}soundcloud_id:#{options[:sc_id]}날짜:#{options[:date]}episode_number:#{options[:episode_number]}---#{options[:text]}HEREDOCend
또한 기존 사이트에서 재생할 수 없는 몇 가지 트릭을 추가하고 싶었습니다. 맞춤형 종합 태깅 시스템을 갖추는 것은 저에게 매우 중요했습니다. 나는 청취자들이 깊은 발견 도구를 갖기를 원했습니다. 따라서 모든 인터뷰 대상자에 대한 태그가 필요했고 하위 헤더도 태그로 분할했습니다. 시즌 1에만 139화를 제작하다 보니 콘텐츠의 양이 점점 많아지는 시기를 대비해 현장을 준비해야 했다. 지능적으로 배치된 권장 사항이 포함된 심층 태깅 시스템이 올바른 방법이었습니다. 이를 통해 사이트를 가볍고 빠르게 유지할 수 있었습니다.
내 사이트의 콘텐츠를 스크랩하기 위한 전체 코드를 살펴보겠습니다. 주위를 둘러보고 무슨 일이 일어나고 있는지 큰 그림을 파악하려고 노력하십시오. 나는 당신이 사물의 초심자 측에 있기를 기대하기 때문에 너무 많이 추상화하지 않고 명확성의 면에서 오류를 범했습니다. 코드 명확성을 돕기 위한 몇 가지 리팩토링을 수행했지만 이 문서를 완료한 후 재생할 수 있도록 뼈대에 약간의 고기도 남겼습니다. 결국 양질의 학습은 읽기를 넘어 스스로 코드를 가지고 놀 때 발생합니다.
그 과정에서 코드를 개선할 수 있는 방법에 대해 생각하기 시작하는 것이 좋습니다. 이것은 이 기사의 끝에서 마지막 작업이 될 것입니다. 약간의 힌트:큰 방법을 작은 방법으로 나누는 것은 항상 좋은 출발점입니다. 코드가 어떻게 작동하는지 이해하고 나면 해당 리팩토링에 집중하는 즐거운 시간을 보내야 합니다.
나는 이미 여러 가지 방법을 작고 집중된 도우미로 추출하는 것으로 시작했습니다. 코드 냄새와 리팩토링에 대한 이전 기사에서 배운 내용을 쉽게 적용할 수 있어야 합니다. 이것이 여전히 당신의 머리 위에 지금이라면 걱정하지 마십시오. 우리는 모두 거기에있었습니다. 계속 하다 보면 어느 순간 더 빠르게 클릭이 시작될 것입니다.
전체 코드
require 'Mechanize'require 'Pry'require 'date'# 도우미 방법# (추출 방법)def extract_interviewee(detail_page) Interviewee_selector ='.episode_sub_title span' detail_page.search(interviewee_selector).text.stripenddef extract_title(detail_page) =".episode_title" detail_page.search(title_selector).text.gsub(/[?#]/, '')enddef extract_soundcloud_id(detail_page) sc =detail_page.iframes_with(href:/soundcloud.com/).to_s sc.scan (/\d{3,}/).firstenddef extract_shownotes_text(detail_page) shownote_selector ="#shownote_container> p" detail_page.search(shownote_selector)enddef extract_subtitle(detail_page) subheader_selector =".episode_sub_title" 추출 detail_page.search(). (episode_subtitle) number =/[#]\d*/.match(episode_subtitle) clean_episode_number(number)end# (Utility Methods)def clean_date(episode_subtitle) string_date =/[^|]*([,])(... ..)/.match(episode_subtitle).to_s Date.parse(string_date)endde f build_tags(제목, 인터뷰 대상자) 추출된 태그 =스트립_파이프(제목) "#{인터뷰 대상자}"+ ", #{extracted_tags}"enddef 스트립_파이프(텍스트) 태그 =text.tr('|', ',') 태그 =태그. gsub(/[@?#&]/, '') tags.gsub(/[w\/]{2}/, 'with')enddef clean_episode_number(숫자) number.to_s.tr('#', '' )enddef dasherize(텍스트) text.lstrip.rstrip.tr(' ', '-')enddef extract_data(detail_page) 인터뷰 대상자 =extract_interviewee(detail_page) 제목 =extract_title(detail_page) sc_id =extract_soundcloud_id(detail_page) 텍스트 =extract_shownotes_text(detail_page) episode_subtitle =extract_subtitle(detail_page) episode_number =extract_episode_number(episode_subtitle) date =clean_date(episode_subtitle) tags =build_tags(title, 인터뷰 대상자) options ={ 인터뷰 대상자:인터뷰 대상자, 제목:제목, sc_id:sc_id, 텍스트:텍스트, 태그:태그, 날짜 :날짜, 에피소드 번호:에피소드 번호 }enddef compose_markdown(옵션={})<<-HEREDOC--- 제목:#{옵션 s[:interviewee]}면접 대상자:#{options[:interviewee]}topic_list:#{options[:title]}태그:#{options[:tags]}soundcloud_id:#{options[:sc_id]}날짜:#{ options[:date]}episode_number:#{options[:episode_number]}---#{options[:text]}HEREDOCenddef write_page(link) detail_page =link.click extracted_data =extract_data(detail_page) markdown_text =compose_markdown(extracted_data) 날짜 =Extracted_data[:date]인터뷰 대상자 =Extracted_data[:인터뷰 대상자]에피소드_번호 =extracted_data[:episode_number] File.open("#{날짜}-#{dasherize(인터뷰 대상자)}-#{에피소드_번호}.html.erb.md", 'w') { |파일| file.write(markdown_text) }enddef 스크랩 link_range =1 에이전트 ||=Mechanize.new 까지 link_range ==21 page =agent.get("https://between-screens.herokuapp.com/?page=#{link_range} ") link_range +=1 page.links[2..8].map do |link| write_page(link) endendscrape 끝
require "Nokogiri" ? Mechanize는 우리의 모든 스크래핑 요구 사항을 제공합니다. 이전 기사에서 논의한 바와 같이 Mechanize는 Nokogiri를 기반으로 하며 콘텐츠를 추출할 수도 있습니다. 그러나 첫 번째 기사에서 이 보석 위에 빌드해야 했기 때문에 이 보석을 다루는 것이 중요했습니다.
프라이
먼저 첫 번째 것들. 여기에서 코드를 시작하기 전에 코드가 모든 단계에서 예상대로 작동하는지 효율적으로 확인할 수 있는 방법을 보여줘야 한다고 생각했습니다. 분명히 눈치채셨겠지만, 저는 믹스에 다른 도구를 추가했습니다. 무엇보다도 Pry 디버깅에 정말 편리합니다.
Pry.start(binding)를 배치하면 코드의 어느 곳에서나 정확히 그 지점에서 애플리케이션을 검사할 수 있습니다. 애플리케이션의 특정 지점에서 개체를 엿볼 수 있습니다. 이것은 발에 걸려 넘어지지 않고 단계별로 응용 프로그램을 수행하는 데 정말 도움이 됩니다. 예를 들어 write_page 바로 뒤에 배치해 보겠습니다. 기능을 수행하고 link인지 확인하십시오. 우리가 기대하는 것입니다.
프라이
...def 스크랩 link_range =1 에이전트 ||=Mechanize.new until link_range ==21 page =agent.get("https://between-screens.herokuapp.com/?page=#{link_range}" ) link_range +=1 page.links[2..8].map do |link| write_page(link) Pry.start(binding) end endend...
스크립트를 실행하면 다음과 같이 됩니다.
출력
»$ ruby noko_scraper.rb 321:def scrape 322:link_range =1 323:에이전트 ||=Mechanize.new 324:326:link_range ==21 327까지:page =agent.get("https://between -screens.herokuapp.com/?page=#{link_range}") 328:link_range +=1 329:330:page.links[2..8].map do |link| 331:write_page(링크) => 332:Pry.start(바인딩) 333:끝 334:끝 335:끝[1] pry(main)>
그런 다음 link를 요청할 때 다른 구현 세부정보로 넘어가기 전에 올바른 방향으로 가고 있는지 확인할 수 있습니다.
터미널
[2] pry(main)> link=> #
우리에게 필요한 것 같습니다. 좋습니다. 계속 진행할 수 있습니다. 전체 애플리케이션을 통해 이 단계를 수행하는 것은 길을 잃지 않고 작동 방식을 진정으로 이해하기 위한 중요한 방법입니다. Pry를 여기에서 더 자세히 다루지는 않겠습니다. 그렇게 하려면 적어도 또 다른 전체 기사가 필요하기 때문입니다. 표준 IRB 쉘의 대안으로만 사용하는 것이 좋습니다. 우리의 주요 작업으로 돌아갑니다.
스크레이퍼
이제 제자리에 있는 퍼즐 조각에 익숙해질 기회를 얻었으므로 하나씩 살펴보고 여기 저기에서 몇 가지 흥미로운 점을 명확히 하는 것이 좋습니다. 중앙 조각부터 시작하겠습니다.
podcast_scraper.rb
...def write_page(링크) detail_page =link.click extracted_data =extract_data(detail_page) markdown_text =compose_markdown(extracted_data) date =extracted_data[:date] 인터뷰 대상자 =extracted_data[:인터뷰 대상자] episode_number =extracted_data[:episode_number] file_name ="#{날짜}-#{대셔라이즈(인터뷰 대상자)}-#{에피소드 번호}.html.erb.md" File.open(file_name, 'w') { |file| file.write(markdown_text) }enddef 스크랩 link_range =1 에이전트 ||=Mechanize.new 까지 link_range ==21 page =agent.get("https://between-screens.herokuapp.com/?page=#{link_range} ") link_range +=1 page.links[2..8].map do |link| write_page(링크) 끝 끝...
scrape에서 일어나는 일 방법? 우선 이전 팟캐스트의 모든 색인 페이지를 반복합니다. 새로운 사이트가 이미 betweenscreens.fm에 온라인 상태이므로 Heroku 앱의 이전 URL을 사용하고 있습니다. 반복해야 할 에피소드가 20페이지나 있었습니다.
link_range를 통해 루프를 구분했습니다. 각 루프와 함께 업데이트한 변수입니다. 페이지 매김을 통과하는 것은 각 페이지의 URL에서 이 변수를 사용하는 것처럼 간단했습니다. 간단하고 효과적입니다.
데프 스크래핑
페이지 =agent.get("https://between-screens.herokuapp.com/?page=#{link_range}")
그런 다음 스크랩할 8개의 에피소드가 있는 새 페이지가 있을 때마다 page.links를 사용합니다. 클릭하려는 링크를 식별하고 각 에피소드의 세부 정보 페이지로 이동합니다. 다양한 링크(links[2..8] ) 모든 페이지에서 일관적이었습니다. 또한 각 색인 페이지에서 필요한 링크를 대상으로 지정하는 가장 쉬운 방법이었습니다. 여기에서 CSS 선택기를 더듬을 필요가 없습니다.
그런 다음 세부 정보 페이지에 대한 해당 링크를 write_page에 제공합니다. 방법. 이것은 대부분의 작업이 수행되는 곳입니다. 해당 링크를 클릭하여 데이터 추출을 시작할 수 있는 세부 정보 페이지로 이동합니다. 해당 페이지에서 새 사이트에 대한 새 마크다운 에피소드를 작성하는 데 필요한 모든 정보를 찾을 수 있습니다.
def write_page
extracted_data =extract_data(detail_page)
추출_데이터 정의
def extract_data(detail_page) 인터뷰 대상 =extract_interviewee(detail_page) title =extract_title(detail_page) sc_id =extract_soundcloud_id(detail_page) text =extract_shownotes_text(detail_page) episode_subtitle =extract_subtitle(detail_page) 에피소드_번호 =extract_episode_subtitle(episode_subtitle) tags =build_tags(title, 인터뷰 대상자) options ={ 인터뷰 대상자:인터뷰 대상자, 제목:제목, sc_id:sc_id, 텍스트:텍스트, 태그:태그, 날짜:날짜, 에피소드 번호:에피소드 번호 }종료
위에서 볼 수 있듯이 detail_page 그리고 그것에 많은 추출 방법을 적용합니다. interviewee을 추출합니다. , title , sc_id , text , episode_title , 및 episode_number . 나는 이러한 추출 책임을 담당하는 집중된 도우미 메서드를 리팩토링했습니다. 간단히 살펴보겠습니다.
도우미 방법
추출 방법
전체적으로 더 작은 방법을 사용할 수 있었기 때문에 이러한 도우미를 추출했습니다. 그들의 행동을 캡슐화하는 것도 중요했습니다. 코드도 더 잘 읽힙니다. 대부분은 detail_page를 사용합니다. 인수로 사용하고 Middleman 게시물에 필요한 특정 데이터를 추출합니다.
def extract_interviewee(detail_page) Interviewee_selector ='.episode_sub_title span' detail_page.search(interviewee_selector).text.stripend
페이지에서 특정 선택자를 검색하고 불필요한 공백 없이 텍스트를 가져옵니다.
def extract_title(detail_page) title_selector =".episode_title" detail_page.search(title_selector).text.gsub(/[?#]/, '')end
제목을 가져오고 ?를 제거합니다. 및 # 이것들은 우리 에피소드의 게시물에서 앞부분과 잘 어울리지 않기 때문입니다. 머리말에 대한 자세한 내용은 아래를 참조하세요.
def extract_soundcloud_id(detail_page) sc =detail_page.iframes_with(href:/soundcloud.com/).to_s sc.scan(/\d{3,}/).firstend
여기서 우리는 호스팅된 트랙의 SoundCloud ID를 추출하기 위해 조금 더 노력해야 했습니다. 먼저 href로 iframe을 기계화해야 합니다. soundcloud.com의 그리고 스캔을 위한 문자열로 만드세요...
"[#<기계화::페이지::프레임\n 없음\n \"https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/221003494&auto_play=false&hide_related=false&show_comments=false&show_user=true&show_reposts=false&visual=true\">\n]"
그런 다음 트랙 ID(우리의 soundcloud_id)의 자릿수에 대한 정규식을 일치시킵니다. "221003494" .
def extract_shownotes_text(detail_page) shownote_selector ="#shownote_container> p" detail_page.search(shownote_selector)end
쇼 노트를 추출하는 것은 매우 간단합니다. 세부 정보 페이지에서 쇼 노트의 단락만 찾으면 됩니다. 여기에 놀라움이 없습니다.
def extract_subtitle(detail_page) subheader_selector =".episode_sub_title" detail_page.search(subheader_selector).textend
자막도 에피소드 번호를 깔끔하게 추출하기 위한 준비 작업이라는 점을 제외하고는 마찬가지입니다.
def extract_episode_number(episode_subtitle) number =/[#]\d*/.match(episode_subtitle) clean_episode_number(number)end
여기에 정규 표현식의 또 다른 라운드가 필요합니다. 정규식을 적용하기 전과 후를 살펴보겠습니다.
에피소드_자막
" João Ferreira | 12분 | 2015년 8월 26일 | 에피소드 #139 "
숫자
#139"
깨끗한 번호가 나올 때까지 한 걸음 더.
def clean_episode_number(숫자) number.to_s.tr('#', '')end
해시 #와 함께 해당 번호를 사용합니다. 제거합니다. 짜잔, 첫 번째 에피소드 번호가 139입니다. 마찬가지로 추출. 나는 우리가 그것을 모두 모으기 전에 다른 유틸리티 방법도 살펴볼 것을 제안합니다.
유틸리티 메소드
모든 추출 작업이 끝나면 청소해야 할 부분이 있습니다. 마크다운을 구성하기 위한 데이터 준비를 이미 시작할 수 있습니다. 예를 들어 episode_subtitle 깨끗한 날짜를 얻고 tags를 빌드하려면 몇 가지 더 build_tags 사용 방법.
정확한 날짜 지정
def clean_date(episode_subtitle) string_date =/[^|]*([,])(.....)/.match(episode_subtitle).to_s Date.parse(string_date)end
다음과 같은 날짜를 찾는 또 다른 정규식을 실행합니다. " Aug 26, 2015" . 보시다시피 이것은 아직별로 도움이되지 않습니다. string_date에서 자막에서 얻은 실제 Date 물체. 그렇지 않으면 중개인 게시물을 만드는 데 쓸모가 없습니다.
문자열_날짜
" 2015년 8월 26일"
따라서 우리는 해당 문자열을 취하고 Date.parse를 수행합니다. . 결과는 훨씬 더 유망해 보입니다.
날짜
2015-08-26
def build_tags
def build_tags(title, 인터뷰 대상자) extracted_tags =strip_pipes(title) "#{인터뷰 대상자}"+ ", #{extracted_tags}"end
title 및 interviewee extract_data 내부에 구축했습니다. 메서드를 사용하고 모든 파이프 문자와 정크를 제거합니다. 파이프 문자를 쉼표, @로 바꿉니다. , ? , # , 및 & 빈 문자열을 사용하고 마지막으로 with의 약어를 처리합니다. .
def strip_pipes
def strip_pipes(text) tags =text.tr('|', ',') tags =tags.gsub(/[@?#&]/, '') tags.gsub(/[w\/] {2}/, '함께')끝
결국 우리는 태그 목록에 인터뷰 대상자 이름도 포함하고 각 태그를 쉼표로 구분합니다.
전
"마스터 @ 작업 | 서브비주얼 | 마감일 | 디자인 개성 | 디자인 문제 | 팀 | 한계에 도전하다 | 즐거운 경험 | 완벽한 세부 사항 | 회사 가치"
이후
"João Ferreira, Masters Work , Subvisual , 마감일 , 디자인 개성 , 디자인 문제 , 팀 , 밀어붙이는 봉투 , 즐거운 경험 , 완벽한 세부 사항 , 회사 가치 "
이러한 각 태그는 해당 주제에 대한 게시물 모음에 대한 링크가 됩니다. 이 모든 것이 extract_data 내에서 발생했습니다. 방법. 우리가 어디에 있는지 다시 살펴 보겠습니다.
추출_데이터 정의
def extract_data(detail_page) 인터뷰 대상 =extract_interviewee(detail_page) title =extract_title(detail_page) sc_id =extract_soundcloud_id(detail_page) text =extract_shownotes_text(detail_page) episode_subtitle =extract_subtitle(detail_page) 에피소드_번호 =extract_episode_subtitle(episode_subtitle) tags =build_tags(title, 인터뷰 대상자) options ={ 인터뷰 대상자:인터뷰 대상자, 제목:제목, sc_id:sc_id, 텍스트:텍스트, 태그:태그, 날짜:날짜, 에피소드 번호:에피소드 번호 }종료
여기서 할 일은 우리가 추출한 데이터와 함께 옵션 해시를 반환하는 것뿐입니다. 이 해시를 compose_markdown에 피드할 수 있습니다. 새로운 사이트에 필요한 파일로 데이터를 기록할 준비를 하는 방법입니다.
게시물 작성
def compose_markdown
def compose_markdown(options={})<<-HEREDOC--- title:#{options[:interviewee]}인터뷰 대상:#{options[:interviewee]}topic_list:#{options[:title]}태그:#{options[:tags]}soundcloud_id:#{options[:sc_id]}날짜:#{options[:date]}episode_number:#{options[:episode_number]}---#{options[:text]}HEREDOCend
내 Middleman 사이트에 팟캐스트 에피소드를 게시하기 위해 블로그 시스템의 용도를 변경하기로 했습니다. "순수한" 블로그 게시물을 만드는 대신 iframe을 통해 SoundCloud에서 호스팅하는 에피소드를 표시하는 에피소드에 대한 쇼 노트를 만듭니다. 인덱스 사이트에서는 해당 iframe과 제목 및 항목만 표시합니다.
이것이 작동하는 데 필요한 형식은 전면 자료라는 것으로 구성됩니다. 이것은 기본적으로 내 정적 사이트의 키/값 저장소입니다. 그것은 내 이전 Sinatra 사이트에서 내 데이터베이스 요구 사항을 대체하고 있습니다.
인터뷰 대상자 이름, 날짜, SoundCloud 트랙 ID, 에피소드 번호 등과 같은 데이터는 세 개의 대시(--- ) 에피소드 파일 위에 있습니다. 아래는 각 에피소드의 콘텐츠(질문, 링크, 스폰서 항목 등)입니다.
서론
---key:valuekey:valuekey:valuekey:value---에피소드 내용이 여기에 갑니다.
compose_markdown에서 방법, 나는 HEREDOC를 사용합니다 우리가 반복하는 각 에피소드에 대한 머리말과 함께 해당 파일을 구성합니다. 이 메서드에 제공한 옵션 해시에서 extract_data에서 수집한 모든 데이터를 추출합니다. 도우미 메서드.
def compose_markdown
...<<-HEREDOC--- 제목:#{options[:interviewee]}면접인:#{options[:interviewee]}topic_list:#{options[:title]}태그:#{options[:태그]}soundcloud_id:#{options[:sc_id]}날짜:#{options[:date]}episode_number:#{options[:episode_number]}---#{options[:text]}HEREDOC...
이것이 바로 새로운 팟캐스트 에피소드의 청사진입니다. 이것이 우리가 온 이유입니다. 아마도 다음과 같은 특정 구문이 궁금할 것입니다. #{options[:interviewee]} . 평소와 같이 문자열로 보간하지만 이미 <<-HEREDOC 안에 있기 때문에 , 큰따옴표를 생략할 수 있습니다.
방향을 잡기 위해 우리는 여전히 write_page 내부의 루프에 있습니다. 단일 에피소드의 쇼 노트가 있는 세부 정보 페이지에 대한 링크를 클릭할 때마다 기능. 다음은 이 청사진을 파일 시스템에 쓸 준비를 하는 것입니다. 즉, 파일 이름과 구성된 markdown_text를 제공하여 실제 에피소드를 생성합니다. .
마지막 단계에서는 날짜, 인터뷰 대상자 이름, 에피소드 번호 등의 재료만 준비하면 됩니다. 플러스 markdown_text 물론 compose_markdown에서 방금 가져온 것입니다. .
쓰기_페이지 정의
...markdown_text =compose_markdown(extracted_data)date =extracted_data[:date]인터뷰 대상자 =extracted_data[:인터뷰 대상자]episode_number =extracted_data[:episode_number]file_name ="#{날짜}-#{대셔라이즈(인터뷰 대상자)}-# {episode_number}.html.erb.md" ...
그런 다음 file_name 및 markdown_text 그리고 파일을 작성합니다.
def write_page
...File.open(file_name, 'w') { |file| file.write(markdown_text) }...
이것도 분해해봅시다. 각 게시물에 대해 특정 형식이 필요합니다. 2016-10-25-Avdi-Grimm-120 . 날짜로 시작하는 파일을 작성하고 인터뷰 대상자 이름과 에피소드 번호를 포함하고 싶습니다.
Middleman이 새 게시물에 대해 기대하는 형식과 일치시키려면 인터뷰 대상자의 이름을 가져와서 dasherize하는 도우미 메서드를 통해 입력해야 했습니다. 내 이름, Avdi Grimm Avdi-Grimm으로 . 마법 같은 것은 아니지만 볼 가치가 있습니다.
데셰리제이션
def dasherize(text) text.lstrip.rstrip.tr(' ', '-')end
인터뷰 대상 이름을 위해 스크랩한 텍스트에서 공백을 제거하고 Avdi와 Grimm 사이의 공백을 대시로 바꿉니다. 파일 이름의 나머지 부분은 문자열 자체에서 함께 대시로 표시됩니다. "date-interviewee-name-episodenumber" .
def write_page
...#{날짜}-#{대셔라이즈(인터뷰 대상)}-#{episode_number}.html.erb.md"...
추출한 콘텐츠는 HTML 사이트에서 바로 가져오기 때문에 .md를 단순히 사용할 수 없습니다. 또는 .markdown 파일 이름 확장자로 .html.erb.md를 사용하기로 결정했습니다. . 스크랩하지 않고 작성하는 향후 에피소드의 경우 .html.erb를 생략할 수 있습니다. 부분이며 .md만 필요합니다. .
이 단계가 끝나면 scrape의 루프 함수가 종료되고 다음과 같은 단일 에피소드가 있어야 합니다.
2014-12-01-Avdi-Grimm-1.html.erb.md
--- 제목:Avdi Grimminterviewee:Avdi Grimmtopic_list:Rake란 무엇입니까 | 기원 | 짐 웨이리치 | 일반적인 사용 사례 | Raketags의 장점:Avdi Grimm, Rake란 무엇입니까, Origins, Jim Weirich, 일반적인 사용 사례, Rakesoundcloud_id의 장점:179619755date:2014-12-01episode_number:1---Questions:- Rake가 무엇입니까?- 무엇에 대해 알려줄 수 있습니까? Rake의 기원은 무엇입니까?- Jim Weihrich에 대해 말씀해 주시겠습니까?- Rake의 가장 일반적인 사용 사례는 무엇입니까?- Rake의 가장 주목할만한 장점은 무엇입니까?Links:In">https://www.youtube.com /watch?v=2ZHJSrF52bc">위대한 Jim WeirichRake">https://github.com/jimweirich/rake">Rake on GitHubJim">https://github.com/jimweirich">Jim Weirich on GitHubBasic ">https://www.youtube.com/watch?v=AFPWDzHWjEY">Jim WeirichPower의 기본 레이크 토크">https://www.youtube.com/watch?v=KaEqZtulOus">짐 웨이리치의 파워 레이크 토크Learn ">https://devblog.avdi.org/2014/04/30/learn-advanced-rake-in-7-episodes/">Avdi Grimm(무료)Avdi">https://about.avdi.org/">Avdi GrimmAvdi Grimm의 스크린캐스트:Ruby">https://www.rubytapas.com/">Ruby TapasRuby">htt p://devchat.tv/ruby-rogues/">Avdi GrimmGreat 전자책이 포함된 Ruby Rogues 팟캐스트:Rake">https://www.amazon.com/Rake-Management-Essentials-Andrey-Koleshko/dp/1783280778"> Rake Task Management Essentials fromhttps://twitter.com/ka8725"> Andrey Koleshko
이 스크레이퍼는 물론 마지막 에피소드에서 시작하여 첫 번째 에피소드까지 반복됩니다. 시연을 위해 에피소드 01은 무엇보다 좋습니다. 우리가 추출한 데이터가 있는 전면 내용을 상단에서 볼 수 있습니다.
에피소드 번호, 날짜, 인터뷰 대상자 이름 등 모든 것이 이전에 내 Sinatra 앱의 데이터베이스에 잠겨 있었습니다. 이제 새로운 정적 Middleman 사이트의 일부로 사용할 준비가 되었습니다. 두 개의 삼중 대시 아래의 모든 항목(--- )는 쇼 노트의 텍스트입니다. 대부분 질문과 링크입니다.
최종 생각
그리고 우리는 끝났습니다. 내 새 팟캐스트는 이미 실행 중입니다. 시간을 내어 처음부터 다시 디자인하게 되어 정말 기쁩니다. 이제 새로운 에피소드를 게시하는 것이 훨씬 좋습니다. 새로운 콘텐츠를 발견하는 것은 사용자에게도 더 원활해야 합니다.
앞서 언급했듯이 지금은 코드 편집기로 이동하여 재미를 느껴야 할 때입니다. 이 코드를 가지고 조금 씨름하십시오. 더 간단하게 만드는 방법을 찾아보십시오. 코드를 리팩토링할 수 있는 몇 가지 기회가 있습니다.
전반적으로, 이 작은 예제가 새로운 웹 스크래핑 촙으로 무엇을 할 수 있는지에 대한 좋은 아이디어를 주었기를 바랍니다. 물론 훨씬 더 정교한 도전 과제를 달성할 수 있습니다. 이러한 기술을 사용하면 소규모 비즈니스 기회가 많이 있을 것이라고 확신합니다.
하지만 항상 그렇듯이 한 번에 한 단계씩 진행하고 상황이 즉시 클릭되지 않더라도 너무 좌절하지 마십시오. 이것은 대부분의 사람들에게 정상일 뿐만 아니라 예상되는 일입니다. 여정의 일부입니다. 즐거운 스크랩!